Jak vylepšit svůj kód Python pomocí souběžnosti a paralelnosti
Zásadní body
- Souběžnost a paralelismus představují základní metody pro provádění úkolů v oblasti výpočetní techniky, přičemž každá z nich se vyznačuje specifickými charakteristikami.
- Souběžnost umožňuje efektivní využití systémových zdrojů a zvyšuje reaktivitu aplikací, zatímco paralelismus je klíčový pro dosažení špičkového výkonu a škálovatelnosti.
- V jazyce Python existují nástroje pro práci se souběžností, jako je vytváření vláken a asynchronní programování s knihovnou asyncio, a také paralelismus prostřednictvím modulu multiprocessing.
Souběžnost a paralelismus představují dvě odlišné metody, které umožňují provádět více programů současně. Python nabízí několik přístupů k zpracování úloh souběžně i paralelně, což může být pro někoho matoucí.
Prozkoumejte dostupné nástroje a knihovny pro správnou implementaci souběžnosti a paralelismu v Pythonu a pochopte rozdíly mezi nimi.
Porozumění souběžnosti a paralelismu
Souběžnost a paralelismus jsou dva klíčové koncepty v oblasti výpočetní techniky. Každý z nich má své unikátní vlastnosti.
- Souběžnost se týká schopnosti programu spravovat více úkolů zdánlivě současně, aniž by byly nutně spouštěny přesně ve stejný okamžik. Klíčová je zde myšlenka prokládání úkolů a přepínání mezi nimi, což vytváří dojem simultánního provádění.
- Naopak, paralelismus zahrnuje skutečné provádění více úkolů současně. Obvykle se využívá více jader CPU nebo procesorů. Paralelismus dosahuje reálného souběžného provádění, což umožňuje provádět úkoly rychleji a je ideální pro výpočetně náročné operace.

Význam souběžnosti a paralelismu
Potřeba souběžnosti a paralelismu ve výpočetní technice je obrovská. Zde jsou hlavní důvody, proč jsou tyto metody tak důležité:
- Využití zdrojů: Souběžnost umožňuje efektivní využití systémových zdrojů a zajišťuje, že úkoly aktivně postupují, namísto nečinného čekání na externí zdroje.
- Reakce: Souběžnost dokáže výrazně zlepšit odezvu aplikací, zejména v situacích s uživatelskými rozhraními nebo webovými servery.
- Výkon: Paralelismus je zásadní pro dosažení optimálního výkonu, zvláště u úloh náročných na CPU, jako jsou komplexní výpočty, zpracování velkých dat a simulace.
- Škálovatelnost: Jak souběžnost, tak paralelismus jsou nezbytné pro vytváření škálovatelných systémů.
- Připravenost na budoucnost: S ohledem na vývoj hardwaru, který stále více upřednostňuje vícejádrové procesory, se paralelismus stává stále důležitější.
Souběžnost v Pythonu
V Pythonu lze dosáhnout souběžnosti pomocí vláken a asynchronního programování s knihovnou asyncio.
Vlákna v Pythonu
Vlákna jsou mechanismem souběžnosti v Pythonu, který umožňuje vytvářet a spravovat úlohy v rámci jednoho procesu. Jsou vhodné zejména pro úlohy vázané na I/O, které mohou těžit z souběžného provádění.
Modul threading v Pythonu poskytuje rozhraní na vysoké úrovni pro vytváření a správu vláken. Přestože GIL (Global Interpreter Lock) omezuje vlákna z hlediska skutečného paralelismu, mohou stále dosáhnout souběžnosti efektivním prokládáním úloh.
Následující kód demonstruje implementaci souběžnosti pomocí vláken. Používá knihovnu requests k odeslání HTTP požadavků, což je běžný I/O blokující úkon, a také modul time k měření doby provádění.
