Úvodní příručka k MapReduce ve velkých datech
MapReduce představuje efektivní, rychlejší a ekonomicky výhodnější metodu pro vývoj aplikací.
Tento model využívá pokročilé principy jako paralelní zpracování a datovou lokalitu, čímž nabízí programátorům a organizacím řadu výhod.
Nicméně, vzhledem k množství dostupných programovacích modelů a rámců na trhu, je obtížné učinit správné rozhodnutí.
V oblasti zpracování velkých dat (Big Data) nemůžeme volit nahodile. Je nutné zvolit technologie, které si efektivně poradí s obrovskými objemy dat.
MapReduce se jeví jako vynikající řešení.
V tomto článku se podíváme na to, co MapReduce ve skutečnosti je a jaké benefity přináší.
Začněme!
Co je to MapReduce?
MapReduce je programovací model, respektive softwarový rámec v rámci Apache Hadoop. Je navržen pro tvorbu aplikací schopných paralelního zpracování rozsáhlých dat na tisících uzlech (nazývaných clustery nebo gridy) s vysokou odolností proti chybám a spolehlivostí.
Zpracování dat probíhá přímo v databázi nebo souborovém systému, kde jsou data uložena. MapReduce je kompatibilní se systémem souborů Hadoop (HDFS), což umožňuje přístup k velkým objemům dat a jejich správu.
Tento rámec, poprvé představený společností Google v roce 2004, získal popularitu díky projektu Apache Hadoop. Funguje jako vrstva zpracování neboli engine v Hadoopu, kde se spouštějí programy MapReduce vyvíjené v různých programovacích jazycích, včetně Java, C++, Pythonu a Ruby.
Programy MapReduce v cloud computingu běží paralelně, což z nich činí ideální nástroj pro analýzu dat v masivním měřítku.
MapReduce se zaměřuje na rozdělení úlohy na menší, dílčí úkoly pomocí funkcí „mapování“ a „redukce“. Každý dílčí úkol je nejprve mapován a následně redukován na ekvivalentní úkoly, což snižuje výpočetní zátěž a režii v síti clusteru.
Příklad: Představte si, že připravujete hostinu pro mnoho hostů. Pokud byste se snažili všechna jídla a procesy zvládnout sami, bylo by to vyčerpávající a časově náročné.
Avšak, pokud byste zapojili přátele či kolegy (nikoli hosty) do přípravy jídla a rozdělili si různé procesy, mohli byste úkoly provádět paralelně. V takovém případě byste připravili hostinu rychleji a snadněji, a to ještě za přítomnosti hostů.
MapReduce pracuje obdobně s distribuovanými úlohami a paralelním zpracováním, což umožňuje rychlejší a jednodušší způsob, jak dokončit daný úkol.
Apache Hadoop umožňuje programátorům využít MapReduce pro spouštění algoritmů na rozsáhlých distribuovaných souborech dat a používat pokročilé techniky strojového učení a statistiky pro hledání vzorců, predikce, nacházení korelací a další.
Charakteristiky MapReduce
Mezi klíčové charakteristiky MapReduce patří:
- Uživatelské rozhraní: Poskytuje intuitivní uživatelské rozhraní, které nabízí detailní informace o každém aspektu rámce. Pomáhá s konfigurací, aplikací a optimalizací vašich úloh.
- Užitečná zátěž: Aplikace používají rozhraní Mapper a Reducer pro spuštění mapování a redukce. Mapper převádí vstupní páry klíč-hodnota na mezilehlé páry klíč-hodnota. Reducer se používá k redukci těchto párů, které sdílejí stejný klíč, na jiné menší hodnoty. Provádí tři funkce – třídění, míchání a redukci.
- Partitioner: Řídí rozdělení mezilehlých klíčů pro výstup mapy.
- Reportér: Zajišťuje hlášení průběhu, aktualizaci čítačů a nastavování stavových zpráv.
- Čítače: Jsou globální čítače definované aplikací MapReduce.
- OutputCollector: Tato funkce shromažďuje výstupní data z Mapperu nebo Reduceru namísto mezivýstupů.
- RecordWriter: Zapisuje výstupní data nebo páry klíč-hodnota do výstupního souboru.
- DistributedCache: Efektivně distribuuje větší soubory určené pouze pro čtení, které jsou specifické pro danou aplikaci.
- Komprese dat: Umožňuje komprimaci výstupů úloh i přechodných výstupů map.
- Přeskakování chybných záznamů: Během zpracování mapových vstupů je možné přeskočit chybné záznamy. Tuto funkci lze ovládat prostřednictvím třídy SkipBadRecords.
