Python Threading: An Introduction – etechblog.cz
V tomto návodu se ponoříme do tajů multithreadingu v Pythonu s využitím vestavěného modulu pro práci s vlákny. Prozkoumáme, jak efektivně využít potenciál souběžného zpracování úloh.
Nejprve si ujasníme základní rozdíly mezi procesy a vlákny a následně si objasníme, jak multithreading funguje v Pythonu, včetně konceptů souběžnosti a paralelismu. Poté se naučíme vytvářet a spouštět vlákna pomocí vestavěného modulu.
Pojďme na to.
Procesy vs. Vlákna: Jaký je mezi nimi rozdíl?
Co je to proces?
Procesem rozumíme jakoukoliv spuštěnou instanci programu.
Může to být jakýkoli program – od skriptu v Pythonu, přes webový prohlížeč, jako je Chrome, až po aplikaci pro videohovory. Pokud otevřete Správce úloh a podíváte se na sekci Výkon –> CPU, uvidíte aktuálně běžící procesy a vlákna na vašem procesoru.
Rozumění procesům a vláknům
Proces má přidělenou paměť, kde se ukládá jeho kód a data.
Každý proces se skládá z jednoho nebo více vláken. Vlákno představuje nejmenší sekvenci instrukcí, kterou může operační systém provést, a definuje tok provádění.
Každé vlákno má svůj vlastní zásobník a registry, ale nesdílí vyhrazenou paměť. Všechna vlákna v rámci procesu mají přístup ke sdíleným datům. Data a paměť jsou tedy sdílené mezi všemi vlákny v rámci procesu.
Na procesoru s N jádry může N procesů běžet paralelně ve stejný okamžik. Dvě vlákna jednoho procesu však nemohou nikdy běžet paralelně, ale mohou se spouštět souběžně. Koncept souběžnosti a paralelismu si vysvětlíme v dalším kroku.
Shrňme si tedy rozdíly mezi procesem a vláknem.
| Vlastnost | Proces | Vlákno |
| Paměť | Vyhrazená paměť | Sdílená paměť |
| Režim provádění | Paralelní, souběžný | Souběžný; ale ne paralelní |
| Správa provádění | Operační systém | Interpret Pythonu CPython |
Multithreading v Pythonu
V Pythonu zajišťuje Global Interpreter Lock (GIL), že pouze jedno vlákno může získat zámek a běžet v daném okamžiku. Každé vlákno musí získat tento zámek pro svůj běh. To zajišťuje, že v jeden okamžik může běžet pouze jedno vlákno a zamezuje se paralelnímu multithreadingu.
Představme si dvě vlákna, t1 a t2, v rámci jednoho procesu. Protože vlákna sdílejí data, když t1 čte hodnotu k, může t2 tuto hodnotu upravit. To může vést k uváznutí a nežádoucím výsledkům. GIL ale zajišťuje, že v jednu chvíli běží pouze jedno vlákno, a taktéž zajišťuje bezpečnost vláken.
Jak tedy dosáhneme multithreadingu v Pythonu? Abychom tomu porozuměli, probereme koncepty souběžnosti a paralelismu.
Souběžnost vs. Paralelismus: Přehled
Představme si procesor s více jádry. Na obrázku níže má CPU čtyři jádra. To znamená, že můžeme mít paralelně spuštěné čtyři různé operace ve stejný okamžik.
Pokud máme čtyři procesy, pak každý z nich může běžet nezávisle a současně na jednotlivých jádrech. Předpokládejme, že každý proces má dvě vlákna.
