
Sharding databáze je technika k dosažení horizontální škálovatelnosti ve velkých systémech.
Téměř všechny systémy reálného světa se skládají z databázového serveru, který přijímá velké množství požadavků na čtení a nezanedbatelné množství požadavků na zápis. To by mohlo přetížit server a snížit výkon systému.
Ke zmírnění těchto dopadů a zlepšení výkonu systému existují přístupy, jako je replikace databáze a sharding databáze. V této příručce nejprve prozkoumáme techniky ke zlepšení výkonu systému, včetně:
- Rozšíření databázového serveru
- Replikace databáze
- Horizontální dělení
Po prodiskutování těchto technik přistoupíme k tomu, jak funguje sdílení databáze, a také se podíváme na výhody a omezení tohoto přístupu.
Pojďme začít!
Table of Contents
Techniky pro zlepšení výkonu systému
Začněme diskusí o technikách ke zlepšení výkonu systému, když existují úzká hrdla kvůli databázovému serveru:
#1. Zvětšení databázového serveru
Zvětšení instance databázového serveru se může zdát jako přímý přístup ke zlepšení výkonu systému. To zahrnuje zvýšení výpočetního výkonu, přidání více paměti RAM a podobně.
Tato technika však přichází s následujícím omezením. Nemůžeme mít server s nekonečným úložištěm a výpočetním výkonem. A za určitým limitem dostáváme klesající výnosy.
#2. Replikace databáze
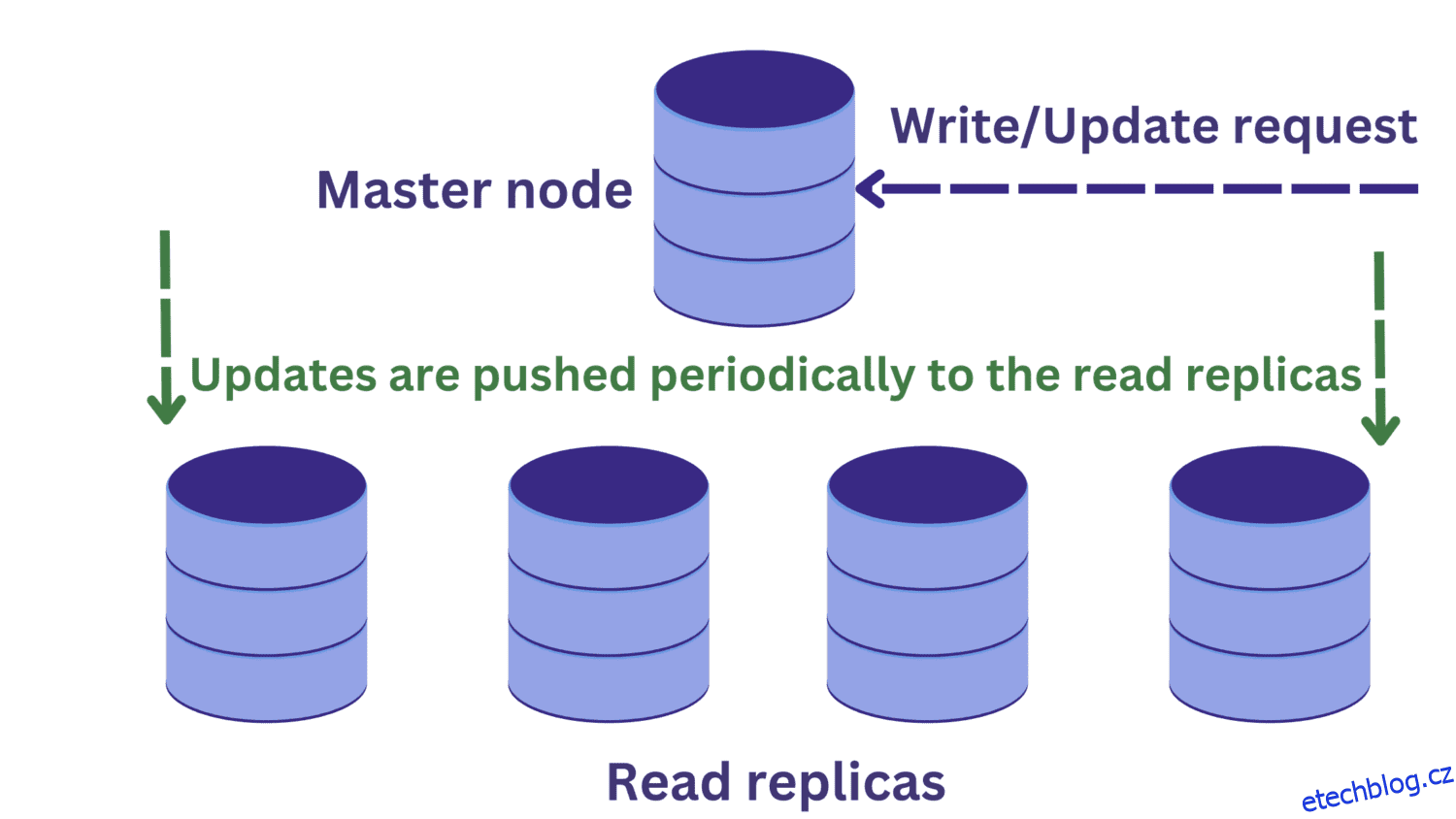
Když dojde k přetížení instance databázového serveru kvůli příchozím požadavkům, můžeme zvážit replikaci databáze.
V rámci replikace databáze máme jeden hlavní uzel, který obvykle přijímá požadavky na zápis. Existuje několik čtených replik.
To zlepšuje dostupnost a zmírňuje přetížení systému. Nyní můžeme paralelně zpracovávat více dotazů, protože požadavky na čtení mohou být směrovány do jedné ze čtených replik.
To ale přináší další problém. Požadavky na zápis do hlavního uzlu mohou změnit data a tyto aktualizace jsou pravidelně šířeny do replik pro čtení.
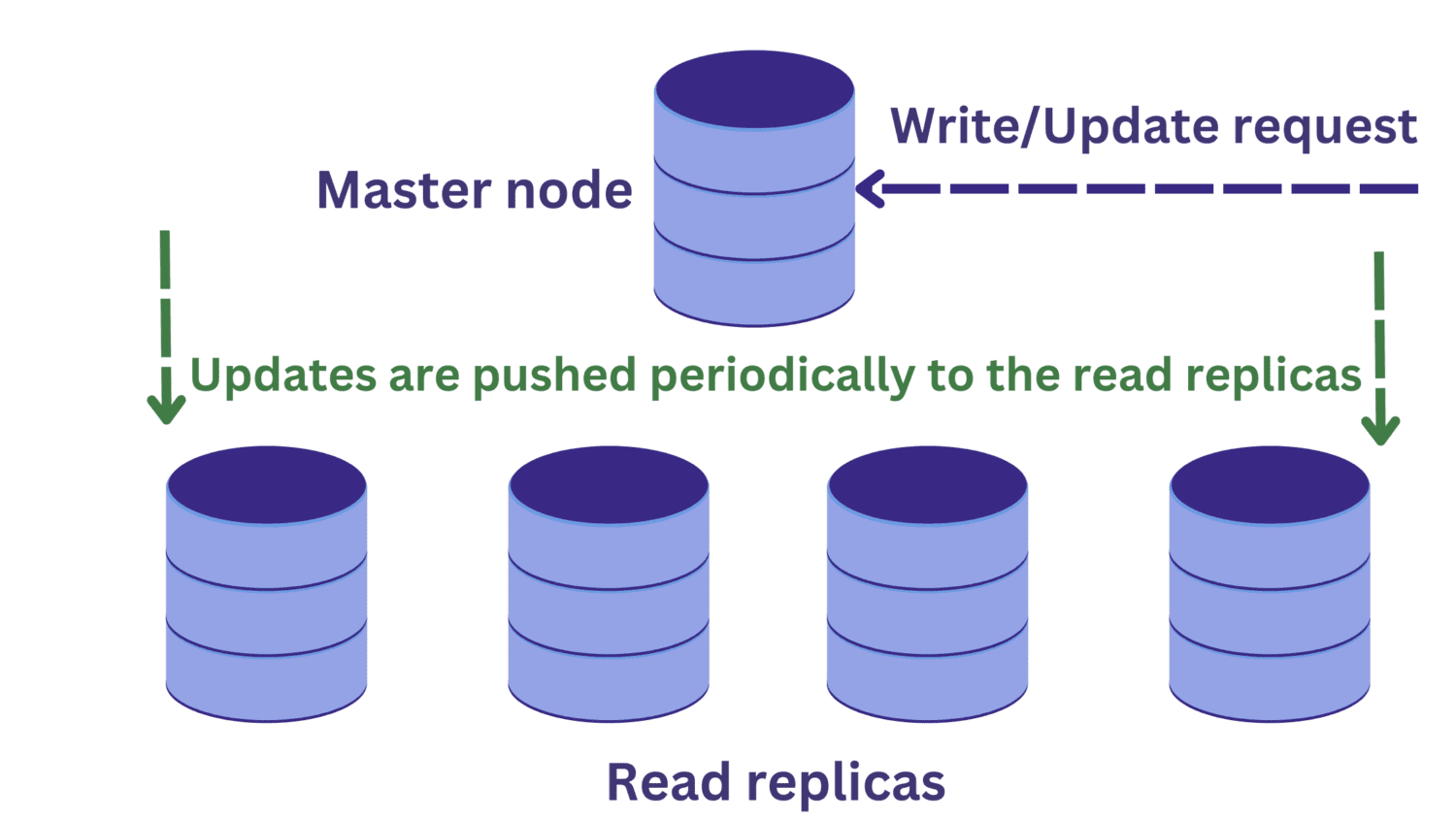
Předpokládejme, že existuje požadavek na čtení na jednu z čtených replik ve stejnou dobu, kdy v hlavním uzlu probíhá operace zápisu.
Změny v hlavním uzlu se zatím nepřenesou do čtených replik. V tomto případě můžeme číst zastaralá data, což není žádoucí.
#3. Horizontální rozdělení
Horizontální dělení je další technika pro optimalizaci výkonu systému. Můžeme mít jednu velkou tabulku s miliardami řádků (například tabulku zákazníků a transakčních údajů).
Operace čtení z takové databázové tabulky jsou pomalejší. Ale pomocí horizontálního rozdělení je nyní jedna velká tabulka rozdělena na více oddílů (nebo menších tabulek), ze kterých můžeme číst. Relační databáze jako PostgreSQL nativně podporují dělení.
Všechny oblasti jsou však stále uvnitř jedné instance databázového serveru. Jediný rozdíl je v tom, že nyní můžeme číst z oddílů místo z jedné velké tabulky.
Proto, když dojde ke zvýšení počtu příchozích požadavků, server nemusí být schopen podporovat zvýšenou poptávku.
Jak funguje sdílení databáze?
Nyní, když jsme probrali přístupy ke zlepšení výkonu systému a jejich omezení, pochopme, jak funguje sdílení databáze.
Při shardingu rozdělujeme jednu velkou databázi na několik menších databází, z nichž každá běží na instanci databázového serveru. Každá taková menší databáze se nazývá shard. A každý fragment obsahuje jedinečnou podmnožinu dat.
