
Pokud Linux nějakou dobu používáte, již znáte grep — Global Regular Expression Print, nástroj pro zpracování textu, který můžete použít k prohledávání souborů a adresářů. V rukou zkušeného uživatele Linuxu je velmi užitečný. Použití bez regulárního výrazu však může omezit jeho možnosti.
Ale co je Regex?
Regex jsou regulární výrazy, které můžete použít ke zlepšení funkce vyhledávání grep. Regex je podle definice pokročilý vzor výstupního filtrování. S praxí můžete regex efektivně používat, stejně jako jej můžete použít s jinými příkazy Linuxu.
V našem tutoriálu se naučíme, jak efektivně používat Grep a Regex.
Table of Contents
Předpoklad
Použití grep s regulárním výrazem vyžaduje dobrou znalost Linuxu. Pokud jste začátečník, podívejte se na naše průvodce Linuxem.
Potřebujete také přístup k notebooku nebo počítači s operačním systémem Linux. Můžete použít jakoukoli linuxovou distribuci dle vašeho výběru. A pokud máte počítač s Windows, stále můžete používat Linux s WSL2. Podívejte se na náš podrobný přehled zde.
Přístup k příkazovému řádku/terminálu vám umožňuje spouštět všechny příkazy uvedené v našem tutoriálu grep/regex.
Dále také potřebujete přístup k textovým souborům, které budete potřebovat ke spuštění příkladů. Použil jsem ChatGPT ke generování textové stěny a řekl jsem jí, aby psala o technice. Výzva, kterou jsem použil, je níže.
„Vygenerujte 400 slov na technice. Mělo by obsahovat většinu techniky. Také se ujistěte, že v textu opakujete názvy technologií.“
Jakmile vygeneroval text, zkopíroval jsem ho a vložil a uložil do souboru tech.txt, který budeme používat v celém tutoriálu.
A konečně, základní znalost příkazu grep je nutností. Můžete se podívat na 16 příkladů příkazů grep, abyste si osvěžili své znalosti. Pro začátek si také krátce představíme příkaz grep.
Syntaxe a příklady příkazu grep
Syntaxe příkazu grep je jednoduchá.
$ grep -options [regex/pattern] [files]
Jak si můžete všimnout, očekává vzor a seznam souborů, ve kterých chcete příkaz spustit.
K dispozici je spousta možností grep, které upravují jeho funkčnost. Tyto zahrnují:
- – i: ignorovat případy
- -r: provede rekurzivní vyhledávání
- -w: proveďte vyhledávání, abyste našli pouze celá slova
- -v: zobrazí všechny neodpovídající řádky
- -n: zobrazí všechna odpovídající čísla řádků
- -l: vytiskne názvy souborů
- –color: barevný výstup
- -c: zobrazí počet shod pro použitý vzor
#1. Hledejte celé slovo
Pro vyhledávání celého slova budete muset použít argument -w s grep. Jeho použitím obejdete všechny řetězce, které odpovídají danému vzoru.
$ grep -w ‘tech\|5G’ tech.txt
Jak vidíte, výsledkem příkazu je výstup, kde hledá dvě slova, „5G“ a „tech“, v celém textu. Poté je označí červenou barvou.
Zde | symbol roury je escapován, aby jej grep nezpracoval jako metaznak.
#2. Vyhledávání nerozlišující malá a velká písmena
Chcete-li provést vyhledávání bez ohledu na velikost písmen, použijte grep s argumentem -i.
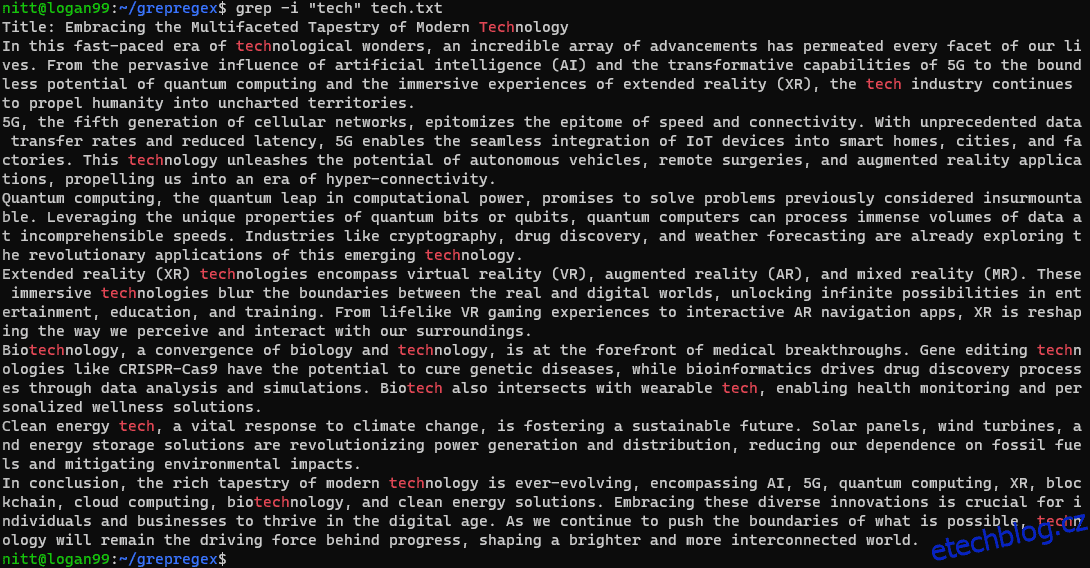
$ grep -i ‘tech’ tech.txt
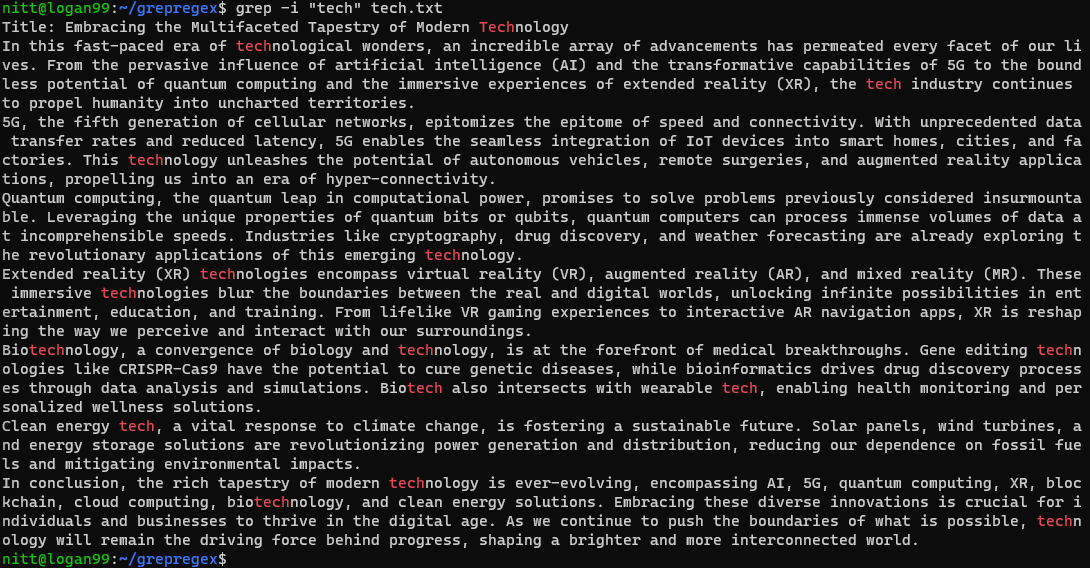
Příkaz hledá jakoukoli instanci řetězce „tech“ bez ohledu na velikost písmen, ať už je to celé slovo nebo jeho část.
#3. Proveďte vyhledávání neodpovídajících řádků
Chcete-li zobrazit všechny řádky, které neobsahují daný vzor, budete muset použít argument -v.
$ grep -v ‘tech’ tech.txt

