Jak vypočítat Z-skóre pomocí aplikace Microsoft Excel
Z-skóre představuje statistický ukazatel, který udává, jak moc se konkrétní hodnota odchyluje od průměrné hodnoty celého datového souboru, a to v jednotkách standardní odchylky. Pro výpočet průměrné hodnoty a směrodatné odchylky lze využít funkce AVERAGE a STDEV.S nebo STDEV.P. Tyto výsledky následně poslouží k určení Z-skóre pro každou individuální hodnotu.
Co přesně Z-skóre znamená a jak fungují funkce AVERAGE, STDEV.S a STDEV.P?
Z-skóre je užitečným nástrojem pro porovnávání hodnot z různých datových souborů. Definuje se jako počet standardních odchylek, o které se daný datový bod liší od průměrné hodnoty. Obecný vzorec pro výpočet Z-skóre je následující:
=(Hodnota-AVERAGE(DatováSada))/STDEV(DatováSada)
Pro lepší pochopení si představme situaci, kdy chceme porovnat výsledky testů dvou studentů, kteří navštěvují kurzy algebry u různých učitelů. První student dosáhl v závěrečném testu 95 %, zatímco druhý získal 87 %. Na první pohled se zdá, že první student si vedl lépe. Nicméně, co když druhý učitel zadal náročnější test? V takovém případě je vhodné vypočítat Z-skóre pro každého studenta na základě průměrného skóre a standardní odchylky skóre v každé třídě. Porovnáním Z-skóre můžeme zjistit, že student s 87 % si vedl lépe ve srovnání se zbytkem své třídy než student s 95 % ve své třídě.
Pro určení Z-skóre potřebujeme znát průměrnou hodnotu, pro jejíž výpočet Excel nabízí funkci „PRŮMĚR“ (AVERAGE). Tato funkce sečte všechny hodnoty v označené oblasti buněk a výsledek vydělí počtem buněk obsahujících číselné hodnoty, přičemž prázdné buňky ignoruje.
Další potřebnou statistickou hodnotou je „směrodatná odchylka“, pro jejíž výpočet Excel nabízí dvě funkce s mírně odlišným přístupem.
Starší verze Excelu obsahovaly pouze funkci „SMODCH“, která počítala směrodatnou odchylku za předpokladu, že data představují „výběr“ z celkové populace. Od verze Excel 2010 jsou k dispozici dvě funkce pro výpočet směrodatné odchylky:
STDEV.S: Tato funkce je ekvivalentní starší funkci „SMODCH“. Počítá směrodatnou odchylku za předpokladu, že data představují „výběr“ z celkové populace. Příkladem výběru může být vzorek komárů odebraných pro výzkumný projekt, nebo automobily vybrané pro testování bezpečnosti při nárazu.
STDEV.P: Tato funkce vypočítá směrodatnou odchylku, pokud data reprezentují celou populaci. Příkladem celkové populace by byli všichni komáři na Zemi, nebo všechny automobily určitého modelu vyrobené v daném období.
Volba mezi těmito funkcemi závisí na charakteru datové sady. Obvykle je rozdíl mezi výsledky malý, nicméně hodnota vypočítaná pomocí „STDEV.P“ bude vždy menší než výsledek „STDEV.S“ pro stejnou datovou sadu. Je konzervativnější předpokládat, že v datech existuje větší variabilita.
Příklad praktického výpočtu Z-skóre
V našem příkladu máme dva sloupce s názvy "Hodnoty" a "Z-skóre". Dále máme tři "pomocné" buňky, do kterých budeme ukládat mezivýsledky funkcí "AVERAGE", "STDEV.S" a "STDEV.P". Sloupec "Hodnoty" obsahuje deset náhodných čísel rozložených okolo 500, a ve sloupci "Z-skóre" budeme počítat Z-skóre na základě výsledků z pomocných buněk.
Nejprve spočítáme průměr hodnot pomocí funkce „PRŮMĚR“. Vybereme buňku, do které uložíme výsledek.
Do vybrané buňky zadáme následující vzorec a potvrdíme Enter, nebo použijeme nabídku „Vzorce“.
=AVERAGE(E2:E13)
Pro přístup k funkci z nabídky "Vzorce", vybereme rozbalovací nabídku "Další funkce", zvolíme "Statistika" a klikneme na "PRŮMĚR".
