
Apache Kafka a RabbitMQ jsou dva široce užívaní zprostředkovatelé zpráv, kteří umožňují oddělení výměny zpráv mezi aplikacemi. Jaké jsou jejich nejdůležitější vlastnosti a čím se od sebe liší? Pojďme ke konceptům.
Table of Contents
RabbitMQ
RabbitMQ je open-source aplikace zprostředkovatele zpráv pro komunikaci a výměnu zpráv mezi stranami. Protože byl vyvinut v Erlangu, je velmi lehký a účinný. Jazyk Erlang byl vyvinut společností Ericson se zaměřením na distribuované systémy.
Je považován za tradičnějšího zprostředkovatele zpráv. Je založen na vzoru vydavatel-odběratel, i když může zpracovávat komunikaci synchronně nebo asynchronně, v závislosti na tom, co je nastaveno v konfiguraci. Zajišťuje také doručování a objednávání zpráv mezi výrobci a spotřebiteli.
Podporuje protokoly AMQP, STOMP, MQTT, HTTP a web socket. Tři modely pro výměnu zpráv: téma, fanout a přímé:
- Přímá a individuální výměna podle tématu nebo tématu [topic]
- Všichni spotřebitelé připojení k frontě obdrží [fanout] zpráva
- Každý spotřebitel obdrží odeslanou zprávu [direct]
Níže jsou uvedeny součásti RabbitMQ:
Producenti
Producenti jsou aplikace, které vytvářejí a odesílají zprávy do RabbitMQ. Může to být jakákoli aplikace, která se může připojit k RabbitMQ a publikovat zprávy.
Spotřebitelé
Spotřebitelé jsou aplikace, které přijímají a zpracovávají zprávy od RabbitMQ. Může to být jakákoli aplikace, která se může připojit k RabbitMQ a přihlásit se k odběru zpráv.
Výměny
Burzy jsou odpovědné za příjem zpráv od producentů a jejich směrování do příslušných front. Existuje několik typů výměn, včetně přímé výměny, výměny fanout, témat a hlaviček, z nichž každá má svá vlastní pravidla směrování.
Fronty
Fronty jsou místa, kde se ukládají zprávy, dokud je spotřebitelé nespotřebují. Jsou vytvářeny aplikacemi nebo automaticky RabbitMQ, když je zpráva publikována na burze.
Vazby
Vazby definují vztah mezi výměnami a frontami. Určují směrovací pravidla pro zprávy, která používají ústředny ke směrování zpráv do příslušných front.
Architektura RabbitMQ
RabbitMQ používá model pull pro doručování zpráv. V tomto modelu spotřebitelé aktivně požadují zprávy makléře. Zprávy jsou publikovány na burzách odpovědných za směrování zpráv do příslušných front na základě směrovacích klíčů.
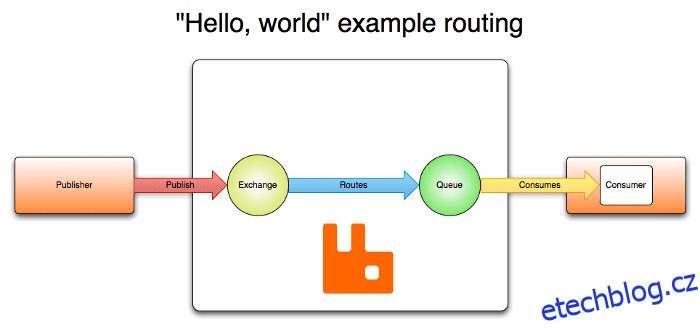
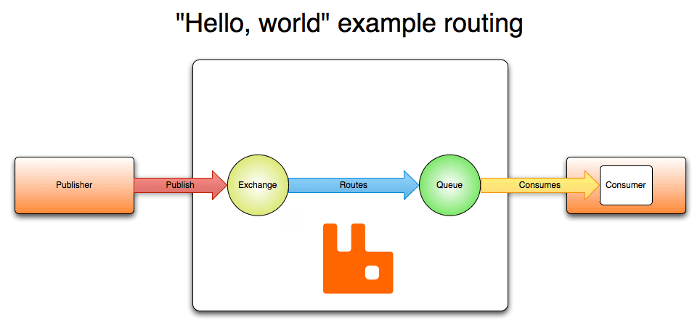
Architektura RabbitMQ je založena na architektuře klient-server a skládá se z několika komponent, které spolupracují a poskytují spolehlivou a škálovatelnou platformu pro zasílání zpráv. Koncept AMQP poskytuje komponenty Exchanges, Queues, Bindings, stejně jako Publishers a Subscribers. Vydavatelé publikují zprávy na burzách.
