
Support Vector Machine patří mezi nejoblíbenější algoritmy strojového učení. Je efektivní a může trénovat v omezených souborech dat. Ale co to je?
Table of Contents
Co je podpůrný vektorový stroj (SVM)?
Support vector machine je algoritmus strojového učení, který využívá řízené učení k vytvoření modelu pro binární klasifikaci. To je sousto. Tento článek vysvětlí SVM a jak souvisí se zpracováním přirozeného jazyka. Nejprve však analyzujme, jak funguje stroj podporující vektor.
Jak funguje SVM?
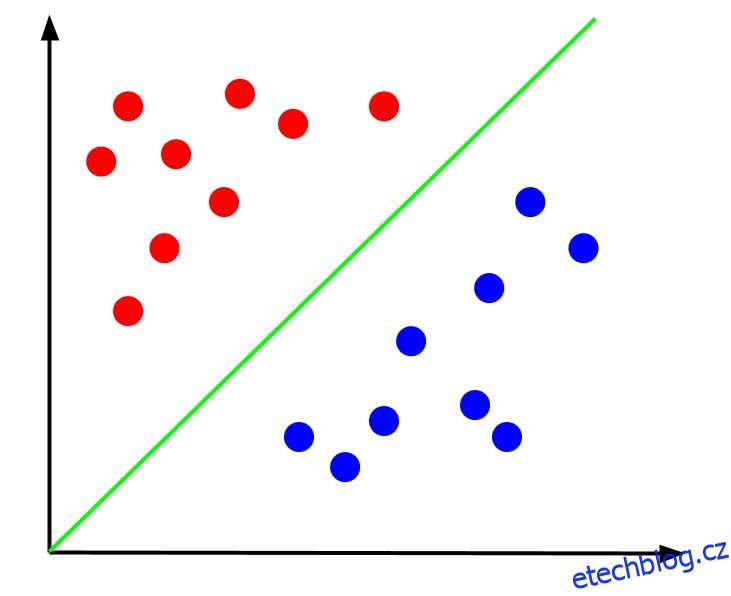
Zvažte jednoduchý klasifikační problém, kde máme data, která mají dva rysy, x a y, a jeden výstup – klasifikaci, která je buď červená nebo modrá. Můžeme vykreslit imaginární datovou sadu, která vypadá takto:
Vzhledem k těmto datům by úkolem bylo vytvořit hranici rozhodování. Rozhodovací hranice je čára, která odděluje dvě třídy našich datových bodů. Toto je stejný soubor dat, ale s hranicí rozhodnutí:
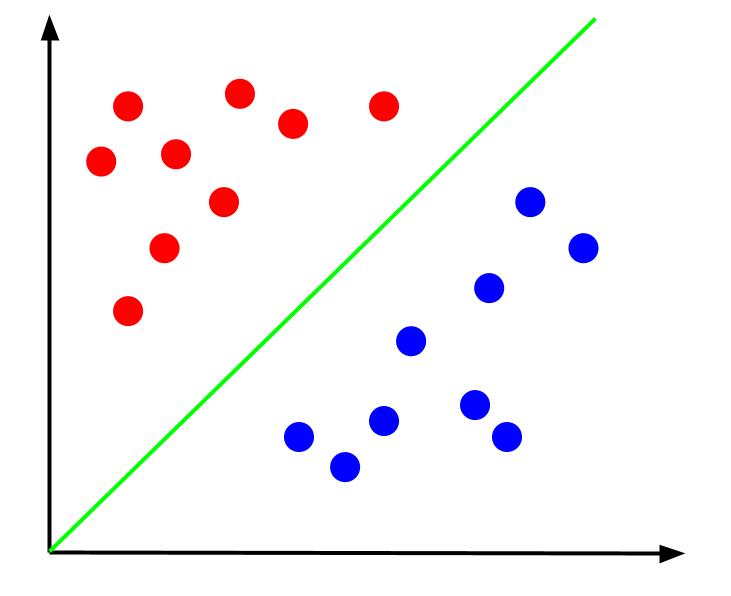
S touto rozhodovací hranicí pak můžeme předpovídat, do které třídy datový bod patří, vzhledem k tomu, kde leží vzhledem k rozhodovací hranici. Algoritmus Support Vector Machine vytvoří nejlepší hranici rozhodování, která bude použita pro klasifikaci bodů.
