
Python je velmi všestranný jazyk a vývojáři Pythonu musí často pracovat s různými soubory a získávat informace v nich uložené ke zpracování. Jedním z oblíbených formátů souborů, se kterými se jako vývojáři Pythonu musíte setkat, je formát Portable Document Format, známý jako PDF.
Soubory PDF mohou obsahovat text, obrázky a odkazy. Při zpracovávání dat v programu Python můžete zjistit, že potřebujete extrahovat data uložená v dokumentu PDF. Na rozdíl od datových struktur, jako jsou n-tice, seznamy a slovníky, se získání informací uložených v dokumentu PDF může zdát jako obtížná věc.
Naštěstí existuje řada knihoven, které usnadňují práci s PDF a extrahují data uložená v souborech PDF. Chcete-li se dozvědět o těchto různých knihovnách, podívejme se, jak můžete extrahovat texty, odkazy a obrázky ze souborů PDF. Chcete-li pokračovat, stáhněte si následující soubor PDF a uložte jej do stejného adresáře jako soubor programu Python.
Chcete-li extrahovat text ze souborů PDF pomocí Pythonu, použijeme PyPDF2 knihovna. PyPDF2 je bezplatná a open source knihovna Pythonu, kterou lze použít ke sloučení, oříznutí a transformaci stránek souborů PDF. Do souborů PDF může přidávat vlastní data, možnosti zobrazení a hesla. Důležité však je, že PyPDF2 dokáže načíst text ze souborů PDF.
Chcete-li použít PyPDF2 k extrahování textu ze souborů PDF, nainstalujte jej pomocí pip, což je instalátor balíčků pro Python. pip vám umožňuje nainstalovat různé balíčky Pythonu na váš počítač:
1. Zkontrolujte, zda již máte nainstalovaný pip spuštěním:
pip --version
Pokud nedostanete zpět číslo verze, znamená to, že pip není nainstalován.
2. Chcete-li nainstalovat pip, klikněte na dostat pip stáhnout jeho instalační skript.
Odkaz otevře stránku se skriptem pro instalaci pip, jak je znázorněno níže:
Klikněte pravým tlačítkem na stránku a kliknutím na Uložit jako soubor uložte. Ve výchozím nastavení je název souboru get-pip.py
Otevřete terminál a přejděte do adresáře se souborem get-pip.py, který jste právě stáhli, a poté spusťte příkaz:
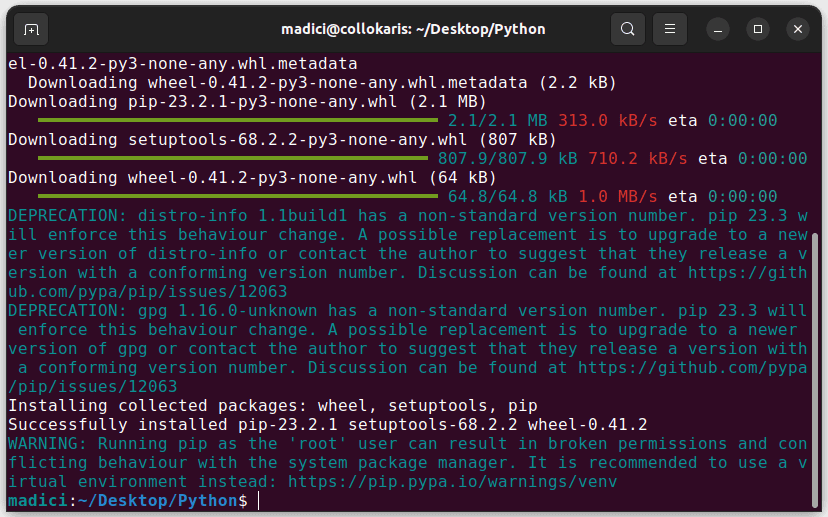
sudo python3 get-pip.py
To by mělo nainstalovat pip, jak je znázorněno níže:
3. Zkontrolujte, zda byl pip úspěšně nainstalován spuštěním:
pip --version
V případě úspěchu byste měli získat číslo verze:

S nainstalovaným pipem můžeme nyní začít pracovat s PyPDF2.
