Porovnání předních platforem pro zasílání zpráv
Apache Kafka a RabbitMQ představují dva významné nástroje pro zprostředkování zpráv, které umožňují oddělenou komunikaci mezi různými aplikacemi. Jaké jsou jejich klíčové charakteristiky a v čem se liší? Následující text se věnuje těmto konceptům.
RabbitMQ
RabbitMQ je open-source zprostředkovatel zpráv, který umožňuje komunikaci a výměnu dat mezi různými stranami. Je vyvinut v jazyce Erlang, díky čemuž je vysoce efektivní a nenáročný na zdroje. Jazyk Erlang byl vyvinut společností Ericsson se zaměřením na vytváření distribuovaných systémů.
RabbitMQ je považován za tradičnějšího zprostředkovatele zpráv. Funguje na principu vydavatel-odběratel, ačkoli může zpracovávat komunikaci jak synchronně, tak asynchronně, v závislosti na konfiguraci. Zajišťuje také spolehlivé doručování zpráv a jejich správné pořadí mezi odesílateli a příjemci.
Podporuje protokoly jako AMQP, STOMP, MQTT, HTTP a WebSockets. Nabízí tři modely pro výměnu zpráv: téma, fanout a přímé:
- Přímá a cílená výměna zpráv na základě tématu [topic]
- Všechny odběratele připojené k frontě obdrží stejnou zprávu [fanout]
- Každý odběratel obdrží odeslanou zprávu individuálně [direct]
Následující komponenty tvoří základ systému RabbitMQ:
Producenti
Producenti jsou aplikace, které vytvářejí a odesílají zprávy do RabbitMQ. Prakticky jakákoli aplikace, která se dokáže připojit k RabbitMQ, může publikovat zprávy.
Spotřebitelé
Spotřebitelé jsou aplikace, které přijímají a zpracovávají zprávy od RabbitMQ. Opět platí, že se jedná o jakoukoli aplikaci schopnou se připojit a odebírat zprávy z RabbitMQ.
Výměny (Exchanges)
Výměny jsou zodpovědné za příjem zpráv od producentů a jejich směrování do příslušných front. Existuje několik typů výměn, včetně přímé výměny, fanout výměny, výměny založené na tématech a hlavičkách. Každá z nich má specifická pravidla pro směrování zpráv.
Fronty (Queues)
Fronty jsou místa, kde se zprávy dočasně ukládají, dokud je spotřebitelé nezpracují. Vytváří je buď aplikace, nebo automaticky RabbitMQ při publikování zprávy na výměně.
Vazby (Bindings)
Vazby definují vztah mezi výměnami a frontami. Určují pravidla, jakými jsou zprávy směrovány z výměn do konkrétních front.
Architektura RabbitMQ
RabbitMQ používá takzvaný pull model pro doručování zpráv. V tomto modelu si spotřebitelé aktivně vyžádají zprávy od zprostředkovatele. Zprávy jsou publikovány na výměnách, které je na základě směrovacích klíčů přesměrují do odpovídajících front.
Architektura RabbitMQ je založena na principu klient-server a skládá se z několika komponent, které spolupracují na zajištění spolehlivé a škálovatelné platformy pro zasílání zpráv. Koncept AMQP definuje klíčové komponenty jako Exchanges, Queues, Bindings, ale také Publishers a Subscribers. Vydavatelé posílají zprávy na výměny.
Výměny převezmou tyto zprávy a distribuují je do nula až n front na základě definovaných pravidel (vazeb). Zprávy uložené ve frontách pak mohou být načteny spotřebiteli. Zjednodušeně řečeno, správa zpráv v RabbitMQ probíhá následovně:
Zdroj obrázku: VMware
- Vydavatelé odesílají zprávy na výměnu;
- Výměna směruje zprávy do front a případně i dalších výměn;
- Po přijetí zprávy odešle RabbitMQ potvrzení odesílateli;
- Spotřebitelé udržují trvalé TCP připojení k RabbitMQ a deklarují, kterou frontu sledují;
- RabbitMQ pak doručuje zprávy konkrétním spotřebitelům;
- Spotřebitelé odesílají potvrzení o úspěšném nebo neúspěšném přijetí zprávy;
- Po úspěšném přijetí je zpráva odstraněna z fronty.
