

Příkaz vzhledu Linuxu prochází souborem a vypisuje všechny řádky, které začínají konkrétním slovem nebo frází. Ale pozor! V různých distribucích Linuxu se chová odlišně. Tento tutoriál vám ukáže, jak jej používat.
Table of Contents
Vzhled Ubuntu Příkaz se chová jinak
Když jsem zkoumal tento článek, byl jsem jednoduchým, ale užitečným příkazem. Byly zde dva problémy: kompatibilita a dokumentace.
Tento článek byl zkontrolován pomocí Ubuntu, Fedory a Manjaro. vzhled byl součástí každé z těchto distribucí, což bylo skvělé. Problém byl v tom, že chování nebylo u všech tří stejné. Verze Ubuntu byla velmi odlišná. Podle Manuálové stránky Ubuntu, chování by mělo být stejné.
Nakonec jsem na to přišel. vzhled tradičně používá a binární vyhledávání, zatímco vzhled Ubuntu používá a lineární vyhledávání. Online manuálové stránky Ubuntu pro Bionic Beaver (18.04), Cosmic Cuttlefish (18.10) a Disco Dingo (19.04) všechny říkají, že verze Ubuntu používá binární vyhledávání, což není tento případ.
Pokud se podíváme na místní manuálovou stránku Ubuntu, vidíme, že jasně uvádí, že jejich vzhled používá lineární vyhledávání. Existuje možnost příkazového řádku, která jej přinutí používat binární vyhledávání. Žádná z verzí v ostatních distribucích nemá možnost volby mezi metodami vyhledávání.
man look

Při procházení manuálovou stránkou dolů vidíme část, která popisuje tuto verzi vzhledu pomocí lineárního namísto binárního vyhledávání.
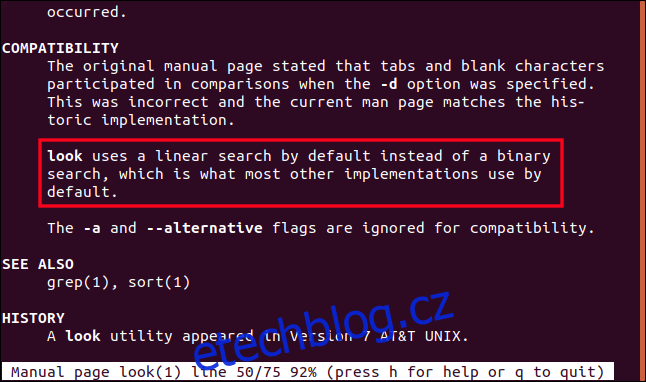
Morálka příběhu je nejprve zkontrolovat místní manuálové stránky.
Lineární vyhledávání versus binární vyhledávání
Binární metoda vyhledávání je rychlejší a efektivnější než lineární vyhledávání. Při práci s velkými soubory je to velmi patrné. Nevýhodou binárního vyhledávání je, že váš soubor musí být tříděn. Pokud nechcete svůj soubor třídit, seřaďte jeho kopii a poté ji použijte s lookem.
To si ukážeme na jiném místě tohoto článku. Jen si uvědomte, že na Fedoře, Manjaru a já očekávám většinu zbytku světa Linuxu budete muset vytvořit seřazenou kopii svého souboru a pracovat s tím.
Instalace slov
look může pracovat s libovolným textovým souborem, který si vyberete, nebo může pracovat se souborem místního slovníku „words“.
Na Manjaro musíte nainstalovat soubor „words“. Použijte tento příkaz:
sudo pacman -Syu words

Použití vzhledu
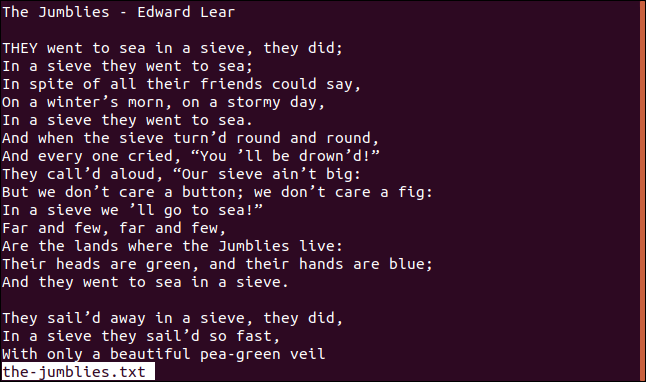
V tomto článku budeme pracovat s textovým souborem Edward Lear báseň „The Jumblies“.
Podívejme se na jeho obsah pomocí tohoto příkazu:
less the-jumblies.txt

