

V tomto článku probereme vektorizaci – techniku NLP, a pochopíme její význam s obsáhlým průvodcem o různých typech vektorizace.
Probrali jsme základní koncepty předzpracování NLP a čištění textu. Podívali jsme se na základy NLP, jeho různé aplikace a techniky, jako je tokenizace, normalizace, standardizace a čištění textu.

Než probereme vektorizaci, zopakujme si, co je tokenizace a jak se liší od vektorizace.
Table of Contents
Co je tokenizace?
Tokenizace je proces rozdělování vět na menší jednotky nazývané tokeny. Token pomáhá počítačům snadno porozumět textu a pracovat s ním.
EX. ‚Tento článek je dobrý‘
Tokeny- [‘This’, ‘article’, ‘is’, ‘good’.]
Co je to vektorizace?
Jak víme, modely a algoritmy strojového učení rozumí numerickým datům. Vektorizace je proces převodu textových nebo kategoriálních dat na číselné vektory. Převedením dat na číselná data můžete svůj model trénovat přesněji.
Proč potřebujeme vektorizaci?
❇️Tokenizace a vektorizace mají různou důležitost ve zpracování přirozeného jazyka (NPL). Tokenizace rozděluje věty na malé tokeny. Vektorizace jej převádí do numerického formátu, aby mu porozuměl počítačový/ML model.
❇️ Vektorizace je užitečná nejen pro její převod do numerické podoby, ale také užitečná pro zachycení sémantického významu.
❇️ Vektorizace může snížit rozměrnost dat a zefektivnit je. To by mohlo být velmi užitečné při práci na velkém souboru dat.
❇️ Mnoho algoritmů strojového učení vyžaduje numerický vstup, jako jsou neuronové sítě, aby nám mohla pomoci vektorizace.
Existují různé typy vektorizačních technik, kterým porozumíme v tomto článku.
Pytel slov
Pokud máte spoustu dokumentů nebo vět a chcete je analyzovat, Bag of Words tento proces zjednoduší tím, že s dokumentem zachází jako s pytlem, který je plný slov.
Přístup pytle slov může být užitečný při klasifikaci textu, analýze sentimentu a vyhledávání dokumentů.
Předpokládejme, že pracujete na velkém množství textu. Pytel slov vám pomůže reprezentovat textová data vytvořením slovní zásoby jedinečných slov v našich textových datech. Po vytvoření slovní zásoby zakóduje každé slovo jako vektor na základě frekvence (jak často se každé slovo vyskytuje v tomto textu) těchto slov.
Tyto vektory se skládají z nezáporných čísel (0,1,2…..), která představují počet frekvencí v tomto dokumentu.
Balíček slov zahrnuje tři kroky:
Krok 1: Tokenizace
Rozdělí dokumenty na tokeny.
Ex – (věta: „Miluji pizzu a miluji burgery“)
Krok 2: Jedinečné oddělení slov/tvorba slovní zásoby
Vytvořte seznam všech jedinečných slov, která se objevují ve vašich větách.
[“I”, “love”, “Pizza”, “and”, “Burgers”]
Krok 3: Počítání výskytu slov/tvorba vektoru
Tento krok spočítá, kolikrát se každé slovo ze slovní zásoby opakuje, a uloží je do řídké matice. V řídké matici každý řádek ve větném vektoru, jehož délka (sloupce matice) se rovná velikosti slovní zásoby.
Import CountVectorizer
Chystáme se importovat CountVectorizer, abychom trénovali náš model Bag of words
from sklearn.feature_extraction.text import CountVectorizer
Vytvořte vektorizátor
V tomto kroku vytvoříme náš model pomocí CountVectorizer a trénujeme jej pomocí našeho vzorového textového dokumentu.
# Sample text documents
documents = [
"This is the first document.",
"This document is the second document.",
"And this is the third one.",
"Is this the first document?",
]
# Create a CountVectorizer
cv = CountVectorizer()
# Fit and Transform X = cv.fit_transform(documents)
Převést na husté pole
V tomto kroku převedeme naše reprezentace do hustého pole. Dostaneme také názvy funkcí nebo slova.
# Get the feature names/words feature_names = vectorizer.get_feature_names_out() # Convert to dense array X_dense = X.toarray()
Vytiskneme matici termínů dokumentu a příznaková slova
# Print the DTM and feature names
print("Document-Term Matrix (DTM):")
print(X_dense)
print("\nFeature Names:")
print(feature_names)
Dokument – Matice termínů (DTM):
 Matice
Matice
Názvy funkcí:
 Hlavní slova
Hlavní slova
Jak vidíte, vektory se skládají z nezáporných čísel (0,1,2……), která představují četnost slov v dokumentu.
Máme čtyři vzorové textové dokumenty a z těchto dokumentů jsme identifikovali devět jedinečných slov. Tato jedinečná slova jsme uložili do naší slovní zásoby tak, že jsme jim přiřadili „Názvy funkcí“.
