Federované učení představuje odklon od tradičních postupů sběru dat a trénování modelů strojového učení. Nabízí alternativní přístup, který upřednostňuje soukromí a efektivitu.
Díky federovanému učení se vývojáři strojového učení mohou těšit z nákladově efektivnějšího trénování, které zároveň chrání data uživatelů. Tento článek se zaměří na definici federovaného učení, princip jeho fungování, oblasti využití a dostupné frameworky.
Co je to federované učení?
Zdroj: Wikipedie
Federované učení je inovativní přístup k trénování modelů strojového učení. Na rozdíl od tradičního modelu, kde se data od různých klientů shromažďují v centrálním úložišti, federované učení funguje na principu opačném. V klasickém přístupu se modely trénují z dat v centrálním úložišti a následně se používají pro predikce. Naproti tomu federované učení umožňuje klientům trénovat modely přímo na svých lokálních datech. Tímto způsobem se citlivá data neodesílají na centrální server, čímž je zajištěna jejich ochrana.
Přečtěte si také: Vysvětlení nejlepších modelů strojového učení
Jak federované učení funguje?
Proces učení ve federovaném učení se skládá z opakovaných kroků, nazývaných tréninková kola, které postupně vylepšují model. Typický postup zahrnuje iteraci těchto kol, přičemž každé kolo se skládá z několika fází.
Typické tréninkové kolo
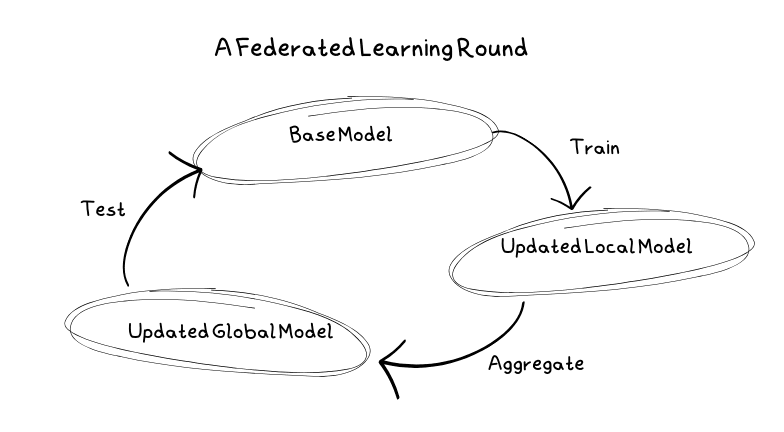
Nejprve server vybere model, který se má trénovat, a definuje hyperparametry, jako je počet tréninkových kol, počet klientů a jejich zastoupení v každém kole. Současně je model inicializován s počátečními parametry, které tvoří základní model.
Následně klienti obdrží kopie tohoto základního modelu, na kterých provádějí trénování s využitím svých lokálních dat. Tím je zajištěno, že jejich citlivé informace se nedostanou na servery.
Po trénování na lokálních datech klienti odesílají aktualizace modelu zpět na server. Server tyto aktualizace zprůměruje a vytvoří nový základní model. Jelikož klienti nemusejí být vždy spolehliví, může se stát, že ne všichni zašlou své aktualizace. V tomto případě server tyto možné výpadky ošetří.
Před nasazením nového základního modelu je nutné jej otestovat. Server ovšem data neukládá, proto se model odešle zpět klientům, kteří jej otestují s využitím svých lokálních dat. Pokud je model lepší než předchozí, je přijat a používán dále.
Zde je užitečný průvodce od týmu federovaného učení společnosti Google AI, který popisuje princip fungování federovaného učení.
Centralizované vs. federované vs. heterogenní
V tomto nastavení je centrální server zodpovědný za koordinaci celého procesu učení. Tento přístup je označován jako centralizované federované učení.
Opakem centralizovaného učení je decentralizované federované učení, ve kterém si klienti vyměňují informace peer-to-peer.
Další variantou je heterogenní učení, kde klienti nemusejí mít nutně stejnou architekturu globálního modelu.
Výhody federovaného učení
- Největší výhodou federovaného učení je ochrana citlivých dat. Klienti sdílejí pouze výsledky trénování, nikoli data použitá během procesu. Navíc lze zavést protokoly, které agregují výsledky tak, aby je nebylo možné spojit s konkrétním klientem.
- Snižuje se datová zátěž sítě, protože se mezi klientem a serverem nevyměňují žádná data, pouze aktualizace modelů.
