Jak používat příkaz seq v systému Linux
Příkaz seq v Linuxu umožňuje velmi rychle generovat posloupnosti čísel. Jak ale tuto funkci efektivně využít v praxi? Podíváme se na různé způsoby, jak vám seq může usnadnit práci.
Příkaz seq
Příkaz seq se na první pohled může zdát jako jednoduchý nástroj. Jeho hlavním úkolem je generovat číselné posloupnosti, a to velmi rychle. Právě rychlost je jeho klíčovou vlastností. Tento malý příkaz dokáže pracovat překvapivě efektivně.
Jak užitečný ale může být seznam čísel? Příkaz seq byl součástí Unixu už od jeho 8. verze v roce 1985, což svědčí o jeho praktické hodnotě.
Filozofie Unixu spočívá v používání malých utilit, které jsou zaměřené na jednu konkrétní úlohu a plní ji co nejlépe. Důležitým principem je také schopnost programů přijímat vstup z jiných programů a generovat výstup, který může být použit jako vstup pro další programy.
Příkaz seq se nejvíce uplatní při kombinaci s jinými příkazy, které mohou využít jeho výstup, ať už pomocí rour (pipes) nebo rozšířením příkazového řádku.
Generování základního seznamu
Pokud spustíte seq s jedním číselným argumentem, vygeneruje se posloupnost čísel od jedné do zadaného čísla. Jednotlivá čísla se vypíší do terminálu, každé na nový řádek:
seq 6
Pokud zadáte dvě čísla, první bude určovat počáteční hodnotu a druhé koncovou hodnotu posloupnosti:
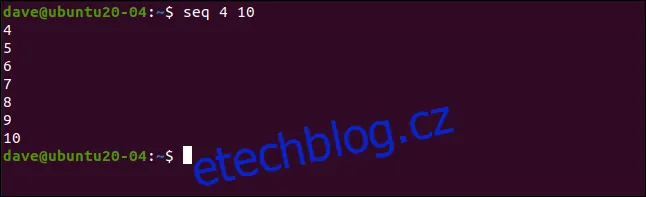
seq 4 10
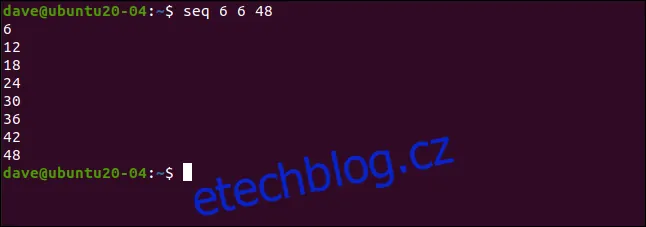
Můžete také definovat krok, o který se budou čísla v posloupnosti měnit. Toto se provede zadáním třetího čísla, které se vloží mezi počáteční a koncové číslo. Například pro vygenerování posloupnosti od 6 do 48 s krokem 6 zadáme:
seq 6 6 48
Počítání pozpátku
Příkaz seq umí generovat i posloupnosti čísel sestupně, od nejvyššího po nejnižší. Pro tento účel je ale nutné zadat záporný krok.
Následující příkaz vytvoří posloupnost čísel od 24 do 12, s krokem -6:
seq 24 -6 12

Práce s desetinnými čísly
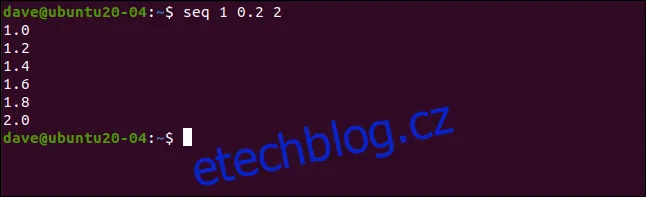
Čísla určující počátek, konec a krok mohou být i desetinná. Pokud je jedno z čísel zadané jako desetinné, i ostatní se považují za desetinná čísla. Následující příkaz vygeneruje seznam čísel s krokem 0,2:
seq 1 0.2 2
Rychlost příkazu seq
seq je extrémně rychlý. Jediným omezením je čas, který potřebujete k napsání příkazu do terminálu. Abychom otestovali jeho výkon, požádáme o vygenerování seznamu 250 000 čísel.