Potom náš model Bag of Words zkontroluje, zda je v našem prvním dokumentu přítomno první jedinečné slovo. Pokud je přítomen, přiřadí hodnotu 1, jinak přiřadí 0.
Pokud se slovo objeví vícekrát (např. 2krát), přiřadí mu odpovídající hodnotu.
Například ve druhém dokumentu se slovo ‚dokument‘ opakuje dvakrát, takže jeho hodnota v matici bude 2.
Pokud chceme jediné slovo jako vlastnost v klíči slovní zásoby – reprezentace Unigram.
n – gramy = Unigramy, bigramy…….atd.
Existuje mnoho knihoven, jako je scikit-learn, které implementují pytlík slov: Keras, Gensim a další. To je jednoduché a může být užitečné v různých případech.
Ale Bag of words je rychlejší, ale má určitá omezení.
K vyřešení tohoto problému můžeme zvolit lepší přístupy, jedním z nich je TF-IDF. Pojďme, rozumějme podrobně.
TF-IDF
TF-IDF, neboli Term Frequency – Inverse Document Frequency, je číselné vyjádření k určení důležitosti slov v dokumentu.
Proč potřebujeme TF-IDF přes Bag of Words?
Pytel slov zachází se všemi slovy stejně a zabývá se pouze frekvencí jedinečných slov ve větách. TF-IDF dává důležitost slovům v dokumentu tím, že bere v úvahu jak frekvenci, tak jedinečnost.
Slova, která se příliš často opakují, nepřebijí méně frekventovaná a důležitější slova.
TF: Term Frequency měří, jak důležité je slovo v jedné větě.
IDF: Inverzní frekvence dokumentů měří, jak důležité je slovo v celé sbírce dokumentů.
TF = Frekvence slov v dokumentu / Celkový počet slov v tomto dokumentu
DF = Dokument obsahující slovo w / Celkový počet dokumentů
IDF = protokol (celkový počet dokumentů / dokumenty obsahující slovo w)
IDF je reciproční vůči DF. Důvodem je, že čím častější je slovo ve všech dokumentech, tím menší je jeho význam v aktuálním dokumentu.
Konečné skóre TF-IDF: TF-IDF = TF * IDF
Je to způsob, jak zjistit, která slova jsou společná v rámci jednoho dokumentu a jedinečná ve všech dokumentech. Tato slova mohou být užitečná při hledání hlavního tématu dokumentu.
Například,
Doc1 = „Miluji strojové učení“
Doc2 = „Miluji etechblog.cz“
Musíme najít matici TF-IDF pro naše dokumenty.
Nejprve si vytvoříme slovní zásobu jedinečných slov.
Slovní zásoba = [“I,” “love,” “machine,” “learning,” “Geekflare”]
Takže máme 5 pět slov. Pojďme najít TF a IDF pro tato slova.
TF = Frekvence slov v dokumentu / Celkový počet slov v tomto dokumentu
TF:
- Pro „I“ = TF pro Doc1: 1/4 = 0,25 a pro Doc2: 1/3 ≈ 0,33
- Pro „lásku“: TF pro Doc1: 1/4 = 0,25 a pro Doc2: 1/3 ≈ 0,33
- Pro „Stroj“: TF pro Doc1: 1/4 = 0,25 a pro Doc2: 0/3 ≈ 0
- Pro „učení“: TF pro Doc1: 1/4 = 0,25 a pro Doc2: 0/3 ≈ 0
- Pro „etechblog.cz“: TF pro Doc1: 0/4 = 0 a pro Doc2: 1/3 ≈ 0,33
Nyní pojďme vypočítat IDF.
IDF = protokol (celkový počet dokumentů / dokumenty obsahující slovo w)
IDF:
- Pro „I“: IDF je log(2/2) = 0
- Pro „lásku“: IDF je log(2/2) = 0
- Pro „Stroj“: IDF je log(2/1) = log(2) ≈ 0,69
- Pro „učení“: IDF je log(2/1) = log(2) ≈ 0,69
- Pro „etechblog.cz“: IDF je log(2/1) = log(2) ≈ 0,69
Nyní spočítejme konečné skóre TF-IDF:
- Pro „I“: TF-IDF pro Doc1: 0,25 * 0 = 0 a TF-IDF pro Doc2: 0,33 * 0 = 0
- Pro „lásku“: TF-IDF pro Doc1: 0,25 * 0 = 0 a TF-IDF pro Doc2: 0,33 * 0 = 0
- Pro „Machine“: TF-IDF pro Doc1: 0,25 * 0,69 ≈ 0,17 a TF-IDF pro Doc2: 0 * 0,69 = 0
- Pro „Learning“: TF-IDF pro Doc1: 0,25 * 0,69 ≈ 0,17 a TF-IDF pro Doc2: 0 * 0,69 = 0
- Pro „etechblog.cz“: TF-IDF pro Doc1: 0 * 0,69 = 0 a TF-IDF pro Doc2: 0,33 * 0,69 ≈ 0,23
Matice TF-IDF vypadá takto:
I love machine learning etechblog.cz Doc1 0.0 0.0 0.17 0.17 0.0 Doc2 0.0 0.0 0.0 0.0 0.23
Hodnoty v matici TF-IDF vám říkají, jak důležitý je každý termín v každém dokumentu. Vysoké hodnoty znamenají, že termín je v konkrétním dokumentu důležitý, zatímco nízké hodnoty naznačují, že termín je v daném kontextu méně důležitý nebo běžný.