Burzy přebírají tyto zprávy a distribuují je do 0 až n front na základě určitých pravidel (vazeb). Zprávy uložené ve frontách pak mohou spotřebitelé načíst. Ve zjednodušené podobě se správa zpráv provádí v RabbitMQ takto:
 Zdroj obrázku: VMware
Zdroj obrázku: VMware
- Vydavatelé posílají zprávy k výměně;
- Exchange posílá zprávy do front a dalších výměn;
- Když je zpráva přijata, RabbitMQ odešle potvrzení odesílatelům;
- Spotřebitelé udržují trvalá připojení TCP k RabbitMQ a deklarují, kterou frontu přijímají;
- RabbitMQ směruje zprávy ke spotřebitelům;
- Spotřebitelé posílají potvrzení o úspěchu nebo chybě při přijetí zprávy;
- Po úspěšném přijetí je zpráva odstraněna z fronty.
Apache Kafka
Apache Kafka je distribuované open-source řešení pro zasílání zpráv vyvinuté společností LinkedIn ve Scale. Je schopen zpracovávat zprávy a ukládat je pomocí modelu vydavatel-odběratel s vysokou škálovatelností a výkonem.

Chcete-li uložit události nebo přijaté zprávy, rozdělte témata mezi uzly pomocí oddílů. Kombinuje vzory vydavatel-odběratel a fronty zpráv a je také zodpovědný za zajištění pořadí zpráv pro každého spotřebitele.
Kafka se specializuje na vysokou datovou propustnost a nízkou latenci pro zpracování datových toků v reálném čase. Toho je dosaženo tím, že se vyhneme přílišné logice na straně serveru (zprostředkovatele) a také některým speciálním implementačním detailům.
Například Kafka vůbec nepoužívá RAM a zapisuje data okamžitě do souborového systému serveru. Protože jsou všechna data zapisována sekvenčně, je dosaženo výkonu čtení a zápisu, který je srovnatelný s výkonem RAM.
Toto jsou hlavní koncepty Kafky, díky kterým je škálovatelný, výkonný a odolný proti chybám:
Téma
Téma je způsob označení nebo kategorizace zprávy; představte si skříň s 10 zásuvkami; každá zásuvka může být tématem a skříň je platforma Apache Kafka, takže kromě kategorizace zpráv do skupin by se v relačních databázích objevila další lepší analogie k tématu.
Výrobce
Producent nebo producent je ten, kdo se připojí k platformě pro zasílání zpráv a odešle jednu nebo více zpráv na určité téma.
Spotřebitel
Spotřebitel je osoba, která se připojuje k platformě pro zasílání zpráv a přijímá jednu nebo více zpráv na určité téma.
Makléř
Pojem broker v platformě Kafka není nic jiného než prakticky samotný Kafka a je to on, kdo spravuje témata a definuje způsob ukládání zpráv, logů atd.
Cluster
Cluster je sada zprostředkovatelů, kteří spolu komunikují nebo nekomunikují pro lepší škálovatelnost a odolnost proti chybám.
Log soubor
Každé téma ukládá své záznamy ve formátu protokolu, tedy strukturovaným a sekvenčním způsobem; soubor protokolu je tedy soubor, který obsahuje informace o tématu.
Příčky
Oddíly jsou vrstvou oddílů zpráv v rámci tématu; toto rozdělení zajišťuje elasticitu, odolnost proti chybám a škálovatelnost Apache Kafka, takže každé téma může mít více oddílů na různých místech.
Architektura Apache Kafka
Kafka je založen na push modelu pro doručování zpráv. Pomocí tohoto modelu jsou zprávy v Kafce aktivně předávány spotřebitelům. Zprávy jsou publikovány do témat, která jsou rozdělena a distribuována mezi různé brokery v clusteru.
Spotřebitelé se pak mohou přihlásit k odběru jednoho nebo více témat a dostávat zprávy, jak jsou k těmto tématům vytvářeny.
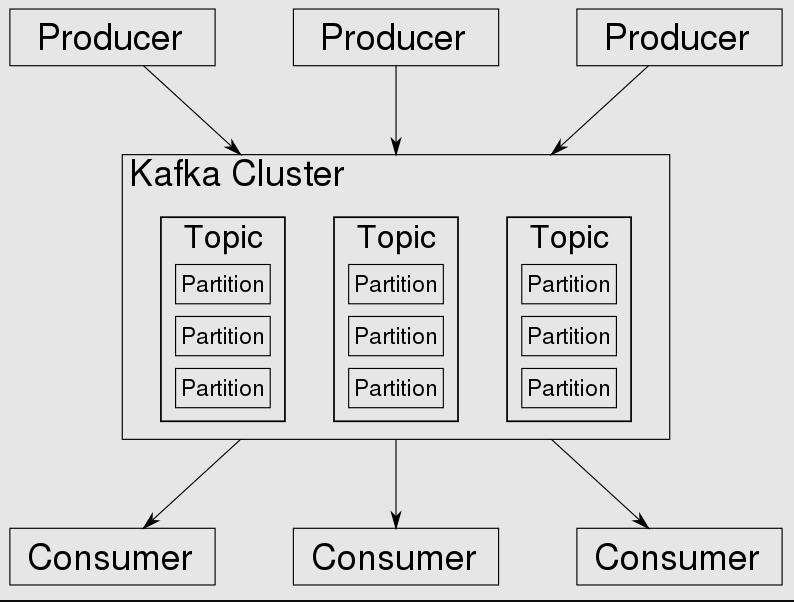
V Kafkovi je každé téma rozděleno do jednoho nebo více oddílů. Události končí v oddílu.
