
V dnešních počítačových systémech se každý den generují miliony datových záznamů. Patří mezi ně vaše finanční transakce, zadání objednávky nebo data z vašeho autosenzoru. Chcete-li zpracovávat tyto události streamování dat v reálném čase a spolehlivě přesouvat záznamy událostí mezi různými podnikovými systémy, potřebujete Apache Kafka.
Apache Kafka je open-source řešení pro streamování dat, které zpracovává více než 1 milion záznamů za sekundu. Kromě této vysoké propustnosti poskytuje Apache Kafka vysokou škálovatelnost a dostupnost, nízkou latenci a trvalé úložiště.
Společnosti jako LinkedIn, Uber a Netflix spoléhají na Apache Kafka pro zpracování a streamování dat v reálném čase. Nejjednodušší způsob, jak začít s Apache Kafka, je spustit jej na místním počítači. To vám umožní nejen vidět server Apache Kafka v akci, ale také vám umožní vytvářet a konzumovat zprávy.
Díky praktickým zkušenostem se spouštěním serveru, vytvářením témat a psaním kódu Java pomocí klienta Kafka budete připraveni používat Apache Kafka ke splnění všech vašich potřeb datového kanálu.
Table of Contents
Jak stáhnout Apache Kafka na místní počítač
Nejnovější verzi Apache Kafka si můžete stáhnout z oficiální odkaz. Stažený obsah bude komprimován do formátu .tgz. Po stažení budete muset totéž extrahovat.
Pokud používáte Linux, otevřete svůj terminál. Dále přejděte do umístění, kde jste stáhli komprimovanou verzi Apache Kafka. Spusťte následující příkaz:
tar -xzvf kafka_2.13-3.5.0.tgz
Po dokončení příkazu zjistíte, že nový adresář s názvem kafka_2.13-3.5.0. Procházejte se ve složce pomocí:
cd kafka_2.13-3.5.0
Nyní můžete vypsat obsah tohoto adresáře pomocí příkazu ls.
Uživatelé Windows mohou postupovat podle stejných kroků. Pokud nemůžete najít příkaz tar, můžete k otevření archivu použít nástroj třetí strany, jako je WinZip.
Jak spustit Apache Kafka na místním počítači
Poté, co si stáhnete a rozbalíte Apache Kafka, je čas jej spustit. Nemá žádné instalační programy. Můžete jej přímo začít používat prostřednictvím příkazového řádku nebo okna terminálu.
Než začnete s Apache Kafka, ujistěte se, že máte na svém systému nainstalovanou Java 8+. Apache Kafka vyžaduje spuštěnou instalaci Java.
#1. Spusťte server Apache Zookeeper
Prvním krokem je spuštění Apache Zookeeper. Dostanete jej předem stažený jako součást archivu. Je to služba, která je zodpovědná za udržování konfigurací a poskytování synchronizace pro další služby.
Jakmile jste v adresáři, kde jste extrahovali obsah archivu, spusťte následující příkaz:
Pro uživatele Linuxu:
bin/zookeeper-server-start.sh config/zookeeper.properties
Pro uživatele Windows:
bin/windows/zookeeper-server-start.bat config/zookeeper.properties
Soubor zookeeper.properties poskytuje konfigurace pro spuštění serveru Apache Zookeeper. Můžete nakonfigurovat vlastnosti, jako je místní adresář, kde budou data uložena, a port, na kterém bude server běžet.
#2. Spusťte server Apache Kafka
Nyní, když byl spuštěn server Apache Zookeeper, je čas spustit server Apache Kafka.
Otevřete nový terminál nebo okno příkazového řádku a přejděte do adresáře, kde jsou extrahované soubory. Poté můžete spustit server Apache Kafka pomocí příkazu níže:
Pro uživatele Linuxu:
bin/kafka-server-start.sh config/server.properties
Pro uživatele Windows:
bin/windows/kafka-server-start.bat config/server.properties
Máte spuštěný server Apache Kafka. V případě, že chcete změnit výchozí konfiguraci, můžete tak učinit úpravou souboru server.properties. Různé hodnoty jsou přítomny v oficiální dokumentace.
