

Linuxový příkaz grep je nástroj pro vyhledávání řetězců a vzorů, který zobrazuje odpovídající řádky z více souborů. Pracuje také s výstupem z jiných příkazů. Ukážeme vám jak.
Table of Contents
Příběh za grep
Příkaz grep je známý v Linuxu a Unix kruhy ze tří důvodů. Za prvé, je to nesmírně užitečné. Za druhé, množství možností může být ohromující. Za třetí, byla napsána přes noc, aby uspokojila konkrétní potřebu. První dva jsou prásk; třetí je mírně mimo.
Ken Thompson extrahoval možnosti vyhledávání regulárních výrazů z editoru ed (vyslovené ee-dee) a vytvořil malý program – pro vlastní potřebu – pro vyhledávání v textových souborech. Jeho vedoucí oddělení v Bell Labs, Doug Mcilroy, oslovil Thompsona a popsal problém jeden z jeho kolegů, Lee McMahon, čelil.
McMahon se snažil identifikovat autory Federalistické listy prostřednictvím textové analýzy. Potřeboval nástroj, který by dokázal vyhledávat fráze a řetězce v textových souborech. Thompson toho večera strávil asi hodinu tím, že ze svého nástroje vytvořil obecný nástroj, který by mohli používat ostatní, a přejmenoval ho na grep. Název převzal z ed příkazového řetězce g/re/p , což se překládá jako „globální vyhledávání regulárních výrazů“.
Můžete sledovat Thompsona, jak mluví na Brian Kernighan o zrození grep.
Jednoduché vyhledávání s grep
Chcete-li vyhledat řetězec v souboru, zadejte hledaný výraz a název souboru na příkazovém řádku:

Zobrazí se odpovídající čáry. V tomto případě se jedná o jeden řádek. Odpovídající text je zvýrazněn. Je to proto, že na většině distribucí je grep přiřazen k:
alias grep='grep --colour=auto'
Podívejme se na výsledky, kde se shoduje více řádků. Budeme hledat slovo „Průměr“ v souboru protokolu aplikace. Protože si nemůžeme vzpomenout, zda je slovo v souboru protokolu napsáno malými písmeny, použijeme volbu -i (ignorovat malá a velká písmena):
grep -i Average geek-1.log

Zobrazí se každý odpovídající řádek, v každém je zvýrazněný odpovídající text.
Neodpovídající řádky můžeme zobrazit pomocí volby -v (invertovat shodu).
grep -v Mem geek-1.log

Není zde žádné zvýraznění, protože se jedná o neodpovídající řádky.
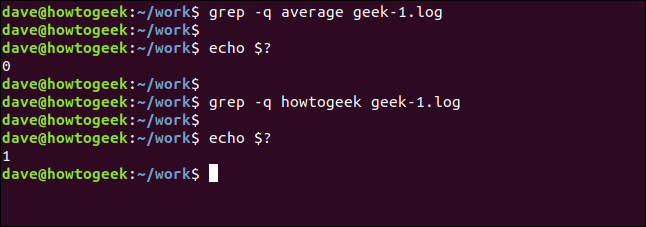
Můžeme způsobit, že grep bude úplně zticha. Výsledek je předán do shellu jako návratová hodnota z grep. Výsledek nula znamená, že řetězec byl nalezen, a výsledek jedna znamená, že nebyl nalezen. Můžeme zkontrolovat návratový kód pomocí $? speciální parametry:
grep -q average geek-1.log
echo $?
grep -q wdzwdz geek-1.log
echo $?
Rekurzivní vyhledávání s grep
Chcete-li prohledávat vnořené adresáře a podadresáře, použijte volbu -r (rekurzivní). Všimněte si, že na příkazovém řádku neuvádíte název souboru, musíte zadat cestu. Zde hledáme v aktuálním adresáři „.“ a jakékoli podadresáře:
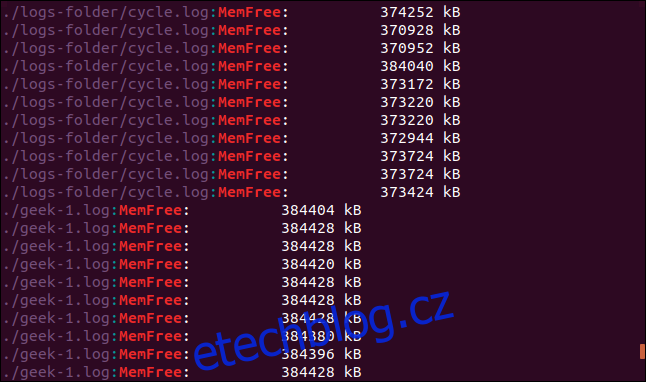
grep -r -i memfree .

