Stírání webu pomocí Pythonu: Průvodce krok za krokem
Web scraping, neboli extrahování dat z webových stránek, je koncept využívaný pro různé účely. Představte si, že potřebujete získat data z tabulky na webu, transformovat je do formátu JSON a následně využít tento JSON soubor pro interní nástroje. Právě díky web scrapingu můžete extrahovat cílená data z konkrétních elementů webové stránky. Python je oblíbenou volbou pro web scraping, neboť nabízí rozmanité knihovny jako BeautifulSoup a Scrapy, které efektivně zjednodušují proces extrakce dat.
Schopnost efektivní extrakce dat je zásadní dovedností pro vývojáře i datové vědce. Tento článek vám poskytne přehled o technikách efektivního web scrapingu a získávání požadovaného obsahu, se kterým můžete následně pracovat dle vašich potřeb. V tomto tutoriálu se zaměříme na balíček BeautifulSoup, který je populární volbou pro scraping dat v Pythonu.
Proč zvolit Python pro web scraping?
Python je pro mnoho vývojářů první volbou při vytváření webových scraperů. Existuje několik důvodů, proč se Python těší takové oblibě, ale v tomto článku si probereme tři hlavní důvody jeho využití pro scraping dat.
Podpora knihoven a komunity: Python nabízí několik vynikajících knihoven, jako jsou BeautifulSoup, Scrapy, Selenium a další, které poskytují skvělé funkce pro efektivní extrakci dat z webových stránek. Díky tomu se vyvinul silný ekosystém pro web scraping. Navíc, díky velkému počtu vývojářů používajících Python po celém světě, máte možnost rychle získat pomoc, když narazíte na problém.
Automatizace: Python je známý svými možnostmi automatizace. Pokud se snažíte vytvořit komplexní nástroj, který se spoléhá na scraping, budete potřebovat více než jen samotné získávání dat. Například, pokud chcete vytvořit nástroj pro sledování cen zboží v online obchodech, musíte přidat automatizaci pro denní sledování cen a ukládání do databáze. Python vám dává nástroje k snadné automatizaci těchto procesů.
Vizualizace dat: Web scraping je hojně využíván datovými vědci, kteří často potřebují extrahovat data z webových stránek. S pomocí knihoven jako Pandas, Python zjednodušuje vizualizaci dat z nezpracovaných zdrojů.
Knihovny pro web scraping v Pythonu
V Pythonu je dostupných několik knihoven, které usnadňují web scraping. Pojďme se podívat na tři nejpopulárnější z nich.
#1. BeautifulSoup
BeautifulSoup je jednou z nejoblíbenějších knihoven pro web scraping. Pomáhá vývojářům seškrábávat webové stránky již od roku 2004. Poskytuje jednoduché metody pro navigaci, vyhledávání a úpravu stromu analýzy. BeautifulSoup se také stará o kódování příchozích a odchozích dat. Je aktivně udržovaná a má silnou komunitu.
#2. Scrapy
Scrapy je další populární framework pro extrakci dat. Na GitHubu má přes 43 000 hvězdiček. Může být použit i pro získávání dat z API. Nabízí také několik zajímavých vestavěných funkcí, jako je odesílání e-mailů.
#3. Selenium
Selenium není primárně knihovna pro web scraping, nýbrž balíček pro automatizaci prohlížeče. Nicméně, jeho funkce lze snadno rozšířit pro účely web scrapingu. Pro ovládání různých prohlížečů využívá protokol WebDriver. Selenium je na trhu již téměř 20 let. Můžete ho využít pro automatizaci a scraping dat z webových stránek.
Výzvy při web scrapingu s Pythonem
Během snahy o získání dat z webových stránek se můžete setkat s různými překážkami. Mezi typické problémy patří pomalé sítě, nástroje proti scrapingu, blokování IP adres, captchy a další. Tyto překážky mohou značně zkomplikovat proces seškrábávání webových stránek.
Nicméně, tyto výzvy se dají efektivně obejít pomocí několika strategií. Například, webové stránky často blokují IP adresu, když je z ní odesláno příliš mnoho požadavků v krátkém časovém intervalu. Pro vyvarování se tohoto problému, je třeba škrabku nakódovat tak, aby po odeslání požadavku vyčkala určitou dobu.
Vývojáři také často umisťují "honeypot" pasti pro škrabky. Tyto pasti jsou pro lidské oko neviditelné, ale škrabka je může "prolézt". Pokud tedy scrapujete web, který má takovou past, musíte tomu svůj kód přizpůsobit.