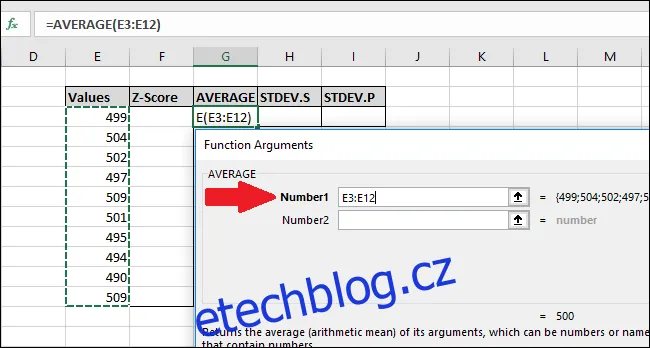
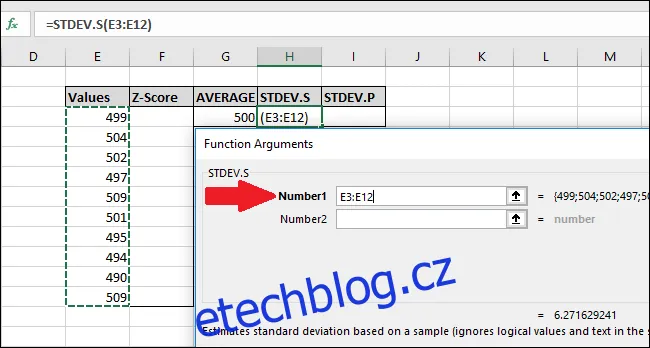
V okně „Argumenty funkce“ vybereme všechny buňky ve sloupci „Hodnoty“ jako vstup pro pole „Číslo1“. Pole „Číslo2“ můžeme ignorovat.
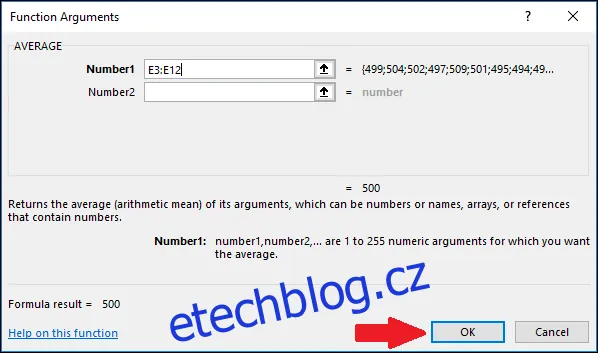
Nyní stiskneme "OK".
Nyní musíme vypočítat směrodatnou odchylku hodnot pomocí funkce "STDEV.S" nebo "STDEV.P". V tomto příkladu si ukážeme výpočet obou variant, začneme s "STDEV.S". Vybereme buňku, kam budeme ukládat výsledek.
Pro výpočet směrodatné odchylky pomocí "STDEV.S", zadáme tento vzorec a potvrdíme Enter (nebo jej otevřeme z nabídky "Vzorce").
=STDEV.S(E3:E12)
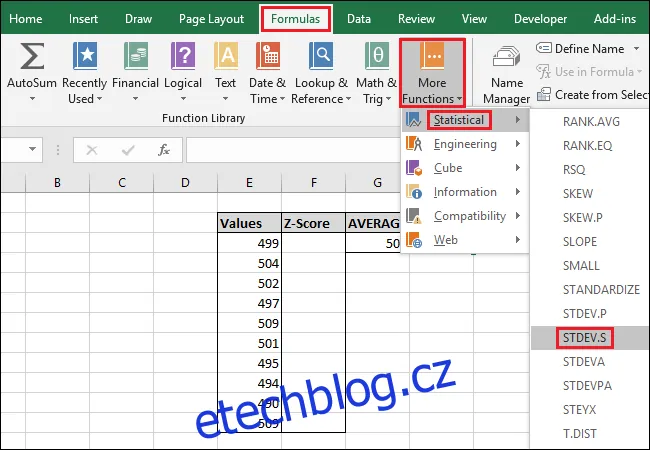
Pro přístup k funkci přes nabídku "Vzorce", vybereme rozbalovací nabídku "Další funkce", zvolíme "Statistika", posuneme se níže a klikneme na "STDEV.S".
V okně "Argumenty funkce", vybereme všechny buňky ve sloupci "Hodnoty" jako vstup pro pole "Číslo1". Pole "Číslo2" opět necháme prázdné.
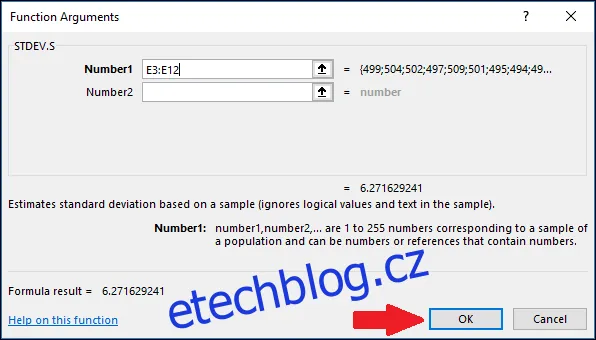
Nyní stiskneme "OK".
