Podpora vektorového stroje (SVM) ve strojovém učení
Support Vector Machine, neboli SVM, je oblíbený algoritmus v oblasti strojového učení. Proslul svou efektivitou a schopností učit se i z menších datových souborů. Ale co vlastně SVM je?
Co je to podpůrný vektorový stroj (SVM)?
Podpůrný vektorový stroj (SVM) je algoritmus strojového učení, který využívá principů řízeného učení. Jeho cílem je vytvořit model pro binární klasifikaci. Chápu, že to může znít složitě. Proto se v tomto článku podíváme na to, co přesně SVM je, jak funguje, a jak se používá v kontextu zpracování přirozeného jazyka. Začněme tím, jak SVM funguje.
Jak SVM funguje?
Představme si jednoduchý klasifikační problém. Máme data se dvěma rysy, označenými jako x a y, a jeden výstup – klasifikaci, která může být buď červená, nebo modrá. Zkusme si vizualizovat, jak by taková imaginární datová sada mohla vypadat:
Naším úkolem je v tomto případě vytvořit hranici rozhodování. To je čára, která odděluje dvě skupiny datových bodů. Zde je stejná data sada, ale s vyznačenou hranicí rozhodování:
Díky této hranici rozhodování můžeme následně předpovídat, do které kategorie patří nový datový bod, a to podle jeho pozice vzhledem k hranici. Algoritmus podpůrného vektorového stroje se snaží najít tu nejlepší možnou hranici pro klasifikaci datových bodů.
Co ale znamená "nejlepší hranice rozhodování"?
Nejlepší rozhodovací hranice je ta, která maximalizuje svou vzdálenost od takzvaných podpůrných vektorů. Podpůrné vektory jsou ty datové body z obou kategorií, které jsou nejblíže protilehlé kategorii. Tyto body představují největší riziko chybné klasifikace kvůli jejich blízkosti k jiné kategorii.
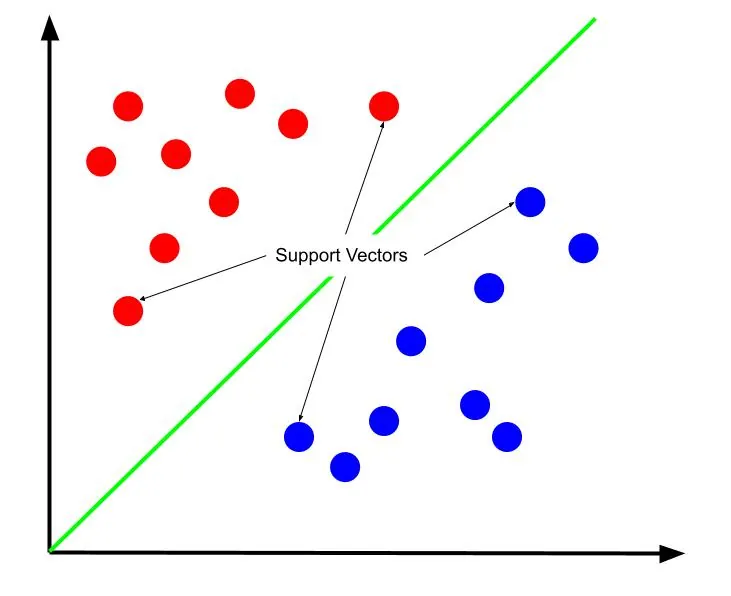
Trénování SVM spočívá v hledání čáry, která maximalizuje vzdálenost mezi podpůrnými vektory. Jinými slovy, hledáme tu nejširší "uličku" mezi kategoriemi.
Je důležité si uvědomit, že poloha rozhodovací hranice je určena výhradně polohou podpůrných vektorů. Ostatní datové body jsou v tomto smyslu nadbytečné. Proto trénování vyžaduje pouze podpůrné vektory.
V tomto příkladu je rozhodovací hranice přímka. Je to proto, že datová sada má pouze dva rysy. Pokud by měla datová sada tři rysy, hranice by byla rovina. A v případě čtyř a více rysů mluvíme o nadrovině.