TF-IDF se většinou používá při klasifikaci textu, získávání informací chatbotem a sumarizaci textu.
Importujte TfidfVectorizer
Pojďme importovat TfidfVectorizer ze sklearn
from sklearn.feature_extraction.text import TfidfVectorizer
Vytvořte vektorizátor
Jak vidíte, vytvoříme náš model Tf Idf pomocí TfidfVectorizer.
# Sample text documents
text = [
"This is the first document.",
"This document is the second document.",
"And this is the third one.",
"Is this the first document?",
]
# Create a TfidfVectorizer
cv = TfidfVectorizer()
Vytvořte matici TF-IDF
Pojďme trénovat náš model poskytnutím textu. Poté převedeme reprezentativní matici na husté pole.
# Fit and transform to create the TF-IDF matrix X = cv.fit_transform(text)
# Get the feature names/words feature_names = vectorizer.get_feature_names_out() # Convert the TF-IDF matrix to a dense array for easier manipulation (optional) X_dense = X.toarray()
Vytiskněte matici TF-IDF a hlavní slova
# Print the TF-IDF matrix and feature words
print("TF-IDF Matrix:")
print(X_dense)
print("\nFeature Names:")
print(feature_names)
Matice TF-IDF:
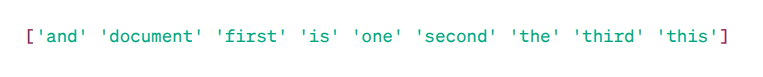 Hlavní slova
Hlavní slova
Jak vidíte, tato celá čísla s desetinnou čárkou označují důležitost slov v konkrétních dokumentech.
Také můžete kombinovat slova ve skupinách po 2, 3, 4 a tak dále pomocí n-gramů.
Existují další parametry, které můžeme zahrnout: min_df, max_feature, subliner_tf atd.
Až dosud jsme zkoumali základní techniky založené na frekvenci.
TF-IDF však nemůže poskytnout sémantický význam a kontextové porozumění textu.
Pojďme pochopit pokročilejší techniky, které změnily svět vkládání slov a které jsou lepší pro sémantický význam a kontextové porozumění.
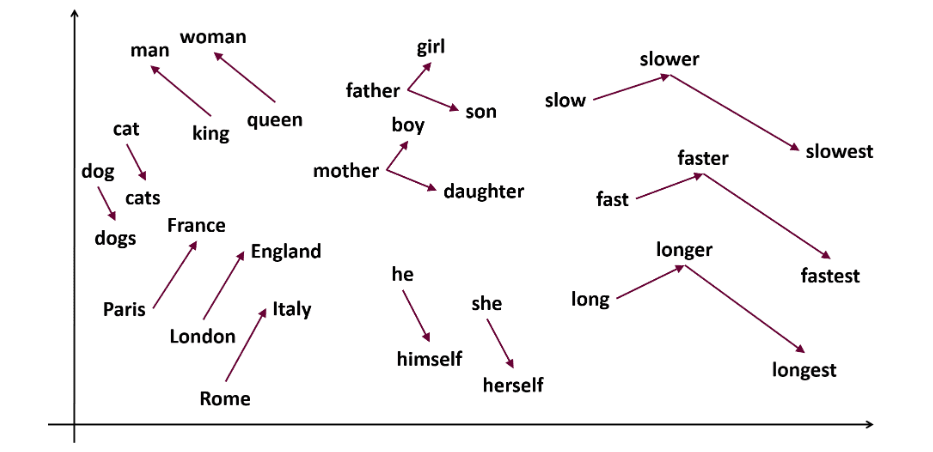
Word2Vec
Word2vec je populární vkládání slov (typ slovního vektoru a užitečný k zachycení sémantické a syntaktické podobnosti) technika v NLP. To bylo vyvinuto Tomášem Mikolovem a jeho týmem v Google v roce 2013. Word2vec představuje slova jako spojité vektory ve vícerozměrném prostoru.
Word2vec si klade za cíl reprezentovat slova způsobem, který zachycuje jejich sémantický význam. Slovní vektory generované word2vec jsou umístěny v souvislém vektorovém prostoru.
