Data Lakehouse: Napájení vaší cesty řízené daty
Data Lakehouse představuje nově vznikající přístup ke správě dat, který v sobě spojuje klíčové výhody datových jezer a datových skladů. S využitím Data Lakehouse získáte možnost ukládat rozmanité typy dat na jednotné platformě a provádět dotazy a analýzy s garancí ACID vlastností.
Proč je tedy datové jezero tak výhodné? Jako zkušený softwarový inženýr chápu, jak náročné je spravovat a udržovat dva oddělené systémy a zajišťovat tok velkého množství dat mezi nimi.
Pokud máte v plánu využívat svá data pro obchodní analýzy a generování reportů, je nezbytné ukládat strukturovaná data do datového skladu. Na druhou stranu, pro ukládání všech dat pocházejících z různých zdrojů v původním formátu je vhodné datové jezero. Koncept lakehouse odstraňuje nutnost udržovat různé systémy, protože spojuje to nejlepší z obou světů.
Význam Data Lakehouse
Pro růst vaší organizace a podnikání je klíčové být schopen ukládat a analyzovat data bez ohledu na jejich formát či strukturu. Data lakehouse mají zásadní význam pro moderní správu dat, jelikož překonávají omezení jak datových jezer, tak datových skladů.
Datová jezera se často mohou proměnit v datové bažiny, kde jsou data ukládána bez jakékoliv organizace nebo správy. To komplikuje vyhledávání a využití dat a může vést k problémům s jejich kvalitou. Na druhé straně, datové sklady bývají příliš rigidní a nákladné.
Data lakehouse se vyznačují specifickými charakteristikami. Podívejme se na ně.
Charakteristika Data Lakehouse
Než se detailně podíváme na architekturu Data Lakehouse, shrňme si nejdůležitější vlastnosti a charakteristiky tohoto konceptu.
- Podpora transakcí: Při provozování datového lakehouse ve větším měřítku dochází ke čtení i zápisu dat současně. Kompatibilita s ACID vlastnostmi zaručuje, že souběžné operace nemají negativní vliv na data.
- Podpora Business Intelligence: Nástroje BI lze připojit přímo k indexovaným datům. Odpadá tak potřeba kopírovat data na jiné místo. Získáte navíc nejaktuálnější data v kratším čase a za nižší cenu.
- Oddělení úložiště a výpočetní vrstvy: Díky oddělení těchto vrstev můžete škálovat jednu z nich nezávisle na druhé. Pokud potřebujete více úložného prostoru, můžete ho přidat, aniž byste museli navyšovat výpočetní kapacitu.
- Podpora různých typů dat: Data Lakehouse, vycházejíc z konceptu datového jezera, podporuje různé typy a formáty dat. Můžete ukládat a analyzovat rozličné druhy dat, jako je zvuk, video, obrázky nebo text.
- Otevřenost formátů úložiště: Data lakehouse využívají otevřené a standardizované formáty úložiště, například Apache Parquet. To umožňuje připojení různých nástrojů a knihoven pro přístup k datům.
- Podpora rozmanitých pracovních zátěží: S daty uloženými v Data Lakehouse můžete provádět širokou škálu úkolů. Patří sem SQL dotazy, BI analýzy, analytické úlohy a strojové učení.
- Podpora streamování v reálném čase: Pro analýzu v reálném čase není nutné vytvářet oddělené úložiště dat a provozovat samostatný datový kanál.
- Správa schématu: Data Lakehouse podporují robustní správu dat a audity.
Architektura Data Lakehouse
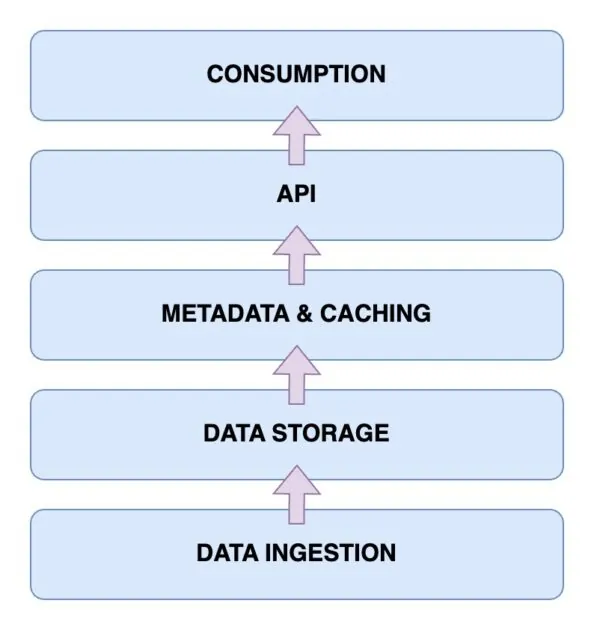
Nyní se podíváme na samotnou architekturu Data Lakehouse. Její pochopení je klíčové pro pochopení principu fungování. Architektura Data Lakehouse se skládá z pěti hlavních komponent. Probereme si je postupně jednu po druhé.
