Jak vytvořit DataFrame v R pro uchování dat organizovaným způsobem
Data framy představují klíčovou datovou strukturu v jazyce R, nabízející uspořádání, flexibilitu a nástroje potřebné pro analýzu a manipulaci s daty. Jejich význam se rozšiřuje do různých oblastí, zahrnujíc statistiku, datovou vědu a rozhodování založené na datech v různých průmyslových odvětvích.
Data framy poskytují strukturu a organizaci nezbytnou k objevování poznatků a přijímání rozhodnutí na základě dat, a to systematickým a efektivním způsobem.
V R jsou data framy strukturovány jako tabulky s řádky a sloupci. Každý řádek reprezentuje pozorování a každý sloupec proměnnou. Toto uspořádání usnadňuje organizaci a práci s daty. Data framy mohou obsahovat různorodé datové typy, včetně čísel, textu a dat, což jim propůjčuje univerzálnost.
V tomto článku objasním význam datových rámců a popíši jejich vytváření pomocí funkce data.frame().
Dále se podíváme na metody manipulace s daty, včetně vytváření z CSV a Excel souborů, konverzi jiných datových struktur na datové rámce a využití knihovny tibble.
Zde uvádím několik hlavních důvodů, proč jsou data framy v R tak klíčové:
Význam datových rámců
- Ukládání strukturovaných dat: Data framy poskytují strukturovaný a tabulkový způsob ukládání dat, podobný tabulkovému procesoru. Tento formát zjednodušuje správu a organizaci dat.
- Smíšené datové typy: Data framy mohou v rámci jedné struktury uchovávat různé datové typy. Můžete mít sloupce s numerickými hodnotami, textovými řetězci, faktory, daty a dalšími. Tato flexibilita je nezbytná při práci s reálnými daty.
- Organizace dat: Každý sloupec v data framu představuje proměnnou, zatímco každý řádek představuje pozorování nebo případ. Toto uspořádání usnadňuje pochopení struktury dat a zvyšuje jejich přehlednost.
- Import a export dat: Data framy podporují snadný import a export dat z různých formátů souborů, jako jsou CSV, Excel a databáze. Tato funkčnost zefektivňuje práci s externími zdroji dat.
- Interoperabilita: Data framy jsou široce podporovány balíčky a funkcemi v R, což zajišťuje kompatibilitu s dalšími nástroji a knihovnami pro statistickou a datovou analýzu. Tato interoperabilita umožňuje bezproblémovou integraci do ekosystému R.
- Manipulace s daty: R nabízí bohatou sadu balíčků, přičemž „dplyr“ je skvělý příklad. Tyto balíčky usnadňují filtrování, transformaci a sumarizaci dat v rámci data framů. Tato schopnost je zásadní pro čištění a přípravu dat.
- Statistická analýza: Data framy jsou standardním formátem dat pro mnoho statistických a analytických funkcí v R. S jejich pomocí lze efektivně provádět regresi, testování hypotéz a mnoho dalších statistických analýz.
- Vizualizace: Balíčky pro vizualizaci dat v R, jako je ggplot2, fungují bez problémů s data framy. Díky tomu je jednoduché vytvářet informativní tabulky a grafy pro průzkum dat a jejich prezentaci.
- Průzkum dat: Data framy usnadňují průzkum dat pomocí souhrnných statistik, vizualizací a dalších analytických metod. To pomáhá analytikům a datovým vědcům porozumět charakteristikám dat a odhalovat vzory nebo odlehlé hodnoty.
Jak vytvořit DataFrame v R
Existuje několik způsobů, jak vytvořit data frame v R. Zde jsou některé z nejpoužívanějších:
#1. Použití funkce data.frame().
# Načtení potřebné knihovny, pokud již není načtena
if (!require("dplyr")) {
install.packages("dplyr")
library(dplyr)
}
# Alternativní způsob načtení knihovny
library(dplyr)
# Nastavení semínka pro opakovatelnost
set.seed(42)
# Vytvoření ukázkového prodejního data frame se skutečnými názvy produktů
sales_data <- data.frame(
OrderID = 1001:1010,
Product = c("Notebook", "Smartphone", "Tablet", "Sluchátka", "Fotoaparát", "Televize", "Tiskárna", "Pračka", "Lednička", "Mikrovlnná trouba"),
Quantity = sample(1:10, 10, replace = TRUE),
Price = round(runif(10, 100, 2000), 2),
Discount = round(runif(10, 0, 0.3), 2),
Date = sample(seq(as.Date('2023-01-01'), as.Date('2023-01-10'), by="days"), 10)
)
# Zobrazení prodejního data frame
print(sales_data)
Pojďme si vysvětlit, co náš kód dělá:
- Nejprve kontroluje, zda je v prostředí R dostupná knihovna "dplyr".