Pro měření času použijeme příkaz time:
time seq 250000

Výsledky měření se zobrazí pod vygenerovaným seznamem. I na průměrném počítači je seq překvapivě rychlý.

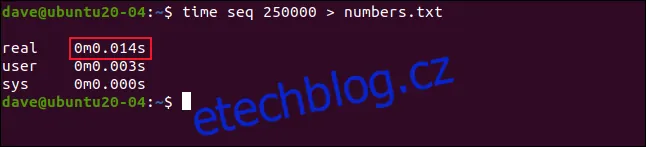
Celý seznam se vytvořil a vypsal na obrazovku za přibližně 1/3 sekundy. Pokud přesměrujeme výstup do souboru, ještě více se vyhneme režii spojené s výpisem v terminálu.
Použijeme následující příkaz:
time seq 250000 > numbers.txt
 Použití oddělovače
Použití oddělovače
Standardně se jednotlivá čísla v seznamu oddělují znakem nového řádku. Tím se čísla zobrazují jako vertikální seznam, kde každé číslo je na samostatném řádku. Můžete však použít i jiný oddělovač.
Oddělovačem může být jakýkoli znak, symbol nebo i víceznaková sekvence. Můžete například vytvořit seznam čísel oddělených čárkami, dvojtečkami nebo jiným interpunkčním znaménkem.
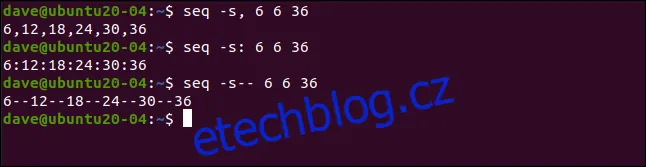
Pro zadání oddělovače se používá volba -s (separator). Následující příkaz vytvoří seznam oddělený čárkami:
seq -s, 6 6 36
Tento příkaz použije jako oddělovač dvojtečku (:):
seq -s: 6 6 36
Tento příkaz naopak jako oddělovač použije dvě pomlčky (--):
seq -s-- 6 6 36
Formátovací řetězce
Příkaz seq podporuje i formátovací řetězce známé z jazyka C. S jejich pomocí můžete lépe kontrolovat formát výstupu, než je pouhé nastavení oddělovače. Formátovací řetězec se nastavuje pomocí volby -f (format).
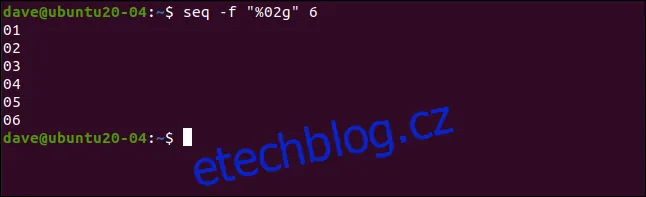
Následující příkaz doplní výstup nulami tak, aby měl vždy dva znaky:
seq -f "%02g" 6
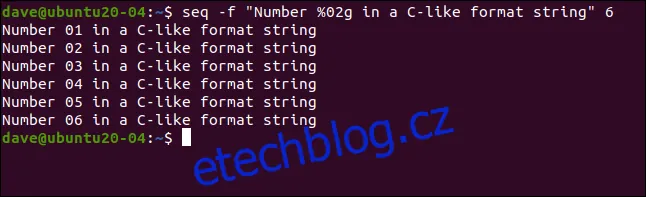
Do formátovacího řetězce můžeme umístit libovolný text a číselnou hodnotu můžeme vložit kamkoli, například takto:
seq -f "Number %02g in a C-like format string" 6
Rychlé nastavení nulového odsazení
Pro rychlé nastavení nulového odsazení můžeme použít volbu -w (equal width). Touto volbou se seq snaží doplnit čísla nulami tak, aby všechna měla stejnou šířku jako největší číslo v posloupnosti.