Nyní vypočítáme směrodatnou odchylku pomocí funkce "STDEV.P". Vybereme buňku pro uložení výsledku.
Pro výpočet směrodatné odchylky pomocí funkce "STDEV.P", zadáme tento vzorec a potvrdíme Enter (nebo ji otevřeme z nabídky "Vzorce").
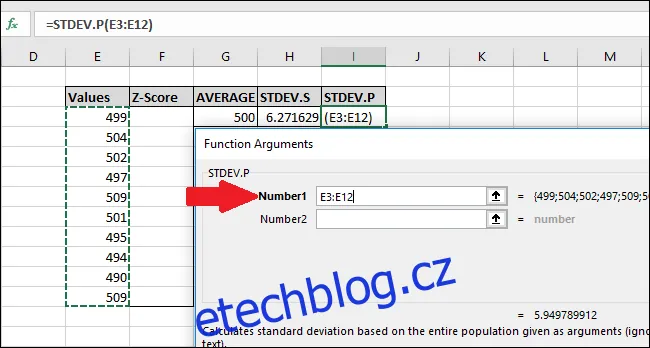
=STDEV.P(E3:E12)
Pro přístup k funkci přes nabídku "Vzorce", vybereme rozbalovací nabídku "Další funkce", zvolíme "Statistika", posuneme se níže a klikneme na "STDEV.P".
V okně "Argumenty funkce", vybereme všechny buňky ve sloupci "Hodnoty" jako vstup pro pole "Číslo1". Opět, pole "Číslo2" nemusíme vyplňovat.
Nyní stiskneme "OK".
Nyní, když máme spočítaný průměr a směrodatnou odchylku, máme vše, co potřebujeme k výpočtu Z-skóre. Můžeme použít jednoduchý vzorec, který odkazuje na buňky obsahující výsledky funkcí "AVERAGE" a "STDEV.S" nebo "STDEV.P".
Vybereme první buňku ve sloupci "Z-skóre". V tomto příkladu použijeme výsledek funkce "STDEV.S", ale můžete použít i výsledek z "STDEV.P".
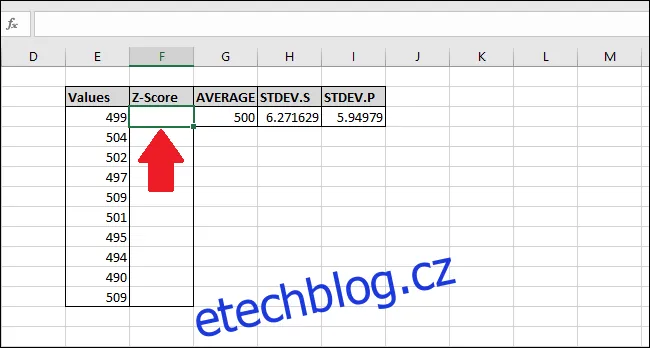
Zadáme následující vzorec a potvrdíme Enter:
=(E3-$G$3)/$H$3
Alternativně, můžeme k vložení vzorce použít následující kroky místo psaní:
Klikneme na buňku F3 a zadáme =(
Vybereme buňku E3 (Můžeme jednou stisknout šipku vlevo nebo použít myš).
Zadáme znak mínus -
Vybereme buňku G3 a stiskneme F4, abychom přidali symboly "$", čímž vytvoříme "absolutní" odkaz na buňku (bude cyklicky procházet "G3" > "$G$3" > "G$3" > "$G3" > "G3", pokud budeme F4 stisknout opakovaně).
Zadáme )/
Vybereme buňku H3 (nebo I3 pokud používáme "STDEV.P") a stiskneme F4 pro přidání dvou symbolů "$".
Stiskneme Enter.
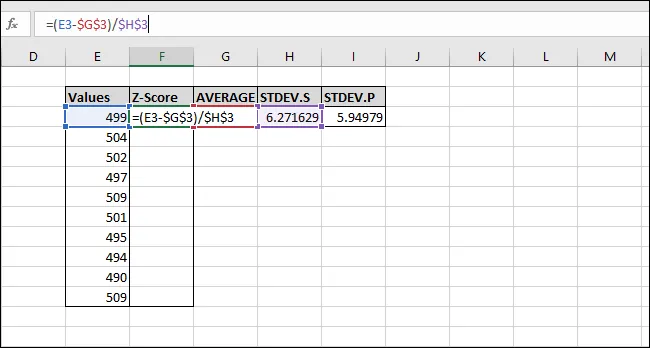
Z-skóre bylo spočítáno pro první hodnotu. Hodnota je 0,15945 směrodatné odchylky pod průměrem. Pro kontrolu, můžeme tento výsledek vynásobit směrodatnou odchylkou (6,271629 * -0,15945) a zkontrolovat, jestli se výsledek rovná rozdílu mezi hodnotou a průměrem (499-500). Oba výsledky jsou stejné, takže hodnota dává smysl.