Příklad – vektory „kočka“ a „pes“ by byly bližší než vektory „kočka“ a „dívka“.
 Zdroj: usna.edu
Zdroj: usna.edu
Word2vec může použít dvě modelové architektury k vytvoření vkládání slov.
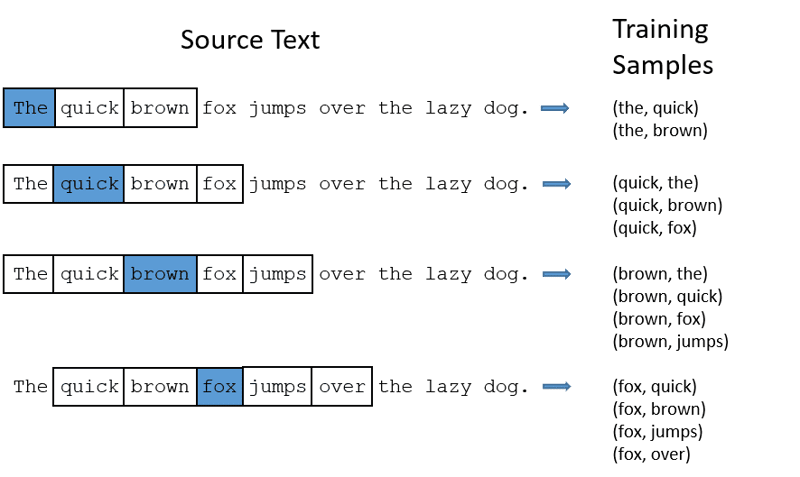
CBOW: Continuous bag of words nebo CBOW se snaží předpovědět slovo průměrováním významu blízkých slov. Vezme pevný počet nebo okno slov kolem cílového slova, pak je převede do číselné podoby (Vložení), pak vše zprůměruje a použije tento průměr k predikci cílového slova pomocí neuronové sítě.
Ex- Předvídat cíl: ‚Liška‘
Slova věty: ‚The‘, ‚quick‘, ‚hnědá‘, ‚skoky‘, ‚over‘, ‚the‘
 Word2Vec
Word2Vec
- CBOW má pevnou velikost okna (počet) slov jako 2 (2 doleva a 2 doprava)
- Převést na vkládání slov.
- CBOW průměruje slovo vkládání.
- CBOW průměruje vkládání slov do kontextových slov.
- Průměrný vektor se snaží předpovědět cílové slovo pomocí neuronové sítě.
Pojďme nyní pochopit, jak se skip-gram liší od CBOW.
Skip-gram: Je to model vkládání slov, ale funguje jinak. Místo předpovídání cílového slova skip-gram předpovídá kontextová slova daná cílovými slovy.
Skip-gramy jsou lepší v zachycení sémantických vztahů mezi slovy.
Ex- ‚Král – Muži + Ženy = královna‘
Pokud chcete pracovat s Word2Vec, máte dvě možnosti: buď můžete trénovat svůj vlastní model, nebo použít předem trénovaný model. Budeme procházet předem trénovaným modelem.
Import gensima
Gensim můžete nainstalovat pomocí pip install:
pip install gensim
Tokenizujte větu pomocí word_tokenize:
Nejprve převedeme věty na nižší. Poté provedeme tokenizaci našich vět pomocí word_tokenize.
# Import necessary libraries
from gensim.models import Word2Vec
from nltk.tokenize import word_tokenize
# Sample sentences
sentences = [
"I love thor",
"Hulk is an important member of Avengers",
"Ironman helps Spiderman",
"Spiderman is one of the popular members of Avengers",
]
# Tokenize the sentences
tokenized_sentences = [word_tokenize(sentence.lower()) for sentence in sentences]
Pojďme trénovat náš model:
Budeme trénovat náš model poskytováním tokenizovaných vět. Pro tento tréninkový model používáme 5 oken, můžete si je přizpůsobit podle svých požadavků.
# Train a Word2Vec model
model = Word2Vec(sentences=tokenized_sentences, vector_size=100, window=5, min_count=1, sg=0)
# Find similar words
similar_words = model.wv.most_similar("avengers")
# Print similar words
print("Similar words to 'avengers':")
for word, score in similar_words:
print(f"{word}: {score}")
Podobná slova pro „avengers“:
 Podobnost Word2Vec
Podobnost Word2Vec
Toto jsou některá slova, která jsou podobná slovu „avengers“ na základě modelu Word2Vec, spolu s jejich skóre podobnosti.
Model počítá skóre podobnosti (většinou kosinusovou podobnost) mezi slovními vektory „mstitel“ a dalšími slovy v jeho slovníku. Skóre podobnosti udává, jak úzce spolu souvisí dvě slova ve vektorovém prostoru.