Jak používat Apache Kafka na místním počítači
Nyní jste připraveni začít používat Apache Kafka na svém místním počítači k vytváření a konzumaci zpráv. Vzhledem k tomu, že servery Apache Zookeeper a Apache Kafka jsou v provozu, pojďme se podívat, jak můžete vytvořit své první téma, vytvořit svou první zprávu a použít to samé.
Jaké jsou kroky k vytvoření tématu v Apache Kafka?
Než vytvoříte své první téma, pojďme pochopit, co to vlastně téma je. V Apache Kafka je tématem logické úložiště dat, které pomáhá při streamování dat. Představte si to jako kanál, kterým se data přenášejí z jedné komponenty do druhé.
Téma podporuje více výrobců a více spotřebitelů – více než jeden systém může psát a číst z tématu. Na rozdíl od jiných systémů zasílání zpráv může být jakákoli zpráva z tématu přijata více než jednou. Kromě toho můžete také zmínit dobu uchování vašich zpráv.
Vezměme si příklad systému (producenta), který produkuje data pro bankovní transakce. A jiný systém (spotřebitel) tato data spotřebuje a odešle uživateli upozornění aplikace. Aby to bylo možné, je potřeba téma.
Otevřete nový terminál nebo okno příkazového řádku a přejděte do adresáře, do kterého jste archiv extrahovali. Následující příkaz vytvoří téma nazvané transakce:
Pro uživatele Linuxu:
bin/kafka-topics.sh --create --topic transactions --bootstrap-server localhost:9092
Pro uživatele Windows:
bin/windows/kafka-topics.bat --create --topic transactions --bootstrap-server localhost:9092
Nyní jste vytvořili své první téma a jste připraveni začít vytvářet a přijímat zprávy.
Jak vytvořit zprávu pro Apache Kafka?
S připraveným tématem Apache Kafka můžete nyní vytvořit svou první zprávu. Otevřete nový terminál nebo okno příkazového řádku nebo použijte stejné okno, které jste použili k vytvoření tématu. Dále se ujistěte, že jste ve správném adresáři, kam jste extrahovali obsah archivu. K vytvoření zprávy k tématu můžete použít příkazový řádek pomocí následujícího příkazu:
Pro uživatele Linuxu:
bin/kafka-console-producer.sh --topic transactions --bootstrap-server localhost:9092
Pro uživatele Windows:
bin/windows/kafka-console-producer.bat --topic transactions --bootstrap-server localhost:9092
Jakmile příkaz spustíte, uvidíte, že váš terminál nebo okno příkazového řádku čeká na vstup. Napište svou první zprávu a stiskněte Enter.
> This is a transactional record for $100
Na svém místním počítači jste vytvořili svou první zprávu pro Apache Kafka. Následně jste nyní připraveni tuto zprávu využít.
Jak zkonzumovat zprávu od Apache Kafka?
Pokud bylo vaše téma vytvořeno a vytvořili jste zprávu ke svému tématu Kafka, můžete tuto zprávu nyní použít.
Apache Kafka vám umožňuje připojit více spotřebitelů ke stejnému tématu. Každý spotřebitel může být součástí skupiny spotřebitelů – logický identifikátor. Pokud máte například dvě služby, které potřebují spotřebovávat stejná data, mohou mít různé skupiny spotřebitelů.
Pokud však máte dvě instance stejné služby, měli byste se vyhnout konzumaci a zpracování stejné zprávy dvakrát. V takovém případě budou mít oba stejnou skupinu spotřebitelů.
V okně terminálu nebo příkazového řádku se ujistěte, že jste ve správném adresáři. Ke spuštění spotřebitele použijte následující příkaz:
Pro uživatele Linuxu:
bin/kafka-console-consumer.sh --topic transactions --from-beginning --bootstrap-server localhost:9092 --group notif-consumer
Pro uživatele Windows:
bin/windows/kafka-console-consumer.bat --topic transactions --from-beginning --bootstrap-server localhost:9092 --group notif-consumer

Na vašem terminálu se zobrazí zpráva, kterou jste předtím vytvořili. Nyní jste použili Apache Kafka ke konzumaci své první zprávy.