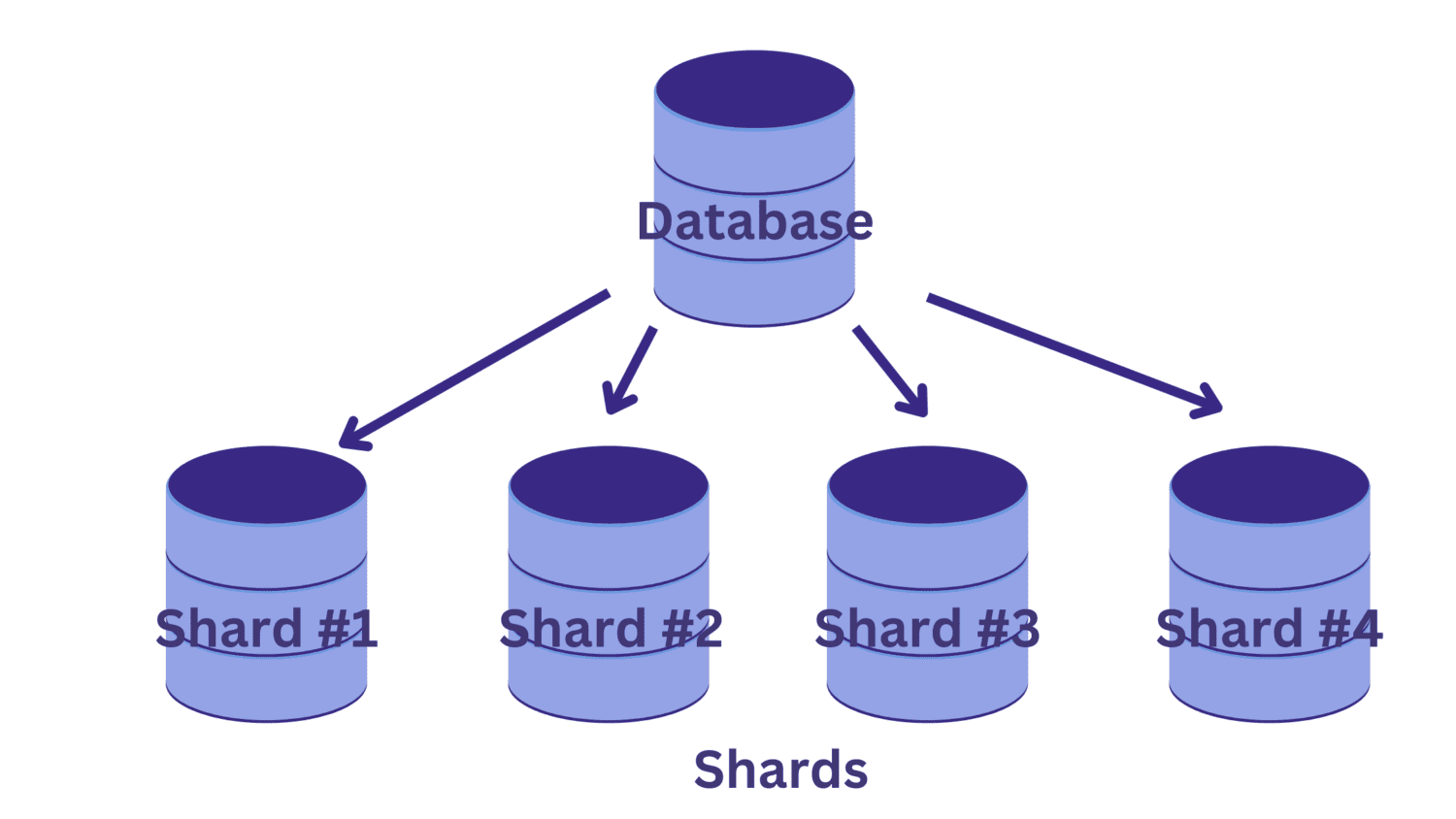
Ale jak rozdělíme databázi na fragmenty? A jak určíme, který z řad jde do kterého ze střepů?
🔑 Zadejte sharding klíč.
Pochopení Sharding Key
Pojďme pochopit roli shardovacího klíče.
Shardingový klíč, kterým je obvykle sloupec (nebo kombinace sloupců) v databázové tabulce, by měl být zvolen tak, aby distribuce dat byla rovnoměrná ve více fragmentech. Protože nechceme, aby byl konkrétní úlomek mnohem větší než ostatní úlomky.
