

Pandas je nejoblíbenější knihovna pro analýzu dat pro Python. Je široce používán datovými analytiky, datovými vědci a inženýry strojového učení.
Spolu s NumPy je to jedna z knihoven a nástrojů, které musí znát každý, kdo pracuje s daty a AI.
V tomto článku prozkoumáme Pandy a funkce, díky kterým je v datovém ekosystému tak populární.
Table of Contents
Co je to Pandas?
Pandas je knihovna pro analýzu dat pro Python. To znamená, že se používá k práci a manipulaci s daty z vašeho kódu Pythonu. S Pandas můžete efektivně číst, manipulovat, vizualizovat, analyzovat a ukládat data.
Název „Pandas“ pochází ze spojení slov Panel Data, což je termín z ekonometrie, který se vztahuje k údajům získaným pozorováním více jedinců v průběhu času. Pandas byla původně vydána v lednu 2008 Wesem Kinneym a od té doby se stala nejoblíbenější knihovnou pro svůj případ použití.
V srdci Pandas jsou dvě základní datové struktury, které byste měli znát, Dataframes a Series. Když vytvoříte nebo načtete datovou sadu v Pandas, je reprezentována jako jedna z těchto dvou datových struktur.
V další části prozkoumáme, jaké to jsou, jak se liší a kdy je použití jednoho z nich ideální.
Klíčové datové struktury
Jak již bylo zmíněno dříve, všechna data v Pandas jsou reprezentována pomocí jedné ze dvou datových struktur, Dataframe nebo Series. Tyto dvě datové struktury jsou podrobně vysvětleny níže.
Datový rámec
Tento příklad datového rámce byl vytvořen pomocí fragmentu kódu v dolní části této sekce
Dataframe v Pandas je dvourozměrná datová struktura se sloupci a řádky. Je to podobné jako tabulka v tabulkové aplikaci nebo tabulka v relační databázi.
Skládá se ze sloupců a každý sloupec představuje atribut nebo funkci ve vaší datové sadě. Tyto sloupce jsou pak tvořeny jednotlivými hodnotami. Tento seznam nebo řada jednotlivých hodnot je reprezentována jako objekty řady. Strukturu dat Series podrobněji probereme dále v tomto článku.
Sloupce v datovém rámci mohou mít popisné názvy, takže jsou od sebe odlišené. Tyto názvy jsou přiřazeny při vytváření nebo načítání datového rámce, ale lze je kdykoli snadno přejmenovat.
Hodnoty ve sloupci musí být stejného datového typu, i když sloupce nemusí obsahovat data stejného typu. To znamená, že sloupec názvu v datové množině bude ukládat výhradně řetězce. Ale stejná datová sada může mít další sloupce, jako je věk, které ukládají ints.
Datové rámce mají také index používaný k odkazování na řádky. Hodnoty v různých sloupcích, ale se stejným indexem tvoří řádek. Ve výchozím nastavení jsou indexy číslovány, ale lze je znovu přiřadit tak, aby vyhovovaly datové sadě. V příkladu (obrázek výše, kódovaný níže) nastavíme sloupec indexu na sloupec „měsíce“.
import pandas as pd
sales_df = pd.DataFrame({
'Month': ['January', 'February', 'March'],
'Jane Doe': [5000, 6000, 5500],
'John Doe': [4500, 6700, 6000]
})
sales_df.set_index(['Month'], inplace=True)
print(sales_df)
Série
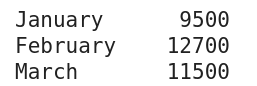 Tato ukázková řada byla vytvořena pomocí kódu v dolní části této sekce
Tato ukázková řada byla vytvořena pomocí kódu v dolní části této sekce
Jak bylo uvedeno výše, řada se používá k reprezentaci sloupce dat v Pandas. Řada je tedy jednorozměrná datová struktura. To je na rozdíl od datového rámce, který je dvourozměrný.
Ačkoli se řada běžně používá jako sloupec v datovém rámci, může také sama o sobě představovat kompletní datovou sadu za předpokladu, že datová sada má pouze jeden atribut zaznamenaný v jednom sloupci. Nebo spíše, datová sada je jednoduše seznam hodnot.
Protože řada je pouze jeden sloupec, nemusí mít název. Hodnoty v řadě jsou však indexovány. Stejně jako index datového rámce lze datový rámec řady upravit z výchozího číslování.
V příkladu (obrázek výše, kódovaný níže) byl index nastaven na různé měsíce pomocí metody set_axis objektu Pandas Series.
import pandas as pd total_sales = pd.Series([9500, 12700, 11500]) months = ['January', 'February', 'March'] total_sales = total_sales.set_axis(months) print(total_sales)
Vlastnosti pand
Nyní, když máte dobrou představu o tom, co Pandas je a jaké klíčové datové struktury využívá, můžeme začít diskutovat o funkcích, díky nimž je Pandas tak výkonnou knihovnou pro analýzu dat a v důsledku toho neuvěřitelně populární v rámci Data Science a Machine Learning. Ekosystémy.
