
V tomto tutoriálu se naučíte, jak používat vestavěný modul pro vytváření vláken v Pythonu k prozkoumání možností multithreadingu v Pythonu.
Počínaje základy procesů a vláken se naučíte, jak funguje multithreading v Pythonu – a zároveň pochopíte koncepty souběžnosti a paralelismu. Poté se naučíte, jak spustit a spustit jedno nebo více vláken v Pythonu pomocí vestavěného modulu vláken.
Začněme.
Table of Contents
Procesy vs. vlákna: Jaké jsou rozdíly?
Co je to proces?
Proces je jakákoli instance programu, která musí být spuštěna.
Může to být cokoliv – skript Python nebo webový prohlížeč, jako je Chrome, až po aplikaci pro videokonference. Pokud na svém počítači spustíte Správce úloh a přejdete na Výkon –> CPU, budete moci vidět procesy a vlákna, která aktuálně běží na vašich jádrech CPU.
Pochopení procesů a vláken
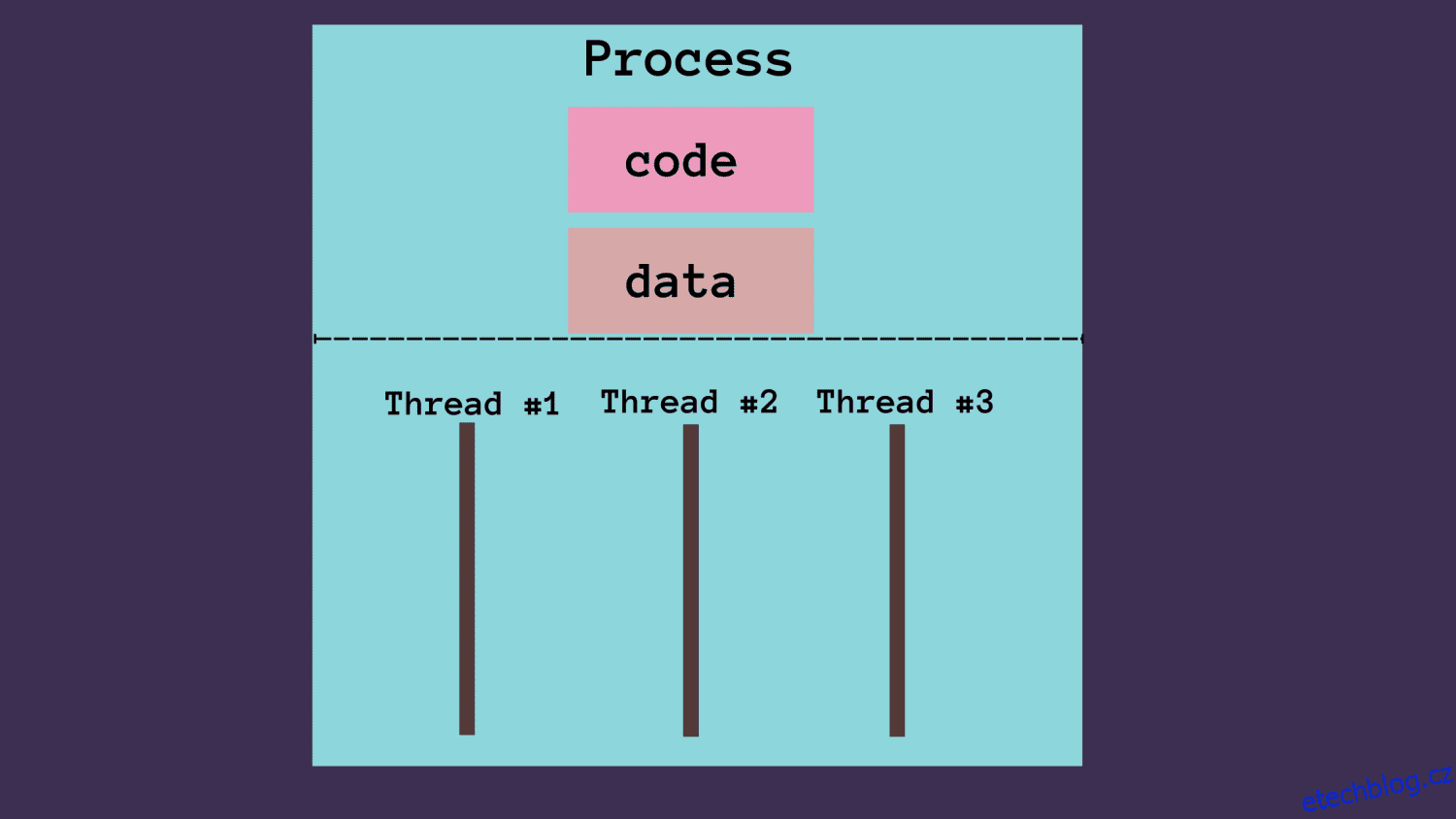
Interně má proces vyhrazenou paměť, která ukládá kód a data odpovídající procesu.