- Pokud "dplyr" není k dispozici, nainstaluje a načte tuto knihovnu.
- Poté nastaví náhodné semínko pro opakovatelnost výsledků.
- Následně vytvoří ukázkový data frame s prodejními daty, včetně názvů produktů.
- Nakonec zobrazí vytvořený data frame v konzoli.
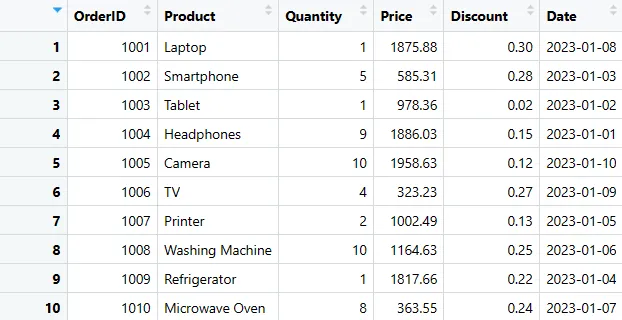 Sales_dataframe
Sales_dataframe
Toto je jeden z nejjednodušších způsobů, jak vytvořit data frame v R. Dále se podíváme na to, jak extrahovat, přidávat, mazat a vybírat konkrétní sloupce nebo řádky a také jak sumarizovat data.
Extrahování sloupců
Existují dva způsoby, jak extrahovat potřebné sloupce z našeho datového rámce:
- Pro načtení posledních tří sloupců z data frame v R můžete využít indexování.
- Sloupce můžete extrahovat pomocí operátoru
$, pokud chcete přistupovat k jednotlivým sloupcům pomocí jejich názvu.
Pro úsporu času si ukážeme oba způsoby společně:
# Extrahování posledních tří sloupců (Discount, Price a Date) z data frame sales_data
last_three_columns <- sales_data[, c("Discount", "Price", "Date")]
# Zobrazení extrahovaných sloupců
print(last_three_columns)
############################################# NEBO #########################################################
# Extrahování posledních tří sloupců (Discount, Price a Date) pomocí operátoru $
discount_column <- sales_data$Discount
price_column <- sales_data$Price
date_column <- sales_data$Date
# Vytvoření nového data frame s extrahovanými sloupci
last_three_columns <- data.frame(Discount = discount_column, Price = price_column, Date = date_column)
# Zobrazení extrahovaných sloupců
print(last_three_columns)
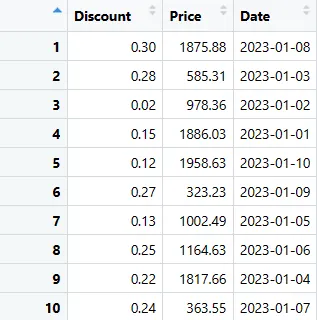
Pomocí kteréhokoli z těchto kódů můžete extrahovat potřebné sloupce.
Řádky z data frame v R můžete extrahovat pomocí různých metod. Zde je jednoduchý způsob:
# Extrahování specifických řádků (3, 6 a 9) z data frame last_three_columns selected_rows <- last_three_columns[c(3, 6, 9), ] # Zobrazení vybraných řádků print(selected_rows)
Můžete také použít zadané podmínky:
# Extrahování a uspořádání řádků, které splňují stanovené podmínky selected_rows <- sales_data %>% filter(Discount < 0.3, Price > 100, format(Date, "%Y-%m") == "2023-01") %>% arrange(OrderID) %>% select(Discount, Price, Date) # Zobrazení vybraných řádků print(selected_rows)
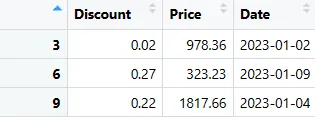 Extrahované řádky
Extrahované řádky
Přidání nového řádku
Pro přidání nového řádku do existujícího data frame v R můžete použít funkci rbind():
# Vytvoření nového řádku jako data frame
new_row <- data.frame(
OrderID = 1011,
Product = "Kávovar",
Quantity = 2,
Price = 75.99,
Discount = 0.1,
Date = as.Date("2023-01-12")
)
# Použití funkce rbind() pro přidání nového řádku do data frame
sales_data <- rbind(sales_data, new_row)
# Zobrazení aktualizovaného data frame
print(sales_data)
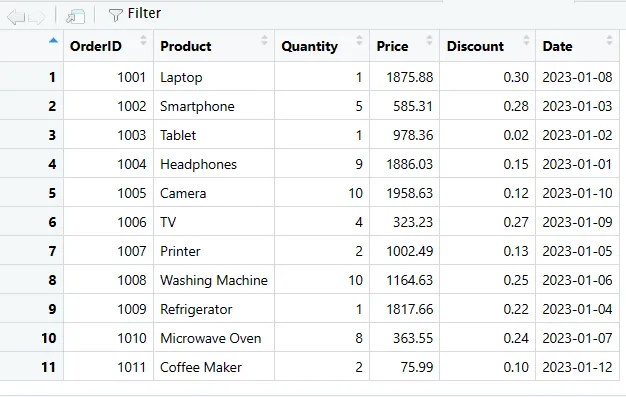 Přidán nový řádek
Přidán nový řádek
Přidání nového sloupce
Pomocí jednoduchého kódu můžete do svého data frame přidat sloupce. Zde chci přidat sloupec "Způsob platby".
