Jak provádět průzkumnou analýzu dat (EDA) v R (s příklady)
Osvojte si klíčové aspekty průzkumné analýzy dat, důležitého procesu, který slouží k odhalování tendencí, vzorců a sumarizaci datových souborů za pomoci statistických přehledů a grafických vizualizací.
Stejně jako každý jiný projekt, i projekt datové vědy je komplexní a časově náročný, vyžadující precizní organizaci a důkladné dodržování jednotlivých kroků. Průzkumná analýza dat (EDA) představuje jeden z nejdůležitějších elementů tohoto procesu.
V tomto článku se proto stručně zaměříme na to, co přesně průzkumná analýza dat obnáší a jak ji lze realizovat za pomoci jazyka R!
Co je to průzkumná analýza dat?
Průzkumná analýza dat představuje proces zkoumání a studia charakteristik daného datového souboru před jeho dalším zpracováním v aplikaci, ať už se jedná o oblast podnikání, statistiky nebo strojového učení.
Toto shrnutí podstaty informací a jejich hlavních rysů se obvykle provádí za použití vizuálních metod, jako jsou grafická znázornění a tabulky. Tato praxe je nezbytná pro posouzení potenciálu daných dat, která budou v budoucnu podrobena komplexnějšímu zpracování.
EDA tedy umožňuje:
- Formulovat hypotézy pro efektivní využití těchto informací;
- Odhalovat skryté detaily v datové struktuře;
- Identifikovat chybějící hodnoty, odlehlé hodnoty nebo neobvyklé jevy;
- Objevovat trendy a relevantní proměnné v celkovém kontextu;
- Eliminovat irelevantní proměnné nebo proměnné, které jsou v korelaci s jinými;
- Stanovit formální modelování, které je nejvhodnější aplikovat.
Jaký je rozdíl mezi deskriptivní a průzkumnou analýzou dat?
Existují dva základní typy analýzy dat, deskriptivní a průzkumná analýza dat. Tyto metody se navzájem doplňují, ačkoli mají rozdílné cíle.
Zatímco deskriptivní analýza se soustředí na popis chování proměnných, například pomocí výpočtu průměru, mediánu, modu atd.
Průzkumná analýza usiluje o odhalení vztahů mezi proměnnými, extrahování předběžných poznatků a nasměrování modelování k nejčastěji využívaným paradigmům strojového učení: klasifikaci, regresi a shlukování.
Obě metody mohou využívat grafické vizualizace; nicméně pouze explorativní analýza se snaží generovat praktické vhledy, tedy postřehy, které podnítí rozhodování.
Zatímco explorativní analýza dat se snaží řešit problémy a poskytovat řešení, která vedou kroky modelování, deskriptivní analýza, jak už název napovídá, má za cíl pouze detailně popsat daný datový soubor.
| Deskriptivní analýza | Průzkumná analýza dat |
| Analyzuje chování | Analyzuje chování a vztahy |
| Poskytuje souhrn | Vede ke specifikaci a akcím |
| Uspořádává data do tabulek a grafů | Uspořádává data do tabulek a grafů |
| Nemá významnou vysvětlovací schopnost | Má významnou vysvětlovací schopnost |
Některé příklady využití EDA v praxi
#1. Digitální marketing
Digitální marketing se vyvinul od tvůrčího procesu k procesu založenému na datech. Marketingové společnosti používají průzkumnou analýzu dat ke zhodnocení výsledků kampaní a marketingových snah, k usměrnění spotřebitelských investic a k rozhodnutím o cílení.
Demografické studie, segmentace zákazníků a další techniky umožňují obchodníkům využívat obrovské množství dat o nákupním chování zákazníků, průzkumech a panelových datech, a tím lépe pochopit a efektivně komunikovat strategický marketing.
Webová explorativní analytika umožňuje obchodníkům sbírat informace o interakcích na webových stránkách na úrovni relací. Google Analytics je příkladem volně dostupného a oblíbeného analytického nástroje, který marketéři používají k těmto účelům.