Ex –
Zde slovo ‚pomáhá‘ s kosinovou podobností -0,005911458611011982 se slovem ‚mstitelé‘. Záporná hodnota naznačuje, že by se mohly navzájem lišit.
Hodnoty kosinové podobnosti se pohybují od -1 do 1, kde:
- 1 ukazuje, že dva vektory jsou identické a mají pozitivní podobnost.
- Hodnoty blízké 1 indikují vysokou pozitivní podobnost.
- Hodnoty blízké 0 znamenají, že vektory spolu úzce nesouvisí.
- Hodnoty blízké -1 znamenají vysokou nepodobnost.
- -1 znamená, že tyto dva vektory jsou zcela opačné a mají dokonalou negativní podobnost.
Navštivte toto odkaz pokud chcete lépe porozumět modelům word2vec a vizuální reprezentaci toho, jak fungují. Je to opravdu skvělý nástroj, jak vidět CBOW a přeskočit gram v akci.
Podobně jako Word2Vec máme GloVe. GloVe může vytvářet vložení, která vyžadují méně paměti ve srovnání s Word2Vec. Pojďme pochopit více o GloVe.
Rukavice
Globální vektory pro reprezentaci slov (GloVe) je technika jako word2vec. Používá se k reprezentaci slov jako vektorů v nepřetržitém prostoru. Koncept GloVe je stejný jako u Word2Vec: vytváří kontextová vkládání slov a přitom bere v úvahu vynikající výkon Word2Vec.
Proč potřebujeme GloVe?
Word2vec je metoda založená na okně a k pochopení slov používá blízká slova. To znamená, že sémantický význam cílového slova je ovlivněn pouze okolními slovy ve větách, což je neefektivní využití statistiky.
Zatímco GloVe zachycuje globální i místní statistiky, které přicházejí s vkládáním slov.
Kdy použít GloVe?
Použijte GloVe, když chcete vkládání slov, které zachycuje širší sémantické vztahy a globální asociace slov.
GloVe je lepší než jiné modely v úlohách rozpoznávání pojmenovaných entit, analogii slov a podobnosti slov.
Nejprve musíme nainstalovat Gensim:
pip install gensim
Krok 1: Chystáme se nainstalovat důležité knihovny
# Import the required libraries import numpy as np import matplotlib.pyplot as plt from sklearn.manifold import TSNE import gensim.downloader as api
Krok 2: Importujte model rukavice
import gensim.downloader as api
glove_model = api.load('glove-wiki-gigaword-300')
Krok 3: Načtěte vektorovou reprezentaci slova pro slovo „roztomilý“
glove_model["cute"]
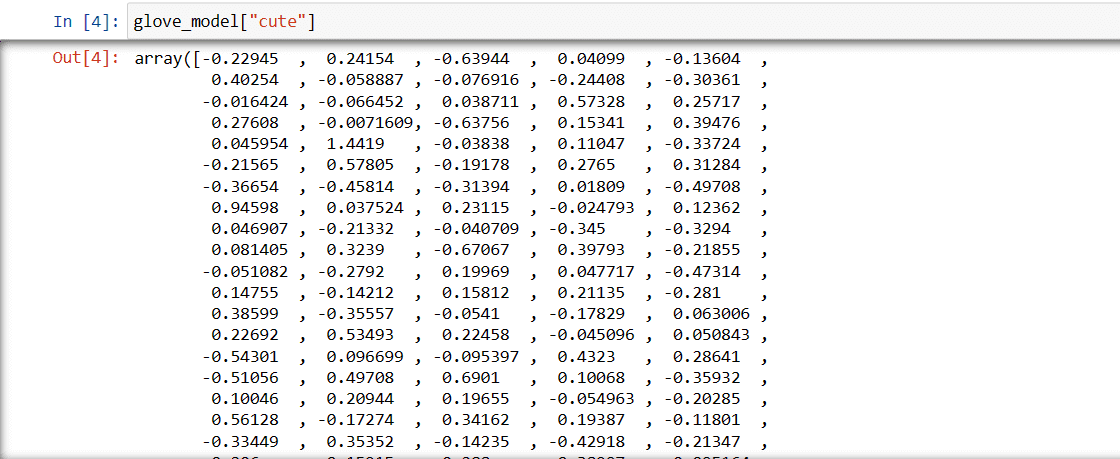 Vektor pro slovo „roztomilý“
Vektor pro slovo „roztomilý“
Tyto hodnoty zachycují význam slova a vztahy s jinými slovy. Kladné hodnoty označují pozitivní asociace s určitými koncepty, zatímco záporné hodnoty označují negativní asociace s jinými koncepty.
V modelu GloVe každý rozměr ve vektoru slova představuje určitý aspekt významu nebo kontextu slova.
Záporné a pozitivní hodnoty v těchto dimenzích přispívají k tomu, jak „roztomilý“ sémanticky souvisí s jinými slovy ve slovníku modelu.
