Jak zobrazit volné místo na disku a využití disku z terminálu Linux
Příkazy df a du jsou nástroje, které v prostředí Bash, typickém pro Linux, macOS a další systémy odvozené od Unixu, slouží k monitorování obsazenosti disku. S jejich pomocí lze snadno zjistit, jaké soubory a adresáře zabírají nejvíce místa ve vašem systému.
Přehled celkového, volného a využitého místa na disku
Bash nabízí dvojici praktických příkazů pro práci s diskovým prostorem. df, neboli "disk free" (volné místo na disku), zobrazuje přehled dostupného a využitého místa na disku. Na druhou stranu, du, zkráceně "disk usage" (využití disku), odhaluje, které soubory a složky nejvíce přispívají k obsazení disku.
Začněte tím, že do okna terminálu Bash zadáte příkaz df a potvrdíte stisknutím klávesy Enter. Výsledkem bude výpis, který může na první pohled působit nepřehledně, ale ve skutečnosti je poměrně srozumitelný. Pokud použijete příkaz df bez dalších parametrů, zobrazí se data o volném a využitém místě pro všechny připojené systémy souborů.
df
Každý řádek výpisu je tvořen šesti sloupci, které reprezentují:
| Filesystem: | Název konkrétního systému souborů. |
| 1K-Blocks: | Celkový počet bloků o velikosti 1 KB dostupných v daném systému souborů. |
| Used: | Počet bloků 1 KB, které byly v systému souborů využity. |
| Available: | Počet bloků 1 KB, které jsou v systému souborů volné. |
| Use%: | Procentuální podíl využitého místa v daném systému souborů. |
| Mounted on: | Bod připojení systému souborů. |
Pro srozumitelnější výstup namísto počtu bloků 1 KB můžete použít volbu -B (block size). Tato volba umožňuje zadat požadovanou velikost bloku, a to pomocí písmen K, M, G, T, P, E, Z nebo Y, které odpovídají násobkům 1024 (kilo, mega, giga, tera, peta, exa, zeta a yotta). Například, pro zobrazení dat v megabajtech, použijte:
df -BM
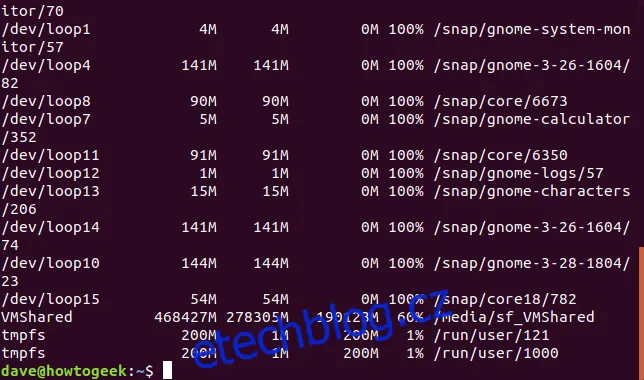
Volba -h (human-readable) způsobí, že df automaticky zvolí nejvhodnější jednotku pro každou velikost systému souborů. V následujícím výpisu můžete vidět, že jsou použity gigabajty, megabajty i kilobajty pro různé systémy.
df -h
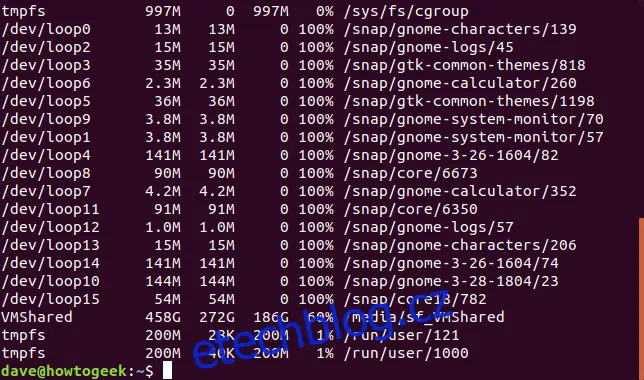
Pokud vás zajímají informace o počtu inodů, použijte volbu -i (inodes). Inody jsou datové struktury používané linuxovými systémy souborů k popisu souborů a uchovávání jejich metadat, jako je název, datum změny a pozice na disku. Pro běžného uživatele to pravděpodobně nebude užitečné, ale správci systému se občas na tyto informace potřebují podívat.
