
Sledujeme-li vývoj podnikového softwaru od první řady již dvě desetiletí, je nepopiratelný trend posledních let jasný – přesouvání databází do cloudu.
Už jsem se podílel na několika migračních projektech, kde bylo cílem převést existující on-premise databázi do cloudové databáze Amazon Web Services (AWS). Zatímco z dokumentačních materiálů AWS se dozvíte, jak snadné to může být, jsem tu, abych vám řekl, že provedení takového plánu není vždy snadné a existují případy, kdy může selhat.
V tomto příspěvku se budu zabývat reálnými zkušenostmi pro následující případ:
- Zdroj: I když teoreticky opravdu nezáleží na tom, jaký je váš zdroj (velmi podobný přístup můžete použít pro většinu nejpopulárnějších databází), Oracle byl databázový systém, který si velké korporace vybíraly po mnoho let a to je místo, kde se zaměřím.
- Cíl: Žádný důvod, proč být na této straně konkrétní. V AWS si můžete vybrat libovolnou cílovou databázi a přístup bude stále vyhovovat.
- Režim: Můžete mít úplné obnovení nebo přírůstkové obnovení. Dávkové načítání dat (stav zdroje a cíle jsou zpožděné) nebo načítání dat (téměř) v reálném čase. Zde se dotkneme obou.
- Frekvence: Možná budete chtít jednorázovou migraci následovanou úplným přechodem do cloudu nebo budete vyžadovat určité přechodné období a mít data aktuální na obou stranách současně, což znamená vyvinout denní synchronizaci mezi on-premise a AWS. První z nich je jednodušší a dává daleko větší smysl, ale to druhé je častěji žádané a má daleko více zlomových bodů. Zde se budu věnovat obojímu.
Table of Contents
popis problému
Požadavek je často jednoduchý:
Chceme začít vyvíjet služby uvnitř AWS, proto prosím zkopírujte všechna naše data do databáze „ABC“. Rychle a jednoduše. Nyní potřebujeme použít data uvnitř AWS. Později zjistíme, jaké části návrhů DB změnit, aby odpovídaly našim aktivitám.
Než půjdeme dále, je třeba zvážit:
- Neskákejte do myšlenky „jen zkopírujte to, co máme a vypořádejte se s tím později“ příliš rychle. Chci říct, ano, je to to nejjednodušší, co můžete udělat, a udělá se to rychle, ale má to potenciál vytvořit tak zásadní architektonický problém, který nebude možné později opravit bez vážného refaktoringu většiny nové cloudové platformy. . Jen si představte, že cloudový ekosystém je úplně jiný než on-premise. Postupem času bude zavedeno několik nových služeb. Lidé přirozeně začnou používat totéž velmi odlišně. Téměř nikdy není dobrý nápad replikovat on-premise stav v cloudu způsobem 1:1. Může to být ve vašem konkrétním případě, ale nezapomeňte to zkontrolovat.
- Zpochybňujte požadavek s některými smysluplnými pochybnostmi, jako jsou:
- Kdo bude typickým uživatelem využívajícím novou platformu? Zatímco on-premise, může to být transakční podnikový uživatel; v cloudu to může být datový vědec nebo analytik datového skladu, nebo může být hlavním uživatelem dat služba (např. Databricks, Glue, modely strojového učení atd.).
- Očekává se, že běžné každodenní úlohy zůstanou zachovány i po přechodu do cloudu? Pokud ne, jak se očekává, že se změní?
- Plánujete v průběhu času výrazný nárůst dat? Odpověď je s největší pravděpodobností ano, protože to je často ten nejdůležitější důvod migrace do cloudu. K tomu má být připraven nový datový model.
- Očekávejte, že koncový uživatel bude přemýšlet o nějakých obecných, očekávaných dotazech, které nová databáze od uživatelů obdrží. To bude definovat, jak moc se má stávající datový model změnit, aby zůstal relevantní pro výkon.
Nastavení migrace
Jakmile je vybrána cílová databáze a uspokojivě prodiskutován datový model, dalším krokem je seznámit se s AWS Schema Conversion Tool. Existuje několik oblastí, ve kterých může tento nástroj sloužit:
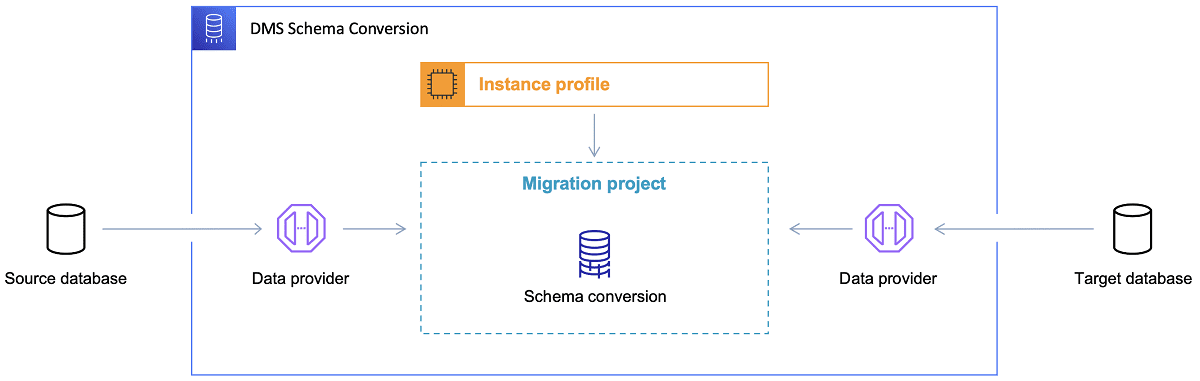 Odkaz: Dokumentace AWS
Odkaz: Dokumentace AWS
Nyní je zde několik tipů pro použití nástroje Schema Conversion Tool.