import requests
import time
import threading
urls = [
'https://www.google.com',
'https://www.wikipedia.org',
'https://www.makeuseof.com',
]
def download_url(url):
response = requests.get(url)
print(f"Downloaded {url} - Status Code: {response.status_code}")
start_time = time.time()
for url in urls:
download_url(url)
end_time = time.time()
print(f"Sequential download took {end_time - start_time:.2f} seconds\n")
start_time = time.time()
threads = []
for url in urls:
thread = threading.Thread(target=download_url, args=(url,))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
end_time = time.time()
print(f"Threaded download took {end_time - start_time:.2f} seconds")
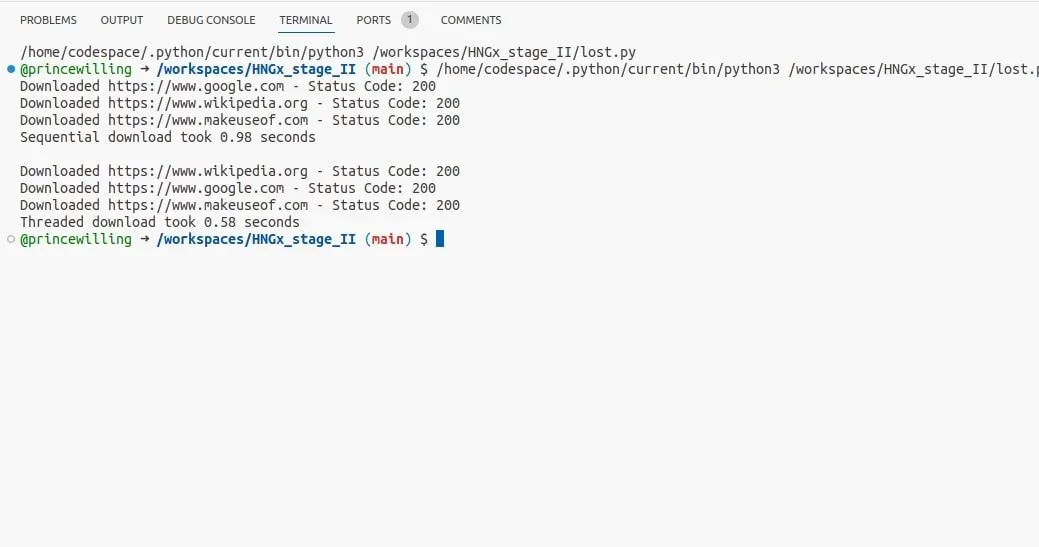
Při spuštění tohoto programu by mělo být patrné, že požadavky prováděné vlákny jsou výrazně rychlejší než sekvenční požadavky. I když je rozdíl jen v zlomcích sekund, je jasné zlepšení výkonu při použití vláken pro úlohy vázané na I/O.
Asynchronní programování s Asyncio
Knihovna asyncio nabízí smyčku událostí, která spravuje asynchronní úlohy, známé jako korutiny. Korutiny jsou funkce, které lze pozastavit a obnovit, což je činí ideální pro úlohy vázané na I/O. Tato knihovna je obzvláště užitečná v situacích, kdy úlohy zahrnují čekání na externí zdroje, například síťové požadavky.
Předchozí příklad odesílání požadavků lze modifikovat, aby pracoval s asyncio:
import asyncio
import aiohttp
import time
urls = [
'https://www.google.com',
'https://www.wikipedia.org',
'https://www.makeuseof.com',
]
async def download_url(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
content = await response.text()
print(f"Downloaded {url} - Status Code: {response.status}")
async def main():
tasks = [download_url(url) for url in urls]
await asyncio.gather(*tasks)
start_time = time.time()
asyncio.run(main())
end_time = time.time()
print(f"Asyncio download took {end_time - start_time:.2f} seconds")
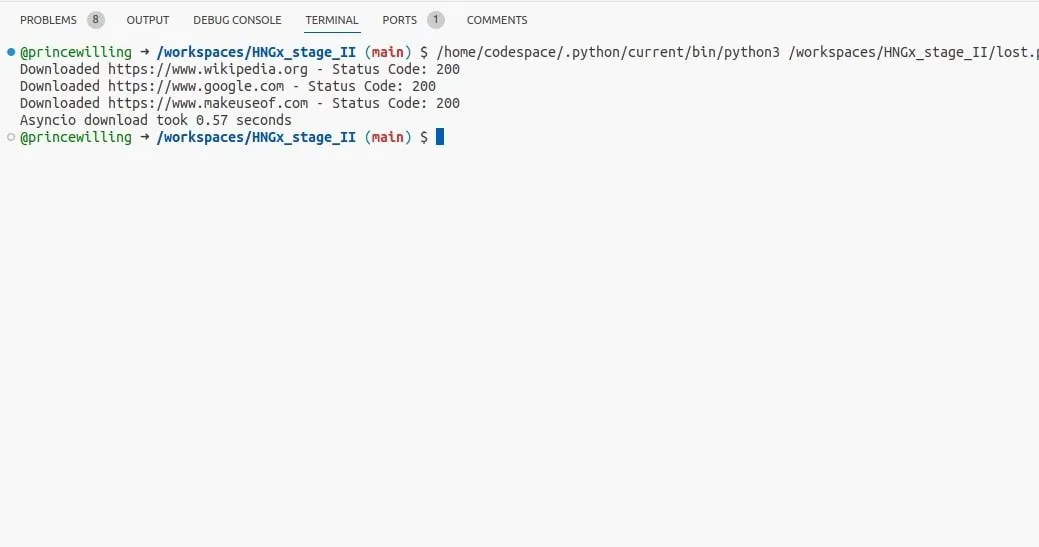
Pomocí tohoto kódu je možné stahovat webové stránky souběžně s využitím asyncia a využít výhod asynchronních I/O operací. To se může ukázat efektivnější pro úlohy vázané na I/O než použití vláken.
