Linuxový příkaz curl umí mnohem více než jen stahovat soubory. Zjistěte, čeho je curl schopen a kdy byste jej měli použít místo wget.
Table of Contents
curl vs. wget : Jaký je rozdíl?
Lidé se často snaží identifikovat relativní sílu příkazů wget a curl. Příkazy mají určité funkční překrývání. Každý může získávat soubory ze vzdálených míst, ale tím podobnost končí.
wget je a fantastický nástroj pro stahování obsahu a souborů. Může stahovat soubory, webové stránky a adresáře. Obsahuje inteligentní rutiny pro procházení odkazů na webových stránkách a rekurzivní stahování obsahu přes celý web. Jako správce stahování z příkazového řádku je nepřekonatelný.
curl uspokojí úplně jiná potřeba. Ano, může načíst soubory, ale nemůže rekurzivně procházet webovou stránkou a hledat obsah k načtení. Curl ve skutečnosti umožňuje interakci se vzdálenými systémy tím, že na tyto systémy zadává požadavky a načítá a zobrazuje jejich odpovědi. Těmito odpověďmi může být obsah webových stránek a soubory, ale mohou také obsahovat data poskytnutá prostřednictvím webové služby nebo rozhraní API jako výsledek „otázky“ podané požadavkem curl.
A curl se neomezuje pouze na webové stránky. curl podporuje více než 20 protokolů, včetně HTTP, HTTPS, SCP, SFTP a FTP. A pravděpodobně díky vynikajícímu zpracování linuxových kanálů lze curl snadněji integrovat s jinými příkazy a skripty.
Autor curl má webovou stránku, která popisuje rozdíly, které vidí mezi curl a wget.
Instalace curl
Z počítačů použitých k prozkoumání tohoto článku byly již nainstalovány Fedora 31 a Manjaro 18.1.0. curl musel být nainstalován na Ubuntu 18.04 LTS. Na Ubuntu spusťte tento příkaz a nainstalujte jej:
sudo apt-get install curl

Verze curl
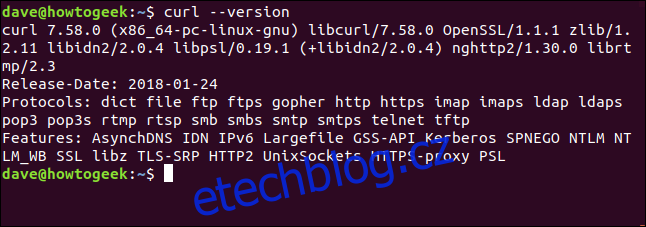
Volba –version dělá curlreport jeho verzí. Obsahuje také seznam všech protokolů, které podporuje.
curl --version
Načítání webové stránky
Pokud ukážeme curl na webovou stránku, načte ji za nás.
curl https://www.bbc.com

Ale jeho výchozí akcí je vypsat jej do okna terminálu jako zdrojový kód.
Pozor: Pokud curl neřeknete, že chcete něco uložit jako soubor, vždy to vypíše do okna terminálu. Pokud je soubor, který načítá, binární soubor, výsledek může být nepředvídatelný. Shell se může pokusit interpretovat některé hodnoty bajtů v binárním souboru jako řídicí znaky nebo sekvence escape.
Ukládání dat do souboru
Řekněme curl, aby přesměroval výstup do souboru:
curl https://www.bbc.com > bbc.html

Uvedené informace jsou:
% Total: Celková částka, která má být získána.
% Received: Procento a skutečné hodnoty dosud načtených dat.
% Xferd: Procento a skutečně odeslané, pokud se data nahrávají.
Průměrná rychlost Dload: Průměrná rychlost stahování.
Průměrná rychlost nahrávání: Průměrná rychlost nahrávání.
Čas celkem: Odhadovaná celková doba trvání přenosu.
Čas strávený: Doposud uplynulý čas tohoto převodu.
Zbývající čas: Odhadovaný čas zbývající do dokončení převodu
Aktuální rychlost: Aktuální přenosová rychlost pro tento přenos.
Protože jsme přesměrovali výstup z curl do souboru, máme nyní soubor s názvem „bbc.html“.