Příkaz kafka-console-consumer přebírá mnoho předávaných argumentů. Podívejme se, co každý z nich znamená:
- Téma – zmiňuje téma, odkud budete konzumovat
- –from-beginning říká uživateli konzole, aby začal číst zprávy hned od první zprávy
- Váš server Apache Kafka je uveden prostřednictvím volby –bootstrap-server
- Kromě toho můžete uvést skupinu spotřebitelů předáním parametru –group
- Pokud parametr skupiny spotřebitelů chybí, je generován automaticky
Se spuštěným spotřebitelem konzoly můžete zkusit vytvářet nové zprávy. Uvidíte, že jsou všechny spotřebovány a zobrazí se ve vašem terminálu.
Nyní, když jste vytvořili své téma a úspěšně vytvořili a spotřebovali zprávy, pojďme to integrovat s aplikací Java.
Jak vytvořit výrobce a spotřebitele Apache Kafka pomocí Javy
Než začnete, ujistěte se, že máte na místním počítači nainstalovanou Java 8+. Apache Kafka poskytuje vlastní klientskou knihovnu, která vám umožní bezproblémové připojení. Pokud ke správě závislostí používáte Maven, přidejte do souboru pom.xml následující závislost
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.5.0</version>
</dependency>
Knihovnu si také můžete stáhnout z Úložiště Maven a přidejte jej do své třídy Java.
Jakmile je vaše knihovna na svém místě, otevřete editor kódu podle vašeho výběru. Podívejme se, jak můžete nastartovat svého výrobce a spotřebitele pomocí Javy.
Vytvořte Apache Kafka Java producenta
Se zavedenou knihovnou klientů kafka jste nyní připraveni začít vytvářet svého výrobce Kafka.
Vytvořme třídu s názvem SimpleProducer.java. To bude zodpovědné za vytváření zpráv na téma, které jste vytvořili dříve. Uvnitř této třídy vytvoříte instanci org.apache.kafka.clients.producer.KafkaProducer. Následně budete tohoto producenta používat k odesílání zpráv.
Pro vytvoření Kafka producenta potřebujete hostitele a port vašeho Apache Kafka serveru. Protože jej provozujete na místním počítači, hostitelem bude localhost. Vzhledem k tomu, že jste při spouštění serveru nezměnili výchozí vlastnosti, bude port 9092. Zvažte následující kód, který vám pomůže vytvořit vašeho producenta:
package org.example.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class SimpleProducer {
private final KafkaProducer<String, String> producer;
public SimpleProducer(String host, String port) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
this.producer = new KafkaProducer<>(properties);
}
}
Všimnete si, že se nastavují tři vlastnosti. Pojďme si rychle projít každou z nich:
- BOOTSTRAP_SERVERS_CONFIG vám umožňuje definovat, kde běží server Apache Kafka
- KEY_SERIALIZER_CLASS_CONFIG říká producentovi, jaký formát má použít pro odesílání klíčů zpráv.
- Formát pro odeslání skutečné zprávy je definován pomocí vlastnosti VALUE_SERIALIZER_CLASS_CONFIG.
Protože budete posílat textové zprávy, obě vlastnosti jsou nastaveny na použití StringSerializer.class.