#1. Manipulace s daty
Objekty Dataframe a Series jsou měnitelné. Podle potřeby můžete přidávat nebo odebírat sloupce. Kromě toho vám Pandas umožňuje přidávat řádky a dokonce slučovat datové sady.
Můžete provádět numerické výpočty, jako je normalizace dat a logická porovnání po jednotlivých prvcích. Pandas také umožňuje seskupovat data a aplikovat agregované funkce, jako je průměr, průměr, maximum a min. Díky tomu je práce s daty v Pandas hračkou.
#2. Čištění dat
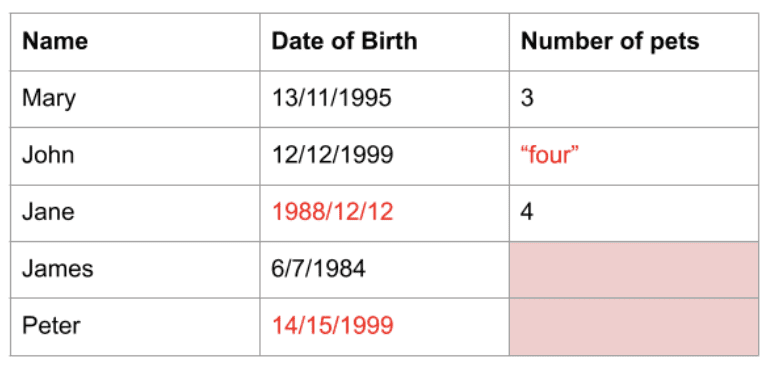
Data získaná z reálného světa mají často hodnoty, které ztěžují práci nebo nejsou ideální pro analýzu nebo použití v modelech strojového učení. Data mohou být nesprávného datového typu, ve špatném formátu nebo mohou úplně chybět. Ať tak či onak, tato data potřebují předběžné zpracování, které se nazývá čištění, než je lze použít.
Pandas má funkce, které vám pomohou vyčistit vaše data. Například v Pandas můžete odstranit duplicitní řádky, vypustit sloupce nebo řádky s chybějícími daty a nahradit hodnoty buď výchozími hodnotami, nebo nějakou jinou hodnotou, jako je průměr sloupce. Existuje více funkcí a knihoven, které spolupracují s Pandas a umožňují vám provádět více čištění dat.
#3. Vizualizace dat
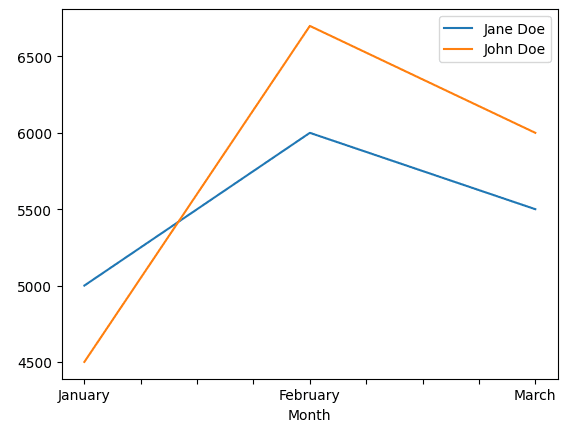 Tento graf byl vygenerován pomocí kódu pod touto částí
Tento graf byl vygenerován pomocí kódu pod touto částí
I když se nejedná o vizualizační knihovnu jako Matplotlib, Pandas má funkce pro vytváření základních vizualizací dat. A přestože jsou základní, ve většině případů svou práci odvedou.
S Pandas můžete snadno vykreslovat sloupcové grafy, histogramy, rozptylové matice a další různé typy grafů. Zkombinujte to s některými manipulacemi s daty, které můžete provádět v Pythonu, a můžete vytvářet ještě složitější vizualizace, abyste lépe porozuměli vašim datům.
import pandas as pd
sales_df = pd.DataFrame({
'Month': ['January', 'February', 'March'],
'Jane Doe': [5000, 6000, 5500],
'John Doe': [4500, 6700, 6000]
})
sales_df.set_index(['Month'], inplace=True)
sales_df.plot.line()
#4. Analýza časových řad
Pandy také podporují práci s daty s časovým razítkem. Když Pandas rozpozná sloupec jako sloupec s hodnotami datetime, můžete na stejném sloupci provádět mnoho operací, které jsou užitečné při práci s daty časových řad.
Patří mezi ně seskupování pozorování podle časového období a aplikace agregovaných funkcí na ně, jako je součet nebo průměr nebo získání nejstarších nebo nejnovějších pozorování pomocí min a max. S daty časových řad v Pandas můžete samozřejmě dělat mnohem více věcí.