- Ladění: Nabízí možnost spouštět uživatelsky definované skripty a povolit ladění. Pokud úloha v MapReduce selže, lze spustit ladicí skript pro nalezení problémů.
Architektura MapReduce
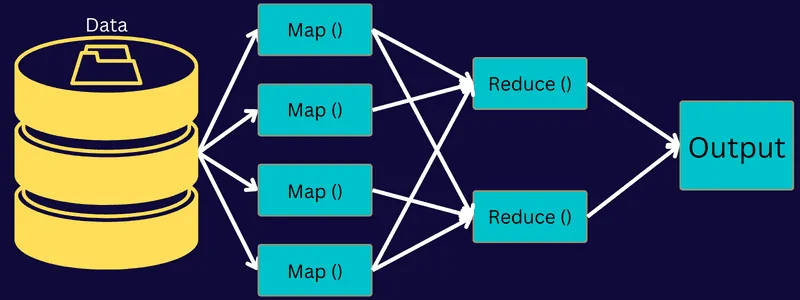
Pojďme si rozebrat architekturu MapReduce a prozkoumat její jednotlivé komponenty:
- Úloha: Úloha v MapReduce představuje konkrétní úkol, který chce klient MapReduce provést. Skládá se z několika menších úkolů, které se spojí do konečné úlohy.
- Server historie úloh: Je to démonický proces, který ukládá historická data o aplikaci či úloze, například protokoly generované před a po provedení úlohy.
- Klient: Klient (program nebo API) odesílá úlohu do MapReduce ke spuštění a zpracování. V MapReduce může jeden nebo více klientů průběžně odesílat úlohy do správce MapReduce ke zpracování.
- MapReduce Master: Rozděluje úlohu na několik menších částí a zajišťuje, že jednotlivé úkoly probíhají současně.
- Části úlohy: Dílčí úlohy získané rozdělením hlavní úlohy. Tyto dílčí úlohy jsou zpracovány a následně sloučeny do konečné úlohy.
- Vstupní data: Datová sada, která je poskytována do MapReduce pro zpracování úloh.
- Výstupní data: Konečný výsledek, který je získán po zpracování úlohy.
Architektura tedy funguje tak, že klient odesílá úlohu správci MapReduce, který ji rozloží na menší, stejně velké části. To umožňuje rychlejší zpracování úlohy, protože menší úkoly se zpracují rychleji než velké.
Je však třeba dávat pozor na to, aby úlohy nebyly rozděleny na příliš malé části, protože v takovém případě by mohla narůstat režie na správu rozdělení a tím i ztráta času.
Dále jsou zpřístupněny části úlohy, aby mohly být provedeny úkoly Map a Reduce. Pro úkoly Map a Reduce je navíc k dispozici vhodný program, který závisí na konkrétním případu použití. Programátor vyvíjí kód, který je založen na logice a splňuje dané požadavky.
Vstupní data jsou následně předána do úlohy Map, která generuje výstup ve formě páru klíč-hodnota. Namísto ukládání dat na HDFS se pro jejich uložení používá lokální disk, čímž se eliminuje možnost replikace.
Po dokončení úlohy lze výstup zahodit. Replikace by v případě ukládání na HDFS byla nadbytečná. Výstup z každé mapové úlohy je dále předáván do redukční úlohy a výstup mapy je poskytnut počítači, na kterém běží redukční úloha.
Dále je výstup sloučen a předán do uživatelsky definované redukční funkce. Nakonec je zredukovaný výstup uložen na HDFS.
V závislosti na konečném cíli může proces zahrnovat několik mapových a redukčních úloh pro zpracování dat. Algoritmy Map a Reduce jsou optimalizovány pro minimalizaci časové a prostorové složitosti.
Vzhledem k tomu, že MapReduce primárně zahrnuje úkoly Map a Reduce, je důležité jim blíže porozumět. Proto si nyní probereme jednotlivé fáze MapReduce, abychom si o těchto tématech vytvořili jasnější představu.
Fáze MapReduce
Mapování
V této fázi jsou vstupní data mapována na výstup ve formě párů klíč-hodnota. Klíč může odkazovat na ID adresy, zatímco hodnota na skutečnou hodnotu této adresy.