Nelineárně oddělitelná data
Předchozí příklad pracoval s jednoduchými daty, která lze oddělit přímkou. Co ale v případě, kdy data po zobrazení vypadají takto?
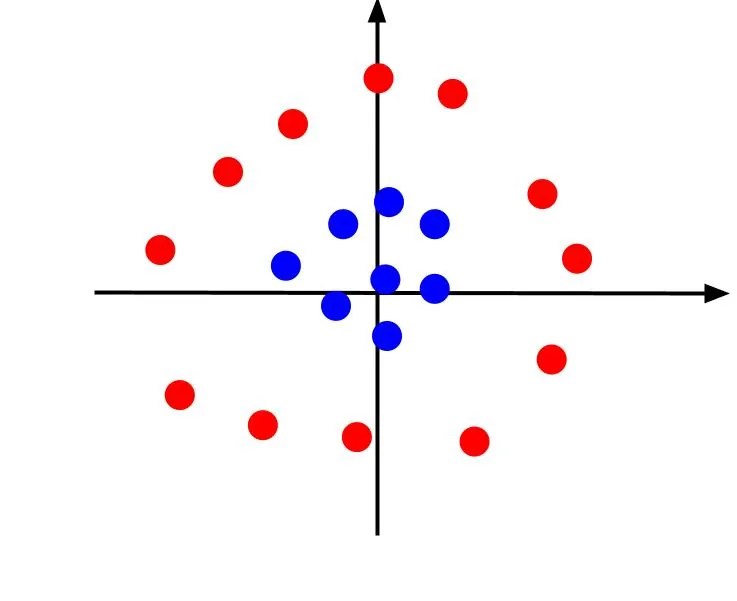
V tomto případě nemůžeme data oddělit přímkou. Můžeme však vytvořit další rys, z. Tento rys může být definován rovnicí: z = x^2 + y^2. Tímto přidáme třetí osu do roviny, a dostaneme trojrozměrný prostor.
Pokud se na 3D graf podíváme tak, že osa x je vodorovná a osa z svislá, získáme něco takového:
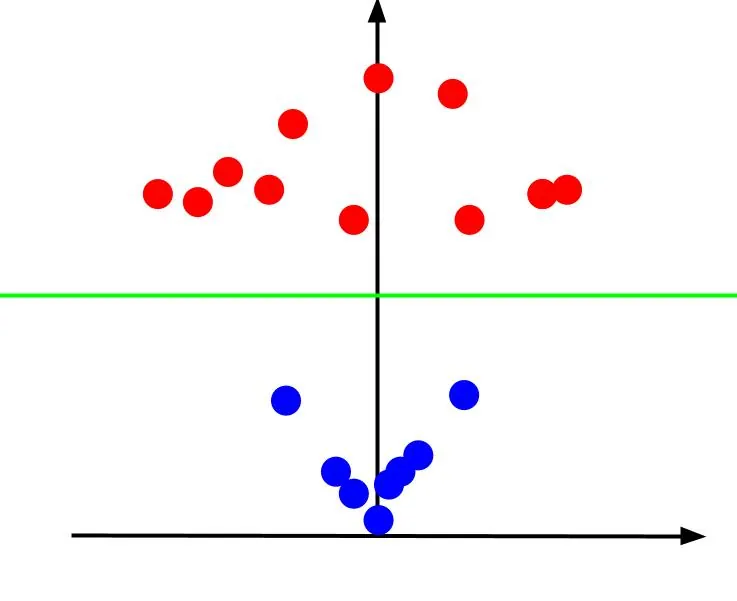
Hodnota z udává vzdálenost bodu od počátku vzhledem k ostatním bodům v původní rovině XY. Modré body, které jsou blíže k počátku, mají tedy nízké hodnoty z.
Červené body, které jsou dále od počátku, mají vyšší hodnoty z. Vynesení proti hodnotám z nám dá klasifikaci, kterou už lze oddělit lineární hranicí.