Mezi běžně používané průzkumné techniky v marketingu patří modelování marketingového mixu, analýzy cen a propagace, optimalizace prodeje a průzkumná analýza zákazníků, například segmentace.
#2. Průzkumná analýza portfolia
Běžným příkladem aplikace explorativní analýzy dat je průzkumná analýza portfolia. Banka nebo úvěrová agentura spravuje portfolio účtů s různou hodnotou a mírou rizika.
Účty se mohou lišit na základě sociálního statusu držitele (bohatí, střední třída, lidé s nízkými příjmy atd.), geografické lokality, čistého jmění a mnoha dalších faktorů. Věřitel musí u každé půjčky zvážit návratnost půjčky oproti riziku nesplácení. Otázkou je, jak posoudit portfolio jako celek.
Půjčky s nejnižším rizikem mohou být poskytovány velmi bohatým lidem, ovšem jejich počet je omezený. Naopak, existuje mnoho lidí s nízkými příjmy, kteří si chtějí půjčit, ovšem s vyšším rizikem nesplácení.
Řešení v rámci průzkumné analýzy dat dokáže skombinovat analýzu časových řad s mnoha dalšími parametry při rozhodování o tom, komu a za jakých podmínek půjčit peníze. Úroky se účtují členům jednotlivých segmentů portfolia tak, aby se pokryly ztráty v rámci daného segmentu.
#3. Průzkumná analýza rizik
Prediktivní modely v bankovnictví se vyvíjejí, aby poskytovaly odhad rizikových skóre pro jednotlivé klienty. Kreditní skóre má za cíl předpovědět potenciální platební neschopnost a běžně se využívá k posouzení bonity každého žadatele.
Kromě toho se analýza rizik využívá i ve vědě a pojišťovnictví. Je také velmi rozšířená ve finančních institucích, například ve společnostech provozující online platební brány, a to za účelem ověření, zda je transakce pravá nebo podvodná.
K tomuto účelu se využívá transakční historie zákazníka. Častěji se uplatňuje při nákupu kreditní kartou; pokud dojde k náhlému nárůstu objemu transakcí, klientovi je zaslán ověřovací hovor s dotazem, zda transakci sám inicioval. Pomáhá to také snižovat ztráty způsobené těmito podvody.
Průzkumná analýza dat s využitím jazyka R
Prvním krokem pro provedení EDA v jazyce R je stáhnout si R base a R Studio (IDE), následně nainstalovat a načíst následující balíčky:
#Instalace balíčků
install.packages("dplyr")
install.packages("ggplot2")
install.packages("magrittr")
install.packages("tsibble")
install.packages("forecast")
install.packages("skimr")
#Načtení balíčků
library(dplyr)
library(ggplot2)
library(magrittr)
library(tsibble)
library(forecast)
library(skimr)
V tomto návodu budeme pracovat s ekonomickými daty, která jsou integrována v jazyce R. Tato data obsahují roční údaje o ekonomických ukazatelích americké ekonomiky. Pro zjednodušení ji přejmenujeme na econ:
econ <- ggplot2::economics
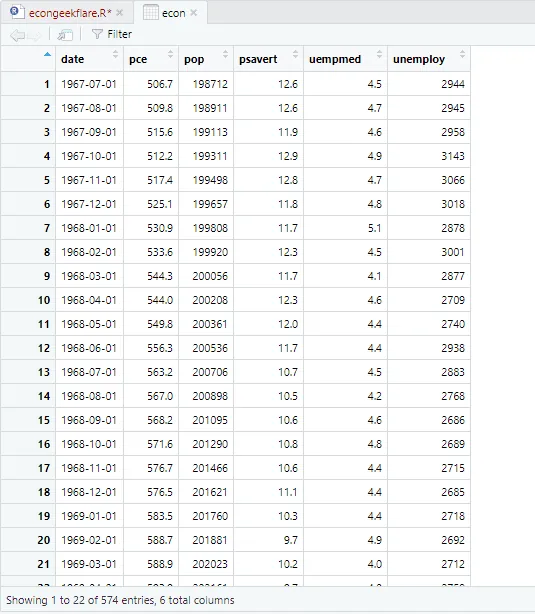
Pro realizaci deskriptivní analýzy použijeme balíček skimr, který tyto statistiky vypočítá jednoduchým a přehledným způsobem:
#Deskriptivní analýza skimr::skim(econ)
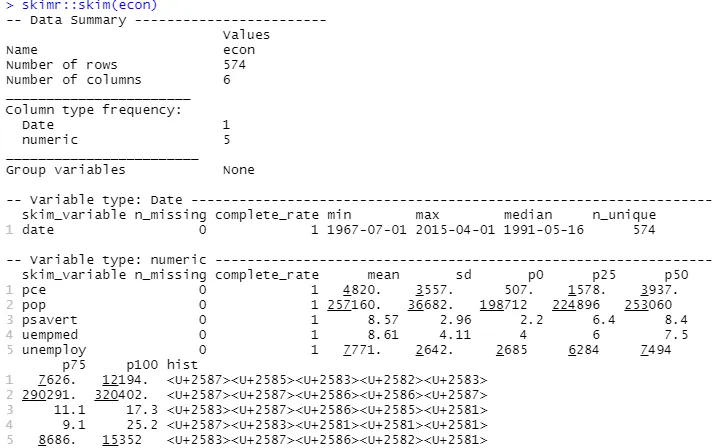
Pro popisnou analýzu lze také použít souhrnnou funkci:
Výše uvedená deskriptivní analýza ukazuje 547 řádků a 6 sloupců v datovém souboru. Minimální hodnota je pro 1967-07-01 a maximální je pro 2015-04-01. Dále ukazuje průměr a směrodatnou odchylku.
Nyní máte základní představu o tom, co se nachází v datovém souboru econ. Podívejme se blíže na data a vykresleme histogram proměnné uempmed:
#Histogram nezaměstnanosti econ %>% ggplot2::ggplot() + ggplot2::aes(x = uempmed) + ggplot2::geom_histogram() + labs(x = "Nezaměstnanost", title = "Měsíční míra nezaměstnanosti v USA mezi lety 1967 a 2015")
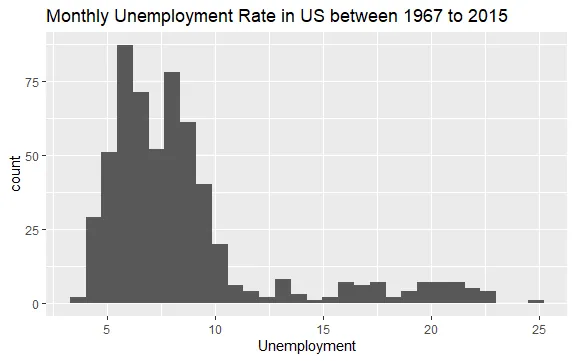
Z rozložení histogramu je zřejmé, že má prodloužený ocas napravo; to znamená, že je možné, že existují pozorování této proměnné s „extrémnějšími“ hodnotami. Nabízí se otázka: v jakém časovém období se tyto hodnoty objevily a jaký je trend této proměnné?
Nejpřímější způsob, jak identifikovat trend proměnné, je pomocí spojnicového grafu. Níže vygenerujeme čárový graf a přidáme vyhlazovací křivku:
#Spojnicový graf nezaměstnanosti econ %>% ggplot2::autoplot(uempmed) + ggplot2::geom_smooth()
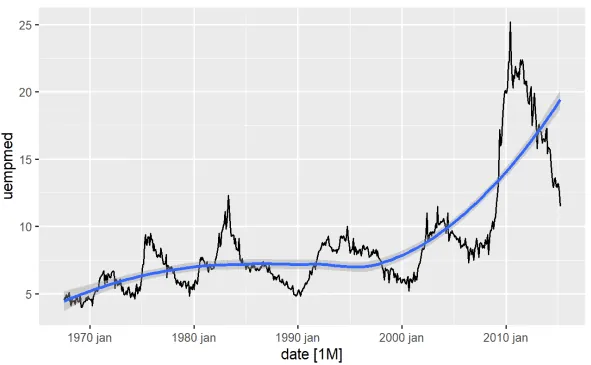
Pomocí tohoto grafu můžeme identifikovat, že v posledním období, v pozorování z roku 2010, dochází k nárůstu nezaměstnanosti, který překonává historii pozorovanou v předchozích desetiletích.