Výstup zobrazuje všechny řádky, které neobsahují slovo „tech“. Také uvidíte prázdné řádky. Tyto řádky jsou řádky, které jsou za odstavcem.
#4. Proveďte rekurzivní vyhledávání
Chcete-li provést rekurzivní vyhledávání, použijte argument -r s grep.
$ grep -R ‘error\|warning’ /var/log/*.log
#output /var/log/bootstrap.log:2023-01-03 21:40:18 URL:http://ftpmaster.internal/ubuntu/pool/main/libg/libgpg-error/libgpg-erro 0_1.43-3_amd64.deb [69684/69684] -> "/build/chroot//var/cache/apt/archives/partial/libgpg-error0_1.43-3_amd64.deb" [1] /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 5 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 5 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 24 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 24 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: ignoring pre-dependency problem!
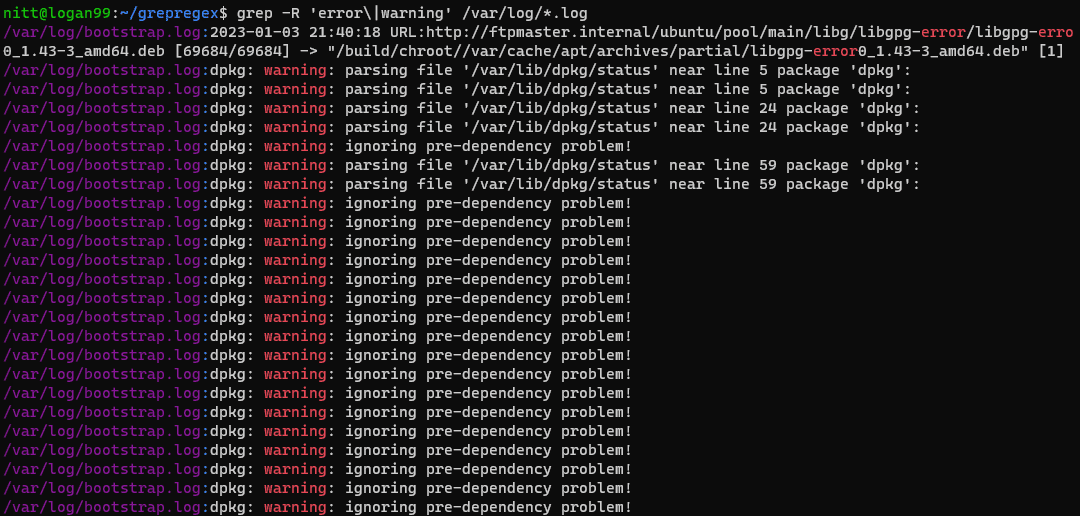
Příkaz grep rekurzivně hledá dvě slova, „error“ a „warning“, v adresáři /var/log. Jedná se o užitečný příkaz, který se dozvíte o všech varováních a chybách v souborech protokolu.
Grep a Regex: Co to je a příklady
Když pracujeme s regulárním výrazem, musíte vědět, že regulární výraz nabízí tři možnosti syntaxe. Tyto zahrnují:
- Základní regulární výrazy (BRE)
- Rozšířené regulární výrazy (ERE)
- Regulární výrazy kompatibilní s Pearl (PCRE)
Příkaz grep používá BRE jako výchozí možnost. Pokud tedy chcete používat jiné režimy regulárních výrazů, budete je muset zmínit. Příkaz grep také zachází s metaznaky tak, jak jsou. Pokud tedy používáte metaznaky jako ?, +, ), budete je muset ukončit pomocí příkazu zpětného lomítka (\).
Syntaxe grep s regulárním výrazem je uvedena níže.
$ grep [regex] [filenames]
Podívejme se na grep a regex v akci s příklady níže.
#1. Doslovné shody slov
Chcete-li provést doslovnou shodu slov, budete muset zadat řetězec jako regulární výraz. Slovo je totiž také regulární výraz.
$ grep "technologies" tech.txt