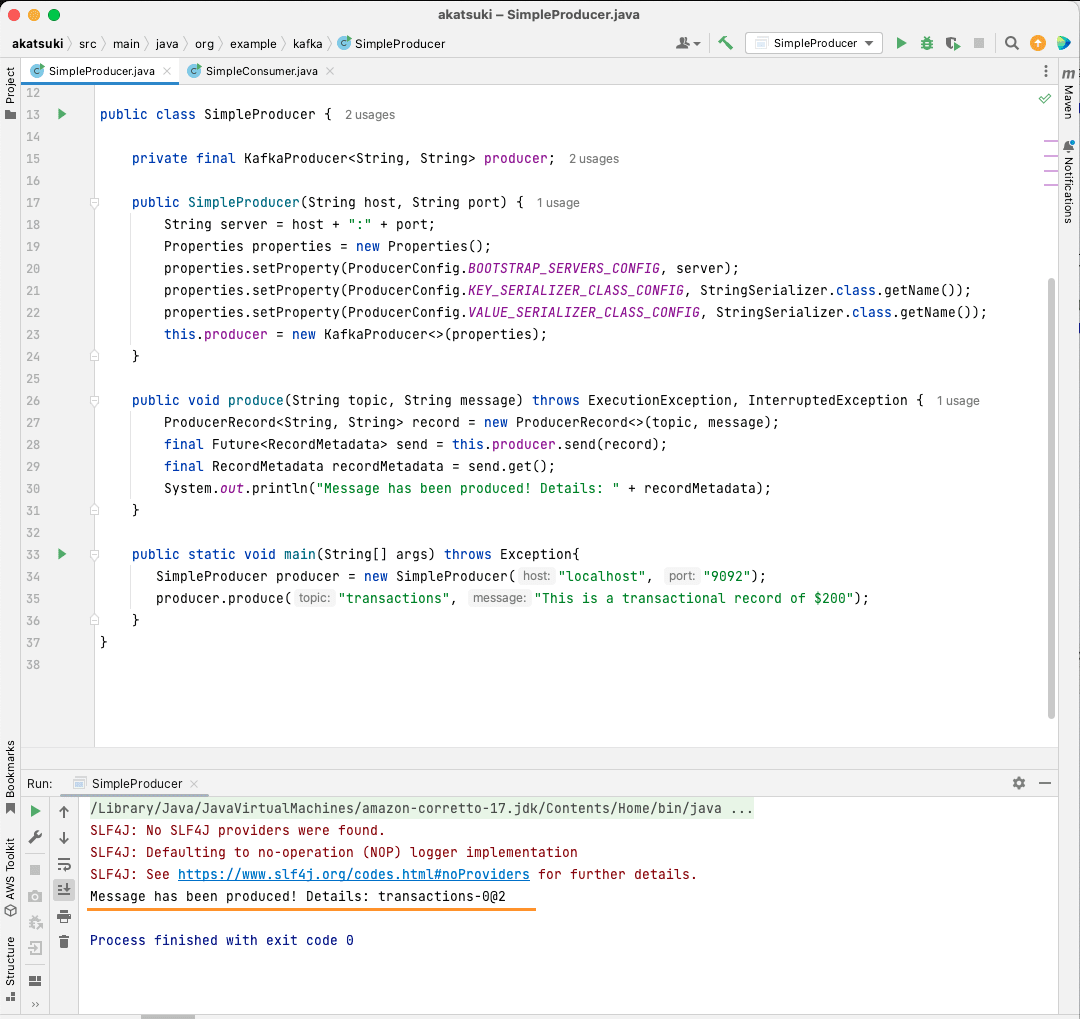
Abyste mohli skutečně odeslat zprávu vašemu tématu, musíte použít metodu producent.send(), která přijímá ProducerRecord. Následující kód vám poskytuje metodu, která odešle zprávu k tématu a vytiskne odpověď spolu s posunem zprávy.
public void produce(String topic, String message) throws ExecutionException, InterruptedException {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, message);
final Future<RecordMetadata> send = this.producer.send(record);
final RecordMetadata recordMetadata = send.get();
System.out.println(recordMetadata);
}
S celým kódem na svém místě nyní můžete posílat zprávy na vaše téma. K otestování můžete použít hlavní metodu, jak je uvedeno v kódu níže:
package org.example.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class SimpleProducer {
private final KafkaProducer<String, String> producer;
public SimpleProducer(String host, String port) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
this.producer = new KafkaProducer<>(properties);
}
public void produce(String topic, String message) throws ExecutionException, InterruptedException {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, message);
final Future<RecordMetadata> send = this.producer.send(record);
final RecordMetadata recordMetadata = send.get();
System.out.println(recordMetadata);
}
public static void main(String[] args) throws Exception{
SimpleProducer producer = new SimpleProducer("localhost", "9092");
producer.produce("transactions", "This is a transactional record of $200");
}
}
V tomto kódu vytváříte SimpleProducer, který se připojuje k vašemu serveru Apache Kafka na vašem místním počítači. Interně používá KafkaProducer k vytváření textových zpráv na vaše téma.