Výstup obsahuje adresář a název souboru každého odpovídajícího řádku.
Můžeme přimět grep, aby sledoval symbolické odkazy pomocí volby -R (rekurzivní dereference). V tomto adresáři máme symbolický odkaz nazvaný logs-folder. Ukazuje na /home/dave/logs.
ls -l logs-folder

Zopakujme naše poslední hledání s volbou -R (rekurzivní dereference):
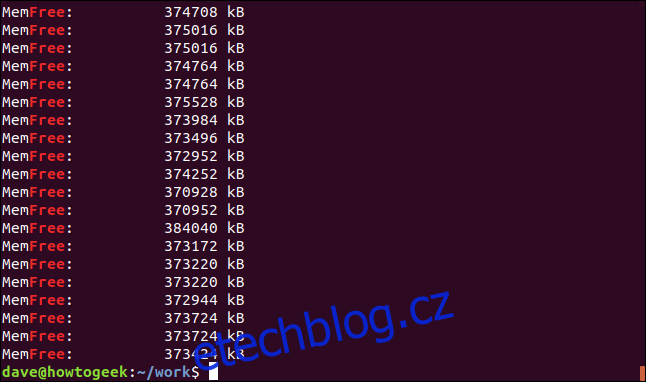
grep -R -i memfree .

Následuje symbolický odkaz a adresář, na který ukazuje, je prohledán také pomocí grep.
Hledání celých slov
Ve výchozím nastavení bude grep odpovídat řádku, pokud se cíl vyhledávání objeví kdekoli v tomto řádku, včetně uvnitř jiného řetězce. Podívejte se na tento příklad. Budeme hledat slovo „zdarma“.
grep -i free geek-1.log

Výsledkem jsou řádky, které obsahují řetězec „free“, ale nejsou to samostatná slova. Jsou součástí řetězce „MemFree“.
Chcete-li, aby grep odpovídal pouze samostatným „slovům“, použijte volbu -w (regulární výraz slova).
grep -w -i free geek-1.log
echo $?
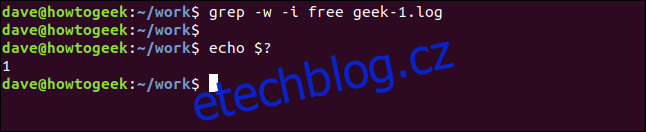
Tentokrát nejsou žádné výsledky, protože hledaný výraz „zdarma“ se v souboru neobjevuje jako samostatné slovo.
Použití více hledaných výrazů
Volba -E (extended regexp) umožňuje vyhledávat více slov. (Volba -E nahrazuje zastaralé egrep verze grep.)
Tento příkaz hledá dva hledané výrazy, „průměr“ a „bez paměti“.
grep -E -w -i "average|memfree" geek-1.log

Pro každý hledaný výraz se zobrazí všechny odpovídající řádky.
Můžete také hledat více výrazů, které nemusí být nutně celá slova, ale mohou to být také celá slova.
Volba -e (vzory) umožňuje použít více hledaných výrazů na příkazovém řádku. K vytvoření vyhledávacího vzoru využíváme funkci závorky regulárního výrazu. Řekne grepu, aby odpovídal kterémukoli ze znaků obsažených v závorkách “[].“ To znamená, že grep bude při vyhledávání odpovídat buď „kB“ nebo „KB“.

Oba řetězce jsou spárovány a ve skutečnosti některé řádky obsahují oba řetězce.
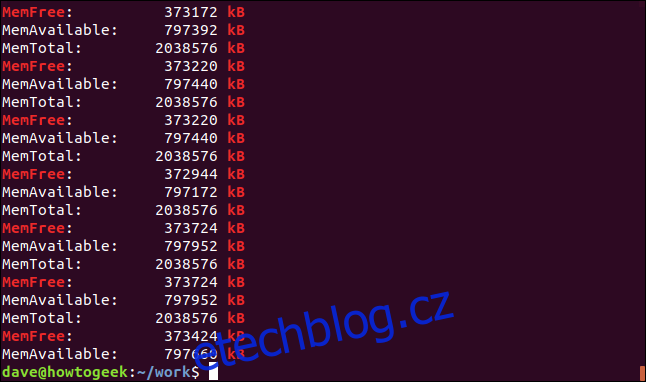
Přesně odpovídající čáry
-x (řádkový regulární výraz) bude odpovídat pouze řádkům, kde celý řádek odpovídá hledanému výrazu. Pojďme hledat datum a časové razítko, o kterém víme, že se v souboru protokolu objeví pouze jednou:
grep -x "20-Jan--06 15:24:35" geek-1.log