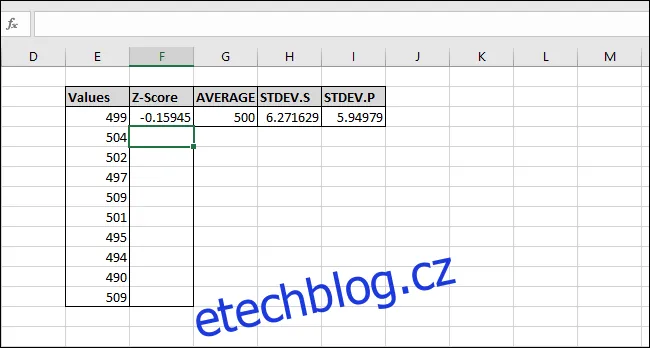
Pojďme nyní vypočítat Z-skóre i pro ostatní hodnoty. Označíme celý sloupec 'Z-Skóre', počínaje buňkou obsahující vzorec.
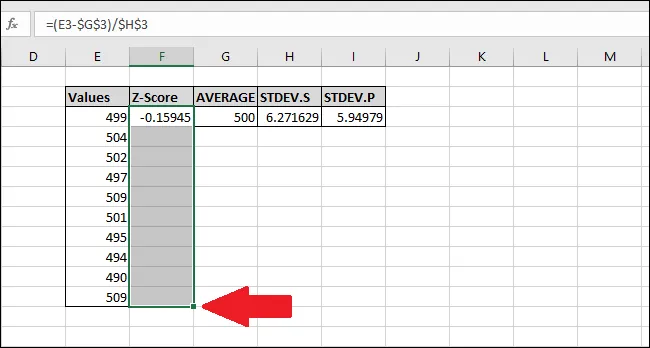
Stiskneme Ctrl+D. Tím se vzorec z horní buňky zkopíruje do všech ostatních vybraných buněk.
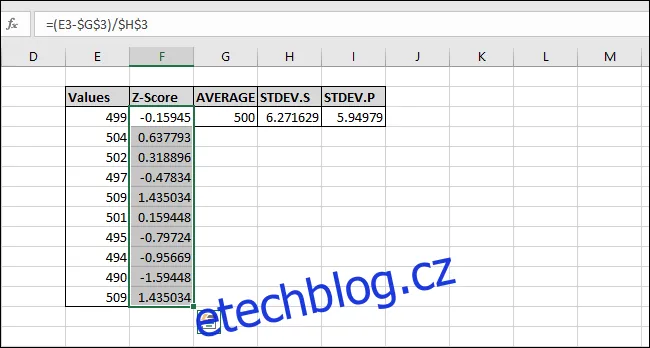
Nyní je vzorec "vyplněn" do všech buněk. Každá buňka bude díky symbolům "$" vždy odkazovat na správné buňky pro "AVERAGE" a "STDEV.S" nebo "STDEV.P". Pokud se zobrazí chyby, zkontrolujte, zda zadaný vzorec obsahuje symboly "$".
Výpočet Z-skóre bez "pomocných" buněk
Pomocné buňky, které slouží pro ukládání mezivýsledků, jako jsou průměr a směrodatná odchylka, mohou být užitečné, ale nejsou vždy nutné. Při výpočtu Z-skóre je lze úplně vynechat použitím následujících vzorců:
Vzorec využívající funkci "STDEV.S":
=(Hodnota-AVERAGE(Hodnoty))/STDEV.S(Hodnoty)
A vzorec využívající "STDEV.P":
=(Hodnota-AVERAGE(Hodnoty))/STDEV.P(Hodnoty)
Při zadávání rozsahu buněk pro "Hodnoty" ve funkcích, nezapomeňte přidat absolutní odkazy ("$" pomocí F4), aby se při "vyplňování" nepočítal průměr nebo směrodatná odchylka jiného rozsahu buněk v každém vzorci.
Pokud máme rozsáhlý soubor dat, může být efektivnější použít pomocné buňky. Výpočet výsledků funkcí "PRŮMĚR" a "STDEV.S" nebo "STDEV.P" pak neprobíhá pro každý jednotlivý řádek. To šetří výpočetní prostředky procesoru a zkracuje dobu potřebnou pro výpočet výsledků.
Kromě toho, zápis "$G$3" vyžaduje méně bajtů pro uložení a méně RAM pro načtení, než zápis "PRŮMĚR($E$3:$E$12)". To je relevantní, jelikož standardní 32bitová verze Excelu má limit 2 GB paměti RAM (64bitové verze nemají omezení na množství využité RAM).