Toto je mocný koncept, který se v SVM používá. Obecně jde o mapování dimenzí do většího počtu dimenzí, aby datové body mohly být odděleny lineární hranicí. Funkce, které za toto mapování zodpovídají, se nazývají funkce jádra. Existuje mnoho typů funkcí jádra, například sigmoidní, lineární, nelineární a RBF.
SVM používá takzvaný trik s jádrem, aby bylo mapování efektivnější.
SVM ve strojovém učení
Support Vector Machine je jedním z mnoha algoritmů používaných ve strojovém učení. Vedle něj stojí populární algoritmy jako rozhodovací stromy a neuronové sítě. SVM je oblíbené díky tomu, že dobře pracuje i s menším objemem dat. Běžně se používá pro:
- Klasifikaci textu: Třídění textových dat, například komentářů a recenzí, do různých kategorií.
- Detekci obličeje: Analýza obrázků za účelem identifikace obličejů, například pro přidávání filtrů v rozšířené realitě.
- Klasifikaci obrázků: SVM dokáže efektivně klasifikovat obrázky ve srovnání s jinými metodami.
Problém klasifikace textu
Internet je plný textových dat. Většina z nich je však nestrukturovaná a neoznačená. Aby bylo možné tato data efektivně využívat, je nutné je klasifikovat. Příklady použití klasifikace textu zahrnují:
- Třídění tweetů do témat, aby uživatelé mohli snadno sledovat, co je zajímá.
- Kategorizace e-mailů jako Sociální sítě, Propagace nebo Spam.
- Klasifikace komentářů na veřejných fórech jako nenávistné nebo obscénní.
Jak SVM funguje s klasifikací přirozeného jazyka
Support Vector Machine se používá k rozdělení textu na ten, který patří do určitého tématu, a ten, který do něj nepatří. Nejprve je text převeden do datové sady s několika rysy.
Jedním ze způsobů je vytvořit rys pro každé slovo v datové sadě. Pro každý textový datový bod se pak zaznamená, kolikrát se každé slovo vyskytuje. Předpokládejme, že se v datové sadě vyskytuje unikátních slov. Potom budeme mít rysů v datové sadě.
Kromě toho je třeba definovat klasifikaci pro každý datový bod. Tyto klasifikace jsou obvykle reprezentovány textem, ale SVM algoritmy obecně očekávají číselné štítky.
Proto je nutné tyto štítky před trénováním převést na číselné. Jakmile je datová sada připravena, lze použít model SVM pro klasifikaci textu.
Vytvoření SVM v Pythonu
Pro vytvoření podpůrného vektorového stroje (SVM) v Pythonu lze použít třídu SVC z knihovny sklearn.svm. Zde je příklad, jak ji použít:
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
# Načtení datové sady
X = ...
y = ...
# Rozdělení dat na trénovací a testovací sadu
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=19)
# Vytvoření SVM modelu
model = SVC(kernel="linear")
# Trénování modelu na trénovacích datech
model.fit(X_train, y_train)
# Vyhodnocení modelu na testovacích datech
accuracy = model.score(X_test, y_test)
print("Přesnost: ", accuracy)
V tomto příkladu nejprve importujeme třídu SVC z knihovny sklearn.svm a funkci train_test_split z knihovny model_selection. Poté načteme data a rozdělíme je na trénovací a testovací sady.
Následně vytvoříme model SVM instancí objektu SVC a nastavením parametru jádra na "lineární". Model natrénujeme na trénovacích datech pomocí metody fit a vyhodnotíme ho na testovacích datech pomocí metody score. Metoda score vrací přesnost modelu, kterou následně vypíšeme do konzole.
Můžete také nastavit další parametry objektu SVC, například parametr C, který ovlivňuje sílu regularizace, a parametr gamma, který ovlivňuje koeficient jádra pro některá jádra.
Výhody SVM
Zde je seznam některých výhod použití podpůrných vektorových strojů (SVM):
- Efektivita: SVM jsou obecně efektivní při trénování, zejména když je velký počet vzorků.