Pokud je v clusteru více brokerů, pak budou oddíly rozděleny rovnoměrně mezi všechny brokery (v rámci možností), což umožní škálovat zátěž při psaní a čtení v jednom tématu na více brokerů najednou. Protože se jedná o cluster, běží pomocí ZooKeeper pro synchronizaci.
Přijímá obchody a distribuuje záznamy. Záznam jsou data generovaná nějakým uzlem systému, což může být událost nebo informace. Odešle se do klastru a klastr jej uloží do tématického oddílu.
Každý záznam má sekvenční offset a spotřebitel může řídit offset, který spotřebovává. Pokud je tedy potřeba téma znovu zpracovat, lze to provést na základě offsetu.
 Zdroj obrázku: Wikipedie
Zdroj obrázku: Wikipedie
Logika, jako je správa ID poslední přečtené zprávy spotřebitele nebo rozhodování o tom, do kterého oddílu se nově příchozí data zapisují, se zcela přesune na klienta (výrobce nebo spotřebitel).
Kromě pojmů výrobce a spotřebitel existují také pojmy téma, rozdělení a replikace.
Téma popisuje kategorii zpráv. Kafka dosahuje odolnosti proti chybám replikací dat v tématu a škálováním rozdělením tématu na více serverů.
RabbitMQ vs. Kafka
Hlavní rozdíly mezi Apache Kafka a RabbitMQ jsou způsobeny zásadně odlišnými modely doručování zpráv implementovanými v těchto systémech.
Konkrétně Apache Kafka funguje na principu tahání (pull), kdy spotřebitelé sami získávají zprávy, které potřebují z tématu.
RabbitMQ na druhé straně implementuje push model odesíláním potřebných zpráv příjemcům. Jako takový se Kafka liší od RabbitMQ v následujících ohledech:
#1. Architektura
Jedním z největších rozdílů mezi RabbitMQ a Kafkou je rozdíl v architektuře. RabbitMQ používá tradiční architekturu front zpráv založenou na brokerovi, zatímco Kafka používá architekturu platformy distribuovaného streamování.
RabbitMQ také používá model doručování zpráv založený na stahování, zatímco Kafka používá model založený na push.
#2. Ukládání zpráv
RabbitMQ zařadí zprávu do fronty FIFO (First Input – First Output) a sleduje stav této zprávy ve frontě a Kafka přidá zprávu do logu (zapíše na disk), přičemž nechá příjemce, aby se postaral o získání potřebné informace z tématu.
RabbitMQ odstraní zprávu poté, co byla doručena příjemci, zatímco Kafka uloží zprávu, dokud není naplánováno vyčištění protokolu.
Kafka tak ukládá aktuální i všechny předchozí stavy systému a může být na rozdíl od RabbitMQ použit jako spolehlivý zdroj historických dat.
#3. Vyrovnávání zátěže
Díky pull modelu doručování zpráv RabbitMQ snižuje latenci. Je však možné, že příjemci přetečou, pokud zprávy dorazí do fronty rychleji, než je stihnou zpracovat.
Vzhledem k tomu, že v RabbitMQ každý příjemce požaduje/nahrává jiný počet zpráv, rozložení práce může být nerovnoměrné, což způsobí zpoždění a ztrátu pořadí zpráv během zpracování.
Aby se tomu zabránilo, každý přijímač RabbitMQ konfiguruje limit předběžného načtení, limit počtu nahromaděných nepotvrzených zpráv. V Kafce se vyrovnávání zátěže provádí automaticky přerozdělením příjemců napříč sekcemi (oddíly) tématu.
#4. Směrování
RabbitMQ zahrnuje čtyři způsoby, jak směrovat na různé burzy pro řazení do fronty, což umožňuje výkonnou a flexibilní sadu vzorů zasílání zpráv. Kafka implementuje pouze jeden způsob, jak zapisovat zprávy na disk bez směrování.