Zde je první část básně. Všimněte si, že používáme Ubuntu, takže soubor zůstane neseřazený. Pro Fedoru a Manjaro bychom pracovali s roztříděnou kopií souboru, které se budeme věnovat později v tomto článku.
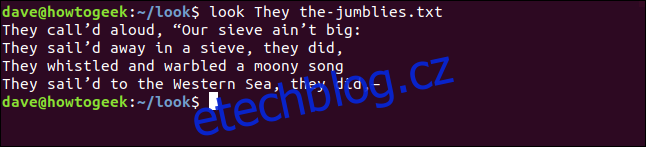
Pokud budeme hledat řádky, které začínají slovem „oni“, zjistíme něco z toho, co Jumblies udělali.
look They the-jumblies.txt

look odpoví výpisem těchto řádků:
Ignorování znaků případu
Chcete-li, aby vzhled ignoroval rozdíly mezi velkými a malými písmeny, použijte volbu -f (ignorovat malá a velká písmena). Jako hledané slovo jsme znovu použili slovo „oni“, ale tentokrát je zapsáno malými písmeny.
look -f they the-jumblies.txt

Tentokrát výsledky zahrnují řádek navíc.
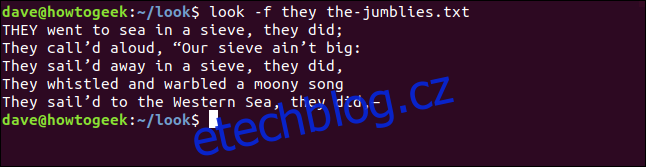
Řádek začínající „ONI“ byl v poslední sadě výsledků vynechán, protože je celý napsán velkými písmeny a neodpovídal našemu hledanému výrazu „oni“.
Ignorování velikosti písmen umožňuje pohled zahrnout je do výsledků.
Použití vzhledu s seřazeným souborem
Pokud má vaše distribuce Linuxu verzi vzhledu, která se řídí tradičním chováním používání binárního vyhledávání, musíte soubor buď seřadit, nebo pracovat s jeho seřazenou kopií.
Zopakujme příkaz k vyhledání „Oni“, ale tentokrát na Manjaro.

Jak vidíte, nebyly vráceny žádné výsledky. Ale víme, že v básni jsou řádky, které začínají slovem „oni“.
Vytvořme setříděnou kopii souboru. Pokud se chystáte použít volby -f (ignorovat malá a velká písmena) nebo -d (pouze alfanumerické znaky a mezery) s lookem, musíte je použít při třídění souboru.
Volba -o (výstup) umožňuje zadat název souboru, do kterého mají být přidány setříděné řádky. V tomto příkladu je to „sorted.txt“.
sort -f -d the-jumblies.txt -o sorted.txt

Použijme pohled na soubor sorted.txt a pak použijte volby -fa -d.
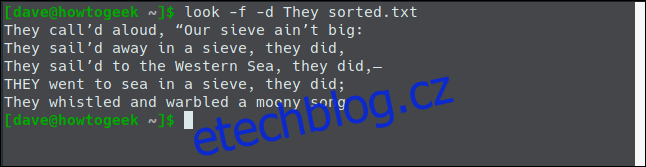
Nyní dostáváme výsledky, které jsme očekávali.
Zvažte pouze mezery a alfanumerické znaky
Chcete-li vypadat, ignorujte vše, co není alfanumerický znak nebo mezeru, použijte volbu -d (alfanumerickou).
Podívejme se, jestli existují nějaká slova, která začínají „Ach“.
look -f oh the-jumblies.txt

Pohledem nejsou vráceny žádné výsledky.
Zkusme to znovu a řekněme looku, aby ignoroval cokoli jiného než alfanumerické znaky a mezery. To znamená, že znaky a symboly, jako je interpunkce, budou ignorovány.
look -f -d oh the-jumblies.txt

Tentokrát máme výsledek. Tento řádek jsme dříve nenašli, protože uvozovky a vykřičník zmátly hledání.

Určení ukončovacího znaku
Můžete říct vzhledu, aby použil konkrétní znak jako ukončovací znak. Obvykle se jako ukončovací znak používají mezery a konce řádků.
Volba -t (ukončit znak) nám umožňuje zadat znak, který bychom chtěli použít. V tomto příkladu použijeme znak apostrof. Musíme to citovat zpětným lomítkem, aby pohled věděl, že neotvíráme řetězec.
Hledaný výraz také citujeme, protože obsahuje mezeru. Hledáme dvě slova.
look -f -t ' "they call" the-jumblies.txt

Výsledky odpovídají hledanému výrazu zakončenému apostrofem, který jsme použili jako ukončovací znak.

Použití vzhledu bez souboru
Pokud nezadáte název souboru na příkazovém řádku, použijte look soubor se slovy.
Příkaz:

dává tyto výsledky:
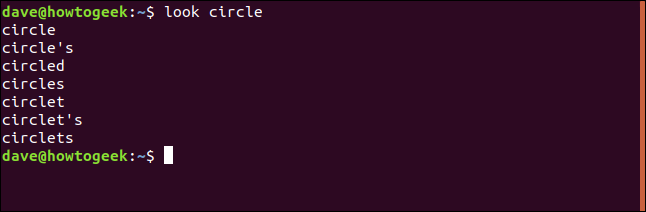
Toto jsou všechna slova v souboru, která začínají slovem „kruh“.
nehledejte dál
To je vše, co je třeba hledat.
Je to docela snadné, jakmile víte, že se různé linuxové distribuce chovají různě, a dostali jste se na dno, zda vaše verze používá binární nebo lineární vyhledávání.