Hodnoty se mohou u různých modelů lišit. Pojďme najít nějaká podobná slova ke slovu ‚chlapec‘
Top 10 podobných slov, která se podle modelky nejvíce podobají slovu „chlapec“
# find similar word
glove_model.most_similar("boy")
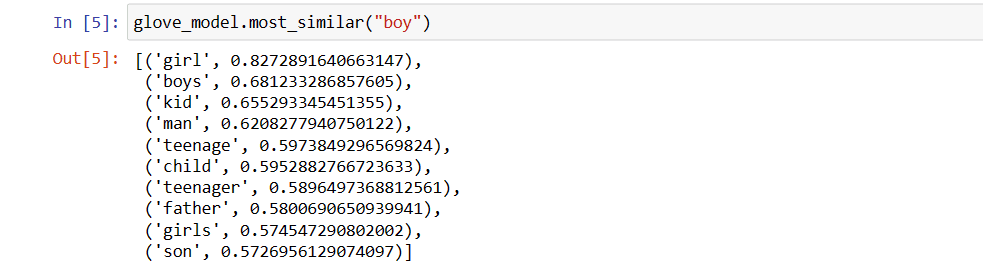 Top 10 podobných slov jako „chlapec“
Top 10 podobných slov jako „chlapec“
Jak vidíte, nejpodobnější slovo ‚chlapec‘ je ‚holka‘.
Nyní se pokusíme zjistit, jak přesně model získá sémantický význam z poskytnutých slov.
glove_model.most_similar(positive=['boy', 'queen'], negative=['girl'], topn=1)
 Nejrelevantnější slovo pro ‚královna‘
Nejrelevantnější slovo pro ‚královna‘
Náš model je schopen najít dokonalý vztah mezi slovy.
Definujte seznam slovíček:
Nyní se pokusme pochopit sémantický význam nebo vztah mezi slovy pomocí zápletky. Definujte seznam slov, která chcete zobrazit.
# Define the list of words you want to visualize vocab = ["boy", "girl", "man", "woman", "king", "queen", "banana", "apple", "mango", "cow", "coconut", "orange", "cat", "dog"]
Vytvořte matici vkládání:
Pojďme napsat kód pro vytvoření matice vkládání.
# Your code for creating the embedding matrix
EMBEDDING_DIM = glove_model.vectors.shape[1]
word_index = {word: index for index, word in enumerate(vocab)}
num_words = len(vocab)
embedding_matrix = np.zeros((num_words, EMBEDDING_DIM))
for word, i in word_index.items():
embedding_vector = glove_model[word]
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
Definujte funkci pro vizualizaci t-SNE:
Z tohoto kódu definujeme funkci pro náš vizualizační graf.
def tsne_plot(embedding_matrix, words):
tsne_model = TSNE(perplexity=3, n_components=2, init="pca", random_state=42)
coordinates = tsne_model.fit_transform(embedding_matrix)
x, y = coordinates[:, 0], coordinates[:, 1]
plt.figure(figsize=(14, 8))
for i, word in enumerate(words):
plt.scatter(x[i], y[i])
plt.annotate(word,
xy=(x[i], y[i]),
xytext=(2, 2),
textcoords="offset points",
ha="right",
va="bottom")
plt.show()
Podívejme se, jak náš pozemek vypadá:
# Call the tsne_plot function with your embedding matrix and list of words tsne_plot(embedding_matrix, vocab)
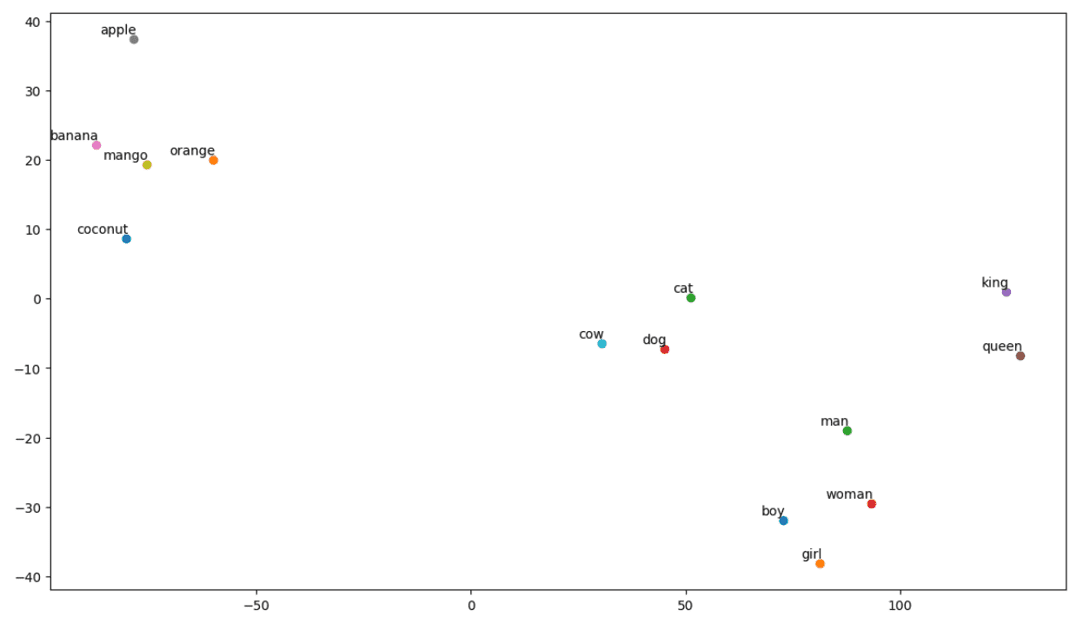 t-SNE pozemek
t-SNE pozemek
Takže, jak vidíme, na levé straně našeho pozemku jsou slova jako ‚banán‘, ‚mango‘, ‚pomeranč‘, ‚kokos‘ a ‚jablko‘. Zatímco „kráva“, „pes“ a „kočka“ jsou si navzájem podobné, protože jsou to zvířata.