Proces se skládá z jednoho nebo více vláken. Vlákno je nejmenší posloupnost instrukcí, kterou může operační systém provést, a představuje tok provádění.
Každé vlákno má svůj vlastní zásobník a registry, ale ne vyhrazenou paměť. K datům mají přístup všechna vlákna spojená s procesem. Data a paměť jsou tedy sdíleny všemi vlákny procesu.
V CPU s N jádry může N procesů probíhat paralelně ve stejnou dobu. Dvě vlákna stejného procesu se však nikdy nemohou spustit paralelně, ale mohou se spouštět souběžně. Konceptu souběžnosti vs. paralelismu se budeme věnovat v další části.
Na základě toho, co jsme se zatím naučili, shrňme rozdíly mezi procesem a vláknem.
FeatureProcessThreadMemoryVyhrazená paměťSdílená paměťRežim prováděníParallel, concurrentConcurrent; ale ne parallelExecution zpracovávaný Operating SystemCPython Interpreter
Multithreading v Pythonu
V Pythonu zajišťuje Global Interpreter Lock (GIL) to, že pouze jedno vlákno může získat zámek a spustit jej v libovolném okamžiku. Všechna vlákna by měla získat tento zámek, aby mohla být spuštěna. Tím je zajištěno, že může být spuštěno pouze jedno vlákno – v jakémkoli daném okamžiku – a zamezuje se současnému vícevláknovému zpracování.
Uvažujme například dvě vlákna, t1 a t2, stejného procesu. Protože vlákna sdílejí stejná data, když t1 čte určitou hodnotu k, může t2 modifikovat stejnou hodnotu k. To může vést k uváznutí a nežádoucím výsledkům. Ale pouze jedno z vláken může získat zámek a spustit v jakékoli instanci. Proto GIL také zajišťuje bezpečnost závitů.
Jak tedy dosáhneme schopností multithreadingu v Pythonu? Abychom tomu porozuměli, pojďme diskutovat o konceptech souběžnosti a paralelismu.