Je nalezen a zobrazen jediný odpovídající řádek.
Opakem je pouze zobrazení čar, které se neshodují. To může být užitečné, když si prohlížíte konfigurační soubory. Komentáře jsou skvělé, ale někdy je těžké mezi nimi najít skutečné nastavení. Zde je soubor /etc/sudoers:
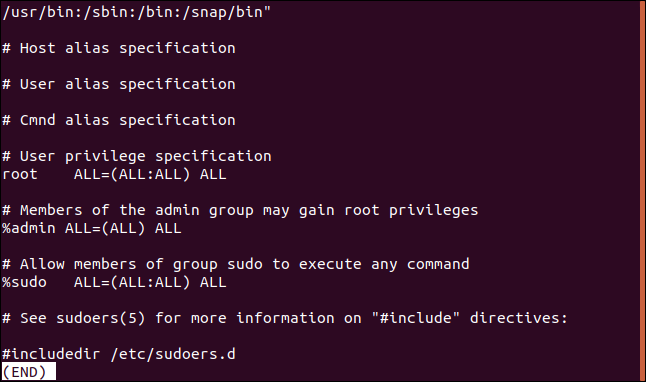
Řádky komentářů můžeme efektivně odfiltrovat takto:
sudo grep -v "https://www.wdzwdz.com/496056/how-to-use-the-grep-command-on-linux/#" /etc/sudoers
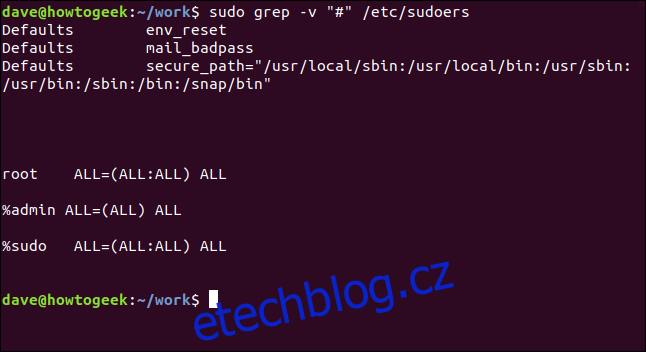
To je mnohem snazší analyzovat.
Zobrazuje se pouze odpovídající text
Může nastat situace, kdy nechcete vidět celý odpovídající řádek, pouze odpovídající text. Volba -o (pouze shoda) dělá právě to.
grep -o MemFree geek-1.log

Zobrazení je omezeno na zobrazení pouze textu, který odpovídá hledanému výrazu, namísto celého odpovídajícího řádku.

Počítání s grep
grep není jen o textu, může poskytovat i číselné informace. Můžeme přimět grep počítat za nás různými způsoby. Pokud chceme vědět, kolikrát se hledaný výraz objeví v souboru, můžeme použít volbu -c (count).
grep -c average geek-1.log

grep uvádí, že hledaný výraz se v tomto souboru vyskytuje 240krát.
Pomocí volby -n (číslo řádku) můžete nastavit, aby grep zobrazoval číslo řádku pro každý odpovídající řádek.
grep -n Jan geek-1.log