V databázi, která ukládá data o zákaznících a transakcích, je customer_ID dobrým kandidátem na shardingový klíč.
Jakmile jsme se rozhodli pro sharding klíč, můžeme přijít s hashovací funkcí, která určí, který z řádků se dostane do kterého ze shardů.
V tomto příkladu řekněme, že potřebujeme rozdělit databázi na pět fragmentů (shard #0 až shard #4) pomocí customer_ID jako shardingového klíče. V tomto případě je jednoduchá hashovací funkce customer_ID % 5.
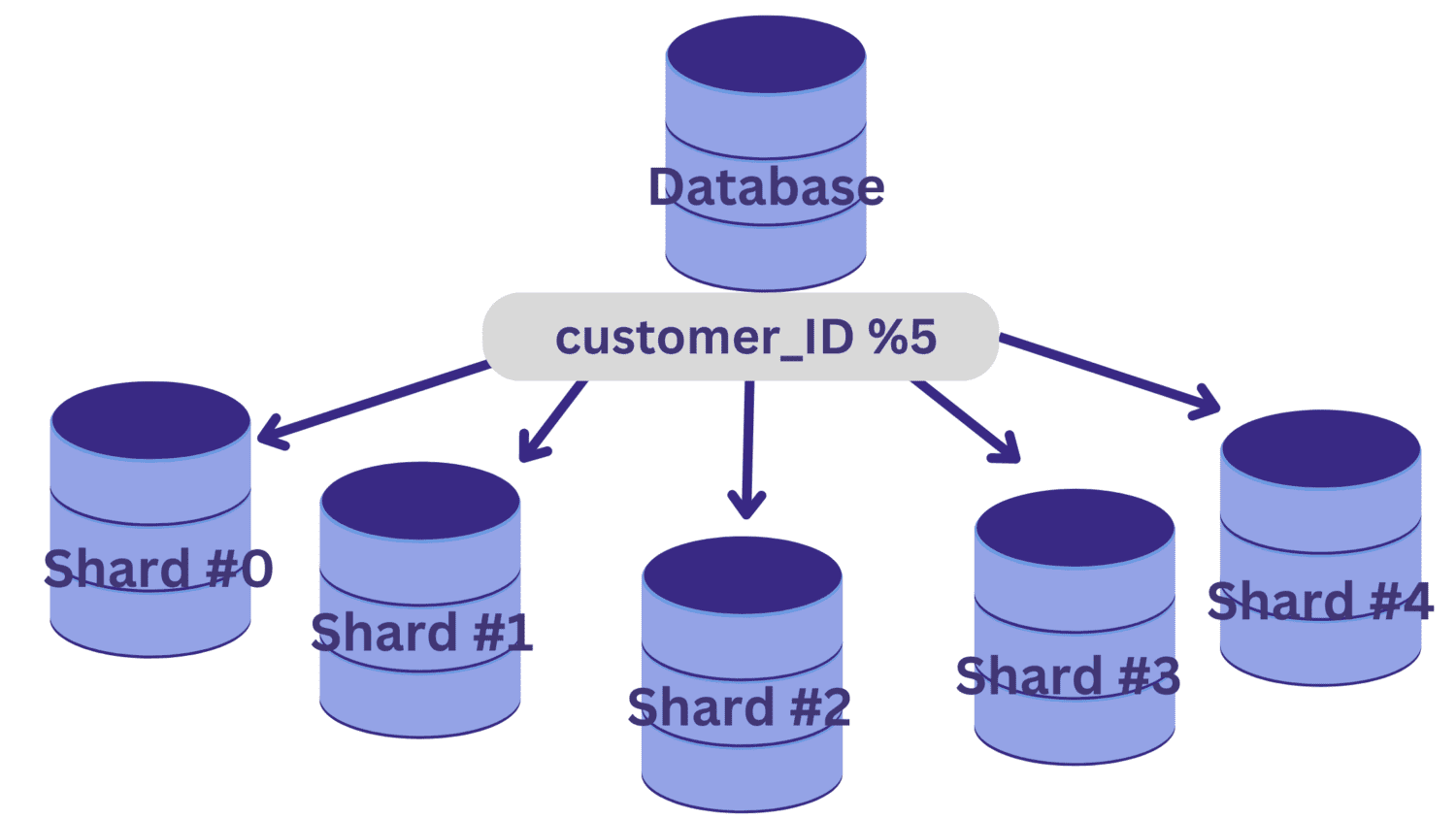
Všechny hodnoty customer_ID, které po vydělení 5 ponechávají zbytek nula, budou mapovány na fragment #0. A hodnoty customer_ID, které ponechávají zbytky 1 až 4, se namapují na fragment #1 až fragment #4.