df -i
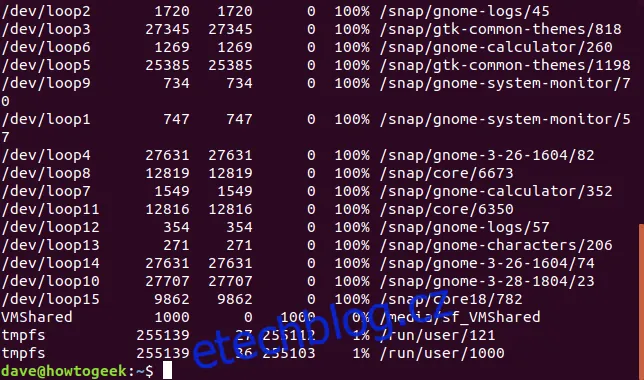
Ve výchozím nastavení df zobrazí informace o všech připojených systémech souborů. To může vést k nepřehlednému výstupu. Například položky typu /dev/loop jsou pseudo systémy souborů, které umožňují připojení souboru, jako by šlo o diskový oddíl. Zejména pokud používáte snap balíčky v Ubuntu, můžete mít takových položek mnoho. Místo na nich bývá vždy 0, protože se o skutečné systémy souborů nejedná, a proto je z výpisu můžeme vyloučit.
Příkazu df můžeme nařídit, aby vynechal systémy souborů určitého typu. Nejprve je ale potřeba zjistit, jaký typ souborového systému chcete vynechat. Pro tento účel slouží volba -T (print type), která do výstupu přidá i typ souborového systému.
df -T
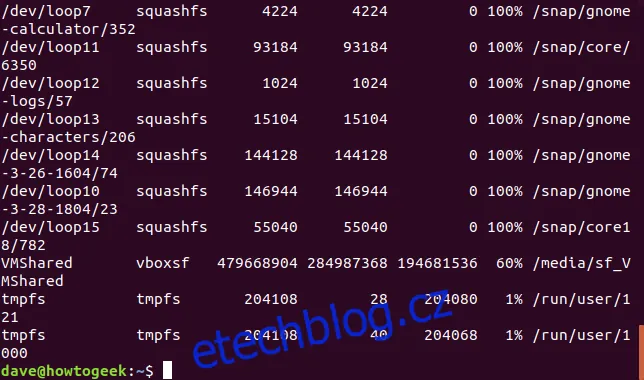
Položky /dev/loop jsou, jak vidíme, typu squashfs. Tyto můžeme vyloučit následujícím příkazem:
df -x squashfs
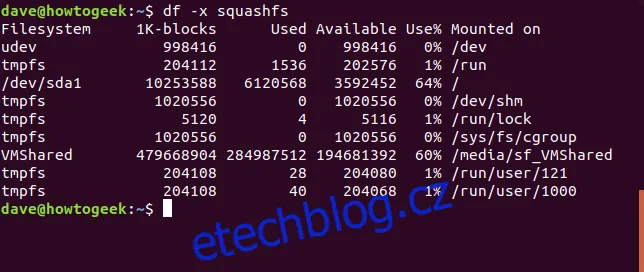
Výsledkem je přehlednější výpis. Pokud chceme zobrazit i celkový součet, použijeme volbu --total.
df -x squashfs --total
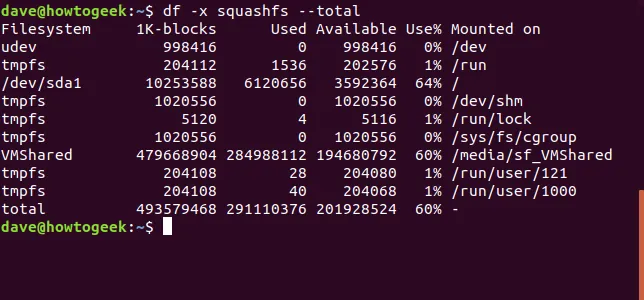
Podobně můžeme df instruovat, aby zahrnul pouze systémy souborů konkrétního typu, pomocí volby -t (type).