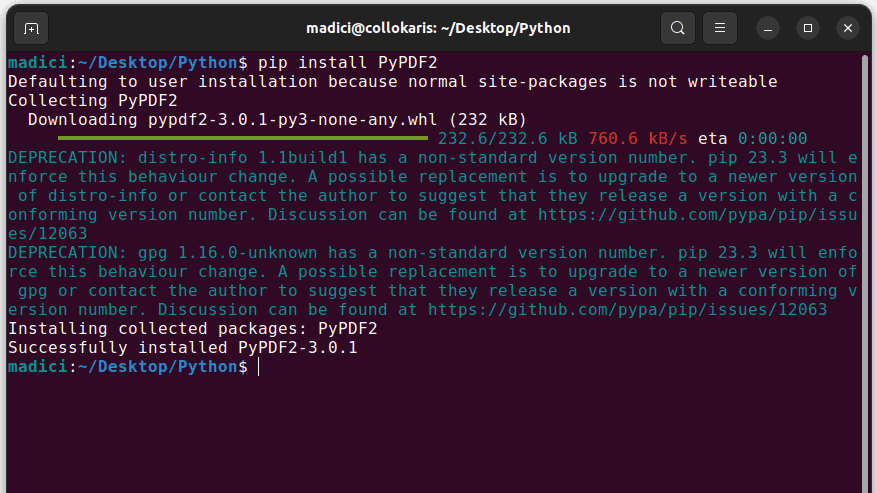
1. Nainstalujte PyPDF2 provedením následujícího příkazu v terminálu:
pip install PyPDF2
2. Vytvořte soubor Python a importujte PdfReader z PyPDF2 pomocí následujícího řádku:
from PyPDF2 import PdfReader
Knihovna PyPDF2 poskytuje různé třídy pro práci se soubory PDF. Jednou z takových tříd je PdfReader, kterou lze mimo jiné použít k otevírání souborů PDF, čtení obsahu a extrahování textu ze souborů PDF.
3. Chcete-li začít pracovat se souborem PDF, musíte soubor nejprve otevřít. Chcete-li to provést, vytvořte instanci třídy PdfReader a předejte soubor PDF, se kterým chcete pracovat:
reader = PdfReader('games.pdf')
Řádek výše vytvoří instanci PdfReader a připraví jej pro přístup k obsahu souboru PDF, který určíte. Instance je uložena v proměnné nazvané reader, která bude mít přístup k řadě metod a vlastností dostupných ve třídě PdfReader.
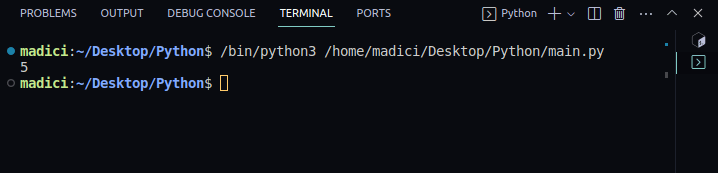
4. Chcete-li zjistit, zda vše funguje správně, vytiskněte počet stránek v souboru PDF, který jste předali, pomocí následujícího kódu:
print(len(reader.pages))
Výstup:
5
5. Protože náš soubor PDF má 5 stránek, máme přístup ke každé stránce dostupné v PDF. Počítání však začíná od 0, stejně jako indexovací konvence Pythonu. První stránka v souboru PDF bude tedy číslo stránky 0. Chcete-li načíst první stránku PDF, přidejte do kódu následující řádek:
page1 = reader.pages[0]
Řádek výše načte první stránku v souboru PDF a uloží ji do proměnné s názvem page1.
6. Chcete-li extrahovat text na první stránce souboru PDF, přidejte následující řádek:
textPage1 = page1.extract_text()
Tím se extrahuje text na první stránce PDF a obsah se uloží do proměnné s názvem textPage1. Máte tak přístup k textu na první stránce souboru PDF prostřednictvím proměnné textPage1.