Číslo řádku pro každý odpovídající řádek se zobrazí na začátku řádku.
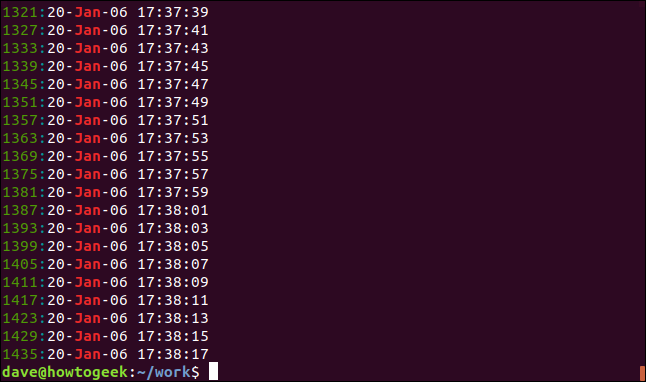
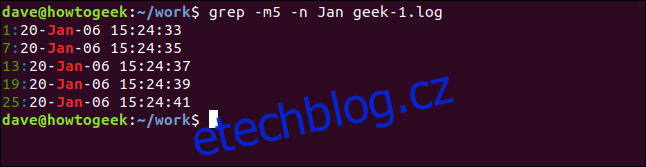
Chcete-li snížit počet zobrazených výsledků, použijte volbu -m (max. počet). Omezíme výstup na pět odpovídajících řádků:
grep -m5 -n Jan geek-1.log
Přidání kontextu
Být schopen vidět některé další řádky – možná neshodné – pro každý odpovídající řádek je často užitečné. může pomoci rozlišit, které ze shodných řádků jsou ty, které vás zajímají.
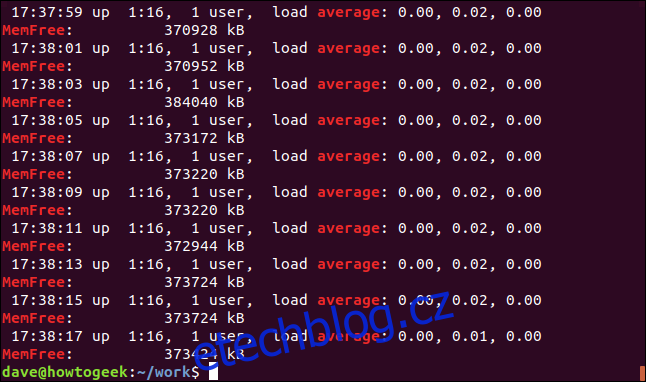
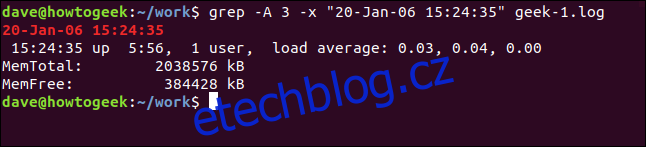
Chcete-li zobrazit některé řádky za odpovídajícím řádkem, použijte volbu -A (po kontextu). V tomto příkladu požadujeme tři řádky:
grep -A 3 -x "20-Jan-06 15:24:35" geek-1.log
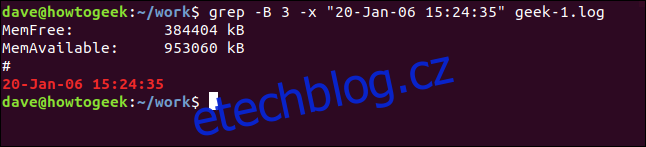
Chcete-li zobrazit některé řádky před odpovídající řádkou, použijte volbu -B (kontext před).
grep -B 3 -x "20-Jan-06 15:24:35" geek-1.log
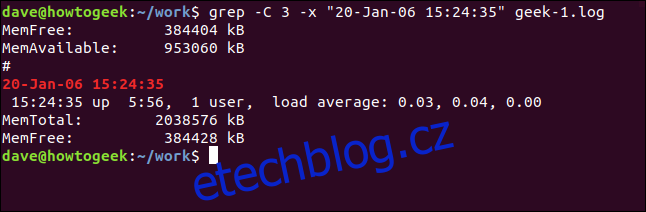
Chcete-li zahrnout řádky před a za odpovídajícím řádkem, použijte volbu -C (kontext).
grep -C 3 -x "20-Jan-06 15:24:35" geek-1.log
Zobrazení odpovídajících souborů
Chcete-li zobrazit názvy souborů, které obsahují hledaný výraz, použijte volbu -l (soubory se shodou). Chcete-li zjistit, které soubory zdrojového kódu C obsahují odkazy na hlavičkový soubor sl.h, použijte tento příkaz:
grep -l "sl.h" *.c

Jsou uvedeny názvy souborů, nikoli odpovídající řádky.

A samozřejmě můžeme hledat soubory, které hledaný výraz neobsahují. Volba -L (soubory bez shody) dělá právě to.
grep -L "sl.h" *.c

Začátek a konec řádků
Můžeme přinutit grep, aby zobrazoval pouze shody, které jsou buď na začátku nebo na konci řádku. Operátor regulárního výrazu „^“ odpovídá začátku řádku. Prakticky všechny řádky v souboru protokolu budou obsahovat mezery, ale my budeme hledat řádky, které mají jako první znak mezeru:
grep "^ " geek-1.log