df -t ext4
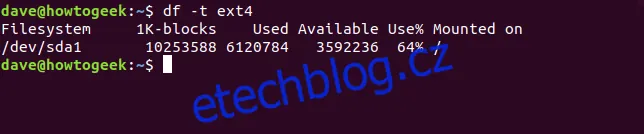
Pokud potřebujeme zobrazit data pro konkrétní sadu systémů souborů, můžeme je zadat podle názvu. V Linuxu se diskové jednotky označují písmeny abecedy. První disk je /dev/sda, druhý /dev/sdb, atd. Jednotlivé oddíly jsou očíslovány. Takže /dev/sda1 je první oddíl na disku /dev/sda. Informace o konkrétním systému souborů získáme tak, že jeho název předáme jako parametr příkazu df. Zobrazme si data pro první oddíl na prvním disku.
df /dev/sda1
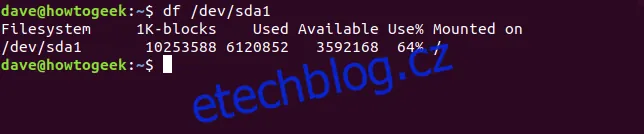
V názvu systémů souborů můžeme používat i zástupné znaky, kde * zastupuje libovolný řetězec znaků a ? zastupuje libovolný jeden znak. Pro zobrazení všech oddílů na prvním disku bychom mohli použít:
df /dev/sda*
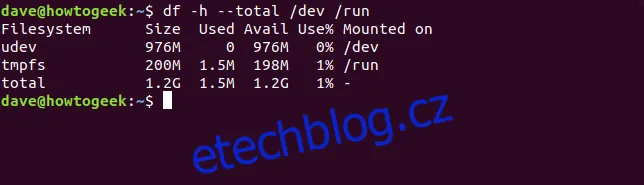
Příkaz df můžeme také požádat o zobrazení informací pro více konkrétních systémů souborů. Například pro zobrazení celkových velikostí systémů /dev a /run:
df -h --total /dev /run
Pro další úpravu výstupu můžeme df nařídit, které sloupce má zahrnout. Toho dosáhneme pomocí volby --output a seznamu požadovaných názvů sloupců oddělených čárkami (bez mezer). Níže je popis jednotlivých sloupců:
| source: | Název systému souborů. |
| fstype: | Typ systému souborů. |
| itotal: | Celková velikost systému souborů v inodech. |
| iused: | Obsazený prostor v systému souborů v inodech. |
| iavail: | Volný prostor v systému souborů v inodech. |
| ipcent: | Procentuální podíl obsazeného místa v systému souborů v inodech. |
| size: | Celková velikost systému souborů (standardně v blocích 1K). |
| used: | Obsazený prostor v systému souborů (standardně v blocích 1K). |
| avail: | Volný prostor v systému souborů (standardně v blocích 1K). |
| pcent: | Procentuální podíl obsazeného místa v systému souborů (standardně v blocích 1K). |
| file: | Název systému souborů, pokud byl zadán v příkazovém řádku. |
| target: | Bod připojení systému souborů. |
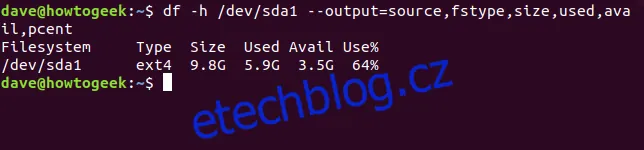
Pojďme požádat df o zobrazení informací o prvním oddílu na prvním disku, v lidsky čitelné formě, se sloupci source, fstype, size, used, avail a pcent:
df -h /dev/sda1 --output=source,fstype,size,used,avail,pcent
Dlouhé příkazy jsou ideální pro vytvoření aliasu. Můžeme si vytvořit alias dfc (pro "df custom"), a to zadáním:
alias dfc="df -h /dev/sda1 --output=source,fstype,size,used,avail,pcent"
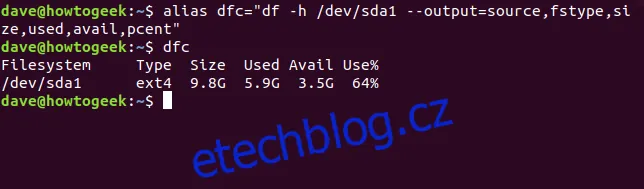
Nyní zadání dfc a stisknutí klávesy Enter bude mít stejný efekt jako zadání celého původního příkazu. Pro zachování aliasu i po restartu systému je nutné jej přidat do souboru .bashrc nebo .bash_aliases.