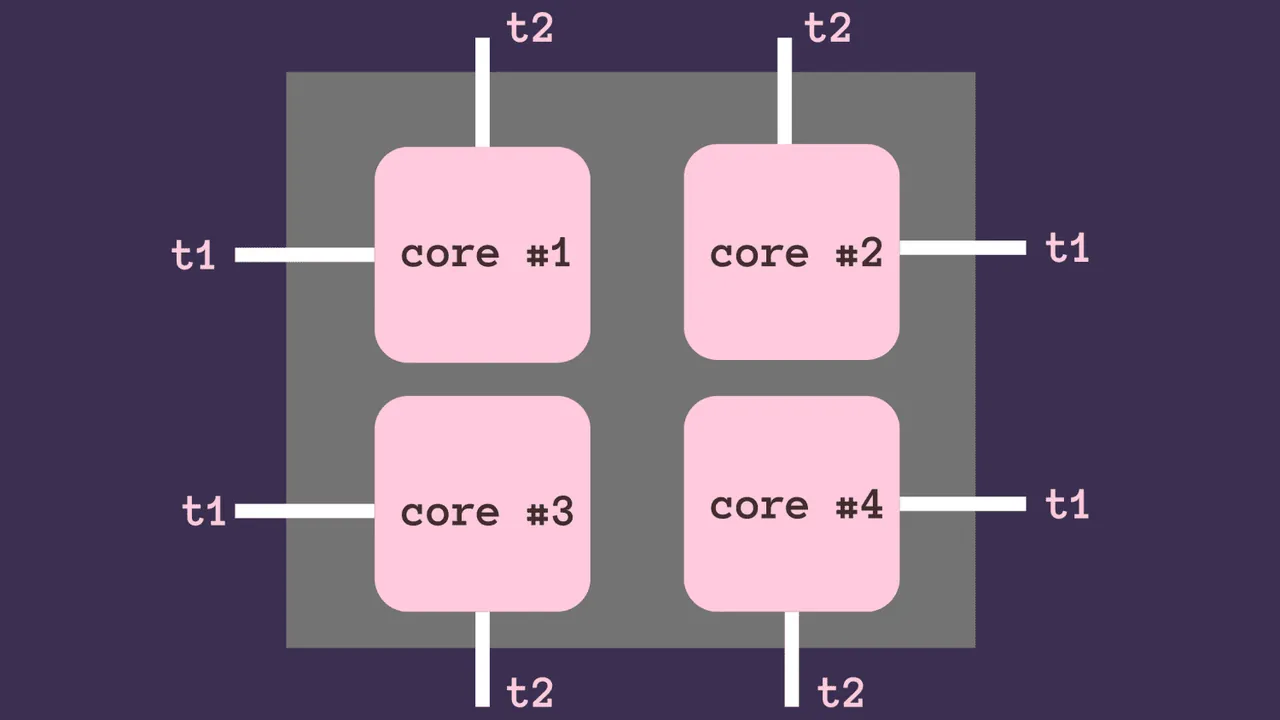
Abychom pochopili fungování vláken, přesuneme se z vícejádrové architektury na jednojádrovou. Jak jsme již zmínili, v konkrétní instanci může běžet pouze jedno vlákno; jádro procesoru však může přepínat mezi vlákny.
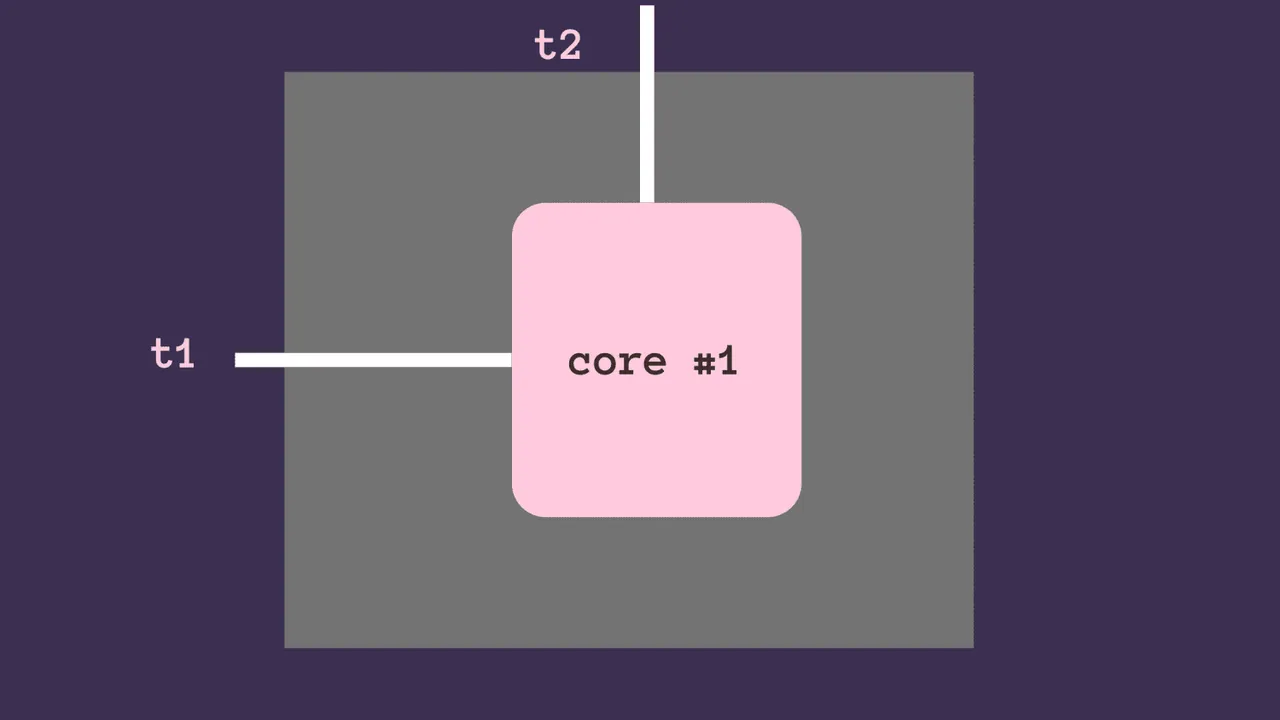
Například vlákna, která čekají na I/O operace (čtení vstupu od uživatele, čtení z databáze, práce se soubory), mohou během čekání uvolnit zámek, a tím umožnit běh jiného vlákna. Čekací doba může být také jednoduchá operace jako uspání na N sekund.