Následující příkaz počítá od 0 do 1000 s krokem 100. Všechna čísla budou doplněna nulami:
seq -w 0 100 1000
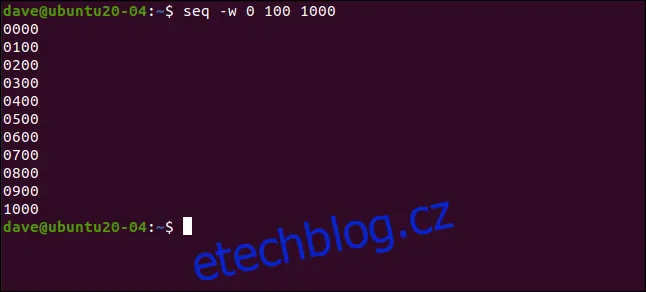
Nejdelší číslo má 4 znaky, takže všechna kratší čísla se doplní nulami tak, aby se této délce vyrovnala. Dokonce i 0 je doplněna o tři nuly.
Propojení seq s příkazem bc
Výstup z seq můžeme použít jako matematický výraz, který se má vypočítat pomocí příkazu bc. Stačí nastavit oddělovač na matematický symbol.
Následující příkaz vygeneruje seznam čísel oddělených hvězdičkami (*):
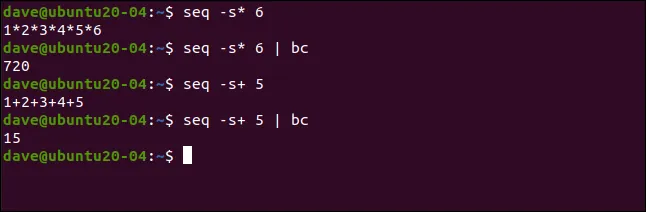
seq -s* 6
který začíná jedničkou a končí šestkou. Pokud tento seznam vložíme do bc, vypočítá součin všech čísel.
seq -s* 6 | bc
Podobně můžeme použít znaménko plus (+) pro součet:
seq -s+ 5
seq -s+ 5 | bc
Vytváření souborů pomocí seq a touch
Příkaz touch aktualizuje časové razítko u zadaných souborů. Pokud soubor neexistuje, tak ho vytvoří. Pomocí seq a rozšíření příkazového řádku můžeme vytvořit sérii souborů s tematickými názvy a čísly.
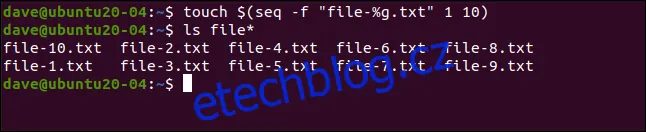
touch $(seq -f "file-%g.txt" 1 10)
Výše uvedený příkaz vytvoří sadu deseti souborů s názvy file-1.txt, file-2.txt, ..., file-10.txt. Pro ověření můžeme použít následující příkaz:
ls file*
Použití seq v Bash skriptech
#!/bin/bash
for val in $(seq 5 0.2 6.6); do
echo "The value is now: $val"
done
Příkaz seq můžeme využít i v Bash skriptech pro řízení cyklů, i s desetinnými čísly.
chmod +x loop.sh

Uložte výše uvedený skript do souboru s názvem "loop.sh" a následně jej spusťte:
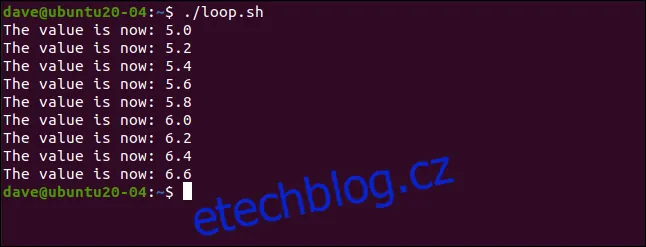
./loop.sh
Nejdříve udělejte nový skript spustitelným:
Po spuštění skriptu se v terminálu vytiskne průběh cyklu. Skript ukazuje, jak se s každou iterací zvyšuje hodnota proměnné cyklu.
seq umí počítat i pozpátku a toto chování můžeme použít i v cyklech. Používání příkazu seq je jednoduché a není zde téměř žádná křivka učení.
Stránka s manuálem je krátká, ale to nebrání tomu, aby byl tento příkaz užitečný v mnoha zajímavých situacích.
seq je užitečný při vytváření testovacích dat s realistickými rozměry. Výstup z seq s formátovacím řetězcem můžeme přesměrovat do souboru a vytvořit soubor s požadovaným počtem řádků fiktivních dat.