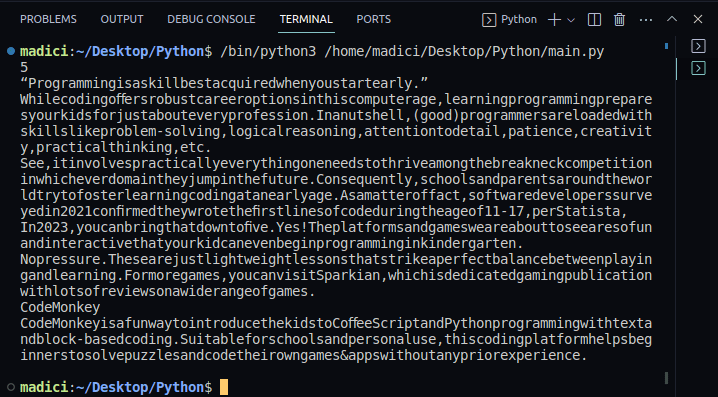
7. Chcete-li potvrdit, že byl text extrahován úspěšně, můžete vytisknout obsah proměnné textPage1. Celý náš kód, který také vytiskne text na první stránce souboru PDF, je zobrazen níže:
# import the PdfReader class from PyPDF2
from PyPDF2 import PdfReader
# create an instance of the PdfReader class
reader = PdfReader('games.pdf')
# get the number of pages available in the pdf file
print(len(reader.pages))
# access the first page in the pdf
page1 = reader.pages[0]
# extract the text in page 1 of the pdf file
textPage1 = page1.extract_text()
# print out the extracted text
print(textPage1)
Výstup:
Chcete-li extrahovat odkazy ze souborů PDF, přejdeme do PyMuPDF, což je knihovna Pythonu pro extrahování, analýzu, konverzi a manipulaci s daty uloženými v dokumentech, jako jsou soubory PDF. Chcete-li používat PyMuPDF, měli byste mít Python 3.8 nebo novější. Začít:
1. Nainstalujte PyMuPDF provedením následujícího řádku v terminálu:
pip install PyMuPDF
2. Importujte PyMuPDF do svého souboru Python pomocí následujícího příkazu:
import fitz
3. Chcete-li získat přístup k PDF, ze kterého chcete extrahovat odkazy, musíte jej nejprve otevřít. Chcete-li jej otevřít, zadejte následující řádek:
doc = fitz.open("games.pdf")
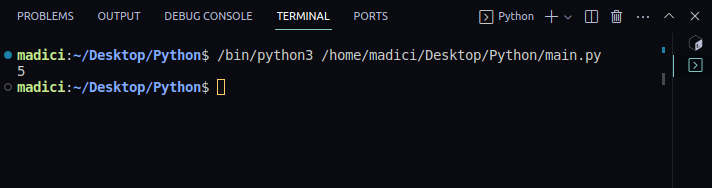
4. Po otevření souboru PDF vytiskněte počet stránek v PDF pomocí následujícího řádku:
print(doc.page_count)
Výstup:
5
4. Chcete-li extrahovat odkazy ze stránky v souboru PDF, musíme načíst stránku, ze které chceme odkazy extrahovat. Chcete-li načíst stránku, zadejte následující řádek, kde předáte číslo stránky, kterou chcete načíst, do funkce nazvané load_page()
page = doc.load_page(0)
Abychom extrahovali odkazy z první stránky, předáme 0 (nula). Počítání stránek začíná od nuly stejně jako v datových strukturách, jako jsou pole a slovníky.