#5. Objednávání zpráv
RabbitMQ vám umožňuje udržovat relativní pořadí v libovolných sadách (skupinách) událostí a Apache Kafka poskytuje snadný způsob, jak udržovat pořadí se škálovatelností zápisem zpráv sekvenčně do replikovaného protokolu (tématu).
FeatureRabbitMQKafka ArchitectureUkládá zprávy na disk připojený k brokeroviDistribuovaná streamovací platforma architekturaDoručovací model Založeno na tahuZaloženo na PushUkládání zprávNelze ukládat zprávyUdržuje objednávky zápisem do tématuVyrovnávání zátěžeKonfiguruje limit předběžného načteníProvádí automaticky směrováníSměrováníZahrnuje pouze pořadí 4 způsoby doZprávy to topicExterní procesyNevyžaduje Vyžaduje spuštění instance ZookeeperPluginyNěkolik pluginůMá omezenou podporu pluginů
RabbitMQ a Kafka jsou oba široce používané systémy zasílání zpráv, z nichž každý má své silné stránky a případy použití. RabbitMQ je flexibilní, spolehlivý a škálovatelný systém zasílání zpráv, který vyniká ve frontě zpráv, což z něj činí ideální volbu pro aplikace, které vyžadují spolehlivé a flexibilní doručování zpráv.
Na druhou stranu je Kafka platforma pro distribuované streamování, která je navržena pro vysoce výkonné zpracování velkých objemů dat v reálném čase, díky čemuž je skvělou volbou pro aplikace, které vyžadují zpracování a analýzu dat v reálném čase.
Hlavní případy použití pro RabbitMQ:
Elektronický obchod

RabbitMQ se používá v aplikacích elektronického obchodování ke správě toku dat mezi různými systémy, jako je správa zásob, zpracování objednávek a zpracování plateb. Dokáže zpracovat velké objemy zpráv a zajistit, aby byly doručeny spolehlivě a ve správném pořadí.
Zdravotní péče
Ve zdravotnictví se RabbitMQ používá k výměně dat mezi různými systémy, jako jsou elektronické zdravotní záznamy (EHR), lékařská zařízení a systémy podpory klinického rozhodování. Může pomoci zlepšit péči o pacienty a omezit chyby tím, že zajistí, aby byly správné informace dostupné ve správný čas.
Finanční služby
RabbitMQ umožňuje zasílání zpráv v reálném čase mezi systémy, jako jsou obchodní platformy, systémy řízení rizik a platební brány. Může pomoci zajistit rychlé a bezpečné zpracování transakcí.
IoT systémy
RabbitMQ se používá v systémech IoT ke správě toku dat mezi různými zařízeními a senzory. Může pomoci zajistit, aby byla data doručována bezpečně a efektivně, a to i v prostředích s omezenou šířkou pásma a přerušovanou konektivitou.
Kafka je distribuovaná streamovací platforma navržená tak, aby zpracovávala velké objemy dat v reálném čase.
Hlavní případy použití pro Kafku
Analytika v reálném čase

Kafka se používá v analytických aplikacích v reálném čase ke zpracování a analýze dat při jejich generování, což firmám umožňuje přijímat rozhodnutí na základě aktuálních informací. Dokáže zpracovat velké objemy dat a škálovat tak, aby vyhovovaly potřebám i těch nejnáročnějších aplikací.
Agregace protokolů
Kafka může agregovat protokoly z různých systémů a aplikací, což podnikům umožňuje sledovat a odstraňovat problémy v reálném čase. Lze jej také použít k ukládání protokolů pro dlouhodobé analýzy a reportování.
Strojové učení
Kafka se používá v aplikacích strojového učení ke streamování dat do modelů v reálném čase, což firmám umožňuje předpovídat a podnikat akce na základě aktuálních informací. Může pomoci zlepšit přesnost a efektivitu modelů strojového učení.
Můj názor na RabbitMQ i Kafku
Nevýhodou širokých a rozmanitých schopností RabbitMQ pro flexibilní správu front zpráv je zvýšená spotřeba zdrojů a v důsledku toho snížení výkonu při zvýšené zátěži. Vzhledem k tomu, že se jedná o režim provozu pro složité systémy, ve většině případů je Apache Kafka tím nejlepším nástrojem pro správu zpráv.
Například v případě shromažďování a agregace mnoha událostí z desítek systémů a služeb s přihlédnutím k jejich geografickým rezervacím, klientským metrikám, log souborům a analytikám, s vyhlídkou navýšení informačních zdrojů, budu preferovat použití Kafka, pokud jste však v situaci, kdy potřebujete pouze rychlé zasílání zpráv, RabbitMQ to udělá dobře!
Můžete si také přečíst, jak nainstalovat Apache Kafka ve Windows a Linux.