# Vytvoření nového sloupce "PaymentMethod" s hodnotami pro každý řádek
sales_data$PaymentMethod <- c("Kreditní karta", "PayPal", "Hotovost", "Kreditní karta", "Hotovost", "PayPal", "Hotovost", "Kreditní karta", "Kreditní karta", "Hotovost", "Kreditní karta")
# Zobrazení aktualizovaného data frame
print(sales_data)
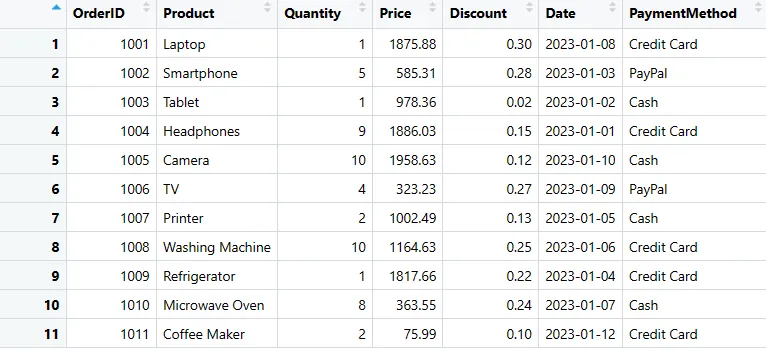 Sloupec přidán do datového rámce
Sloupec přidán do datového rámce
Smazání řádků
Pokud chcete odstranit nepotřebné řádky, může být užitečná následující metoda:
# Identifikace řádku pro smazání pomocí jeho OrderID row_to_delete <- sales_data$OrderID == 1010 # Použití identifikovaného řádku pro vyloučení a vytvoření nového data frame sales_data <- sales_data[!row_to_delete, ] # Zobrazení aktualizovaného data frame bez smazaného řádku print(sales_data)
Smazání sloupců
Pomocí balíčku dplyr můžete odstranit sloupec z data frame v R.
# Instalace balíčku dplyr (pokud není nainstalován) library(dplyr) # Odstranění sloupce "Discount" pomocí funkce select() sales_data <- sales_data %>% select(-Discount) # Zobrazení aktualizovaného data frame bez sloupce "Discount" print(sales_data)
Získání souhrnu
Pro získání souhrnu vašich dat v R můžete použít funkci summary(). Tato funkce poskytuje rychlý přehled o centrální tendenci a rozložení číselných proměnných ve vašich datech.
# Získání souhrnu dat data_summary <- summary(sales_data) # Zobrazení souhrnu print(data_summary)
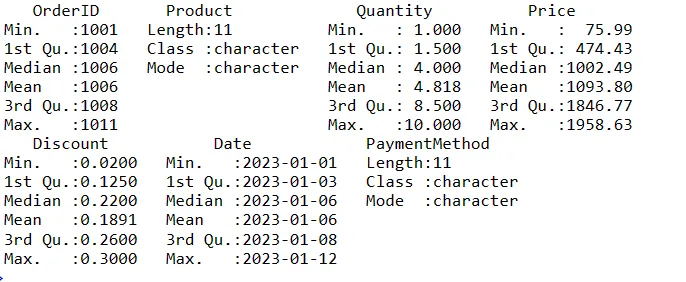
Toto je několik kroků, které můžete provést při manipulaci s daty v rámci data frame.