Náš model tedy může najít sémantický význam a vztahy i mezi slovy!
Pouhou změnou slovníku nebo vytvořením modelu od začátku můžete experimentovat s různými slovy.
Tuto matici pro vkládání můžete použít, jak chcete. Může být aplikován na úlohy týkající se podobnosti slov samostatně nebo může být vložen do vkládací vrstvy neuronové sítě.
GloVe trénuje na matici společného výskytu, aby odvodila sémantický význam. Je založen na myšlence, že společné výskyty slov a slov jsou základním poznatkem a že jejich použití je efektivním způsobem, jak využít statistiky k vytváření vkládání slov. Tímto způsobem GloVe přidává „globální statistiky“ ke konečnému produktu.
A to je GloVe; Další populární metodou pro vektorizaci je FastText. Pojďme o tom diskutovat více.
FastText
FastText je knihovna s otevřeným zdrojovým kódem, kterou zavedl tým Facebook AI Research pro klasifikaci textu a analýzu sentimentu. FastText poskytuje nástroje pro trénování vkládání slov, které jsou hustými vektorovými slovy. To je užitečné pro zachycení sémantického významu dokumentu. FastText podporuje klasifikaci více štítků i více tříd.
Proč FastText?
FastText je lepší než jiné modely díky své schopnosti zobecňovat na neznámá slova, která u jiných metod chyběla. FastText poskytuje předem připravené vektory slov pro různé jazyky, které by mohly být užitečné v různých úkolech, kde potřebujeme předchozí znalosti o slovech a jejich významu.
 FastText vs Word2Vec
FastText vs Word2Vec
Jak to funguje?
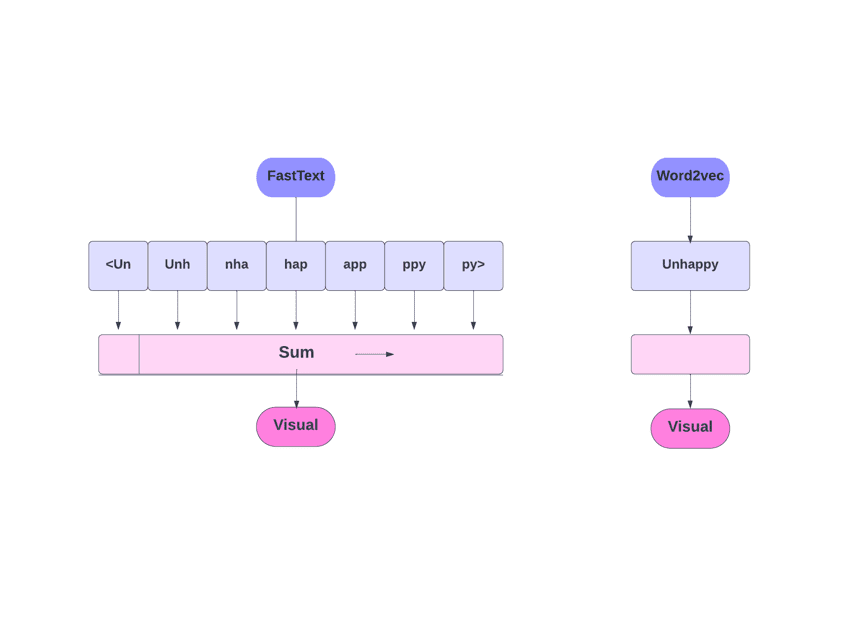
Jak jsme diskutovali, jiné modely, jako Word2Vec a GloVe, používají slova pro vkládání slov. Ale stavebním kamenem FastTextu jsou písmena místo slov. Což znamená, že používají písmena pro vkládání slov.