Vytvořte spotřebitele Apache Kafka Java
Je čas vytvořit spotřebitele Apache Kafka pomocí klienta Java. Vytvořte třídu s názvem SimpleConsumer.java. Dále pro tuto třídu vytvoříte konstruktor, který inicializuje org.apache.kafka.clients.consumer.KafkaConsumer. Pro vytvoření spotřebitele potřebujete hostitele a port, na kterém běží server Apache Kafka. Kromě toho potřebujete skupinu spotřebitelů a téma, ze kterého chcete konzumovat. Použijte níže uvedený fragment kódu:
package org.example.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicBoolean;
public class SimpleConsumer {
private static final String OFFSET_RESET = "earliest";
private final KafkaConsumer<String, String> consumer;
private boolean keepConsuming = true;
public SimpleConsumer(String host, String port, String consumerGroupId, String topic) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, consumerGroupId);
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, OFFSET_RESET);
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
this.consumer = new KafkaConsumer<>(properties);
this.consumer.subscribe(List.of(topic));
}
}
Podobně jako Producent Kafka i Spotřebitel Kafka přijímá objekt Vlastnosti. Podívejme se na všechny různé sady vlastností:
- BOOTSTRAP_SERVERS_CONFIG informuje spotřebitele, kde běží server Apache Kafka
- Skupina spotřebitelů je uvedena pomocí GROUP_ID_CONFIG
- Když spotřebitel začne přijímat zprávy, AUTO_OFFSET_RESET_CONFIG vám umožní zmínit, jak daleko zpět chcete začít přijímat zprávy od
- KEY_DESERIALIZER_CLASS_CONFIG informuje spotřebitele o typu klíče zprávy
- VALUE_DESERIALIZER_CLASS_CONFIG informuje typ spotřebitele o skutečné zprávě
Protože ve vašem případě budete konzumovat textové zprávy, jsou vlastnosti deserializeru nastaveny na StringDeserializer.class.
Nyní budete přijímat zprávy z vašeho tématu. Aby to bylo jednoduché, jakmile je zpráva spotřebována, vytisknete zprávu na konzoli. Podívejme se, jak toho můžete dosáhnout pomocí níže uvedeného kódu:
private boolean keepConsuming = true;
public void consume() {
while (keepConsuming) {
final ConsumerRecords<String, String> consumerRecords = this.consumer.poll(Duration.ofMillis(100L));
if (consumerRecords != null && !consumerRecords.isEmpty()) {
consumerRecords.iterator().forEachRemaining(consumerRecord -> {
System.out.println(consumerRecord.value());
});
}
}
}
Tento kód bude pokračovat v dotazování tématu. Když obdržíte jakýkoli spotřebitelský záznam, zpráva se vytiskne. Otestujte svého spotřebitele v akci pomocí hlavní metody. Spustíte Java aplikaci, která bude pokračovat v konzumaci tématu a tisku zpráv. Zastavte aplikaci Java a ukončete spotřebitele.
package org.example.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicBoolean;
public class SimpleConsumer {
private static final String OFFSET_RESET = "earliest";
private final KafkaConsumer<String, String> consumer;
private boolean keepConsuming = true;
public SimpleConsumer(String host, String port, String consumerGroupId, String topic) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, consumerGroupId);
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, OFFSET_RESET);
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
this.consumer = new KafkaConsumer<>(properties);
this.consumer.subscribe(List.of(topic));
}
public void consume() {
while (keepConsuming) {
final ConsumerRecords<String, String> consumerRecords = this.consumer.poll(Duration.ofMillis(100L));
if (consumerRecords != null && !consumerRecords.isEmpty()) {
consumerRecords.iterator().forEachRemaining(consumerRecord -> {
System.out.println(consumerRecord.value());
});
}
}
}
public static void main(String[] args) {
SimpleConsumer simpleConsumer = new SimpleConsumer("localhost", "9092", "transactions-consumer", "transactions");
simpleConsumer.consume();
}
}
Když kód spustíte, zjistíte, že nespotřebovává pouze zprávy vytvořené vaším producentem Java, ale také ty, které jste vytvořili prostřednictvím Console Producer. Důvodem je, že vlastnost AUTO_OFFSET_RESET_CONFIG byla nastavena na nejdříve.