5. Extrahujte odkazy ze stránky pomocí následujícího řádku:
links = page.get_links()
Všechny odkazy na vámi zadané stránce, v našem případě na stránce 1, budou extrahovány a uloženy do proměnné nazvané odkazy
6. Chcete-li zobrazit obsah proměnné odkazů, vytiskněte ji takto:
print(links)
Výstup:
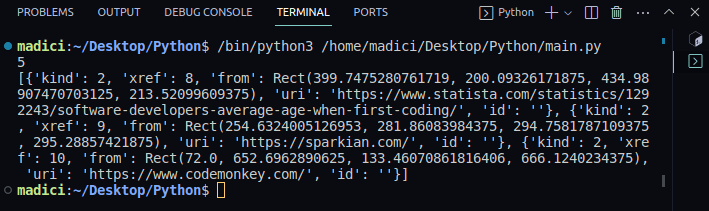
Z tištěného výstupu si všimněte, že odkazy na proměnné obsahují seznam slovníků s páry klíč–hodnota. Každý odkaz na stránce je reprezentován slovníkem, přičemž aktuální odkaz je uložen pod klíčem „uri“
7. Chcete-li získat odkazy ze seznamu objektů uložených pod proměnnými odkazy, iterujte seznam pomocí příkazu for in a vytiskněte konkrétní odkazy uložené pod klíčem uri. Celý kód, který to dělá, je zobrazen níže:
import fitz
# Open the PDF file
doc = fitz.open("games.pdf")
# Print out the number of pages
print(doc.page_count)
# load the first page from the PDF
page = doc.load_page(0)
# extract all links from the page and store it under - links
links = page.get_links()
# print the links object
#print(links)
# print the actual links stored under the key "uri"
for obj in links:
print(obj["uri"])
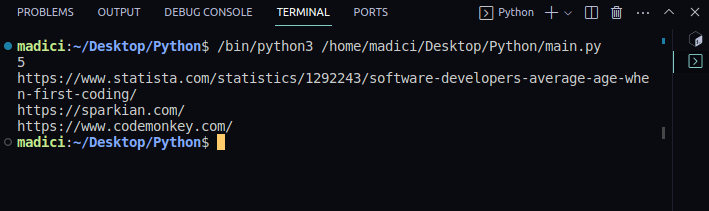
Výstup:
5 https://www.statista.com/statistics/1292243/software-developers-average-age-when-first-coding/ https://sparkian.com/ https://www.codemonkey.com/
8. Aby byl náš kód opětovněji použitelný, můžeme jej refaktorovat definováním funkce pro extrahování všech odkazů v PDF a funkce pro tisk všech odkazů nalezených v PDF. Tímto způsobem můžete volat funkce s jakýmkoli PDF a získáte zpět všechny odkazy v PDF. Kód, který to dělá, je zobrazen níže:
import fitz
# Extract all the links in a PDF document
def extract_link(path_to_pdf):
links = []
doc = fitz.open(path_to_pdf)
for page_num in range(doc.page_count):
page = doc.load_page(page_num)
page_links = page.get_links()
links.extend(page_links)
return links
# print out all the links returned from the PDF document
def print_all_links(links):
for link in links:
print(link["uri"])
# Call the function to extract all the links in a pdf
# all the return links are stored under all_links
all_links = extract_link("games.pdf")
# call the function to print all links in the PDF
print_all_links(all_links)
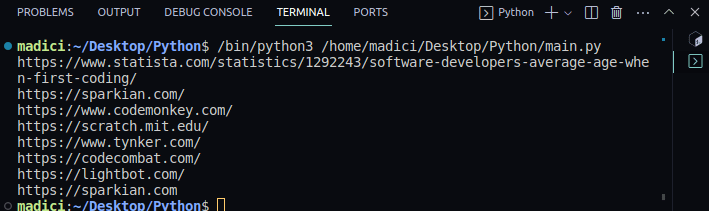
Výstup:
https://www.statista.com/statistics/1292243/software-developers-average-age-when-first-coding/ https://sparkian.com/ https://www.codemonkey.com/ https://scratch.mit.edu/ https://www.tynker.com/ https://codecombat.com/ https://lightbot.com/ https://sparkian.com
Z výše uvedeného kódu funkce extract_link() přijme soubor PDF, iteruje všechny stránky v PDF, extrahuje všechny odkazy a vrátí je. Výsledek této funkce je uložen v proměnné s názvem all_links
Funkce print_all_links() převezme výsledek extract_link(), iteruje seznam a vytiskne všechny skutečné odkazy nalezené v PDF, které jste předali do funkce extract_link().