Dalším důležitým aspektem, zejména v kontextu ekonometrického modelování, je stacionarita řad; to znamená, zda průměr a rozptyl jsou v čase konstantní?
Pokud tyto předpoklady u dané proměnné nejsou splněny, mluvíme o tom, že řada má jednotkový kořen (je nestacionární), což znamená, že dopady na tuto proměnnou mají trvalý charakter.
Zdá se, že tomu tak bylo v případě proměnné „délka nezaměstnanosti“. Viděli jsme, že kolísání proměnné se významně změnilo, což má dalekosáhlé důsledky související s ekonomickými teoriemi, které se zabývají cykly. Pokud ale odhlédneme od teorie, jak v praxi zkontrolujeme, zda je proměnná stacionární?
Balíček pro předpovídání má skvělou funkci umožňující aplikovat testy jako ADF, KPSS a další, které nám už ukážou, kolik diferencí je potřeba pro to, aby byla řada stacionární:
#Pomocí ADF testu zkontrolujeme stacionaritu forecast::ndiffs( x = econ$uempmed, test = "adf")

Zde p-hodnota větší než 0,05 ukazuje, že data jsou nestacionární.
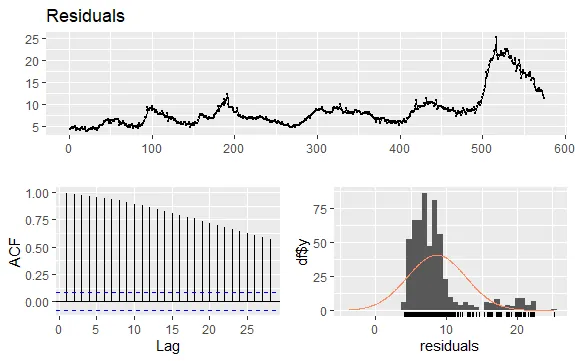
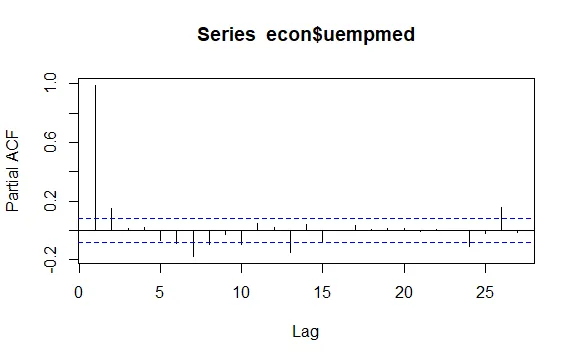
Další důležitou otázkou v časových řadách je identifikace možných korelací (lineární vztahy) mezi zpožděnými hodnotami řady. K tomuto nám pomohou korelogramy ACF a PACF.
Vzhledem k tomu, že řada nevykazuje sezónnost, ale má určitý trend, počáteční autokorelace bývají velké a kladné, protože pozorování, která jsou si časově blízká, mají také blízkou hodnotu.
Autokorelační funkce (ACF) časové řady s trendem má tedy tendenci mít kladné hodnoty, které pomalu klesají s rostoucím zpožděním.
#Zbytky nezaměstnanosti checkresiduals(econ$uempmed) pacf(econ$uempmed)
Závěr
Když se dostaneme k datům, která jsou víceméně čistá, tedy již vyčištěná, máme okamžitou tendenci vrhnout se na fázi konstrukce modelu, abychom získali první výsledky. Je nutné tomuto nutkání odolat a začít provádět průzkumnou analýzu dat, která je sice jednoduchá, ale pomáhá nám získat silný vhled do dat.
Doporučujeme vám prozkoumat nejlepší zdroje pro získávání statistických dat pro datovou vědu.