Shrnutí: Během čekání vlákno uvolní zámek a procesor může přepnout na jiné vlákno. Původní vlákno pokračuje v provádění po skončení čekací doby. Tento proces, kdy procesor přepíná mezi vlákny, umožňuje multithreading. ✅
Pokud chcete dosáhnout paralelismu na úrovni procesů, doporučujeme místo toho použít multiprocesing.
Modul Python Threading: První kroky
Python nabízí modul pro práci s vlákny, který lze importovat do vašeho skriptu.
import threading
Pro vytvoření objektu vlákna v Pythonu se používá konstruktor Thread: threading.Thread(…). Toto je základní syntaxe, která stačí pro většinu případů:
threading.Thread(target=...,args=...)
Kde:
- target je klíčový argument, který odkazuje na volanou funkci
- args je n-tice argumentů, které funkce target přebírá
Pro spuštění ukázek kódu v tomto tutoriálu budete potřebovat Python 3.x. Stáhněte si kód a postupujte podle něj.
Jak definovat a spustit vlákna v Pythonu
Nyní si definujeme vlákno, které spustí cílovou funkci.
Cílová funkce je some_func.
import threading
import time
def some_func():
print("Spouštím some_func...")
time.sleep(2)
print("some_func dokončena.")
thread1 = threading.Thread(target=some_func)
thread1.start()
print(threading.active_count())
Pojďme si rozebrat, co tento kód dělá:
- Importují se moduly threading a time.
- Funkce some_func obsahuje příkazy print() a operaci spánku na 2 sekundy: time.sleep(n) uspí funkci na n sekund.
- Vytvoříme vlákno thread_1 s cílem some_func. threading.Thread(target=…) vytvoří objekt vlákna.
- Důležité: Předává se název funkce, nikoliv volání funkce; použijte tedy some_func a ne some_func().
- Vytvoření objektu vlákna jej nespustí, k tomu slouží metoda start() objektu.
- Funkce active_count() vrátí počet aktivních vláken.
Skript v Pythonu běží na hlavním vlákně a my jsme vytvořili další vlákno (thread1) pro spuštění funkce some_func, takže počet aktivních vláken jsou dvě, jak je vidět ve výstupu:
# Výstup Spouštím some_func... 2 some_func dokončena.
Při bližším pohledu na výstup vidíme, že po spuštění vlákna1 se spustí první print příkaz. Nicméně během operace spánku procesor přepne na hlavní vlákno a vypíše počet aktivních vláken – bez čekání, než vlákno 1 dokončí své provádění.
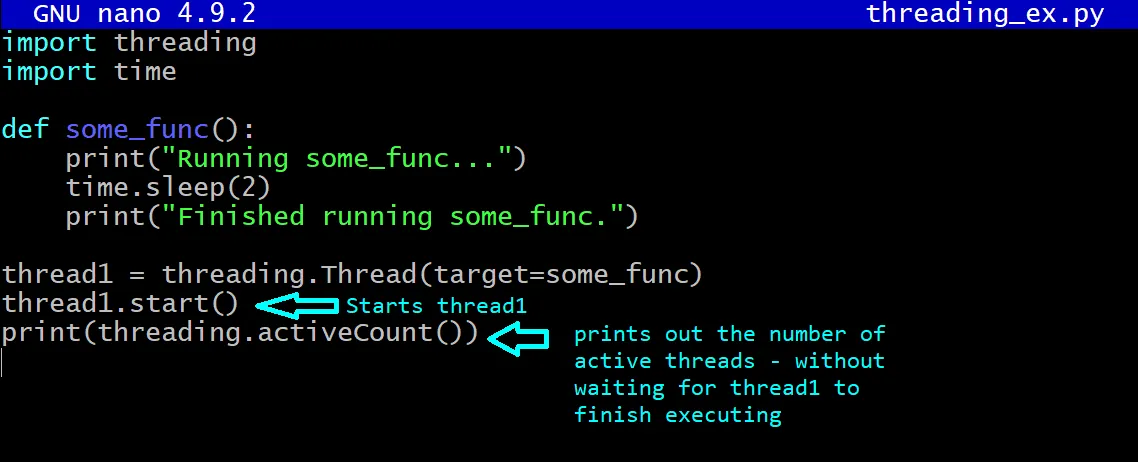
Čekání na dokončení vláken
Pokud chcete, aby vlákno1 dokončilo provádění, můžete na něm po spuštění vlákna zavolat metodu join(). Tím se zajistí, že program počká, až vlákno1 dokončí provádění, než se přepne na hlavní vlákno.