Podobně můžete také použít doslovné shody k nalezení aktuálních uživatelů. Chcete-li tak učinit, běžte,
$ grep bash /etc/passwd
#output root:x:0:0:root:/root:/bin/bash nitt:x:1000:1000:,,,:/home/nitt:/bin/bash
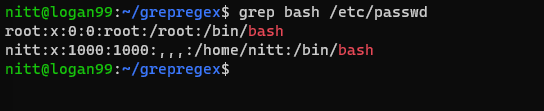
Zobrazí se uživatelé, kteří mají přístup k bash.
#2. Přizpůsobení kotvy
Přiřazení ukotvení je užitečná technika pro pokročilé vyhledávání pomocí speciálních znaků. V regulárním výrazu existují různé kotevní znaky, které můžete použít k reprezentaci konkrétních pozic v textu. Tyto zahrnují:
- Symbol stříšky ‚^‘: Symbol stříšky odpovídá začátku vstupního řetězce nebo řádku a hledá prázdný řetězec.
- ‚$‘ symbol dolaru: Symbol dolaru odpovídá konci vstupního řetězce nebo řádku a hledá prázdný řetězec.
Další dva znaky shodné s kotvou zahrnují hranici slova ‚\ b‘ a hranici neslova ‚\ B‘.
- Hranice slova ‚\ b‘: Pomocí \b můžete potvrdit pozici mezi slovem a neslovným znakem. Jednoduše řečeno, umožňuje vám spárovat celá slova. Tímto způsobem se můžete vyhnout dílčím shodám. Můžete jej také použít k nahrazení slov nebo počítání výskytů slov v řetězci.
- \B hranice slova: Je opakem hranice \b slova v regulárním výrazu, protože prosazuje pozici, která není mezi dvouslovnými nebo neslovnými znaky.
Pojďme si projít příklady, abychom měli jasnou představu.
$ grep ‘^From’ tech.txt