- Snižují se náklady na trénink modelů, protože není potřeba kupovat specializovaný drahý hardware. Místo toho se k trénování modelů používá hardware klienta. A vzhledem k omezenému množství zpracovávaných dat to pro klienty nepředstavuje žádnou zátěž.
Nevýhody federovaného učení
- Tento model závisí na účasti velkého množství různých uzlů, které vývojář nemusí mít pod kontrolou, což ovlivňuje spolehlivost tréninkového procesu.
- Klienti, na kterých se modely trénují, obvykle nemají k dispozici výkonné GPU, jedná se o běžná zařízení jako telefony. A tyto zařízení nemusí být, ani když je jich mnoho, dostatečně výkonná ve srovnání s clustery GPU.
- Federované učení předpokládá, že všechny klientské uzly jsou důvěryhodné a pracují pro obecné blaho. Nicméně, někteří klienti mohou být škodliví a posílat špatné aktualizace, které mohou ovlivnit výsledek trénování.
Aplikace federovaného učení
Federované učení umožňuje efektivní trénování modelů se zachováním soukromí uživatelů, což je užitečné v mnoha oblastech:
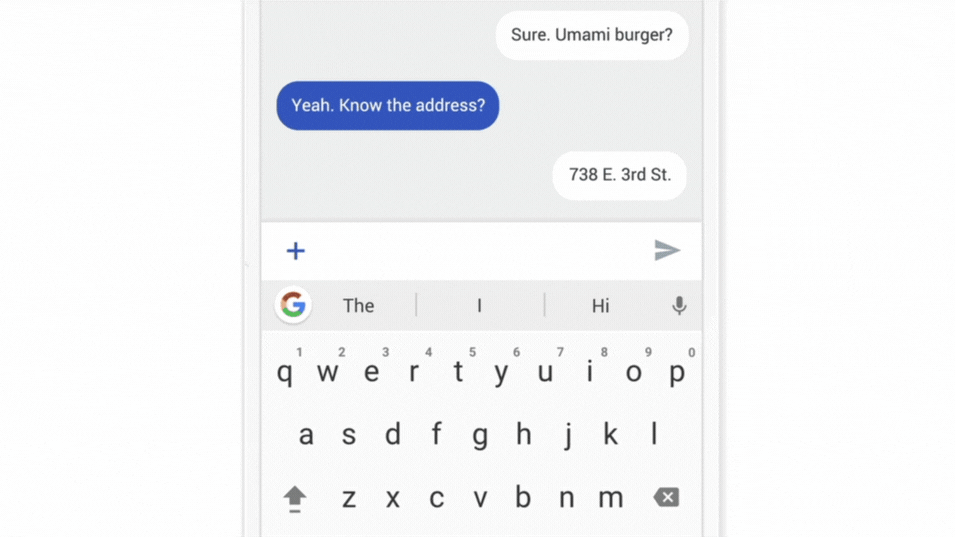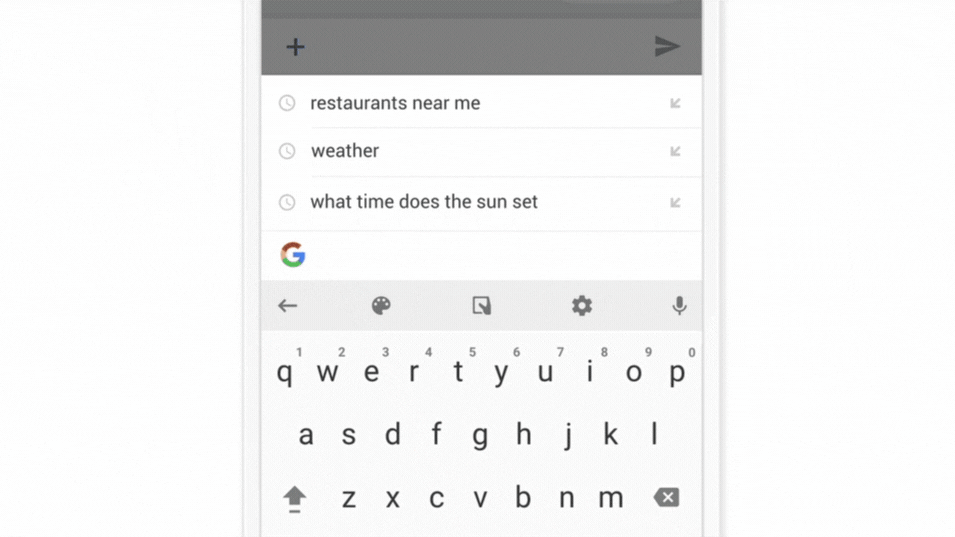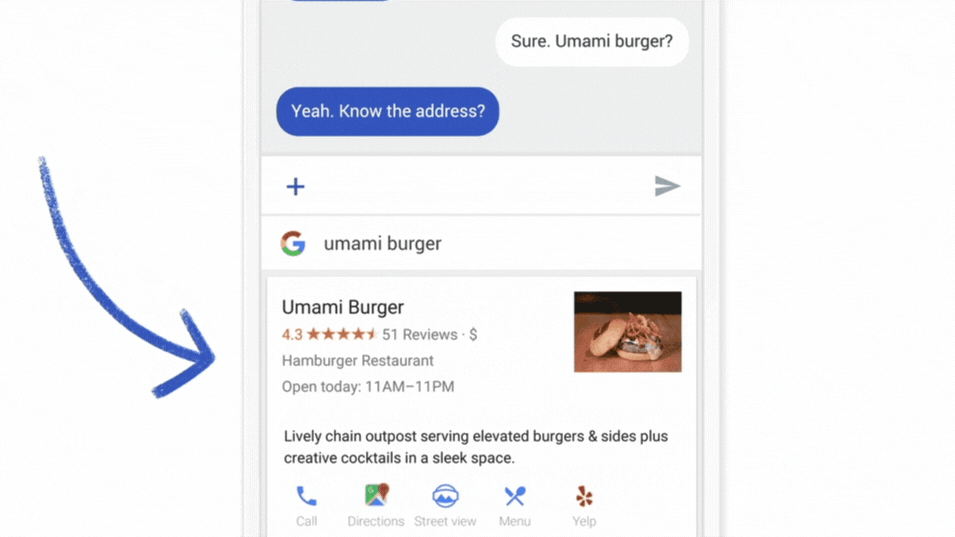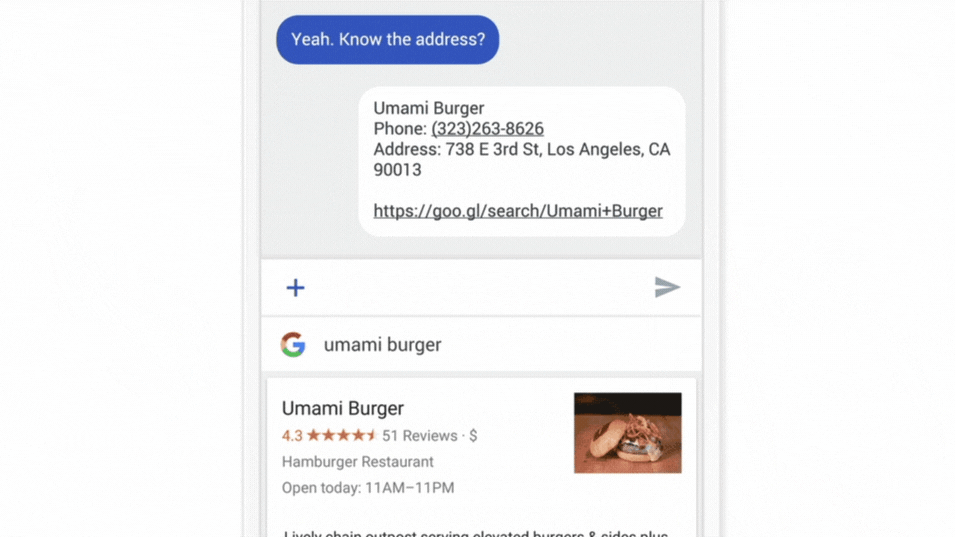
- Predikce dalšího slova na klávesnici smartphonu.
- IoT zařízení, která mohou lokálně trénovat modely specifické pro konkrétní situaci.
- Farmaceutický a zdravotnický průmysl.
- Obranný průmysl, který může trénovat modely bez sdílení citlivých dat.
Frameworky pro federované učení
Existuje mnoho frameworků pro implementaci federovaného učení. Mezi nejpopulárnější patří NVFlare, FATE, Flower a PySft. Pro podrobnější srovnání si můžete přečíst tento návod.
Závěr
Tento článek představil základní koncept federovaného učení, vysvětlil jeho princip fungování a probral výhody a nevýhody jeho implementace. Dále byly uvedeny vybrané aplikace a frameworky, které se používají pro nasazení federovaného učení v praxi.
Dále si můžete přečíst článek o nejlepších platformách MLOps pro trénování modelů strojového učení.