#5. Vstup/výstup v Pandas
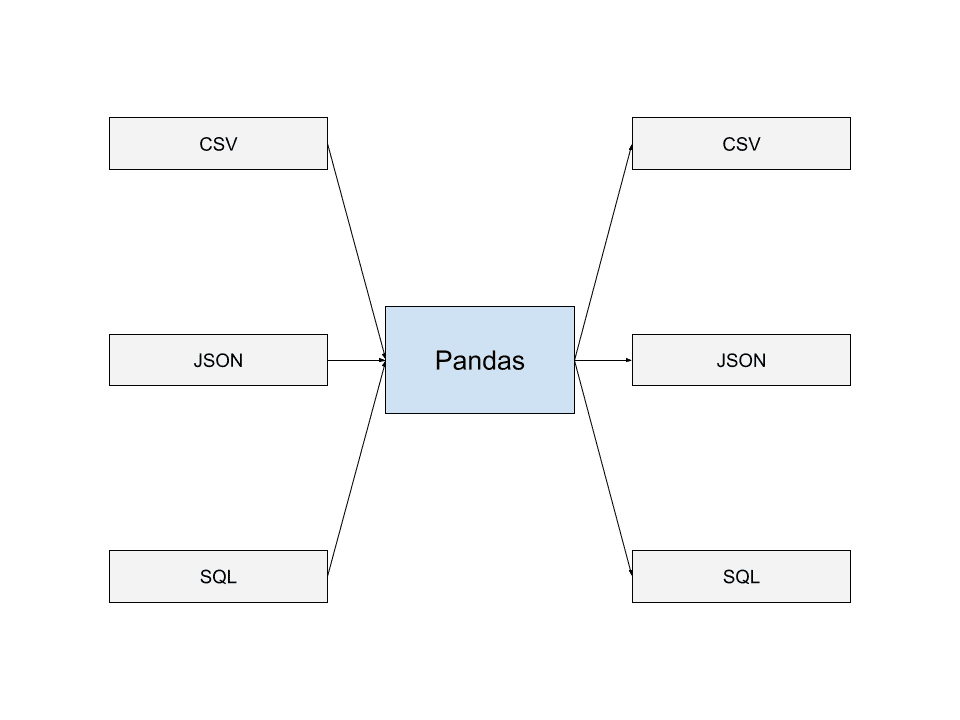
Pandas je schopen číst data z nejběžnějších formátů pro ukládání dat. Patří mezi ně JSON, SQL výpisy a CSV. Můžete také zapisovat data do souborů v mnoha z těchto formátů.
Tato schopnost číst a zapisovat do různých formátů datových souborů umožňuje Pandám bezproblémovou spolupráci s jinými aplikacemi a vytváření datových kanálů, které se dobře integrují s Pandas. To je jeden z důvodů, proč jsou Pandy hojně využívány mnoha vývojáři.
#6. Integrace s jinými knihovnami
Pandas má také bohatý ekosystém nástrojů a knihoven vybudovaných na jeho vrcholu, které doplňují jeho funkčnost. To z ní dělá ještě výkonnější a užitečnější knihovnu.
Nástroje v rámci ekosystému Pandas rozšiřují jeho funkčnost v různých oblastech, včetně čištění dat, vizualizace, strojového učení, vstupu/výstupu a paralelizace. Pandas udržuje registr takových nástrojů ve své dokumentaci.
Úvahy o výkonu a účinnosti v Pandách
Zatímco Pandy ve většině operací září, mohou být notoricky pomalé. Světlou stránkou je, že můžete optimalizovat svůj kód a zlepšit jeho rychlost. Chcete-li to provést, musíte pochopit, jak jsou Pandy stavěny.
Pandas je postaven na NumPy, oblíbené knihovně Pythonu pro numerické a vědecké výpočty. Proto, stejně jako NumPy, Pandas pracuje efektivněji, když jsou operace vektorizovány, na rozdíl od vybírání jednotlivých buněk nebo řádků pomocí smyček.
Vektorizace je forma paralelizace, kde je stejná operace aplikována na více datových bodů najednou. Toto je označováno jako SIMD – Single Instruction, Multiple Data. Využití vektorizovaných operací dramaticky zvýší rychlost a výkon Pand.
Protože pod kapotou používají pole NumPy, datové struktury DataFrame a Series jsou rychlejší než jejich alternativní slovníky a seznamy.
Výchozí implementace Pandas běží pouze na jednom jádru CPU. Dalším způsobem, jak urychlit svůj kód, je použití knihoven, které umožňují Pandám využít všechna dostupná jádra CPU. Patří mezi ně Dask, Vaex, Modin a IPython.
Komunita a zdroje
Pandas je oblíbenou knihovnou nejoblíbenějšího programovacího jazyka a má velkou komunitu uživatelů a přispěvatelů. V důsledku toho existuje mnoho zdrojů, které lze použít, abyste se naučili, jak jej používat. Patří mezi ně oficiální dokumentace Pandas. Existuje ale také nespočet kurzů, návodů a knih, ze kterých se můžete učit.
Existují také online komunity na platformách, jako je Reddit v subredditech r/Python a r/Data Science, kde můžete klást otázky a získávat odpovědi. Protože se jedná o knihovnu s otevřeným zdrojovým kódem, můžete nahlásit problémy na GitHubu a dokonce přispívat kódem.
Závěrečná slova
Pandas je neuvěřitelně užitečná a výkonná jako datová vědecká knihovna. V tomto článku jsem se pokusil vysvětlit jeho popularitu tím, že jsem prozkoumal funkce, které z něj dělají oblíbený nástroj pro datové vědce a programátory.
Dále se podívejte, jak vytvořit Pandas DataFrame.