Přejděme k druhému způsobu vytvoření data frame.
#2. Vytvoření R DataFrame z CSV souboru
Pro vytvoření R data frame z CSV souboru můžete použít funkci read.csv().
# Načtení CSV souboru do data frame
df <- read.csv("my_data.csv")
# Zobrazení prvních několika řádků data frame
head(df)
Tato funkce čte data ze souboru CSV a převádí je. Poté můžete s daty v R pracovat podle potřeby.
# Instalace a načtení balíčku readr, pokud ještě není nainstalován
if (!requireNamespace("readr", quietly = TRUE)) {
install.packages("readr")
}
library(readr)
# Načtení CSV souboru do data frame
df <- read_csv("data.csv")
# Zobrazení prvních několika řádků data frame
head(df)
můžete použít balíček readr pro čtení CSV souboru v R. Funkce read_csv() z balíčku readr se běžně používá. Je rychlejší než běžná metoda.
#3. Použití funkce as.data.frame().
Data frame v R můžete vytvořit pomocí funkce as.data.frame(). Tato funkce vám umožňuje převést další datové struktury, jako jsou matice nebo seznamy, do data frame.
Postup použití:
# Vytvoření vnořeného seznamu pro reprezentaci dat
data_list <- list(
OrderID = 1001:1011,
Product = c("Notebook", "Smartphone", "Tablet", "Sluchátka", "Fotoaparát", "Televize", "Tiskárna", "Pračka", "Lednička", "Mikrovlnná trouba", "Kávovar"),
Quantity = c(1, 5, 1, 9, 10, 4, 2, 10, 1, 8, 2),
Price = c(1875.88, 585.31, 978.36, 1886.03, 1958.63, 323.23, 1002.49, 1164.63, 1817.66, 363.55, 75.99),
Discount = c(0.3, 0.28, 0.02, 0.15, 0.12, 0.27, 0.13, 0.25, 0.22, 0.24, 0.1),
Date = as.Date(c("2023-01-08", "2023-01-03", "2023-01-02", "2023-01-01", "2023-01-10", "2023-01-09", "2023-01-05", "2023-01-06", "2023-01-04", "2023-01-07", "2023-01-12")),
PaymentMethod = c("Kreditní karta", "PayPal", "Hotovost", "Kreditní karta", "Hotovost", "PayPal", "Hotovost", "Kreditní karta", "Kreditní karta", "Hotovost", "Kreditní karta")
)
# Převod vnořeného seznamu na data frame
sales_data <- as.data.frame(data_list)
# Zobrazení data frame
print(sales_data)
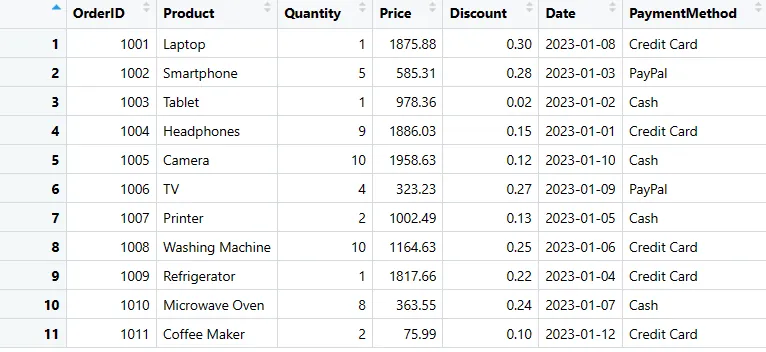 Prodejní_data
Prodejní_data
Tato metoda vám umožňuje vytvořit data frame bez zadávání každého sloupce jednotlivě a je obzvláště užitečná, když máte velké množství dat.
#4. Z existujícího data frame
Pro vytvoření nového data frame výběrem konkrétních sloupců nebo řádků z existujícího data frame v R můžete použít hranaté závorky [] pro indexování. Funguje to takto:
# Výběr řádků a sloupců
sales_subset <- sales_data[c(1, 3, 4), c("Product", "Quantity")]
# Zobrazení vybrané podmnožiny
print(sales_subset)
V tomto kódu vytváříme nový data frame s názvem sales_subset, který obsahuje konkrétní řádky (1, 3 a 4) a konkrétní sloupce ("Product" a "Quantity") z sales_data.