Vrstva příjmu dat
Tato vrstva slouží k zachycení všech různých dat v různých formátech. Může jít o změny v primární databázi, data z IoT senzorů nebo uživatelská data proudící v reálném čase.
Vrstva úložiště dat
Jakmile jsou data zpracována z různých zdrojů, je čas je uložit ve správných formátech. Zde přichází na řadu úložná vrstva. Data je možné ukládat na různá média, například AWS S3. Jedná se vlastně o vaše datové jezero.
Metadata a mezipaměťová vrstva
Po vytvoření vrstvy úložiště dat je potřeba vrstva pro správu metadat. Ta poskytuje jednotný pohled na všechna data uložená v datovém jezeře. Tato vrstva také přidává transakce ACID do stávajícího datového jezera, čímž ho přemění na Data Lakehouse.
Vrstva API
K indexovaným datům z vrstvy metadat je možné přistupovat pomocí vrstvy API. Ta může být reprezentována databázovými ovladači umožňujícími spouštění dotazů přes kód, nebo ve formě koncových bodů, ke kterým je možné přistupovat z libovolného klienta.
Vrstva spotřeby dat
Do této vrstvy spadají analytické nástroje a nástroje Business Intelligence, které jsou hlavními uživateli dat z Data Lakehouse. Zde můžete spouštět programy strojového učení pro získání cenných poznatků z uložených a indexovaných dat.
Nyní máte jasnou představu o architektuře Lakehouse. Jak ale takový systém vybudovat?
Kroky pro vybudování Data Lakehouse
Podívejme se, jakým způsobem si můžete postavit vlastní Data Lakehouse. Bez ohledu na to, zda už máte existující datové jezero nebo sklad, či začínáte od nuly, kroky jsou obdobné.
- Identifikace požadavků: Zahrnuje určení, jaké typy dat budete ukládat a na jaké případy použití se chcete zaměřit. Může se jednat o modely strojového učení, obchodní reporty nebo analýzy.
- Vytvoření kanálu příjmu dat: Kanál příjmu dat je zodpovědný za přenos dat do systému. V závislosti na zdrojových systémech, které data generují, můžete využít například message queue jako Apache Kafka, nebo API koncové body.
- Vytvoření úložné vrstvy: Pokud už máte datové jezero, může sloužit jako úložná vrstva. V opačném případě si můžete vybrat z různých možností, jako je AWS S3, HDFS, nebo Delta Lake.
- Aplikování zpracování dat: Zde získáváte a transformujete data na základě vašich obchodních požadavků. Můžete využít open-source nástroje jako Apache Spark pro spouštění pravidelných úloh, které budou přijímat a zpracovávat data z vaší úložné vrstvy.
- Vytvoření správy metadat: Potřebujete sledovat a ukládat různé druhy dat a jejich odpovídající vlastnosti, aby je bylo možné v případě potřeby snadno katalogizovat a vyhledávat. Můžete také chtít vytvořit vrstvu mezipaměti.
- Poskytnutí možností integrace: Nyní, když je váš primární Lakehouse připraven, budete muset poskytnout integrační mechanismy, kam se mohou připojit externí nástroje a získat přístup k datům. Může se jednat o SQL dotazy, nástroje strojového učení, nebo Business Intelligence řešení.
- Implementace správy dat: Jelikož pracujete s různými druhy dat z různých zdrojů, musíte vytvořit zásady správy dat, včetně řízení přístupu, šifrování a auditování. Cílem je zajistit kvalitu dat, jejich konzistenci a soulad s předpisy.
Dále se podíváme, jak můžete migrovat do Data Lakehouse, pokud máte stávající řešení pro správu dat.
Kroky pro migraci do Data Lakehouse
Při migraci vaší datové zátěže na řešení Data Lakehouse byste měli mít na paměti určité kroky. Akční plán vám umožní předejít problémům na poslední chvíli.
Krok 1: Analyzujte data
Prvním a nejdůležitějším krokem pro úspěšnou migraci je analýza dat. Správnou analýzou můžete definovat rozsah migrace a identifikovat případné závislosti. Získáte tak lepší přehled o prostředí a o tom, co budete migrovat. To vám umožní lépe stanovit priority.