Co ale rozumíme nejlepší hranicí rozhodování?
Za nejlepší rozhodovací hranici lze tvrdit, že je ta, která maximalizuje svou vzdálenost od jednoho z podpůrných vektorů. Podpůrné vektory jsou datové body kterékoli třídy, která je nejblíže opačné třídě. Tyto datové body představují největší riziko chybné klasifikace kvůli jejich blízkosti k jiné třídě.
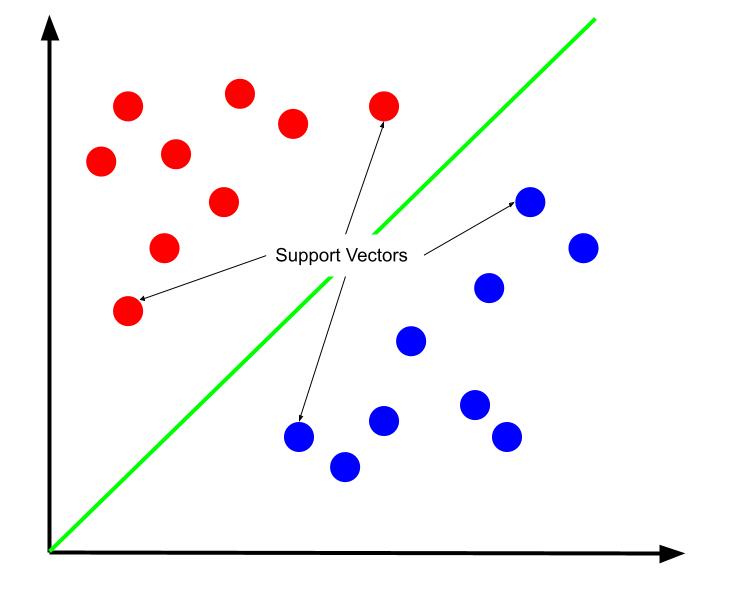
Trénink stroje podpůrných vektorů proto zahrnuje snahu najít čáru, která maximalizuje rozpětí mezi podpůrnými vektory.
Je také důležité poznamenat, že protože rozhodovací hranice je umístěna vzhledem k podpůrným vektorům, jsou jedinými determinanty polohy rozhodovací hranice. Ostatní datové body jsou proto nadbytečné. A tak trénink vyžaduje pouze podpůrné vektory.
V tomto příkladu je vytvořená rozhodovací hranice přímka. Je to jen proto, že datová sada má pouze dvě funkce. Když má datová množina tři prvky, tvořící se hranice rozhodování je spíše rovina než čára. A když má čtyři nebo více prvků, je rozhodovací hranice známá jako nadrovina.