import threading
import time
def some_func():
print("Spouštím some_func...")
time.sleep(2)
print("some_func dokončena.")
thread1 = threading.Thread(target=some_func)
thread1.start()
thread1.join()
print(threading.active_count())
Nyní vlákno1 dokončí provádění před tím, než vypíšeme počet aktivních vláken. To znamená, že běží pouze hlavní vlákno, takže počet aktivních vláken je jedna. ✅
# Výstup Spouštím some_func... some_func dokončena. 1
Jak spustit více vláken v Pythonu
Nyní vytvoříme dvě vlákna pro spuštění dvou odlišných funkcí.
count_down je funkce, která bere číslo jako argument a odpočítává od tohoto čísla k nule.
def count_down(n):
for i in range(n,-1,-1):
print(i)
Definujeme count_up, další funkci v Pythonu, která počítá od nuly po dané číslo.
def count_up(n):
for i in range(n+1):
print(i)
📑 Při použití funkce range() s rozsahem syntaxe (start, stop, step) je koncový bod ve výchozím nastavení vyloučen.
– Pro odpočítávání od čísla k nule se použije záporná hodnota kroku -1 a koncovou hodnotou bude -1, aby se zahrnula nula.
– Podobně, pro počítání do n, musí být koncová hodnota n+1. Jelikož výchozí hodnoty start a step jsou 0 a 1, lze použít range(n+1) pro získání sekvence od 0 do n.
Nyní definujeme dvě vlákna, thread1 a thread2, pro spuštění funkcí count_down a count_up. Pro obě funkce přidáme tiskové příkazy a operaci spánku.
Při vytváření objektů vláken si všimněte, že argumenty cílové funkce musí být specifikovány jako n-tice – parametrem args. Obě funkce (count_down a count_up) mají jeden argument, proto musí být za hodnotou explicitně čárka. To zajistí, že argument bude předán jako n-tice, jinak by byl považován za None.
import threading
import time
def count_down(n):
for i in range(n,-1,-1):
print("Spouštím thread1....")
print(i)
time.sleep(1)
def count_up(n):
for i in range(n+1):
print("Spouštím thread2...")
print(i)
time.sleep(1)
thread1 = threading.Thread(target=count_down,args=(10,))
thread2 = threading.Thread(target=count_up,args=(5,))
thread1.start()
thread2.start()
Výstup:
- Funkce count_up běží na thread2 a počítá do 5 začínajíc 0.
- Funkce count_down běží na thread1 a odpočítává od 10 do 0.
# Výstup Spouštím thread1.... 10 Spouštím thread2... 0 Spouštím thread1.... 9 Spouštím thread2... 1 Spouštím thread1.... 8 Spouštím thread2... 2 Spouštím thread1.... 7 Spouštím thread2... 3 Spouštím thread1.... 6 Spouštím thread2... 4 Spouštím thread1.... 5 Spouštím thread2... 5 Spouštím thread1.... 4 Spouštím thread1.... 3 Spouštím thread1.... 2 Spouštím thread1.... 1 Spouštím thread1.... 0
Vidíme, že thread1 a thread2 se střídají ve spouštění, protože obě obsahují operaci čekání (sleep). Jakmile funkce count_up dopočítá do 5, thread2 již není aktivní. Proto získáme výstup pouze od thread1.
Shrnutí
V tomto návodu jste se naučili, jak používat vestavěný modul threading v Pythonu pro implementaci multithreadingu. Zde je shrnutí hlavních poznatků:
- Konstruktor vlákna se používá pro vytvoření objektu vlákna. Pomocí threading.Thread(target=<callable>,args=(<ntice argumentů>))) se vytvoří vlákno, které spustí cílovou funkci s argumenty uvedenými v args.
- Program v Pythonu běží v hlavním vlákně, takže objekty vláken, které vytvoříte, jsou další vlákna. Funkce active_count() vrátí počet aktivních vláken v jakémkoliv okamžiku.
- Vlákno se spouští pomocí metody start() objektu vlákna a čeká se na dokončení jeho provádění pomocí metody join().
Můžete si vyzkoušet další příklady s různými čekacími dobami a I/O operacemi. Nezapomeňte implementovat multithreading ve svých budoucích projektech v Pythonu. Přejeme vám zábavné kódování! 🎉