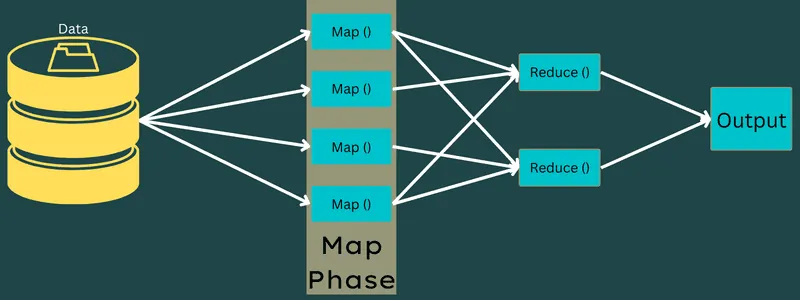
Tato fáze zahrnuje dva úkoly: rozdělení a mapování. Rozdělení znamená oddělení dílčích částí nebo částí zakázky od hlavní zakázky. Tyto části jsou také označovány jako vstupní rozdělení. Vstupní rozdělení lze tedy chápat jako vstupní blok spotřebovaný mapou.
Dále následuje úkol mapování. Ten je považován za první fázi při provádění programu pro mapovou redukci. Data obsažená v každém rozdělení jsou zde předána mapové funkci ke zpracování a vygenerování výstupu.
Funkce Map() se provádí v paměti nad vstupními páry klíč-hodnota a generuje mezilehlé páry klíč-hodnota. Tento nový pár klíč-hodnota slouží jako vstup pro funkci Reduce() nebo Reducer.
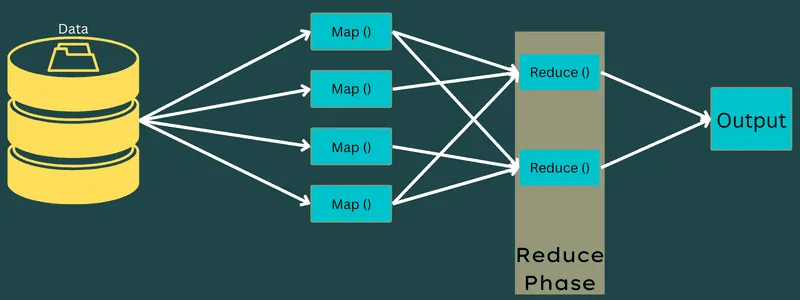
Redukce
Mezilehlé páry klíč-hodnota získané ve fázi mapování fungují jako vstup pro funkci Reduce neboli Reducer. Podobně jako ve fázi mapování se jedná o dva úkoly: míchání a redukce.
Získané páry klíč-hodnota jsou tedy tříděny a míchány, aby byly předány do reduktoru. Dále reduktor seskupuje a agreguje data podle svého páru klíč-hodnota na základě redukčního algoritmu, který napsal vývojář.
V této fázi jsou hodnoty z fáze míchání kombinovány pro vrácení výstupní hodnoty. Tato fáze shrnuje celou datovou sadu.
Nyní je celý proces provádění úloh Map a Reduce řízen některými entitami. Těmi jsou:
- Job Tracker: Zjednodušeně řečeno, Job Tracker funguje jako řídící jednotka, která je zodpovědná za kompletní provedení odeslané úlohy. Job Tracker spravuje všechny úlohy a zdroje v rámci clusteru. Kromě toho Job Tracker plánuje každou mapu přidanou do Task Tracker, která běží na konkrétním datovém uzlu.
- Multiple Task Trackers: Task Trackers fungují jako vykonavatelé, kteří provádí úlohy podle pokynů Job Trackeru. Task Tracker je nasazen na každý uzel v clusteru a provádí úkoly Map a Reduce.
Funguje to tak, že úloha je rozdělena na několik úloh, které běží na různých datových uzlech v clusteru. Job Tracker je zodpovědný za koordinaci úlohy tím, že plánuje úkoly a spouští je na více datových uzlech. Task Tracker, umístěný na každém datovém uzlu, provádí části úlohy a spravuje jednotlivé úkoly.
Task Tracker navíc odesílají zprávy o průběhu do Job Tracker. Task Tracker také pravidelně vysílá signál "srdce" do Job Tracker a informuje ho o stavu systému. V případě selhání je Job Tracker schopen přeplánovat úlohu na jiném Task Trackeru.
Výstupní fáze: V této fázi jsou generovány poslední páry klíč-hodnota z Reduceru. K převodu párů klíč-hodnota a jejich zápisu do souboru pomocí RecordWriter lze použít formátovač výstupu.
Proč používat MapReduce?
Zde jsou některé z výhod MapReduce, které vysvětlují, proč byste ho měli používat ve vašich aplikacích pro velká data:
Paralelní zpracování

Úlohu lze rozdělit mezi různé uzly, kde každý uzel současně zpracovává část dané úlohy v MapReduce. Rozdělení velkých úkolů na menší tak snižuje složitost. Vzhledem k tomu, že různé úlohy běží paralelně na různých strojích místo na jednom stroji, zpracování dat trvá podstatně méně času.
Lokalita dat
V MapReduce lze přesunout procesní jednotku k datům, nikoli naopak.