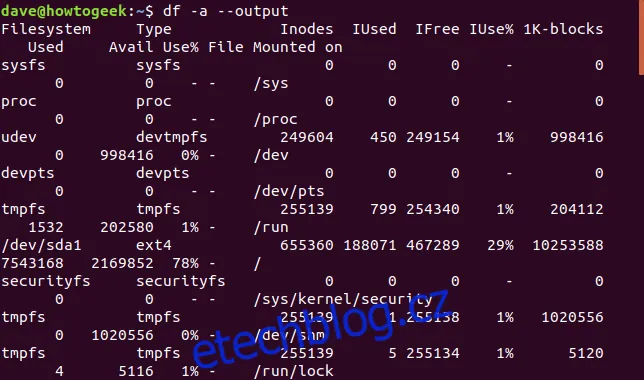
Ukázali jsme si, jak zpřesnit výstup příkazu df tak, aby zobrazoval pouze potřebné informace. Můžeme ale zvolit i opačný přístup a nechat příkaz vypsat všechny dostupné informace. To lze docílit pomocí volby -a (all) a --output bez seznamu sloupců, jak je ukázáno níže:
df -a --output
Pokud je výstup z příkazu df příliš rozsáhlý, lze jej snadno zpracovat pomocí programu less:
df -a --output | less
Zjištění, co zabírá místo na disku
Nyní se podíváme na to, jak zjistit, co přesně zabírá nejvíce místa na disku. Začneme jedním z příkazů df:
df -h -t ext4

Vidíme, že na prvním oddílu prvního pevného disku je využito 78% místa. Pomocí příkazu du můžeme zjistit, které složky zabírají nejvíce místa. Pokud spustíme du bez parametrů, vypíší se všechny adresáře a podadresáře pod adresářem, ve kterém jsme příkaz spustili. Pokud bychom to provedli z domovské složky, byl by výpis velmi dlouhý.
du
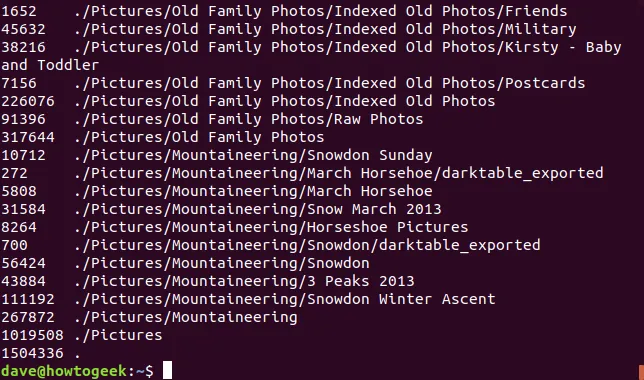
Formát výstupu je jednoduchý: každý řádek zobrazuje velikost a název adresáře. Velikost je implicitně zobrazena v blocích 1 KB. Pro změnu velikosti bloku použijeme volbu -B (block size). Stejně jako u df zadáváme po -B písmena z řady K, M, G, T, P, E, Z a Y. Například pro zobrazení velikosti v 1 MB blocích použijeme příkaz:
du -BM
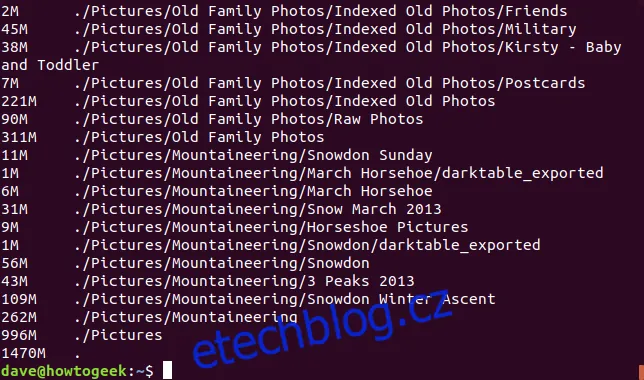
Stejně jako df, i du má lidsky čitelnou volbu -h, která automaticky použije nejvhodnější jednotky pro každou velikost adresáře.