K extrahování obrázků z PDF budeme stále používat PyMuPDF. Chcete-li extrahovat obrázky ze souboru PDF:
1. Importujte PyMuPDF, io a PIL. Python Imaging Library (PIL) poskytuje nástroje, které kromě jiných funkcí usnadňují vytváření a ukládání obrázků. io poskytuje třídy pro snadnou a efektivní manipulaci s binárními daty.
import fitz from io import BytesIO from PIL import Image
2. Otevřete soubor PDF, ze kterého chcete extrahovat obrázky:
doc = fitz.open("games.pdf")
3. Načtěte stránku, ze které chcete extrahovat obrázky:
page = doc.load_page(0)
4. PyMuPdf identifikuje obrázky v souboru PDF pomocí křížového referenčního čísla (xref), což je obvykle celé číslo. Každý obrázek v souboru PDF má jedinečnou externí referenci. Proto, abychom extrahovali obrázek z PDF, musíme nejprve získat číslo externí reference, které jej identifikuje. Abychom získali xref číslo obrázků na stránce, použijeme funkci get_images() takto:
image_xref = page.get_images() print(image_xref)
Výstup:
[(7, 0, 699, 407, 8, 'DeviceRGB', '', 'X7', 'FlateDecode')]
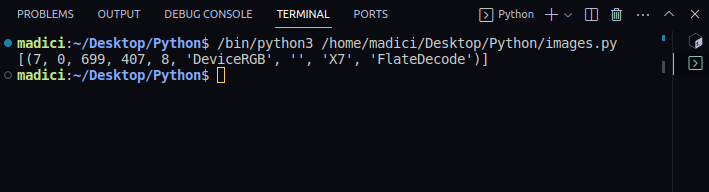
get_images() vrací seznam n-tic s informacemi o obrázku. Vzhledem k tomu, že na první stránce máme pouze jeden obrázek, je zde pouze jedna n-tice. První prvek v n-tice představuje externí referenci obrázku na stránce. Proto je xref obrázku na první stránce 7.
5. K extrahování hodnoty xref pro obrázek ze seznamu n-tic použijeme níže uvedený kód:
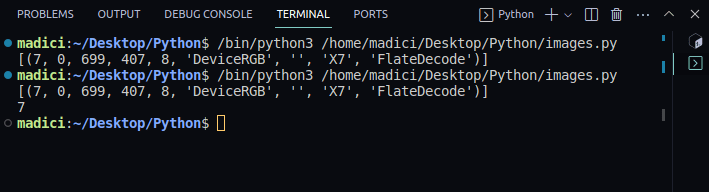
# get xref value of the image xref_value = image_xref[0][0] print(xref_value)
Výstup:
[(7, 0, 699, 407, 8, 'DeviceRGB', '', 'X7', 'FlateDecode')] 7
6. Protože nyní máte externí referenci, která identifikuje obrázek v PDF, můžete obrázek extrahovat pomocí funkce extract_image() takto:
img_dictionary = doc.extract_image(xref_value)
Tato funkce však nevrací skutečný obraz. Místo toho vrací slovník obsahující mimo jiné binární obrazová data obrázku a metadata o obrázku.
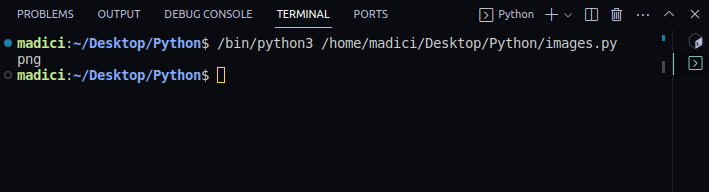
7. Ve slovníku vráceném funkcí extract_image() zkontrolujte příponu souboru extrahovaného obrázku. Přípona souboru je uložena pod klíčem „ext“:
# get file extenstion img_extension = img_dictionary["ext"] print(img_extension)
Výstup:
png
8. Extrahujte binární soubory obrázků ze slovníku uloženého v img_dictionary. Binární soubory obrázků jsou uloženy pod klíčem „image“
# get the actual image binary data img_binary = img_dictionary["image"]
9. Vytvořte objekt BytesIO a inicializujte jej s daty binárního obrazu, která představují obraz. Tím se vytvoří objekt podobný souboru, který lze zpracovat knihovnami Pythonu, jako je PIL, abyste mohli uložit obrázek.