Nelineárně oddělitelná data
Výše uvedený příklad považoval za velmi jednoduchá data, která po vynesení lze oddělit lineární hranicí rozhodování. Zvažte jiný případ, kdy jsou data vykreslena následovně:
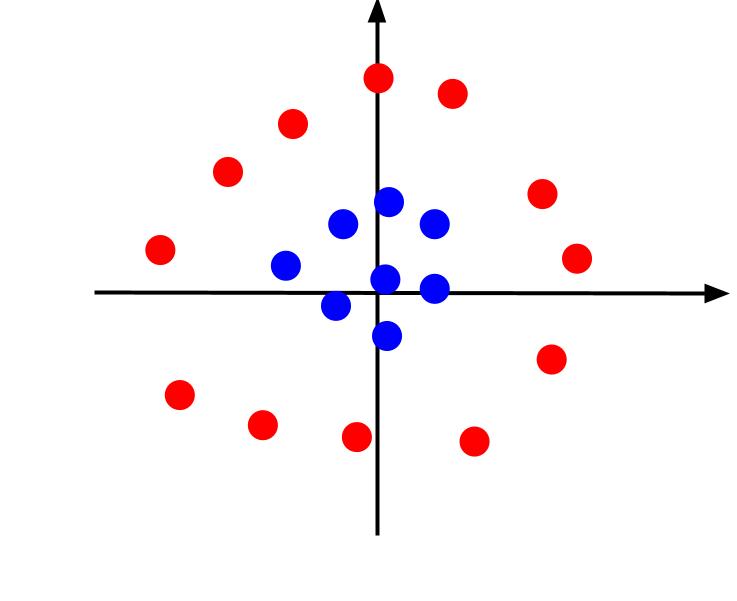
V tomto případě není možné oddělit data pomocí čáry. Ale můžeme vytvořit další funkci, z. A tato vlastnost může být definována rovnicí: z = x^2 + y^2. Můžeme přidat z jako třetí osu do roviny, aby byla trojrozměrná.
Když se podíváme na 3D graf z takového úhlu, že osa x je vodorovná, zatímco osa z je svislá, dostaneme něco, co vypadá takto:
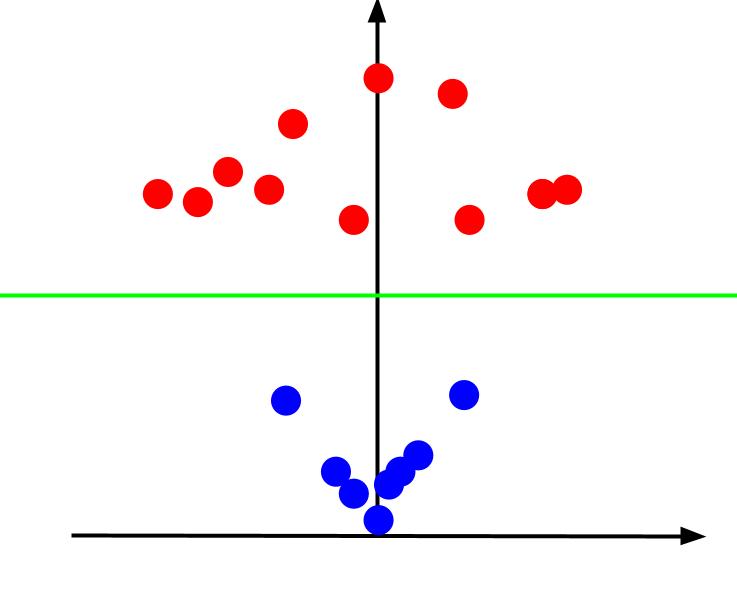
Hodnota z představuje, jak daleko je bod od počátku vzhledem k ostatním bodům ve staré rovině XY. V důsledku toho mají modré body blíže k počátku nízké hodnoty z.
Zatímco červené body dále od počátku měly vyšší z-hodnoty, jejich vynesení proti jejich z-hodnotám nám dává jasnou klasifikaci, kterou lze vymezit lineární rozhodovací hranicí, jak je znázorněno.
Toto je výkonný nápad, který se používá v Support Vector Machines. Obecněji se jedná o myšlenku mapování dimenzí do většího počtu dimenzí tak, aby datové body mohly být odděleny lineární hranicí. Funkce, které jsou za to zodpovědné, jsou funkce jádra. Existuje mnoho funkcí jádra, jako je sigmoidní, lineární, nelineární a RBF.
Aby bylo mapování těchto funkcí efektivnější, používá SVM trik s jádrem.