Apache Kafka
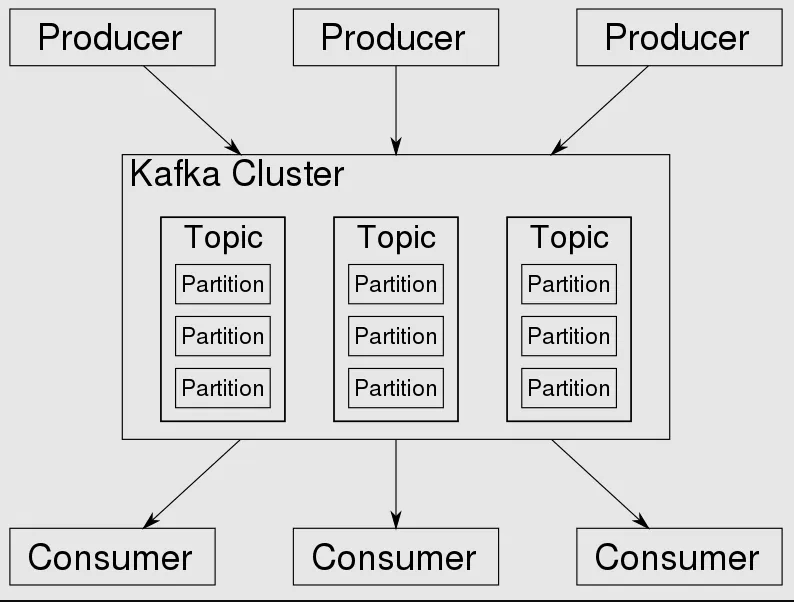
Apache Kafka je distribuované open-source řešení pro zasílání zpráv, které bylo vyvinuto společností LinkedIn. Využívá model vydavatel-odběratel a dokáže efektivně zpracovávat a ukládat velké objemy zpráv s vysokou škálovatelností a výkonem.

Pro ukládání událostí nebo přijatých zpráv se používají témata, která se rozdělují mezi uzly pomocí oddílů. Kafka kombinuje prvky modelu vydavatel-odběratel a front zpráv. Zajišťuje také pořadí zpráv pro každého spotřebitele.
Kafka se specializuje na vysokou propustnost dat a nízkou latenci při zpracování datových proudů v reálném čase. Toho dosahuje eliminací nadbytečné logiky na straně serveru (zprostředkovatele) a pomocí specifických implementačních detailů.
Například Kafka nepoužívá RAM a zapisuje data okamžitě do souborového systému serveru. Díky sekvenčnímu zápisu dat je dosaženo vysokého výkonu čtení i zápisu, srovnatelného s výkonem RAM.
Následující klíčové koncepty Kafky přispívají k její škálovatelnosti, výkonu a odolnosti proti chybám:
Téma
Téma slouží ke kategorizaci zpráv. Pro lepší představu si můžeme představit skříň s deseti zásuvkami, kde každá zásuvka představuje jedno téma. Celá skříň pak symbolizuje platformu Apache Kafka. Další analogií může být sloupec v relační databázi.
Producent
Producent je entita, která se připojuje k platformě pro zasílání zpráv a odesílá jednu nebo více zpráv na určité téma.
Spotřebitel
Spotřebitel je entita, která se připojuje k platformě pro zasílání zpráv a přijímá jednu nebo více zpráv na určité téma.
Zprostředkovatel (Broker)
Termín broker v kontextu Kafky označuje samotnou instanci Kafky, která spravuje témata, způsob ukládání zpráv, logy a další aspekty.
Cluster
Cluster představuje soubor zprostředkovatelů, kteří mohou, ale nemusí spolu vzájemně komunikovat za účelem zlepšení škálovatelnosti a odolnosti proti chybám.
Log soubor
Každé téma ukládá své záznamy v log souboru, tedy strukturovaným a sekvenčním způsobem. Tento soubor obsahuje informace o daném tématu.
Oddíly (Partitions)
Oddíly představují rozdělení zpráv v rámci tématu. Toto rozdělení je klíčové pro elasticitu, odolnost proti chybám a škálovatelnost Apache Kafka, protože každé téma může mít několik oddílů uložených na různých místech.
Architektura Apache Kafka
Kafka je založena na push modelu pro doručování zpráv. V tomto modelu jsou zprávy aktivně doručovány spotřebitelům. Zprávy se publikují do témat, která jsou rozdělena a distribuována mezi různé brokery v clusteru.
Spotřebitelé se pak mohou přihlásit k odběru jednoho nebo více témat a přijímat zprávy, jakmile se v daných tématech objeví nové záznamy.