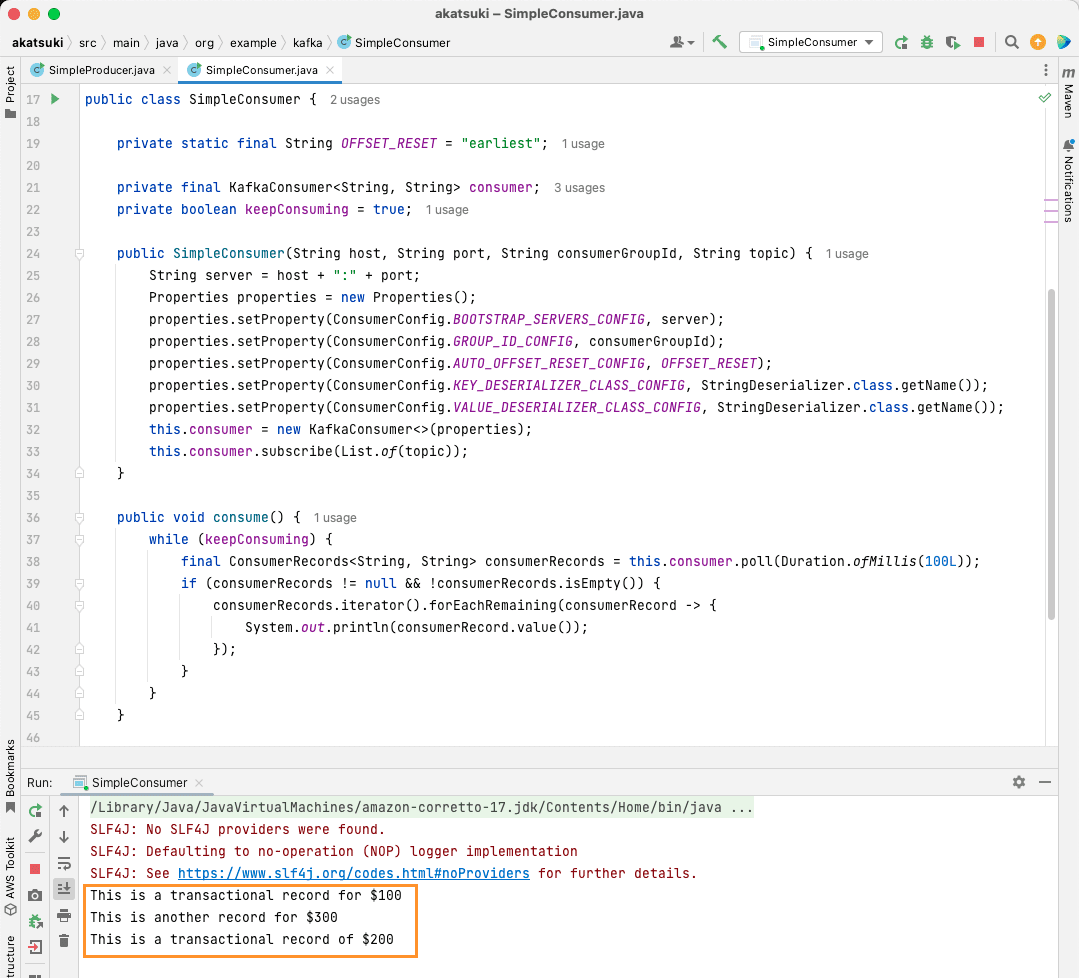
Se spuštěným SimpleConsumer můžete použít konzolového producenta nebo Java aplikaci SimpleProducer k vytváření dalších zpráv k tématu. Uvidíte, jak se spotřebovávají a tisknou na konzoli.
Splňte všechny své potřeby datového kanálu s Apache Kafka
Apache Kafka vám umožní snadno zvládnout všechny vaše požadavky na datový kanál. S nastavením Apache Kafka na místním počítači můžete prozkoumat všechny různé funkce, které Kafka poskytuje. Kromě toho vám oficiální Java klient umožňuje efektivně psát, připojovat se a komunikovat s vaším serverem Apache Kafka.
Apache Kafka je všestranný, škálovatelný a vysoce výkonný systém pro streamování dat a může pro vás skutečně změnit hru. Můžete jej použít pro svůj místní vývoj nebo jej dokonce integrovat do svých produkčních systémů. Stejně jako je snadné jej lokálně nastavit, není nastavení Apache Kafka pro větší aplikace žádný velký úkol.
Pokud hledáte platformy pro streamování dat, můžete se podívat na nejlepší platformy pro streamování dat pro analýzu a zpracování v reálném čase.