Můžete upravit indexy a názvy řádků a sloupců, abyste si vybrali data, která potřebujete.
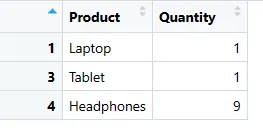 Prodej_Podmnožina
Prodej_Podmnožina
#5. Z vektoru
Vektor je jednorozměrná datová struktura v R, která se skládá z prvků stejného datového typu, včetně logických, celočíselných, dvojitých, znakových, komplexních nebo nezpracovaných.
Na druhou stranu R data frame je dvourozměrná struktura navržená pro ukládání dat v tabulkovém formátu s řádky a sloupci. Existují různé metody, jak vytvořit R data frame z vektoru, a jeden takový příklad je uveden níže.
# Vytvoření vektorů pro každý sloupec
OrderID <- 1001:1011
Product <- c("Notebook", "Smartphone", "Tablet", "Sluchátka", "Fotoaparát", "Televize", "Tiskárna", "Pračka", "Lednička", "Mikrovlnná trouba", "Kávovar")
Quantity <- c(1, 5, 1, 9, 10, 4, 2, 10, 1, 8, 2)
Price <- c(1875.88, 585.31, 978.36, 1886.03, 1958.63, 323.23, 1002.49, 1164.63, 1817.66, 363.55, 75.99)
Discount <- c(0.3, 0.28, 0.02, 0.15, 0.12, 0.27, 0.13, 0.25, 0.22, 0.24, 0.1)
Date <- as.Date(c("2023-01-08", "2023-01-03", "2023-01-02", "2023-01-01", "2023-01-10", "2023-01-09", "2023-01-05", "2023-01-06", "2023-01-04", "2023-01-07", "2023-01-12"))
PaymentMethod <- c("Kreditní karta", "PayPal", "Hotovost", "Kreditní karta", "Hotovost", "PayPal", "Hotovost", "Kreditní karta", "Kreditní karta", "Hotovost", "Kreditní karta")
# Vytvoření data frame pomocí funkce data.frame()
sales_data <- data.frame(
OrderID = OrderID,
Product = Product,
Quantity = Quantity,
Price = Price,
Discount = Discount,
Date = Date,
PaymentMethod = PaymentMethod
)
# Zobrazení data frame
print(sales_data)
V tomto kódu vytváříme samostatné vektory pro každý sloupec a poté pomocí funkce data.frame() tyto vektory zkombinujeme do data frame s názvem sales_data.
To vám umožní vytvořit strukturovaný tabulkový data frame z jednotlivých vektorů v R.
#6. Ze souboru Excel
Pro vytvoření data frame importem souboru Excel v R můžete použít balíčky třetích stran, jako je readxl, protože základní R nenabízí nativní podporu pro čtení souborů CSV. Jednou z takových funkcí pro čtení souborů aplikace Excel je read_excel().
# Načtení knihovny readxl library(readxl) # Definování cesty k souboru Excel excel_file_path <- "your_file.xlsx" # Nahraďte skutečnou cestou k souboru # Načtení souboru Excel a vytvoření data frame data_frame_from_excel <- read_excel(excel_file_path) # Zobrazení data frame print(data_frame_from_excel)
Tento kód načte soubor Excel a uloží jeho data do R data frame, což vám umožní pracovat s daty v prostředí R.
#7. Z textového souboru
Pro import textového souboru do data frame můžete použít funkci read.table() v R. Tato funkce vyžaduje dva základní parametry: název souboru, který chcete číst, a oddělovač, který určuje, jak jsou pole v souboru oddělena.
# Definování názvu souboru a oddělovače file_name <- "your_text_file.txt" # Nahraďte skutečným názvem souboru delimiter <- "\t" # Nahraďte skutečným oddělovačem (např. "\t" pro tabulku, "," pro CSV) # Použití funkce read.table() pro vytvoření data frame data_frame_from_text <- read.table(file_name, header = TRUE, sep = delimiter) # Zobrazení data frame print(data_frame_from_text)
Tento kód přečte textový soubor a vytvoří jej v R, čímž jej zpřístupní pro analýzu dat ve vašem prostředí R.