V Kafce je každé téma rozděleno na jeden nebo více oddílů, do kterých se ukládají události.
Pokud cluster obsahuje více brokerů, oddíly se mezi nimi rovnoměrně rozdělí (v rámci možností), což umožňuje škálovat zátěž spojenou se zápisem i čtením z jednoho tématu současně na více brokerů. Pro synchronizaci v rámci clusteru se využívá ZooKeeper.
Kafka přijímá, uchovává a distribuuje záznamy. Záznam je datová jednotka vygenerovaná nějakým uzlem systému, která může reprezentovat událost nebo informaci. Záznam se odesílá do clusteru a ten jej uloží do příslušného tematického oddílu.
Každý záznam má sekvenční offset a spotřebitel může řídit, který offset aktuálně zpracovává. Pokud je tedy potřeba téma znovu zpracovat, lze se vrátit na dřívější offset.
 Zdroj obrázku: Wikipedie
Zdroj obrázku: Wikipedie
Logika, jako je správa ID poslední přečtené zprávy spotřebitelem nebo rozhodování o tom, do kterého oddílu se nově příchozí data zapisují, je přesunuta na klienta (producenta nebo spotřebitele).
Kromě pojmů producent a spotřebitel existují v Kafce i pojmy téma, rozdělení a replikace.
Téma popisuje kategorii zpráv. Kafka dosahuje odolnosti proti chybám pomocí replikace dat v tématu a škálovatelnosti pomocí rozdělení tématu na více serverů.
RabbitMQ vs. Kafka
Zásadní rozdíly mezi Apache Kafka a RabbitMQ vyplývají z odlišných modelů doručování zpráv, které tyto systémy implementují.
Apache Kafka funguje na principu tahání (pull), kdy si spotřebitelé sami načítají zprávy, které potřebují, z daného tématu.
RabbitMQ naopak implementuje push model, kdy se potřebné zprávy posílají přímo příjemcům. V důsledku toho se Kafka od RabbitMQ liší v následujících ohledech:
#1. Architektura
Jedním z hlavních rozdílů mezi RabbitMQ a Kafkou je jejich odlišná architektura. RabbitMQ používá tradiční architekturu front zpráv založenou na zprostředkovateli (brokeru), zatímco Kafka je postavena na architektuře distribuované streamovací platformy.
RabbitMQ také používá model doručování zpráv založený na stahování (pull), zatímco Kafka využívá model založený na push.
#2. Ukládání zpráv
RabbitMQ zařazuje zprávu do fronty FIFO (First Input – First Output) a sleduje její stav ve frontě. Kafka naopak přidává zprávu do logu (zápis na disk) a nechává příjemce, aby si sám zajistil načtení potřebných informací z daného tématu.
RabbitMQ odstraní zprávu po jejím doručení příjemci, zatímco Kafka uchovává zprávu, dokud není naplánováno vyčištění protokolu.
Díky tomu Kafka uchovává jak aktuální, tak i všechny předchozí stavy systému a na rozdíl od RabbitMQ může být využita jako spolehlivý zdroj historických dat.
#3. Vyrovnávání zátěže
Díky pull modelu doručování zpráv RabbitMQ dosahuje nízké latence. Nicméně existuje riziko, že příjemci budou zahlceni, pokud zprávy budou do fronty přicházet rychleji, než je stíhají zpracovávat.
Vzhledem k tomu, že v RabbitMQ si každý příjemce vyžádá/načte jiný počet zpráv, může dojít k nerovnoměrnému rozložení práce, což může způsobit zpoždění a ztrátu pořadí zpráv během zpracování.
Aby se tomu zabránilo, každý příjemce v RabbitMQ konfiguruje limit předběžného načtení, což je maximální počet nepotvrzených zpráv, které si může načíst. V Kafce se vyrovnávání zátěže provádí automaticky přerozdělením příjemců mezi jednotlivé oddíly tématu.
#4. Směrování
RabbitMQ nabízí čtyři různé způsoby směrování zpráv do různých výměn pro zařazení do front, což umožňuje robustní a flexibilní sadu vzorů pro zasílání zpráv. Kafka implementuje pouze jeden způsob zápisu zpráv na disk bez směrování.