Za prvé, téměř nikdy by nemělo platit, že výstup přímo použijete. Považoval bych to spíše za referenční výsledky, kde budete provádět úpravy na základě vašeho pochopení a účelu dat a způsobu, jak budou data v cloudu použita.
Za druhé, dříve byly tabulky pravděpodobně vybrány uživateli, kteří očekávali rychlé krátké výsledky o nějaké konkrétní entitě datové domény. Nyní však mohou být data vybrána pro analytické účely. Například databázové indexy dříve pracující v on-premise databázi budou nyní k ničemu a rozhodně nezlepší výkon DB systému související s tímto novým využitím. Podobně můžete chtít rozdělit data na cílovém systému jinak, jako tomu bylo dříve na zdrojovém systému.
Také by mohlo být dobré zvážit provedení některých transformací dat během procesu migrace, což v podstatě znamená změnu cílového datového modelu pro některé tabulky (aby již nebyly kopiemi 1:1). Později bude potřeba transformační pravidla implementovat do migračního nástroje.
Pokud jsou zdrojové a cílové databáze stejného typu (např. Oracle on-premise vs. Oracle v AWS, PostgreSQL vs. Aurora Postgresql atd.), pak je nejlepší použít vyhrazený migrační nástroj, který konkrétní databáze nativně podporuje ( např. exporty a importy datových pump, Oracle Goldengate atd.).
Ve většině případů však zdrojová a cílová databáze nebudou kompatibilní, a pak bude zřejmým nástrojem volby AWS Database Migration Service.
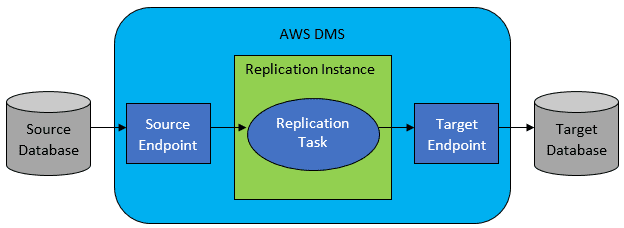 Odkaz: Dokumentace AWS
Odkaz: Dokumentace AWS
AWS DMS v zásadě umožňuje konfiguraci seznamu úkolů na úrovni tabulky, která bude definovat:
- Jaká je přesná zdrojová DB a tabulka, ke které se má připojit?
- Specifikace příkazu, které budou použity k získání dat pro cílovou tabulku.
- Transformační nástroje (pokud existují), definující, jak mají být zdrojová data mapována na data cílové tabulky (pokud ne 1:1).
- Jaká je přesná cílová databáze a tabulka, do které se mají data načíst?
Konfigurace úloh DMS se provádí v nějakém uživatelsky přívětivém formátu, jako je JSON.
Nyní v nejjednodušším scénáři vše, co musíte udělat, je spustit implementační skripty v cílové databázi a spustit úlohu DMS. Ale je toho daleko víc.
Jednorázová úplná migrace dat

Nejjednodušší případ k provedení je, když je požadavkem přesunout celou databázi jednou do cílové cloudové databáze. Pak bude v zásadě vše, co je nutné udělat, vypadat takto:
Pokud je konfigurace DMS provedena dobře, nic špatného se v tomto scénáři nestane. Každá jednotlivá zdrojová tabulka bude vyzvednuta a zkopírována do cílové databáze AWS. Jedinou starostí bude provedení činnosti a zajištění správného dimenzování v každém kroku, aby nedošlo k selhání kvůli nedostatečnému úložnému prostoru.
Přírůstková denní synchronizace

Tady se věci začínají komplikovat. Chci říct, kdyby byl svět ideální, pak by to pravděpodobně fungovalo pořád dobře. Ale svět není nikdy ideální.
DMS lze nakonfigurovat tak, aby fungoval ve dvou režimech:
- Plná zátěž – výchozí režim popsaný a používaný výše. Úlohy DMS se spouštějí buď při jejich spuštění, nebo když je jejich spuštění naplánováno. Po dokončení jsou úkoly DMS hotové.
- Change Data Capture (CDC) – v tomto režimu neustále běží DMS úloha. DMS prohledá zdrojovou databázi pro změnu na úrovni tabulky. Pokud ke změně dojde, okamžitě se pokusí replikovat změnu v cílové databázi na základě konfigurace uvnitř úlohy DMS související se změněnou tabulkou.