Použití znaků místo slov má ještě jednu výhodu. Pro školení je potřeba méně dat. Jakmile se slovo stane jeho kontextem, z textu lze získat více informací.
Word Embedding získaný přes FastText je kombinací vkládání nižší úrovně.
Nyní se podívejme, jak FastText využívá informace o podslovech.
Řekněme, že máme slovo „čtení“. Pro toto slovo by se znak n-gramů délky 3-6 vygeneroval následovně:
- Začátek a konec jsou označeny hranatými závorkami.
- Hašování se používá, protože tam může být velký počet n-gramů; místo toho, abychom se učili vložení pro každý odlišný n-gram, naučíme se celkové vložení B, kde B znamená velikost segmentu. V původním papíru byla použita velikost kyblíku 2 miliony.
- Každý znak n-gram, například „eadi“, je pomocí této hašovací funkce mapován na celé číslo mezi 1 a B a tento index má odpovídající vložení.
- Zprůměrováním těchto základních n-gramových vložení se pak získá úplné vložení slova.
- I když tento přístup hašování vede ke kolizím, do značné míry pomáhá zvládnout velikost slovní zásoby.
- Síť použitá ve FastTextu je podobná Word2Vec. Stejně jako tam můžeme FastText trénovat ve dvou režimech – CBOW a skip-gram. Tudíž tu část nemusíme znovu opakovat.
Můžete trénovat svůj vlastní model, nebo můžete použít předem trénovaný model. Použijeme předtrénovaný model.
Nejprve musíte nainstalovat FastText.
pip install fasttext
Použijeme datovou sadu, která se skládá z konverzačního textu o několika drogách, a tyto texty musíme roztřídit do 3 typů. Stejně jako s druhem drog, se kterými jsou spojeny.
 Dataset
Dataset
Nyní, abychom mohli trénovat model FastText na jakékoli datové sadě, musíme připravit vstupní data v určitém formátu, což je:
__label__
Udělejme to také pro naši datovou sadu.
all_texts = train['text'].tolist()
all_labels = train['drug type'].tolist()
prep_datapoints=[]
for i in range(len(all_texts)):
sample="__label__"+ str(all_labels[i]) + ' '+ all_texts[i]
prep_datapoints.append(sample)
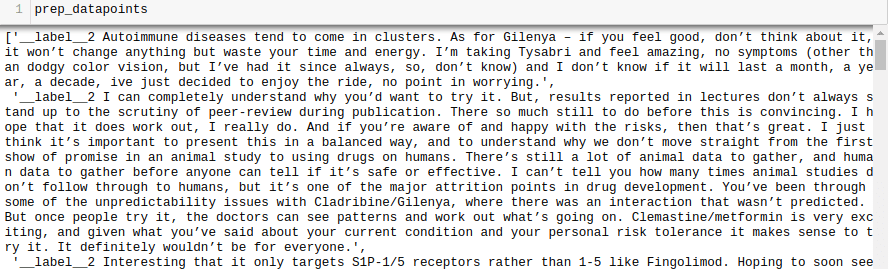 prep_datapoints
prep_datapoints
V tomto kroku jsme vynechali mnoho předzpracování. Jinak bude náš článek příliš velký. V reálných problémech je nejlepší provést předběžné zpracování, aby byla data vhodná pro modelování.
Nyní zapište připravené datové body do souboru .txt.
with open('train_fasttext.txt','w') as f:
for datapoint in prep_datapoints:
f.write(datapoint)
f.write('n')
f.close()
Pojďme trénovat náš model.
model = fasttext.train_supervised('train_fasttext.txt')
Předpovědi získáme z našeho modelu.

Model předpovídá označení a přiřadí mu skóre spolehlivosti.
Stejně jako u jakéhokoli jiného modelu závisí výkon tohoto na řadě proměnných, ale pokud chcete získat rychlou představu o očekávané přesnosti, FastText může být skvělou volbou.
Závěr
Závěrem lze říci, že metody vektorizace textu jako Bag of Words (BoW), TF-IDF, Word2Vec, GloVe a FastText poskytují různé možnosti pro úlohy NLP.
Zatímco Word2Vec zachycuje sémantiku slov a je adaptabilní pro různé úkoly NLP, BoW a TF-IDF jsou jednoduché a vhodné pro klasifikaci textu a doporučení.
Pro aplikace, jako je analýza sentimentu, GloVe nabízí předem vyškolená vložení a FastText si vede dobře při analýze na úrovni podslov, takže je užitečný pro strukturálně bohaté jazyky a rozpoznávání entit.
Výběr techniky závisí na úkolu, datech a zdrojích. O složitosti NLP budeme hovořit hlouběji v průběhu této série. Šťastné učení!
Dále se podívejte na nejlepší kurzy NLP, abyste se naučili zpracování přirozeného jazyka.