SVM ve strojovém učení
Support Vector Machine je jedním z mnoha algoritmů používaných ve strojovém učení spolu s populárními, jako jsou rozhodovací stromy a neuronové sítě. Je oblíbený, protože funguje dobře s menším počtem dat než jiné algoritmy. Běžně se používá k následujícímu:
- Klasifikace textu: Klasifikace textových dat, jako jsou komentáře a recenze, do jedné nebo více kategorií
- Detekce obličeje: Analýza snímků za účelem detekce obličejů, například přidání filtrů pro rozšířenou realitu
- Klasifikace obrázků: Podporované vektorové stroje mohou klasifikovat obrázky efektivně ve srovnání s jinými přístupy.
Problém klasifikace textu
Internet je plný spousty a spousty textových dat. Velká část těchto dat je však nestrukturovaná a neoznačená. Pro lepší využití těchto textových dat a jejich lepší pochopení je potřeba klasifikace. Příklady případů, kdy je text klasifikován, zahrnují:
- Když jsou tweety kategorizovány do témat, aby lidé mohli sledovat témata, která chtějí
- Když je e-mail kategorizován jako Sociální sítě, Propagace nebo Spam
- Když jsou komentáře na veřejných fórech klasifikovány jako nenávistné nebo obscénní
Jak SVM pracuje s klasifikací přirozeného jazyka
Support Vector Machine se používá ke klasifikaci textu na text, který patří k určitému tématu, a text, který do tématu nepatří. Toho je dosaženo nejprve převedením a reprezentací textových dat do datové sady s několika funkcemi.
Jedním ze způsobů, jak toho dosáhnout, je vytvoření funkcí pro každé slovo v sadě dat. Poté pro každý textový datový bod zaznamenáte, kolikrát se každé slovo vyskytuje. Předpokládejme tedy, že se v sadě dat vyskytují jedinečná slova; budete mít funkce v datové sadě.
Kromě toho poskytnete klasifikaci těchto datových bodů. Zatímco tyto klasifikace jsou označeny textem, většina implementací SVM očekává číselné štítky.
Proto budete muset tyto štítky před tréninkem převést na čísla. Jakmile je datová sada připravena pomocí těchto funkcí jako souřadnic, můžete pak použít model SVM ke klasifikaci textu.
Vytvoření SVM v Pythonu
K vytvoření podpůrného vektorového stroje (SVM) v Pythonu můžete použít třídu SVC z knihovny sklearn.svm. Zde je příklad toho, jak můžete použít třídu SVC k vytvoření modelu SVM v Pythonu:
from sklearn.svm import SVC
# Load the dataset
X = ... y = ...
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=19)
# Create an SVM model
model = SVC(kernel="linear")
# Train the model on the training data
model.fit(X_train, y_train)
# Evaluate the model on the test data
accuracy = model.score(X_test, y_test)
print("Accuracy: ", accuracy)
V tomto příkladu nejprve importujeme třídu SVC z knihovny sklearn.svm. Poté načteme datovou sadu a rozdělíme ji na trénovací a testovací sady.
Dále vytvoříme model SVM vytvořením instance objektu SVC a zadáním parametru jádra jako „lineární“. Model pak natrénujeme na trénovacích datech pomocí metody fit a model vyhodnotíme na testovacích datech metodou skóre. Metoda skóre vrací přesnost modelu, kterou vytiskneme do konzole.
Můžete také zadat další parametry pro objekt SVC, jako je parametr C, který řídí sílu regularizace, a parametr gamma, který řídí koeficient jádra pro určitá jádra.
Výhody SVM
Zde je seznam některých výhod používání podpůrných vektorových strojů (SVM):
- Efektivní: SVM jsou obecně efektivní při trénování, zvláště když je počet vzorků velký.
- Robust to Noise: SVM jsou relativně odolné vůči šumu v trénovacích datech, protože se snaží najít klasifikátor maximální rezervy, který je méně citlivý na šum než jiné klasifikátory.
- Paměťově efektivní: SVM vyžadují, aby byla v daný čas v paměti pouze podmnožina trénovacích dat, díky čemuž jsou paměťově efektivnější než jiné algoritmy.