#8. Použití Tibble
Chcete-li jej vytvořit pomocí poskytnutých vektorů a využít knihovnu tidyverse, můžete postupovat takto:
# Načtení knihovny tidyverse
library(tidyverse)
# Vytvoření tibble pomocí poskytnutých vektorů
sales_data <- tibble(
OrderID = 1001:1011,
Product = c("Notebook", "Smartphone", "Tablet", "Sluchátka", "Fotoaparát", "Televize", "Tiskárna", "Pračka", "Lednička", "Mikrovlnná trouba", "Kávovar"),
Quantity = c(1, 5, 1, 9, 10, 4, 2, 10, 1, 8, 2),
Price = c(1875.88, 585.31, 978.36, 1886.03, 1958.63, 323.23, 1002.49, 1164.63, 1817.66, 363.55, 75.99),
Discount = c(0.3, 0.28, 0.02, 0.15, 0.12, 0.27, 0.13, 0.25, 0.22, 0.24, 0.1),
Date = as.Date(c("2023-01-08", "2023-01-03", "2023-01-02", "2023-01-01", "2023-01-10", "2023-01-09", "2023-01-05", "2023-01-06", "2023-01-04", "2023-01-07", "2023-01-12")),
PaymentMethod = c("Kreditní karta", "PayPal", "Hotovost", "Kreditní karta", "Hotovost", "PayPal", "Hotovost", "Kreditní karta", "Kreditní karta", "Hotovost", "Kreditní karta")
)
# Zobrazení vytvořeného prodejního tibble
print(sales_data)
Tento kód používá funkci tibble() z knihovny tidyverse k vytvoření datového rámce tibble s názvem sales_data. Formát tibble poskytuje více informativní výpis ve srovnání s výchozím data framem v R, jak jste zmínil.
Jak efektivně používat DataFrames v R
Efektivní používání data framů v R je nezbytné pro manipulaci a analýzu dat. Data framy jsou základní datovou strukturou v R a obvykle jsou vytvářeny a manipulovány pomocí funkce data.frame. Zde je několik tipů pro efektivní práci:
- Před vytvořením se ujistěte, že jsou vaše data čistá a dobře strukturovaná. Odstraňte všechny nepotřebné řádky nebo sloupce, zpracujte chybějící hodnoty a ujistěte se, že datové typy jsou vhodné.
- Nastavte vhodné datové typy pro vaše sloupce (např. numerický, znakový, faktor, datum). To může zlepšit využití paměti a rychlost výpočtu.
- Pomocí indexování a podmnožin můžete pracovat s menšími částmi dat. Funkce
subset()a operátor[]jsou pro tento účel užitečné.
- Funkce
attach()adetach()mohou být pohodlné, ale mohou také vést k nejednoznačnosti a neočekávanému chování.
- R je vysoce optimalizováno pro vektorizované operace. Kdykoli je to možné, používejte pro manipulaci s daty místo smyček vektorizované funkce.
- Vnořené smyčky mohou být v R pomalé. Místo vnořených smyček zkuste použít vektorizované operace nebo funkce jako
lapplynebosapply.
- Velké data framy mohou spotřebovat hodně paměti. Zvažte použití balíčků
data.tablenebodtplyr, které jsou pro větší datové sady efektivnější z hlediska paměti.
- R má širokou škálu balíčků pro manipulaci s daty. Pro efektivní transformaci dat využijte balíčky jako
dplyr,tidyradata.table.
- Minimalizujte používání globálních proměnných, zejména při práci s více data framy. Používejte funkce a předávejte data framy jako argumenty.
- Při práci s agregovanými daty použijte funkce
group_by()asummarize()vdplyrk efektivnímu provádění výpočtů.
- U velkých datových sad zvažte použití paralelního zpracování s balíčky, jako je
parallelneboforeach, abyste urychlili operace.
- Při čtení dat do R používejte funkce jako
readrnebodata.table::freadmísto základních funkcí R, jako jeread.csvpro rychlejší import dat.
- U velmi velkých datových sad zvažte použití databázových systémů nebo specializovaných formátů úložiště, jako je Feather, Arrow nebo Parquet.
Dodržováním těchto osvědčených postupů můžete efektivně pracovat s data framy v R, díky čemuž bude manipulace s daty a analytické úlohy lépe zvládnutelné a rychlejší.
Závěrečné myšlenky
Vytváření data framů v R je jednoduché a máte k dispozici různé metody. Zdůraznil jsem důležitost data framů a diskutoval o jejich vytváření pomocí funkce data.frame().
Kromě toho jsme prozkoumali metody pro manipulaci s daty a probrali, jak vytvářet z CSV a Excel souborů, převádět jiné datové struktury na data framy a využívat knihovnu tibble.
Možná vás budou zajímat nejlepší IDE pro programování v R.