Souběžnost vs. Paralelismus: Přehled
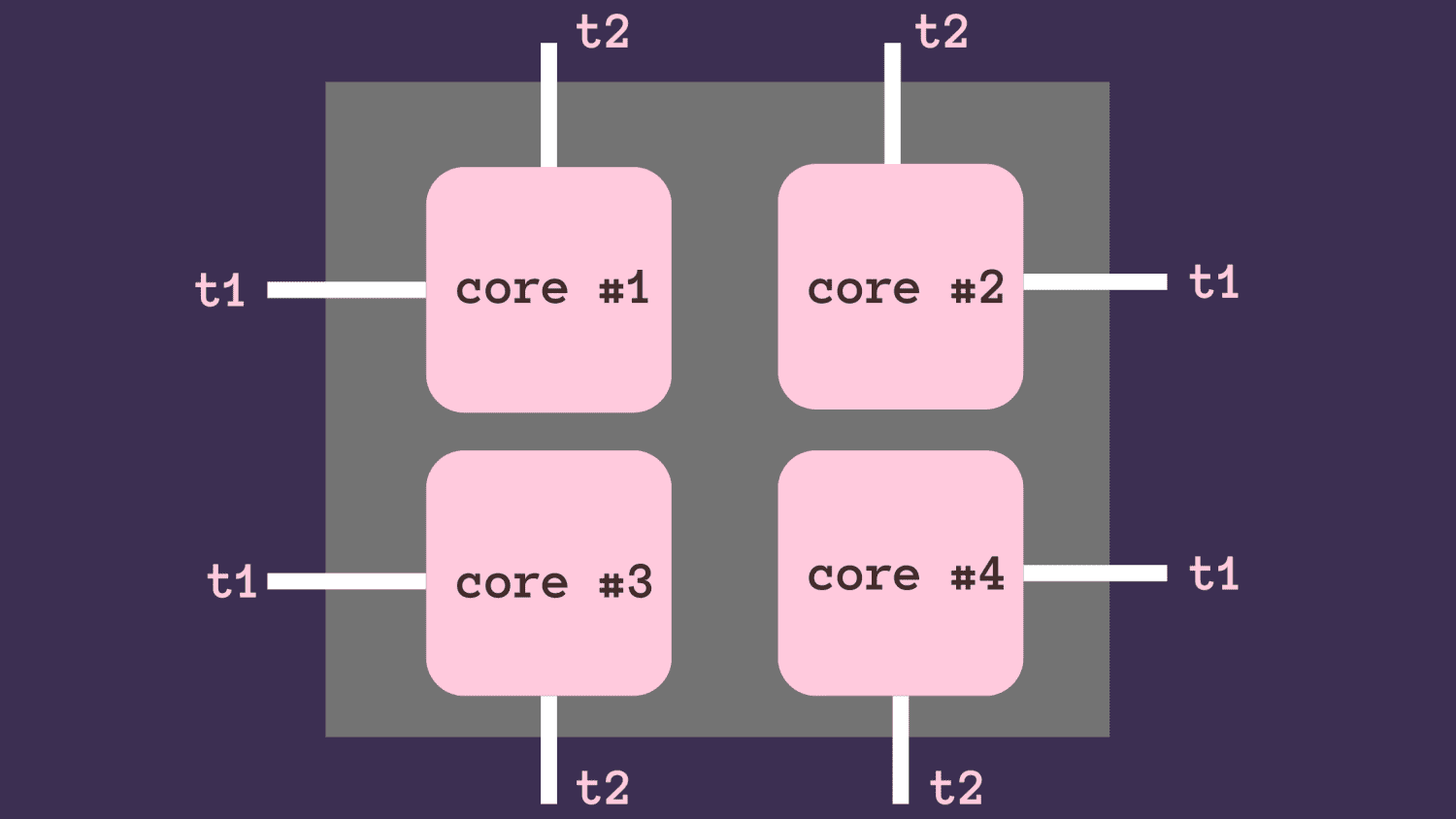
Zvažte CPU s více než jedním jádrem. Na obrázku níže má CPU čtyři jádra. To znamená, že v kterémkoli daném okamžiku můžeme mít paralelně čtyři různé operace.
Pokud existují čtyři procesy, pak každý z procesů může běžet nezávisle a současně na každém ze čtyř jader. Předpokládejme, že každý proces má dvě vlákna.
Abychom pochopili, jak vlákno funguje, přejděme z vícejádrové na jednojádrovou architekturu procesoru. Jak bylo zmíněno, v konkrétní instanci spuštění může být aktivní pouze jedno vlákno; ale jádro procesoru umí přepínat mezi vlákny.
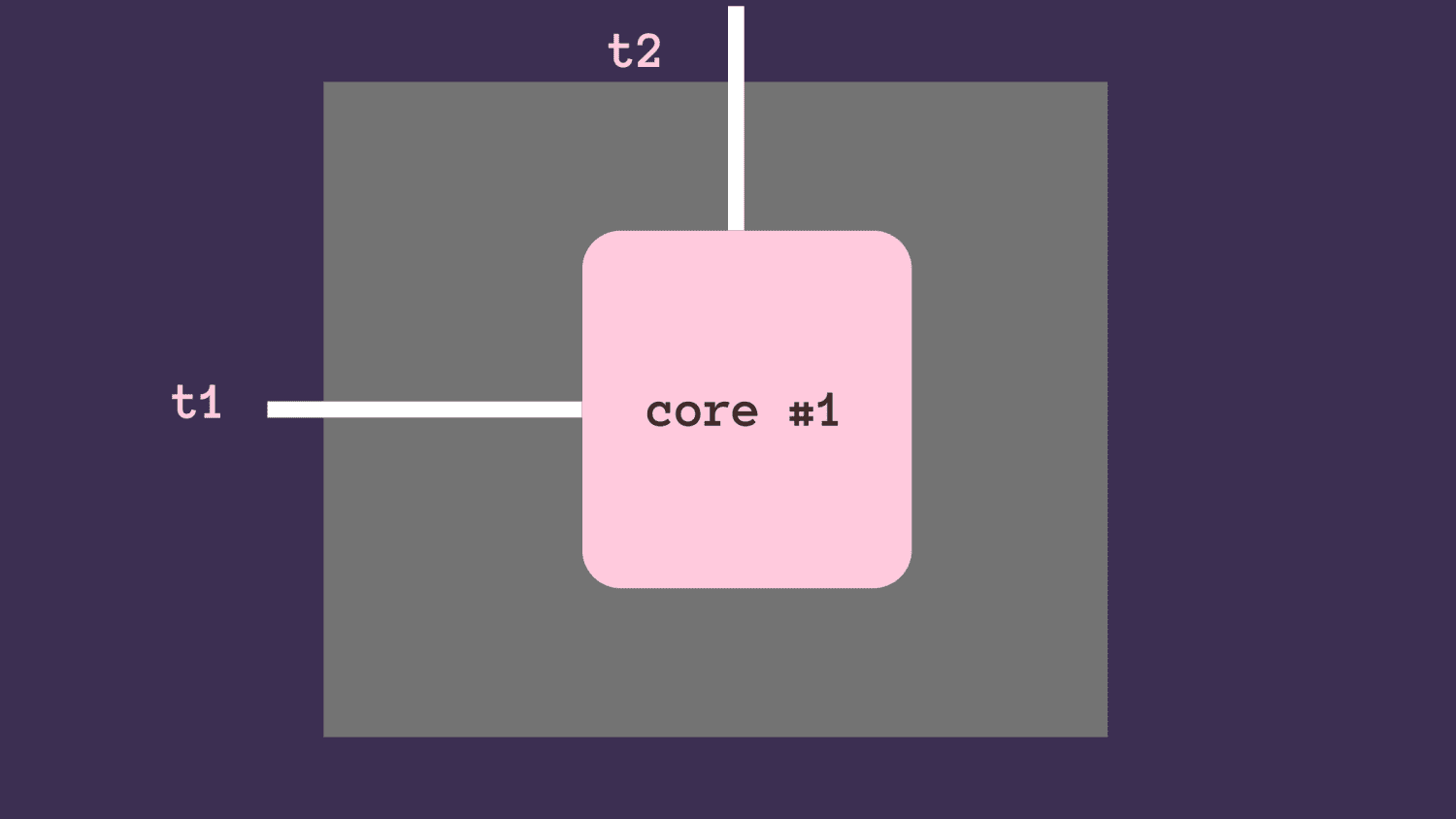
Například vlákna vázaná na I/O často čekají na I/O operace: čtení uživatelského vstupu, čtení databáze a operace se soubory. Během této čekací doby může uvolnit zámek, aby mohlo běžet druhé vlákno. Čekací doba může být také jednoduchá operace, jako je spánek na n sekund.
Shrnutí: Během operací čekání vlákno uvolní zámek a umožní jádru procesoru přepnout na jiné vlákno. Dřívější vlákno obnoví provádění po dokončení čekací doby. Tento proces, kdy jádro procesoru přepíná mezi vlákny souběžně, usnadňuje multithreading. ✅
Pokud chcete ve své aplikaci implementovat paralelismus na úrovni procesu, zvažte místo toho použití multiprocesingu.
Python Threading Module: První kroky
Python se dodává s modulem vláken, který můžete importovat do skriptu Python.
import threading
Chcete-li vytvořit objekt vlákna v Pythonu, můžete použít konstruktor Thread: threading.Thread(…). Toto je obecná syntaxe, která postačuje pro většinu implementací vláken:
threading.Thread(target=...,args=...)