Dalším zásadním problémem jsou captchy. Většina webových stránek dnes používá captcha pro ochranu před přístupem robotů. V takovém případě můžete zvážit použití řešičů captcha.
Seškrábání webu s Pythonem
Jak bylo zmíněno, pro demonstraci použijeme knihovnu BeautifulSoup. V tomto tutoriálu seškrábeme historická data Etherea z Coingecka a uložíme je ve formátu JSON. Přejděme k samotnému vývoji škrabky.
Prvním krokem je instalace BeautifulSoup a Requests. Pro tento tutoriál použiji Pipenv, správce virtuálního prostředí pro Python. Pokud preferujete, můžete použít Venv, nicméně Pipenv osobně preferuji. Detaily o Pipenv přesahují rámec tohoto tutoriálu. Nicméně, pokud se chcete dozvědět více o Pipenv, doporučuji tento průvodce. Pro více informací o virtuálních prostředích v Pythonu, navštivte tento průvodce.
V adresáři vašeho projektu spusťte prostředí Pipenv pomocí příkazu pipenv shell. Tím se aktivuje subshell ve vašem virtuálním prostředí. Nyní nainstalujte BeautifulSoup spuštěním příkazu:
pipenv install beautifulsoup4
A pro instalaci Requests spusťte podobný příkaz:
pipenv install requests
Po dokončení instalace importujte potřebné balíčky do vašeho hlavního souboru. Vytvořte soubor main.py a importujte knihovny takto:
from bs4 import BeautifulSoup import requests import json
Nyní získáme obsah stránky s historickými daty a parsujeme ho pomocí HTML parseru v BeautifulSoup.
r = requests.get('https://www.coingecko.com/en/coins/ethereum/historical_data#panel')
soup = BeautifulSoup(r.content, 'html.parser')
V kódu výše získáváme data z webu pomocí metody get z knihovny Requests. Parsed content je pak uložen do proměnné soup.
Teď přichází samotný proces scrapingu. Nejprve musíte správně identifikovat tabulku v DOM. Pokud si otevřete webovou stránku a prozkoumáte ji pomocí vývojářských nástrojů prohlížeče, zjistíte, že tabulka má tyto třídy: table-stripped text-sm text-lg-normal.
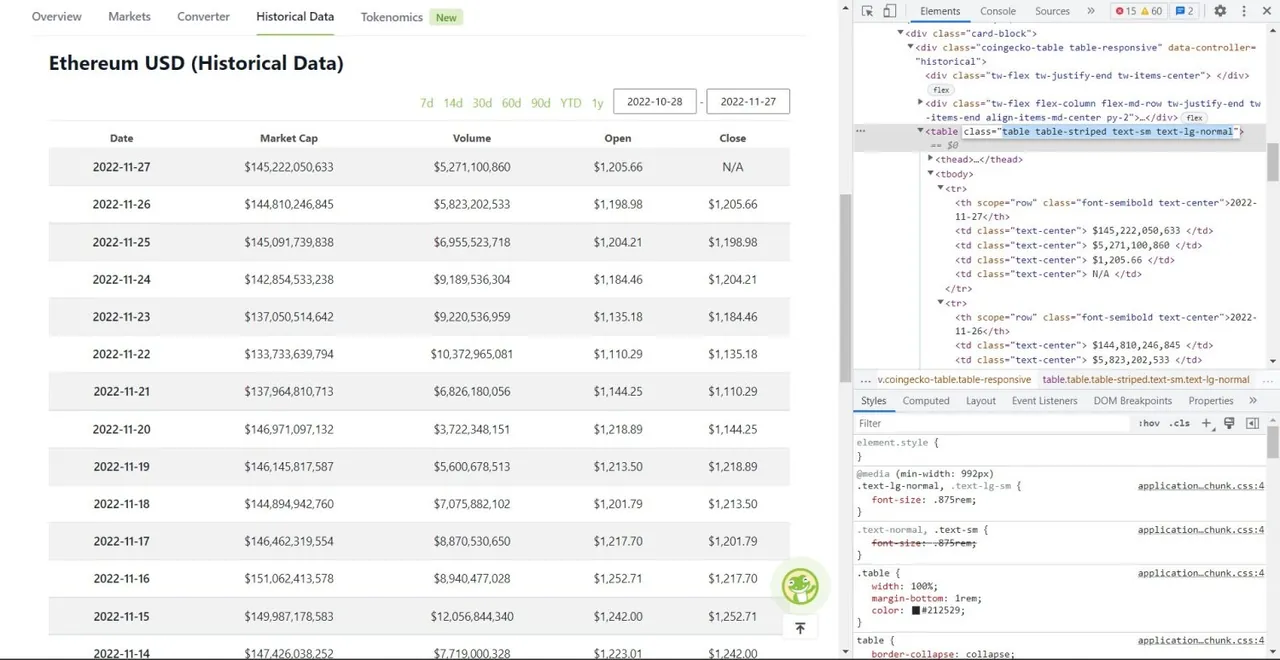
Pro cílení na tuto tabulku můžete použít metodu find.