Krok 2: Připravte data pro migraci
Dalším krokem je příprava dat. Zahrnuje to jak data, která budete migrovat, tak i podpůrné datové rámce, které budete potřebovat. Namísto čekání na dostupnost všech dat v Lakehouse můžete zjistit, které datové sady a sloupce jsou skutečně potřeba, čímž ušetříte drahocenný čas a zdroje.
Krok 3: Převeďte data do požadovaného formátu
Můžete využít automatickou konverzi. Při migraci na Data Lakehouse je konverze dat často komplexní. Většina nástrojů však nabízí snadno čitelný SQL kód nebo low-code řešení. Nástroje jako Alchymista vám s tím mohou pomoci.
Krok 4: Ověřte data po migraci
Po dokončení migrace je čas data ověřit. V tomto kroku je vhodné maximálně automatizovat proces ověřování. Ruční migrace je náročná a zpomaluje celý proces. Ověření by mělo proběhnout jako poslední krok. Důležité je ověřit, že vaše obchodní procesy a datové úlohy zůstanou po migraci beze změny.
Klíčové vlastnosti Data Lakehouse
🔷 Kompletní správa dat: Získáte funkce správy dat, které vám pomohou využít data na maximum. Jedná se o čištění dat, proces ETL (Extract-Transform-Load) a vynucení schématu. Data tak můžete jednoduše vyčistit a připravit pro další analýzy a BI nástroje.
🔷 Otevřené formáty úložiště: Formát úložiště je otevřený a standardizovaný. To znamená, že všechna data ze zdrojů jsou ukládána podobně a můžete s nimi pracovat od počátku. Podporovány jsou formáty jako AVRO, ORC, nebo Parquet. Kromě toho jsou podporovány i tabulkové formáty dat.
🔷 Oddělení úložiště: Úložiště je možné oddělit od výpočetních zdrojů. Toho se dosáhne pomocí samostatných clusterů pro obě komponenty. Úložiště můžete škálovat nezávisle na výpočetních zdrojích, a to podle potřeb.
🔷 Podpora streamování dat: Rozhodování na základě dat často zahrnuje spotřebu datových streamů v reálném čase. Data Lakehouse poskytuje podporu příjmu dat v reálném čase, na rozdíl od standardního datového skladu.
🔷 Správa dat: Systém podporuje silnou správu dat a audity. Tyto prvky jsou zásadní pro zachování integrity dat.
🔷 Snížené náklady na data: Provozní náklady Data Lakehouse jsou nižší než u datového skladu. Můžete využít cloudové objektové úložiště za nižší cenu. Navíc získáte hybridní architekturu. To eliminuje nutnost udržovat více systémů pro ukládání dat.
Data Lake vs. Data Warehouse vs. Data Lakehouse
| Vlastnost | Data Lake | Data Warehouse | Data Lakehouse |
| Úložiště dat | Ukládá nezpracovaná nebo nestrukturovaná data | Ukládá zpracovaná a strukturovaná data | Ukládá surová i strukturovaná data |
| Schéma dat | Nemá pevné schéma | Má pevné schéma | Používá k integraci schéma open source |
| Transformace dat | Data nejsou transformována | Rozsáhlá shoda s ETL dle potřeby | ACID, ETL |
| Výkon dotazů | Typicky pomalejší, protože data jsou nestrukturovaná | Velmi rychlá díky strukturovaným datům | Rychlá díky polostrukturovaným datům |
| Náklady | Úložiště je nákladově efektivní | Vyšší náklady na úložiště a dotazy | Náklady na úložiště a dotazy jsou vyvážené |
| Správa dat | Vyžaduje pečlivou správu | Potřebná analýza v reálném čase | Podpora řízení, auditu a shody s předpisy |
| Analýza | Podporuje analýzu v reálném čase | Reporty a analýzy pomocí BI | Strojové učení i analytika |
Závěr
Díky spojení silných stránek datových jezer i datových skladů řeší Data Lakehouse důležité výzvy spojené se správou a analýzou dat.
Nyní znáte charakteristiky i architekturu Data Lakehouse. Jeho význam je zřejmý v jeho schopnosti pracovat se strukturovanými i nestrukturovanými daty a nabízí tak jednotnou platformu pro ukládání, dotazy i analýzy. Navíc získáte soulad s ACID vlastnostmi.
S využitím kroků uvedených v tomto článku pro budování a migraci na Data Lakehouse můžete odemknout výhody jednotné a nákladově efektivní platformy pro správu dat. Udržujte krok s moderními trendy správy dat a řiďte rozhodování na základě dat, analytiku a obchodní růst.
Přečtěte si také náš podrobný článek o replikaci dat.