- Odolnost vůči šumu: SVM jsou relativně odolné vůči šumu v trénovacích datech, protože se snaží najít klasifikátor s maximální rezervou, který je méně citlivý na šum než jiné klasifikátory.
- Efektivní využití paměti: SVM vyžadují v paměti pouze podmnožinu trénovacích dat, což je paměťově efektivnější než u jiných algoritmů.
- Efektivní ve vysokodimenzionálních prostorech: SVM mohou dobře fungovat i v případě, že je počet rysů větší než počet vzorků.
- Všestrannost: SVM lze použít pro klasifikační i regresní úlohy a mohou pracovat s různými typy dat, včetně lineárních i nelineárních.
Nyní se podívejme na některé z nejlepších zdrojů, kde se můžete o Support Vector Machine (SVM) dozvědět více.
Výukové zdroje
Úvod do podpory vektorových strojů
Tato kniha, "Úvod do podpory vektorových strojů", vás komplexně a postupně seznámí s metodami učení založeného na jádru.
Poskytne vám pevný základ v teorii podpůrných vektorových strojů.
Aplikace podpory vektorových strojů
Zatímco první kniha se zaměřovala na teorii, tato kniha "Aplikace podpory vektorových strojů" se soustředí na jejich praktické použití.
Detailně pojednává o tom, jak se SVM používají při zpracování obrazu, detekci vzorů a počítačovém vidění.
Support Vector Machines (informační věda a statistika)
Účelem knihy "Podpůrné vektorové stroje (informační věda a statistika)" je poskytnout přehled principů efektivnosti SVM v různých aplikacích.
Autoři zdůrazňují faktory, které přispívají k úspěchu SVM, včetně jejich schopnosti dobře pracovat s omezeným počtem parametrů, odolnosti vůči různým chybám a anomáliím, a efektivního výpočetního výkonu ve srovnání s jinými metodami.
Učení s jádry
"Learning with Kernels" je kniha, která seznamuje čtenáře s podpůrnými vektorovými stroji (SVM) a souvisejícími technikami jádra.
Cílem je poskytnout čtenářům matematické základy a znalosti potřebné k používání algoritmů jádra ve strojovém učení. Kniha nabízí důkladný a zároveň přístupný úvod do SVM a metod jádra.
Podporujte vektorové stroje pomocí Sci-kit Learn
Tento online kurz "Support Vector Machines with Sci-Kit Learn" od projektu Coursera učí, jak implementovat model SVM pomocí oblíbené knihovny strojového učení Sci-Kit Learn.

Dále se naučíte teorii SVM a pochopíte jejich silné stránky a omezení. Kurz je určen pro začátečníky a trvá přibližně 2,5 hodiny.
Podpora vektorových strojů v Pythonu: koncepty a kód
Placený online kurz "Support Vector Machines in Python" od Udemy nabízí až 6 hodin video výuky a certifikát.

Kurz pokrývá SVM a jejich spolehlivou implementaci v Pythonu, včetně obchodních aplikací.
Strojové učení a AI: Podpora vektorových strojů v Pythonu
V tomto kurzu o strojovém učení a umělé inteligenci se naučíte používat SVM pro různé praktické aplikace, včetně rozpoznávání obrázků, detekce spamu, lékařské diagnostiky a regresní analýzy.

Pro implementaci ML modelů pro tyto aplikace budete používat programovací jazyk Python.
Závěrečná slova
V tomto článku jsme se stručně seznámili s teorií podpůrných vektorových strojů, jejich aplikací ve strojovém učení a zpracování přirozeného jazyka.
Viděli jsme také příklad implementace pomocí scikit-learn, hovořili jsme o praktických aplikacích a výhodách SVM.
Tento článek sloužil jako úvod, doporučené zdroje vám pomohou ponořit se do detailů a lépe pochopit Support Vector Machines. Vzhledem k jejich všestrannosti a efektivitě stojí za to SVM dobře pochopit, pokud se chcete stát datovým vědcem nebo ML inženýrem.
Dále se můžete podívat na další modely strojového učení.