Použití stříšky vyžaduje zadání slova nebo vzoru ve správných velikostech písmen. To proto, že rozlišuje malá a velká písmena. Pokud tedy spustíte následující příkaz, nic nevrátí.
$ grep ‘^from’ tech.txt
Podobně můžete použít symbol $ k nalezení věty, která odpovídá danému vzoru, řetězci nebo slovu.
$ grep ‘technology.$' tech.txt

Můžete také kombinovat oba symboly ^ a $. Podívejme se na příklad níže.
$ grep “^From \| technology.$” tech.txt
Jak vidíte, výstup obsahuje věty začínající na „Od“ a věty končící na „technologie“.
#3. Seskupování
Pokud chcete hledat více vzorů najednou, budete muset použít seskupování. Pomáhá vám vytvářet malé skupiny postav a vzorů, se kterými můžete zacházet jako s jednou jednotkou. Můžete například vytvořit skupinu (tech), která bude obsahovat výraz ‚t‘, ‚e‘, ’c‘, ‚h.‘
Abychom měli jasnou představu, podívejme se na příklad.
$ grep 'technol\(ogy\)\?' tech.txt

Pomocí seskupování můžete porovnávat opakované vzory, zachycovat skupiny a hledat alternativy.
Alternativní vyhledávání se seskupováním
Podívejme se na příklad alternativního vyhledávání.
$ grep "\(tech\|technology\)" tech.txt
Pokud chcete provést vyhledávání v řetězci, musíte jej předat se symbolem svislé čáry. Podívejme se na to v příkladu níže.
$ echo “tech technological technologies technical” | grep "\(tech\|technology\)"
#output “tech technological technologies technical”

Zachycení skupin, nezachytávání skupin a opakovaných vzorů
A co zachycující a nezachycující skupiny?
Budete muset vytvořit skupinu v regulárním výrazu a předat ji řetězci nebo souboru pro zachycení skupin.
$ echo 'tech655 tech655nical technologies655 tech655-oriented 655' | grep "\(tech\)\(655\)"
#output tech655 tech655nical technologies655 tech655-oriented 655