- Efektivní ve velkorozměrných prostorech: SVM mohou stále fungovat dobře, i když počet funkcí převyšuje počet vzorků.
- Všestrannost: SVM mohou být použity pro klasifikační a regresní úlohy a mohou zpracovávat různé typy dat, včetně lineárních a nelineárních dat.
Nyní se podívejme na některé z nejlepších zdrojů, jak se naučit Support Vector Machine (SVM).
Výukové zdroje
Úvod do podpory vektorových strojů
Tato kniha Úvod do podpory vektorových strojů vás komplexně a postupně seznámí s metodami učení založeného na jádru.
Poskytuje vám pevný základ na teorii podpůrných vektorových strojů.
Podpora aplikací vektorových strojů
Zatímco první kniha byla zaměřena na teorii podpůrných vektorových strojů, tato kniha o aplikacích podpůrných vektorových strojů se zaměřuje na jejich praktické aplikace.
Zabývá se tím, jak se SVM používají při zpracování obrazu, detekci vzorů a počítačovém vidění.
Support Vector Machines (informační věda a statistika)
Účelem této knihy o podpůrných vektorových strojích (informační věda a statistika) je poskytnout přehled principů účinnosti podpůrných vektorových strojů (SVM) v různých aplikacích.
Autoři zdůrazňují několik faktorů, které přispívají k úspěchu SVM, včetně jejich schopnosti dobře fungovat s omezeným počtem nastavitelných parametrů, jejich odolnosti vůči různým typům chyb a anomálií a jejich efektivního výpočetního výkonu ve srovnání s jinými metodami.
Učení s jádry
“Learning with Kernels” je kniha, která seznamuje čtenáře s podporou vektorových strojů (SVM) a souvisejících technik jádra.
Je navržen tak, aby čtenářům poskytl základní porozumění matematice a znalosti, které potřebují, aby mohli začít používat algoritmy jádra ve strojovém učení. Kniha si klade za cíl poskytnout důkladný, ale dostupný úvod do SVM a metod jádra.
Podporujte vektorové stroje pomocí Sci-kit Learn
Tento online kurz Support Vector Machines with Sci-Kit Learn od sítě projektu Coursera učí, jak implementovat model SVM pomocí oblíbené knihovny strojového učení Sci-Kit Learn.

Kromě toho se naučíte teorii SVM a určíte jejich silné stránky a omezení. Kurz je pro začátečníky a trvá asi 2,5 hodiny.
Podpora vektorových strojů v Pythonu: koncepty a kód
Tento placený online kurz Support Vector Machines v Pythonu od Udemy má až 6 hodin video výuky a je dodáván s certifikací.

Pokrývá SVM a jak je lze spolehlivě implementovat v Pythonu. Dále pokrývá obchodní aplikace Support Vector Machines.
Strojové učení a AI: Podpora vektorových strojů v Pythonu
V tomto kurzu o strojovém učení a umělé inteligenci se naučíte, jak používat podpůrné vektorové stroje (SVM) pro různé praktické aplikace, včetně rozpoznávání obrázků, detekce spamu, lékařské diagnostiky a regresní analýzy.

K implementaci ML modelů pro tyto aplikace použijete programovací jazyk Python.
Závěrečná slova
V tomto článku jsme se krátce dozvěděli o teorii, která stojí za Support Vector Machines. Dozvěděli jsme se o jejich aplikaci v Machine Learning a Natural Langauge Processing.
Viděli jsme také, jak vypadá jeho implementace pomocí scikit-learn. Dále jsme hovořili o praktických aplikacích a výhodách Support Vector Machines.
I když byl tento článek jen úvodem, další zdroje doporučovaly jít do podrobností a vysvětlovat více o Support Vector Machines. Vzhledem k tomu, jak jsou všestranné a efektivní, stojí za to pochopit SVM, aby se staly datovým vědcem a inženýrem ML.
Dále se můžete podívat na nejlepší modely strojového učení.