#5. Pořadí zpráv
RabbitMQ umožňuje zachovat relativní pořadí v libovolných sadách (skupinách) událostí, zatímco Apache Kafka nabízí jednoduchý způsob, jak udržovat pořadí se škálovatelností pomocí sekvenčního zápisu zpráv do replikovaného protokolu (tématu).
| Funkce | RabbitMQ | Kafka |
| Architektura | Ukládá zprávy na disk připojený k brokerovi | Distribuovaná streamovací platforma |
| Model doručování | Založeno na tahu (pull) | Založeno na push |
| Ukládání zpráv | Neukládá zprávy | Udržuje pořadí zápisem do tématu |
| Vyrovnávání zátěže | Konfiguruje limit předběžného načtení | Provádí automaticky |
| Směrování | 4 způsoby | Směrování zpráv pouze do topicu |
| Externí procesy | Nevyžaduje | Vyžaduje spuštění instance Zookeeper |
| Pluginy | Několik pluginů | Má omezenou podporu pluginů |
RabbitMQ a Kafka jsou široce využívané systémy pro zasílání zpráv, každý s vlastními silnými stránkami a vhodnými případy použití. RabbitMQ je flexibilní, spolehlivý a škálovatelný systém, který exceluje v oblasti front zpráv, což z něj činí ideální volbu pro aplikace vyžadující spolehlivé a flexibilní doručování zpráv.
Kafka naopak představuje distribuovanou streamovací platformu, navrženou pro vysoce výkonné zpracování velkých objemů dat v reálném čase. To ji předurčuje pro aplikace vyžadující zpracování a analýzu dat v reálném čase.
Hlavní případy použití pro RabbitMQ:
Elektronický obchod

RabbitMQ se používá v aplikacích elektronického obchodování pro správu toku dat mezi různými systémy, jako je správa zásob, zpracování objednávek a plateb. Dokáže zpracovávat velké objemy zpráv a zajistit, že budou spolehlivě doručeny ve správném pořadí.
Zdravotnictví
Ve zdravotnictví se RabbitMQ využívá pro výměnu dat mezi různými systémy, například elektronickými zdravotními záznamy (EHR), zdravotnickými zařízeními a systémy pro podporu klinického rozhodování. Pomáhá zlepšovat péči o pacienty a omezovat chyby díky zajištění dostupnosti správných informací ve správný čas.
Finanční služby
RabbitMQ umožňuje zasílání zpráv v reálném čase mezi systémy, jako jsou obchodní platformy, systémy řízení rizik a platební brány. Pomáhá zajistit rychlé a bezpečné zpracování transakcí.
IoT systémy
RabbitMQ se používá v systémech internetu věcí (IoT) pro správu toku dat mezi různými zařízeními a senzory. Pomáhá zajistit bezpečné a efektivní doručování dat i v prostředích s omezenou šířkou pásma a přerušovaným připojením.
Kafka je distribuovaná streamovací platforma, která je navržena pro zpracování velkých objemů dat v reálném čase.
Hlavní případy použití pro Kafku
Analýza v reálném čase

Kafka se používá v analytických aplikacích pro zpracování a analýzu dat v reálném čase, což firmám umožňuje přijímat rozhodnutí na základě aktuálních informací. Dokáže zpracovávat obrovské objemy dat a škálovat se podle potřeb i těch nejnáročnějších aplikací.
Agregace protokolů
Kafka dokáže agregovat protokoly z různých systémů a aplikací, což firmám umožňuje monitorovat a odstraňovat problémy v reálném čase. Může být také použita pro ukládání protokolů za účelem dlouhodobé analýzy a generování reportů.
Strojové učení
Kafka se využívá v aplikacích strojového učení pro streamování dat do modelů v reálném čase. To umožňuje firmám vytvářet predikce a provádět akce na základě aktuálních informací. Může pomoci zvýšit přesnost a efektivitu modelů strojového učení.
Můj názor na RabbitMQ i Kafku
Flexibilní možnosti správy front zpráv v RabbitMQ mají za následek zvýšenou spotřebu zdrojů a snížení výkonu při vyšší zátěži. Přestože se jedná o řešení vhodné pro komplexní systémy, v mnoha případech je Apache Kafka lepším nástrojem pro správu zpráv.
Například v situaci, kdy je potřeba shromažďovat a agregovat události z desítek systémů a služeb s ohledem na geografické rozložení, metriky klientů, log soubory a analýzy s možností dalšího rozšíření, bych upřednostnil použití Kafky. Pokud ale potřebujete pouze rychlé zasílání zpráv, RabbitMQ bude fungovat dobře!
Můžete si také přečíst, jak nainstalovat Apache Kafka ve Windows a Linux.