Když se chystáte na CDC, musíte udělat ještě další volbu – konkrétně, jak CDC extrahuje delta změny ze zdrojové DB.
#1. Oracle Redo Logs Reader
Jednou z možností je zvolit nativní databázi redo logs reader od společnosti Oracle, kterou může CDC využít k získání změněných dat a na základě posledních změn replikovat stejné změny v cílové databázi.
I když to může vypadat jako jasná volba, pokud se jedná o Oracle jako zdroj, má to háček: čtečka redo logů Oracle využívá zdrojový cluster Oracle, a tak přímo ovlivňuje všechny ostatní aktivity běžící v databázi (ve skutečnosti přímo vytváří aktivní relace v databáze).
Čím více úloh DMS jste nakonfigurovali (nebo čím více clusterů DMS paralelně), tím více pravděpodobně budete muset zvýšit velikost clusteru Oracle – v podstatě upravit vertikální škálování vašeho primárního databázového clusteru Oracle. To jistě ovlivní celkové náklady na řešení, a to ještě více, pokud se denní synchronizace chystá zůstat u projektu po dlouhou dobu.
#2. AWS DMS Log Miner
Na rozdíl od výše uvedené možnosti se jedná o nativní řešení AWS pro stejný problém. V tomto případě DMS neovlivňuje zdrojovou databázi Oracle. Místo toho zkopíruje redo logy Oracle do clusteru DMS a tam provede veškeré zpracování. I když to šetří zdroje Oracle, je to pomalejší řešení, protože zahrnuje více operací. A také, jak lze snadno předpokládat, vlastní čtečka redo logů Oracle je pravděpodobně pomalejší ve své práci jako nativní čtečka od Oracle.
V závislosti na velikosti zdrojové databáze a počtu tamních denních změn můžete v nejlepším případě skončit s inkrementální synchronizací dat z místní databáze Oracle do cloudové databáze AWS v téměř reálném čase.
V žádných jiných scénářích to stále nebude blízko synchronizace v reálném čase, ale můžete se pokusit co nejvíce přiblížit přijatému zpoždění (mezi zdrojem a cílem) vyladěním konfigurace výkonu a paralelismu zdrojového a cílového clusteru nebo experimentováním s množství úkolů DMS a jejich distribuce mezi instancemi CDC.
A možná se budete chtít dozvědět, které změny zdrojové tabulky podporuje CDC (jako například přidání sloupce), protože ne všechny možné změny jsou podporovány. V některých případech je jediným způsobem ruční změna cílové tabulky a restartování úlohy CDC od nuly (přičemž dojde ke ztrátě všech existujících dat v cílové databázi).
Když se věci pokazí, bez ohledu na to, co

Naučil jsem se to tvrdě, ale existuje jeden konkrétní scénář spojený s DMS, kde je těžké dosáhnout příslibu každodenní replikace.
DMS může zpracovávat redo logy pouze s určitou definovanou rychlostí. Nezáleží na tom, zda existuje více instancí DMS provádějících vaše úkoly. Přesto každá instance DMS čte redo protokoly pouze jednou definovanou rychlostí a každý z nich je musí číst celé. Nezáleží ani na tom, zda používáte Oracle redo logs nebo AWS log miner. Oba mají tento limit.
Pokud zdrojová databáze obsahuje velké množství změn během jednoho dne, kdy jsou redo logy Oracle opravdu šíleně velké (např. 500 GB+ velké) každý den, CDC prostě nebude fungovat. Replikace nebude dokončena před koncem dne. Přinese část nezpracované práce do dalšího dne, kde již čeká nová sada změn, které mají být replikovány. Množství nezpracovaných dat bude ze dne na den jen růst.
V tomto konkrétním případě CDC nebylo možné (po mnoha testech výkonu a pokusech, které jsme provedli). Jediný způsob, jak zajistit, že alespoň všechny změny delta z aktuálního dne budou replikovány ve stejný den, bylo přistoupit takto:
- Oddělte opravdu velké stoly, které se nepoužívají tak často, a replikujte je pouze jednou týdně (např. o víkendech).
- Nakonfigurujte replikaci nepříliš velkých, ale stále velkých tabulek tak, aby byly rozděleny mezi několik úloh DMS; jedna tabulka byla nakonec migrována 10 nebo více samostatnými úlohami DMS paralelně, což zajistilo, že rozdělení dat mezi úlohy DMS je odlišné (zde je zahrnuto vlastní kódování) a spouštějí je denně.
- Přidejte další (v tomto případě až 4) instance DMS a rozdělte mezi ně úlohy DMS rovnoměrně, tedy nejen podle počtu tabulek, ale také podle velikosti.
V podstatě jsme použili režim plného zatížení DMS k replikaci denních dat, protože to byl jediný způsob, jak dosáhnout dokončení replikace dat alespoň ve stejný den.
Není to dokonalé řešení, ale stále existuje a i po mnoha letech stále funguje stejným způsobem. Takže to možná nakonec není tak špatné řešení. 😃