table = soup.find('table', attrs={'class': 'table table-striped text-sm text-lg-normal'})
table_data = table.find_all('tr')
table_headings = []
for th in table_data[0].find_all('th'):
table_headings.append(th.text)
V tomto kódu, nejprve nalezneme tabulku pomocí soup.find, a následně hledáme všechny prvky tr uvnitř tabulky metodou find_all. Tyto prvky jsou uloženy v proměnné table_data. Tabulka má několik prvků pro nadpis. Nová proměnná table_headings je inicializovaná pro ukládání názvů v seznamu.
Následně se spustí cyklus for pro první řádek tabulky. V tomto řádku se vyhledají všechny prvky th a jejich textová hodnota se přidá do seznamu table_headings. Text se extrahuje pomocí metody text. Pokud si nyní vypíšete proměnnou table_headings, zobrazí se následující výstup:
['Date', 'Market Cap', 'Volume', 'Open', 'Close']
Dalším krokem je seškrábání zbylých prvků, vytvoření slovníku pro každý řádek a přidání těchto řádků do seznamu.
table_details = []
for tr in table_data:
th = tr.find_all('th')
td = tr.find_all('td')
data = {}
for i in range(len(td)):
data.update({table_headings[0]: th[0].text})
data.update({table_headings[i+1]: td[i].text.replace('n', '')})
if data.__len__() > 0:
table_details.append(data)
Toto je klíčová část kódu. Pro každý tr v table_data, se nejprve hledají prvky th. Prvky th reprezentují datum v tabulce. Tyto elementy se ukládají do proměnné th. Podobně všechny prvky td se ukládají do proměnné td.
Inicializuje se prázdný slovník data. Po inicializaci iterujeme přes rozsah prvků td. Pro každý řádek nejprve aktualizujeme první pole slovníku s prvním prvkem th. Kód table_headings[0]: th[0].text přiřazuje pár klíč-hodnota datum a první element.
Po inicializaci prvního prvku, se ostatní elementy přiřadí pomocí data.update({table_headings[i+1]: td[i].text.replace('n', '')}). Zde se text elementů td extrahuje metodou text, a následně se všechna n nahradí pomocí metody replace. Hodnota je pak přiřazena k i+1. prvku v seznamu table_headings, protože i. prvek je již přiřazen.
Pokud délka slovníku dat překročí nulu, přidáme tento slovník do seznamu table_details. Pro kontrolu si můžete tento seznam vypsat, ale my zapíšeme hodnoty do JSON souboru. Podívejme se na kód pro zápis do souboru:
with open('table.json', 'w') as f:
json.dump(table_details, f, indent=2)
print('Data saved to json file...')
Pro zápis hodnot do JSON souboru s názvem table.json, se používá metoda json.dump. Po dokončení zápisu se do konzole vypíše text Data saved to json file....
Nyní spusťte soubor pomocí příkazu:
python main.py
Po chvíli se v konzoli objeví text Data saved to json file.... V adresáři projektu uvidíte nový soubor table.json, který bude mít podobnou strukturu jako tento příklad:
[
{
"Date": "2022-11-27",
"Market Cap": "$145,222,050,633",
"Volume": "$5,271,100,860",
"Open": "$1,205.66",
"Close": "N/A"
},
{
"Date": "2022-11-26",
"Market Cap": "$144,810,246,845",
"Volume": "$5,823,202,533",
"Open": "$1,198.98",
"Close": "$1,205.66"
},
{
"Date": "2022-11-25",
"Market Cap": "$145,091,739,838",
"Volume": "$6,955,523,718",
"Open": "$1,204.21",
"Close": "$1,198.98"
},
// ...
// ...
]
Úspěšně jste implementovali webový škrabák s použitím Pythonu. Pro zobrazení kompletního kódu, navštivte toto GitHub repo.
Závěr
Tento článek se zabýval implementací jednoduchého webového scraperu v Pythonu. Ukázali jsme si, jak lze BeautifulSoup použít pro rychlé extrahování dat z webu. Diskutovali jsme o dalších dostupných knihovnách a o důvodech, proč je Python oblíbenou volbou pro web scraping mezi mnoha vývojáři.
Doporučujeme vám také prozkoumat další rámce pro web scraping.