du -h
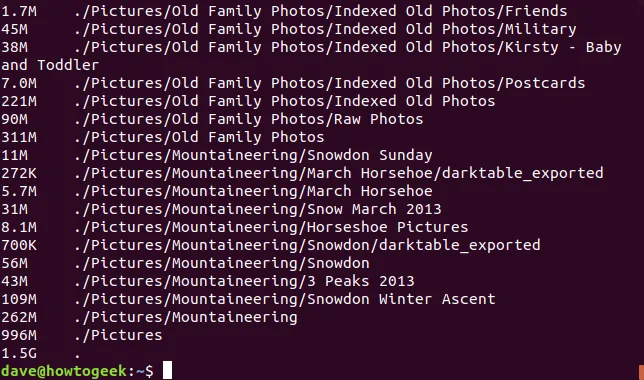
Volba -s (summarize) zobrazí souhrnnou velikost každého adresáře, bez výpisu jeho podadresářů. Následující příkaz tedy zobrazí souhrnné informace v lidsky čitelné formě pro všechny adresáře v aktuálním pracovním adresáři:
du -h -s *
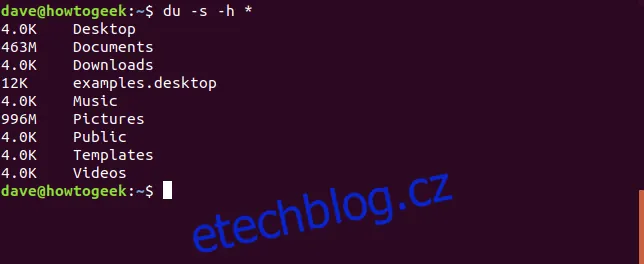
Zobrazíme-li si velikosti adresářů ve složce Pictures, seřazené od největšího po nejmenší, zjistíme:
du -sm Pictures/* | sort -nr
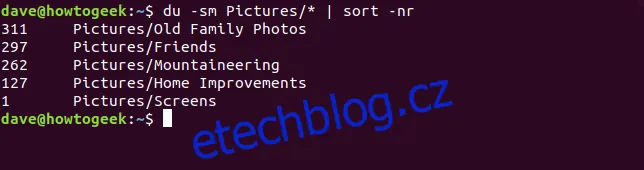
Složka Pictures tedy obsahuje zdaleka nejvíce dat. Díky seřazení můžeme snadno zjistit, které složky zabírají nejvíce místa.
Díky možnostem příkazů df a du můžeme snadno zjistit, kolik místa na disku je využito, a také, co konkrétně toto místo zabírá. Na základě těchto informací se můžeme rozhodnout, zda je nutné přesunout některá data na jiné úložiště, přidat nový pevný disk, nebo odstranit nadbytečná data. Tyto příkazy nabízejí mnoho dalších možností, zde jsme popsali ty nejběžnější. Kompletní seznam voleb pro příkaz df a pro příkaz du naleznete v manuálových stránkách Linuxu.