Poklepáním na tento soubor se otevře váš výchozí prohlížeč, takže zobrazí načtenou webovou stránku.
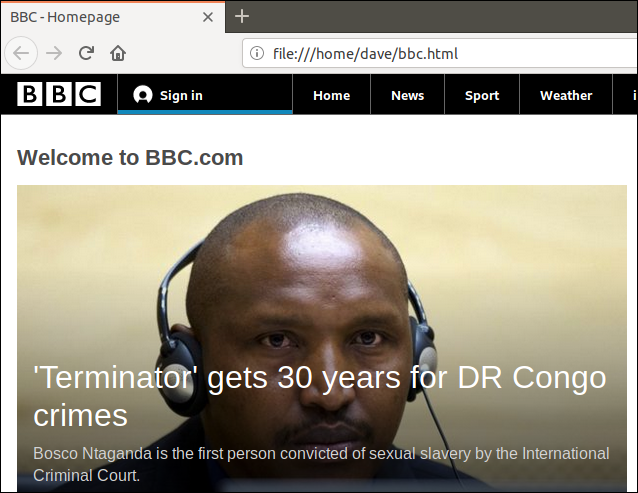
Všimněte si, že adresa v adresním řádku prohlížeče je místní soubor v tomto počítači, nikoli vzdálený web.
Pro vytvoření souboru nemusíme přesměrovat výstup. Můžeme vytvořit soubor použitím volby -o (výstup) a příkazem curl, aby soubor vytvořil. Zde používáme volbu -o a poskytujeme název souboru, který chceme vytvořit „bbc.html“.
curl -o bbc.html https://www.bbc.com
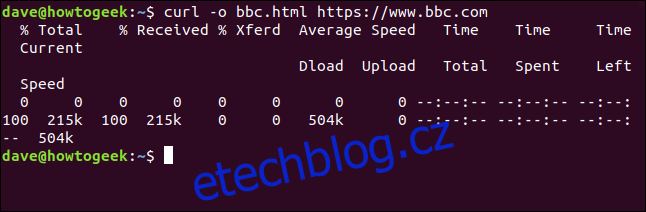
Použití ukazatele průběhu ke sledování stahování
Chcete-li, aby byly textové informace o stahování nahrazeny jednoduchým ukazatelem průběhu, použijte volbu -# (ukazatel průběhu).
curl -x -o bbc.html https://www.bbc.com

Restartování přerušeného stahování
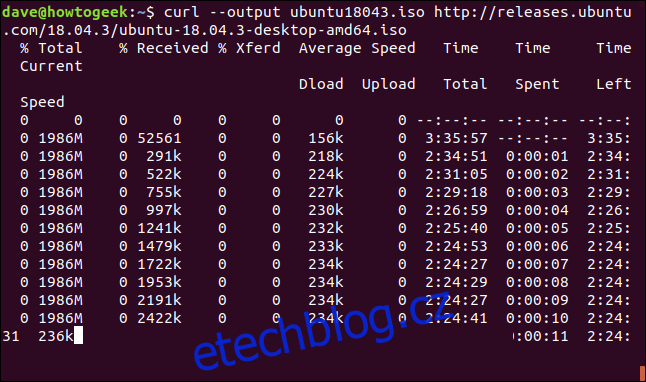
Je snadné restartovat stahování, které bylo ukončeno nebo přerušeno. Začněme stahování velkého souboru. Použijeme nejnovější sestavení dlouhodobé podpory Ubuntu 18.04. Pomocí volby –output specifikujeme název souboru, do kterého jej chceme uložit: „ubuntu180403.iso.“
curl --output ubuntu18043.iso http://releases.ubuntu.com/18.04.3/ubuntu-18.04.3-desktop-amd64.iso

Stahování se spustí a postupuje k dokončení.
Pokud násilně přerušíme stahování pomocí Ctrl+C , vrátíme se do příkazového řádku a stahování se ukončí.
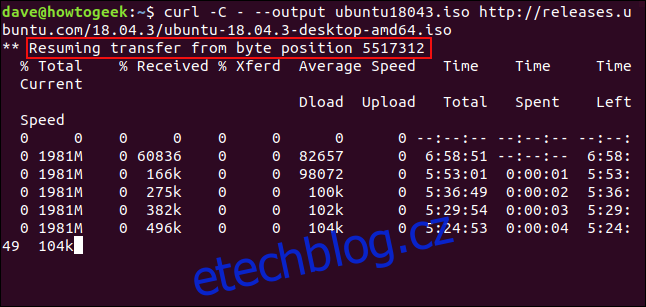
Chcete-li restartovat stahování, použijte volbu -C (pokračovat v). To způsobí, že curl restartuje stahování v určeném bodě nebo posunu v cílovém souboru. Pokud použijete pomlčku – jako posun, curl se podívá na již staženou část souboru a určí správný posun, který má pro sebe použít.
curl -C - --output ubuntu18043.iso http://releases.ubuntu.com/18.04.3/ubuntu-18.04.3-desktop-amd64.iso