Tradiční metody vyžadovaly přenos dat do zpracovatelské jednotky. S rychlým nárůstem objemu dat však tento postup začal představovat mnohé problémy. Mezi ně patří vyšší náklady, časová náročnost, zatížení hlavního uzlu, časté poruchy a snížení výkonu sítě.
MapReduce však pomáhá tyto problémy překonat díky obrácenému přístupu – přivedení procesní jednotky k datům. Tímto způsobem jsou data distribuována mezi různé uzly, kde každý uzel může zpracovat část uložených dat.
Díky tomu je systém nákladově efektivní a snižuje dobu zpracování, protože každý uzel pracuje paralelně s odpovídající datovou částí. Navíc, protože každý uzel zpracovává pouze část dat, nedochází k přetížení žádného uzlu.
Bezpečnost

Model MapReduce nabízí vyšší bezpečnost. Pomáhá chránit vaši aplikaci před neoprávněnými daty a zároveň zvyšuje zabezpečení clusteru.
Škálovatelnost a flexibilita
MapReduce je vysoce škálovatelný rámec. Umožňuje spouštět aplikace z několika strojů za použití dat o velikosti tisíců terabajtů. Nabízí také flexibilitu při zpracování dat, která mohou být strukturovaná, polostrukturovaná nebo nestrukturovaná, v jakémkoli formátu a velikosti.
Jednoduchost
Programy MapReduce lze psát v libovolném programovacím jazyce, jako je Java, R, Perl, Python a další. Proto se je snadné naučit a psát programy, které splňují požadavky na zpracování dat.
Případy použití MapReduce
- Fulltextové indexování: MapReduce se využívá k provádění fulltextového indexování. Jeho Mapper může mapovat každé slovo nebo frázi v jednom dokumentu. Reducer se pak používá k zápisu všech mapovaných prvků do indexu.
- Výpočet Pagerank: Google používá MapReduce pro výpočet Pagerank.
- Analýza protokolů: MapReduce dokáže analyzovat soubory protokolů. Může rozdělit velký soubor protokolů na různé části (rozdělit), zatímco Mapper hledá přístupné webové stránky.
Pokud je v protokolu nalezena webová stránka, je předán pár klíč-hodnota do Reduceru. Klíčem je webová stránka a hodnotou je index "1". Po předání páru klíč-hodnota do Reduceru jsou různé webové stránky agregovány. Konečným výstupem je celkový počet přístupů pro každou webovou stránku.

- Reverse Web-Link Graph: Rámec také nachází uplatnění v reverzním grafu webových odkazů. Zde Map() poskytne cílovou URL a zdroj a převezme vstup ze zdroje nebo webové stránky.
Funkce Reduce() následně agreguje seznam všech zdrojových URL adres spojených s cílovou URL adresou. Nakonec vypíše zdroje a cíle.
- Počítání slov: MapReduce se používá k počítání, kolikrát se slovo vyskytuje v daném dokumentu.
- Globální oteplování: Organizace, vlády a společnosti mohou využívat MapReduce k řešení problémů globálního oteplování.
Například, pokud byste chtěli zjistit zvýšení teploty oceánu v důsledku globálního oteplování, můžete shromáždit tisíce dat z celého světa. Data mohou zahrnovat vysokou a nízkou teplotu, zeměpisnou šířku, délku, datum, čas atd. Zpracování takového množství dat by vyžadovalo několik mapových a redukčních úloh pro výpočet výstupu pomocí MapReduce.
- Drogové studie: Tradičně datařští vědci a matematici spolupracovali na vytvoření nového léku, který by dokázal bojovat s nemocí. Díky rozšíření algoritmů a MapReduce mohou IT oddělení v organizacích snadno řešit problémy, které dříve řešily pouze superpočítače nebo Ph.D. vědci. Nyní je například možné ověřit účinnost léku u skupiny pacientů.
- Další aplikace: MapReduce je schopen zpracovat rozsáhlá data, která se nevejdou do relační databáze. Využívá také nástroje datové vědy a umožňuje je spouštět na různých distribuovaných datových sadách, což bylo dříve možné pouze na jednom počítači.
Díky své robustnosti a jednoduchosti nachází MapReduce uplatnění v armádě, obchodu, vědě atd.
Závěr
MapReduce se může stát průlomovou technologií. Nejenže se jedná o rychlejší a jednodušší proces, ale je také nákladově efektivní a méně časově náročný. Vzhledem k jeho výhodám a rostoucímu využití se zdá být pravděpodobné, že se bude těšit stále většímu přijetí v různých odvětvích a organizacích.
Doporučujeme vám prozkoumat některé z nejlepších zdrojů, které vám pomohou se naučit Big Data a Hadoop.