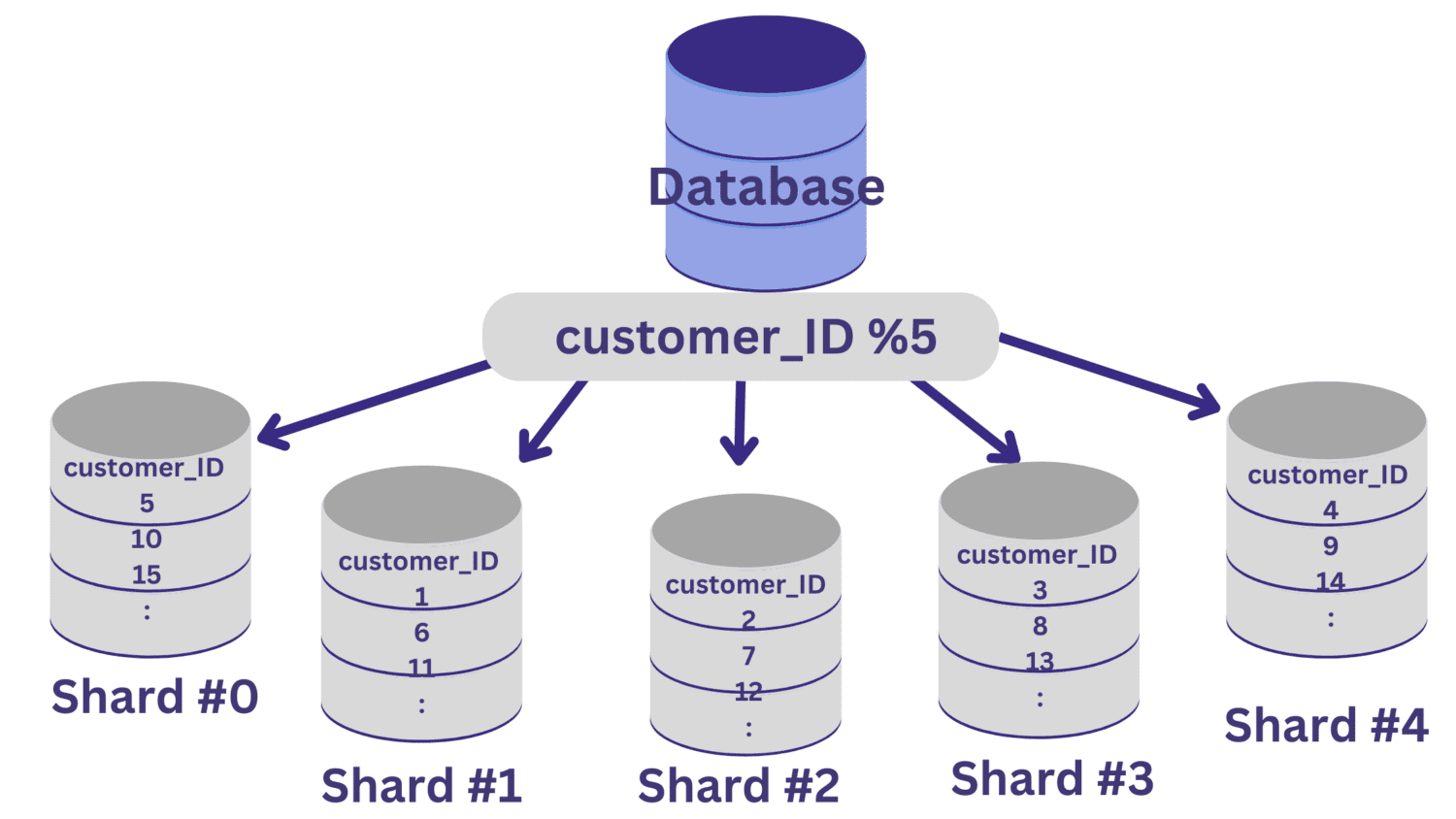
Poté, co je databázové sharding implementováno tímto způsobem, je důležité mít směrovací vrstvu, která směruje příchozí požadavky do správného databázového fragmentu.