Paralelismus v Pythonu
Paralelismus lze implementovat pomocí modulu multiprocessing v Pythonu, který umožňuje plně využít potenciálu vícejádrových procesorů.
Multiprocessing v Pythonu
Modul multiprocessing v Pythonu poskytuje způsob, jak dosáhnout paralelismu vytvořením samostatných procesů, z nichž každý má svůj vlastní interpret Pythonu a paměťový prostor. Tímto způsobem se efektivně obchází Global Interpreter Lock (GIL), což je výhodné pro úlohy vázané na CPU.
import requests
import multiprocessing
import time
urls = [
'https://www.google.com',
'https://www.wikipedia.org',
'https://www.makeuseof.com',
]
def download_url(url):
response = requests.get(url)
print(f"Downloaded {url} - Status Code: {response.status_code}")
def main():
num_processes = len(urls)
pool = multiprocessing.Pool(processes=num_processes)
start_time = time.time()
pool.map(download_url, urls)
end_time = time.time()
pool.close()
pool.join()
print(f"Multiprocessing download took {end_time-start_time:.2f} seconds")
main()
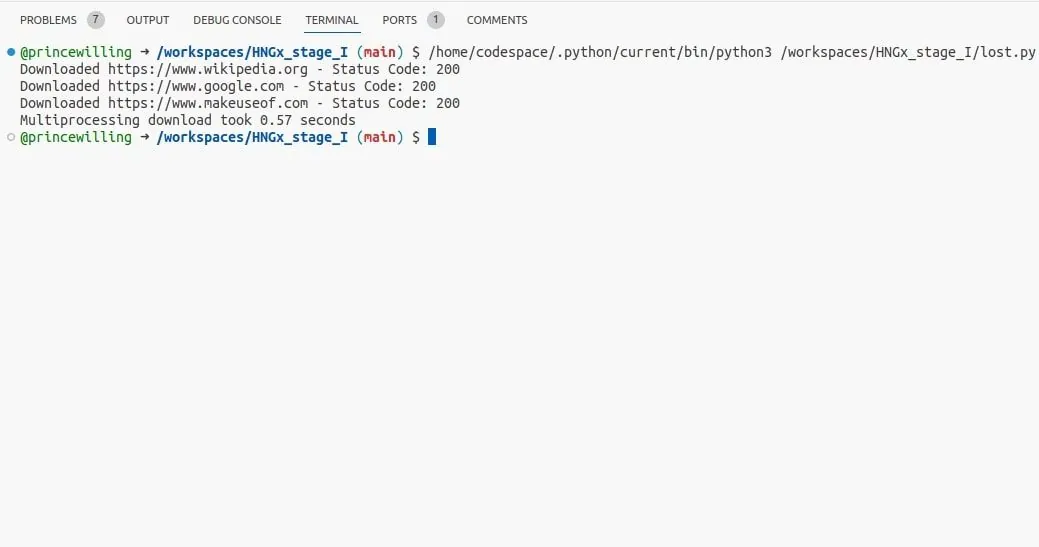
V tomto příkladu multiprocessing vytváří několik procesů, což umožňuje funkci download_url běžet paralelně.
Kdy použít souběžnost nebo paralelismus
Volba mezi souběžností a paralelismem závisí na charakteru úloh a dostupných hardwarových prostředcích.
Souběžnost je vhodná pro úlohy vázané na I/O, jako je čtení a zápis do souborů nebo provádění síťových požadavků, a také tehdy, když jsou omezené paměťové zdroje.
Multiprocessing je naopak vhodný pro úlohy vázané na CPU, které mohou těžit z reálného paralelismu, a také v situacích, kdy je potřeba silná izolace mezi úlohami, aby selhání jedné z nich nemělo dopad na ostatní.
Využití výhod souběžnosti a paralelismu
Paralelismus a souběžnost jsou efektivní způsoby, jak zlepšit odezvu a výkon kódu v Pythonu. Je klíčové pochopit rozdíly mezi těmito koncepty a vybrat nejvhodnější strategii.
Python nabízí potřebné nástroje a moduly pro optimalizaci kódu pomocí souběžnosti nebo paralelismu, ať už pracujete s úlohami vázanými na CPU, nebo na I/O.