Stahování se restartuje. curl hlásí posun, při kterém se restartuje.
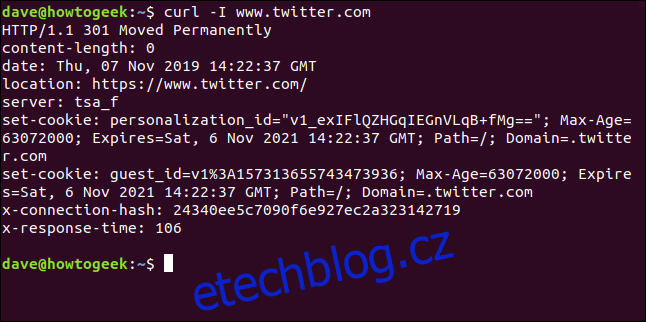
Načítání HTTP hlaviček
S volbou -I (head) můžete načíst pouze hlavičky HTTP. To je stejné jako odeslání Příkaz HTTP HEAD na webový server.
curl -I www.twitter.com

Tento příkaz načte pouze informace; nestahuje žádné webové stránky ani soubory.
Stahování více adres URL
Pomocí xargs můžeme stáhnout více URL najednou. Možná si chceme stáhnout řadu webových stránek, které tvoří jeden článek nebo tutoriál.
Zkopírujte tyto adresy URL do editoru a uložte je do souboru s názvem „urls-to-download.txt“. Můžeme použít xargs ošetřit obsah každého řádku textového souboru jako parametr, který bude postupně podávat ke zvlnění.
https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#0 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#1 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#2 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#3 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#4 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#5
Toto je příkaz, který musíme použít, aby xargs předal tyto adresy URL, aby se po jedné zkroutil:
xargs -n 1 curl -ONote that this command uses the -O (remote file) output command, which uses an uppercase “O.” This option causes curl to save the retrieved file with the same name that the file has on the remote server.
The -n 1 option tells xargs to treat each line of the text file as a single parameter.
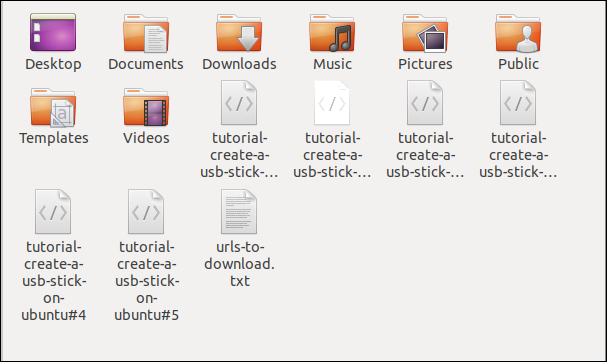
When you run the command, you’ll see multiple downloads start and finish, one after the other.
Checking in the file browser shows the multiple files have been downloaded. Each one bears the name it had on the remote server.
Downloading Files From an FTP Server
Using curl with a File Transfer Protocol (FTP) server is easy, even if you have to authenticate with a username and password. To pass a username and password with curl use the -u (user) option, and type the username, a colon “:”, and the password. Don’t put a space before or after the colon.
This is a free-for-testing FTP server hosted by Rebex. The test FTP site has a pre-set username of “demo”, and the password is “password.” Don’t use this type of weak username and password on a production or “real” FTP server.
curl -u demo:password ftp://test.rebex.net