A pro nezachycující skupiny budete muset použít ?: v závorkách.
Nakonec máme opakované vzory. Pro kontrolu opakujících se vzorů budete muset upravit regulární výraz.
$ echo ‘teach tech ttrial tttechno attest’ | grep '\(t\+\)'
#output ‘teach tech ttrial tttechno attest’
Zde regulární výraz hledá jeden nebo více výskytů znaku ‚t‘.
#4. Třídy postav
S třídami znaků můžete snadno psát výrazy regulárních výrazů. Tyto třídy znaků používají hranaté závorky. Některé ze známých tříd postav zahrnují:
- [:digit:] – 0 až 9 číslic
- [:alpha:] – abecední znaky
- [:alnum:] – alfanumerické znaky
- [:lower:] – malá písmena
- [:upper:] – velká písmena
- [:xdigit:] – hexadecimální číslice, včetně 0-9, AF, af
- [:blank:] – prázdné znaky, jako je tabulátor nebo mezera
A tak dále!
Pojďme se podívat na několik z nich v akci.
$ grep [[:digit]] tech.txt

$ grep [[:alpha:]] tech.txt
$ grep [[:xdigit:]] tech.txt
#5. Kvantifikátory
Kvantifikátory jsou metaznaky a jsou jádrem regulárního výrazu. Ty vám umožní přesně odpovídat vzhledu. Podívejme se na ně níže.
- * → Žádná nebo více shod
- + → jedna nebo více shod
- ? → Shoduje se nula nebo jedna
- {x} → odpovídá x
- {x, } → x nebo více shod
- {x,z} → od x do z odpovídá
- {, z} → až z odpovídá
$ echo ‘teach tech ttrial tttechno attest’ | grep -E 't+'
#output ‘teach tech ttrial tttechno attest’
Zde hledá výskyty znaků ‚t‘ pro jednu nebo více shod. Zde -E znamená rozšířený regulární výraz (o kterém budeme diskutovat později.)

#6. Rozšířený Regex
Pokud se vám nelíbí přidávání znaků escape do vzoru regulárního výrazu, musíte použít rozšířený regulární výraz. Odstraňuje potřebu přidávat únikové znaky. Chcete-li tak učinit, musíte použít parametr -E.
$ grep -E 'in+ovation' tech.txt

#7. Použití PCRE ke komplexnímu vyhledávání
PCRE (Perl Compatible Regular Expression) umožňuje mnohem více než jen psát základní výrazy. Můžete například napsat „\d“, které označuje [0-9].
Pomocí PCRE můžete například vyhledávat e-mailové adresy.
echo "Contact me at [email protected]" | grep -P "\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}\b"
#output Contact me at [email protected]

Zde PCRE zajišťuje shodu vzoru. Podobně můžete také použít vzor PCRE ke kontrole vzorů data.
$ echo "The Sparkain site launched on 2023-07-29" | grep -P "\b\d{4}-\d{2}-\d{2}\b"
#output The Sparkain site launched on 2023-07-29

Příkaz vyhledá datum ve formátu RRRR-MM-DD. Můžete jej upravit tak, aby odpovídal i jinému formátu data.
#8. Střídání
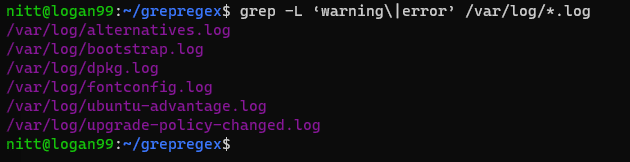
Pokud chcete alternativní shody, můžete použít svislé svislé znaky (\|).
$ grep -L ‘warning\|error’ /var/log/*.log
#output /var/log/alternatives.log /var/log/bootstrap.log /var/log/dpkg.log /var/log/fontconfig.log /var/log/ubuntu-advantage.log /var/log/upgrade-policy-changed.log
Výstup uvádí názvy souborů obsahující „varování“ nebo „chybu“.
Závěrečná slova
To nás přivádí na konec našeho průvodce grep a regex. K upřesnění vyhledávání můžete široce používat grep s regulárním výrazem. Při správném používání můžete ušetřit spoustu času a pomoci zautomatizovat mnoho úkolů, zejména pokud je používáte k psaní skriptů nebo použití regulárního výrazu při prohledávání textu.
Dále se podívejte na často kladené otázky a odpovědi na rozhovory s Linuxem.