Zobrazí se řádky, které mají jako první znak mezeru – na začátku řádku.
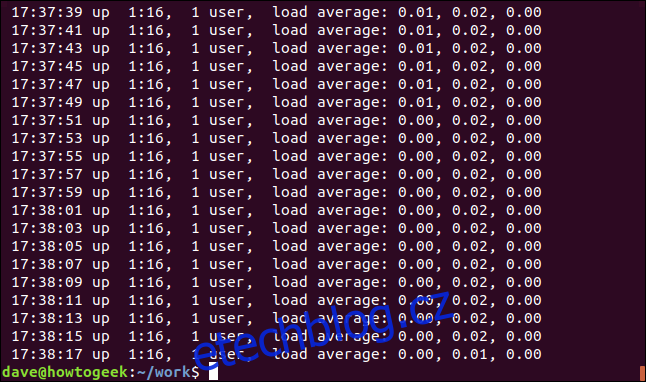
Chcete-li odpovídat konci řádku, použijte operátor regulárního výrazu „$“. Budeme hledat řádky, které končí „00“.
grep "00$" geek-1.log

Na displeji se zobrazí řádky, jejichž poslední znaky jsou „00“.
Použití Pipes s grep
Samozřejmě můžete vstup do grep routovat, výstup z grep přenést do jiného programu a nechat grep zahnízděný uprostřed řetězce rour.
Řekněme, že chceme vidět všechny výskyty řetězce „ExtractParameters“ v našich souborech zdrojového kódu C. Víme, že jich bude docela málo, takže výstup zavedeme do méně:
grep "ExtractParameters" *.c | less

Výstup je prezentován v méně.
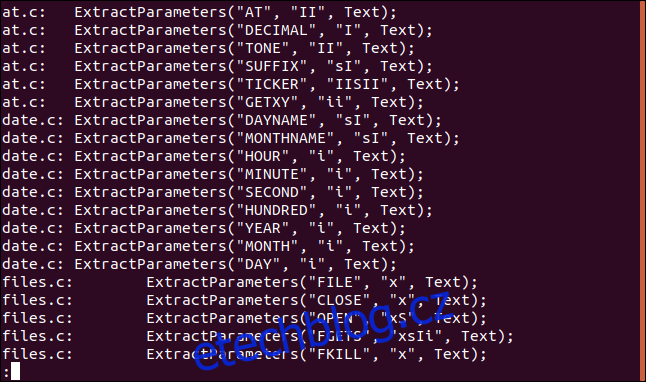
To vám umožní listovat v seznamu souborů a používat méně vyhledávací zařízení.
Pokud převedeme výstup z grep do wc a použijeme volbu -l (řádky), we umí spočítat počet řádků v souborech zdrojového kódu, které obsahují „ExtractParameters“. (Mohli bychom toho dosáhnout pomocí volby grep -c (count), ale je to úhledný způsob, jak demonstrovat vyřazení z grep.)
grep "ExtractParameters" *.c | wc -l

S dalším příkazem převedeme výstup z ls do grep a výstup z grep do sort . Vypisujeme soubory v aktuálním adresáři, vybíráme ty, které obsahují řetězec „Aug“, a seřadit je podle velikosti souboru:
ls -l | grep "Aug" | sort +4n
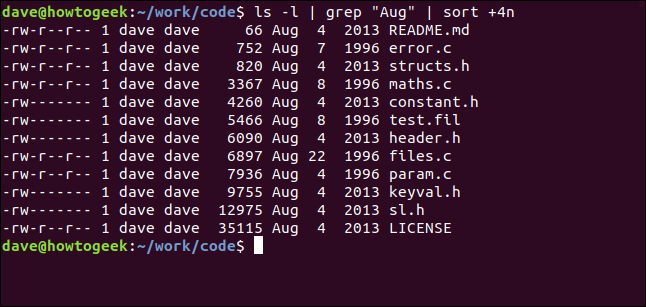
Pojďme si to rozebrat:
ls -l: Provede dlouhý formátový výpis souborů pomocí ls.
grep „Aug“: Vyberte řádky ze seznamu ls, které mají v sobě „Aug“. Všimněte si, že by to také našlo soubory, které mají ve svém názvu „Aug“.
sort +4n: Seřadí výstup z grep na čtvrtém sloupci (velikost souboru).
Získáme seřazený seznam všech souborů upravených v srpnu (bez ohledu na rok), ve vzestupném pořadí podle velikosti souboru.
grep: Méně velení, více spojence
grep je skvělý nástroj, který máte k dispozici. Pochází z roku 1974 a je stále silný, protože potřebujeme to, co dělá, a nic to neumí lépe.
Spojení grep s některými regulárními výrazy-fu to skutečně posouvá na další úroveň.