curl zjistí, že jej míříme na FTP server, a vrátí seznam souborů, které jsou na serveru přítomny.
Jediný soubor na tomto serveru je soubor „readme.txt“ o délce 403 bajtů. Pojďme to získat. Použijte stejný příkaz jako před chvílí s připojeným názvem souboru:
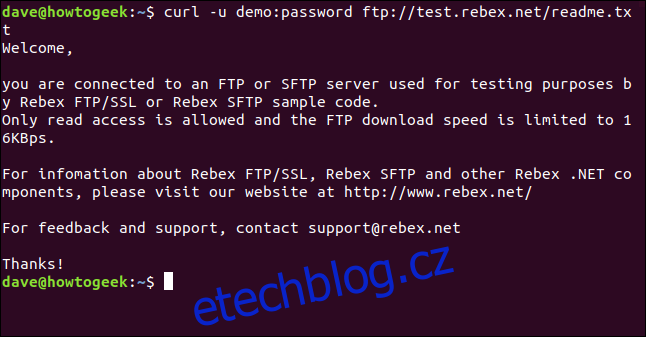
curl -u demo:password ftp://test.rebex.net/readme.txt
Soubor je načten a curl zobrazí jeho obsah v okně terminálu.
Téměř ve všech případech bude pohodlnější nechat si načtený soubor uložit na disk, než jej zobrazit v okně terminálu. Ještě jednou můžeme použít výstupní příkaz -O (vzdálený soubor) k uložení souboru na disk se stejným názvem souboru, jaký má na vzdáleném serveru.
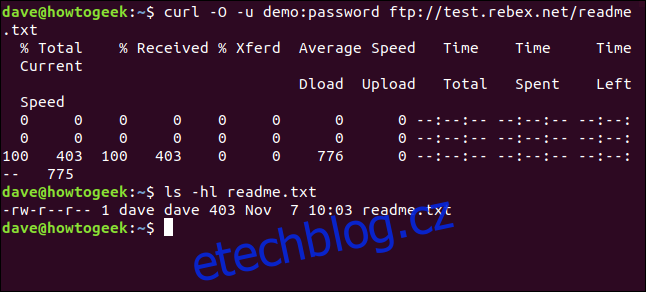
curl -O -u demo:password ftp://test.rebex.net/readme.txt
Soubor se načte a uloží na disk. Můžeme použít ls ke kontrole podrobností souboru. Má stejný název jako soubor na FTP serveru a je stejně dlouhý, 403 bajtů.
ls -hl readme.txt
Odesílání parametrů na vzdálené servery
Některé vzdálené servery přijmou parametry v požadavcích, které jim budou zaslány. Parametry mohou být použity například k formátování vrácených dat, nebo mohou být použity k výběru přesných dat, která si uživatel přeje získat. Často je možné komunikovat s webem rozhraní pro programování aplikací (API) pomocí curl.
Jako jednoduchý příklad, ipify web má API, lze se dotázat, abyste zjistili vaši externí IP adresu.
curl https://api.ipify.orgPřidáním parametru format do příkazu s hodnotou „json“ můžeme opět požádat o naši externí IP adresu, ale tentokrát budou vrácená data zakódována v formát JSON.
curl https://api.ipify.org?format=json
Zde je další příklad, který využívá Google API. Vrací objekt JSON popisující knihu. Parametr, který musíte zadat, je Mezinárodní standardní číslo knihy (ISBN) číslo knihy. Najdete je na zadní straně obálky většiny knih, obvykle pod čárovým kódem. Parametr, který zde použijeme, je „0131103628“.
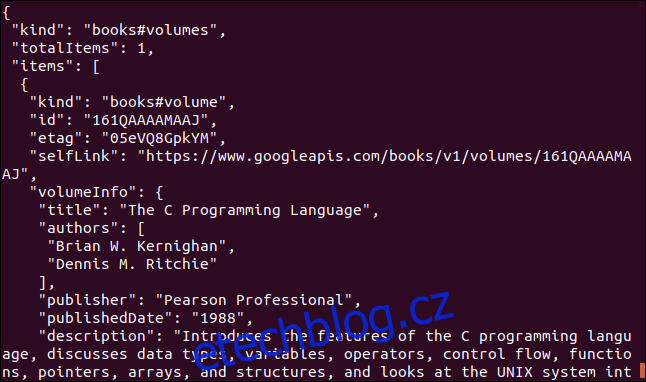
curl https://www.googleapis.com/books/v1/volumes?q=isbn:0131103628
Vrácená data jsou komplexní:
Někdy curl, Někdy wget
Pokud bych chtěl stáhnout obsah z webové stránky a nechat si tento obsah vyhledat rekurzivně ve stromové struktuře webu, použil bych wget.
Pokud bych chtěl komunikovat se vzdáleným serverem nebo API a případně stáhnout nějaké soubory nebo webové stránky, použil bych curl. Zvláště pokud byl protokol jedním z mnoha, které wget nepodporuje.