# create a BytesIO object to work with the image bytes image_io = BytesIO(img_binary)
10. Otevřete a analyzujte data obrázku uložená v objektu BytesIO s názvem image_io pomocí knihovny PIL. To je důležité, protože umožňuje knihovně PIL určit formát obrázku, se kterým se pokoušíte pracovat, v tomto případě PNG. Po zjištění formátu obrázku PIL vytvoří objekt obrázku, se kterým lze manipulovat pomocí funkcí a metod PIL, jako je metoda save() a uložit obrázek do místního úložiště.
# open the image using Pillow image = Image.open(image_io)
11. Zadejte cestu, kam chcete obrázek uložit.
output_path = "image_1.png"
Protože výše uvedená cesta obsahuje pouze název souboru s jeho příponou, bude extrahovaný obrázek uložen ve stejném adresáři jako soubor Python obsahující tento program. Obrázek bude uložen jako image_1.png. Přípona PNG je důležitá, aby odpovídala původní příponě obrázku.
12. Uložte obraz a zavřete objekt ByteIO.
# save the image image.save(output_path) # Close the BytesIO object image_io.close()
Celý kód pro extrahování obrázku ze souboru PDF je zobrazen níže:
import fitz
from io import BytesIO
from PIL import Image
doc = fitz.open("games.pdf")
page = doc.load_page(0)
# get a cross reference(xref) to the image
image_xref = page.get_images()
# get the actual xref value of the image
xref_value = image_xref[0][0]
# extract the image
img_dictionary = doc.extract_image(xref_value)
# get file extenstion
img_extension = img_dictionary["ext"]
# get the actual image binary data
img_binary = img_dictionary["image"]
# create a BytesIO object to work with the image bytes
image_io = BytesIO(img_binary)
# open the image using PIL library
image = Image.open(image_io)
#specify the path where you want to save the image
output_path = "image_1.png"
# save the image
image.save(output_path)
# Close the BytesIO object
image_io.close()
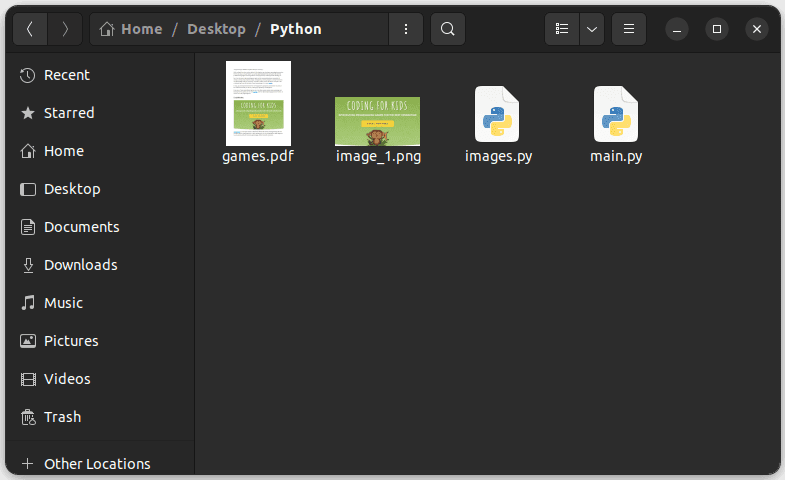
Spusťte kód a přejděte do složky obsahující váš soubor Python; měli byste vidět extrahovaný obrázek s názvem image_1.png, jak je ukázáno níže:
Závěr
Chcete-li si více procvičit extrahování odkazů, obrázků a textů z PDF, zkuste kód v příkladech přefaktorovat, aby byly znovu použitelné, jak ukazuje příklad odkazů. Tímto způsobem budete muset předat pouze soubor PDF a váš program Python extrahuje všechny odkazy, obrázky nebo text v celém PDF. Šťastné kódování!
Můžete také prozkoumat některá nejlepší PDF API pro každou obchodní potřebu.