Výhody sdílení databáze
Zde jsou některé z výhod sdílení databáze:
#1. Vysoká škálovatelnost
Vždy je možné rozdělit větší databázi na několik menších fragmentů. Sharding databáze nám tedy umožňuje horizontální škálování.
#2. Vysoká dostupnost
Pokud existuje jediná instance databázového serveru, která zpracovává všechny příchozí požadavky, máme jediný bod selhání. Pokud je databázový server mimo provoz, je mimo provoz celá aplikace.
U databázového shardingu je pravděpodobnost, že budou všechny databázové fragmenty v daném okamžiku nedostupné, relativně nízká. Pokud je tedy konkrétní datový fragment mimo provoz, nebudeme moci zpracovat požadavky na čtení tohoto datového fragmentu. Ale ostatní fragmenty mohou stále zpracovávat příchozí požadavky. Výsledkem je vysoká dostupnost a zvýšená odolnost proti chybám.
Omezení sdílení databáze
Nyní se podívejme na některá omezení sdílení databáze:
#1. Složitost
Ačkoli má sharding výhody z hlediska škálovatelnosti a odolnosti proti chybám, přináší do systému složitost.
Od mapování záznamů na oddíly až po implementaci směrovací vrstvy až po směrování dotazů na příslušné fragmenty dat je se sdílením databází značná složitost.
#2. Resharding
Dalším omezením shardingu je nutnost reshardingu.
Přestože používáme hašovací funkci, abychom dosáhli rovnoměrného rozložení datových záznamů, je možné, že jeden ze střípků je mnohem větší než ostatní úlomky a může se dříve vyčerpat. V tomto případě musíme počítat s přeskupením (nebo přeskupením), a to je spojeno se značnou režií.
#3. Spouštění složitých dotazů
Když potřebujete spouštět dotazy pro analýzu, které zahrnují spojení, musíte použít záznamy z více fragmentů na rozdíl od jedné databáze. Takže to může být problém, když potřebujete spustit příliš mnoho analytických dotazů. Můžete to obejít denormalizací databází, ale stále to vyžaduje určité úsilí!
Závěr
Zakončeme diskuzi shrnutím toho, co jsme se naučili.
Rozšiřování hardwaru není vždy optimální. Posilování instance serveru se tedy nedoporučuje. Také jsme prozkoumali techniky, jako je replikace databáze a horizontální dělení a jejich omezení.
Poté jsme se naučili, jak funguje sdílení databáze rozdělením velké databáze na menší a snadno spravovatelné fragmenty. Diskutovali jsme o tom, jak by měl být sharding klíč pečlivě vybrán, aby se dosáhlo rovnoměrných oddílů, a o potřebě směrovací vrstvy, která směruje příchozí požadavky do správného databázového fragmentu.
Sharding databáze má výhody, jako je vysoká dostupnost a škálovatelnost. Mezi některé nevýhody patří složitost nastavení shardingu a opětovného sdílení, když se jeden nebo více fragmentů vyčerpá.
Můžete tedy uvažovat o shardování, pokud si myslíte, že výhody převažují nad složitostí, kterou sharování přináší. Dále se podívejte na srovnání různých relačních databází AWS.