Tady,
- target je argument klíčového slova označující volání v Pythonu
- args je n-tice argumentů, které cíl přebírá.
Ke spuštění příkladů kódu v tomto tutoriálu budete potřebovat Python 3.x. Stáhněte si kód a postupujte podle něj.
Jak definovat a spouštět vlákna v Pythonu
Pojďme definovat vlákno, které spouští cílovou funkci.
Cílová funkce je some_func.
import threading
import time
def some_func():
print("Running some_func...")
time.sleep(2)
print("Finished running some_func.")
thread1 = threading.Thread(target=some_func)
thread1.start()
print(threading.active_count())
Pojďme analyzovat, co dělá výše uvedený fragment kódu:
- Importuje moduly vláken a času.
- Funkce some_func má popisné příkazy print() a zahrnuje operaci spánku na dvě sekundy: time.sleep(n) způsobí, že funkce uspí na n sekund.
- Dále definujeme vlákno thread_1 s cílem jako some_func. threading.Thread(target=…) vytvoří objekt vlákna.
- Poznámka: Zadejte název funkce a ne volání funkce; použijte some_func a ne some_func().
- Vytvoření objektu vlákna nespustí vlákno; volání metody start() na objekt vlákna ano.
- K získání počtu aktivních vláken použijeme funkci active_count().
Skript Python běží na hlavním vlákně a my vytváříme další vlákno (thread1) pro spuštění funkce some_func, takže počet aktivních vláken je dva, jak je vidět na výstupu:
# Output Running some_func... 2 Finished running some_func.
Pokud se blíže podíváme na výstup, uvidíme, že po spuštění vlákna1 se spustí první příkaz print. Ale během operace spánku se procesor přepne na hlavní vlákno a vytiskne počet aktivních vláken – aniž by čekal, až vlákno 1 dokončí své provádění.
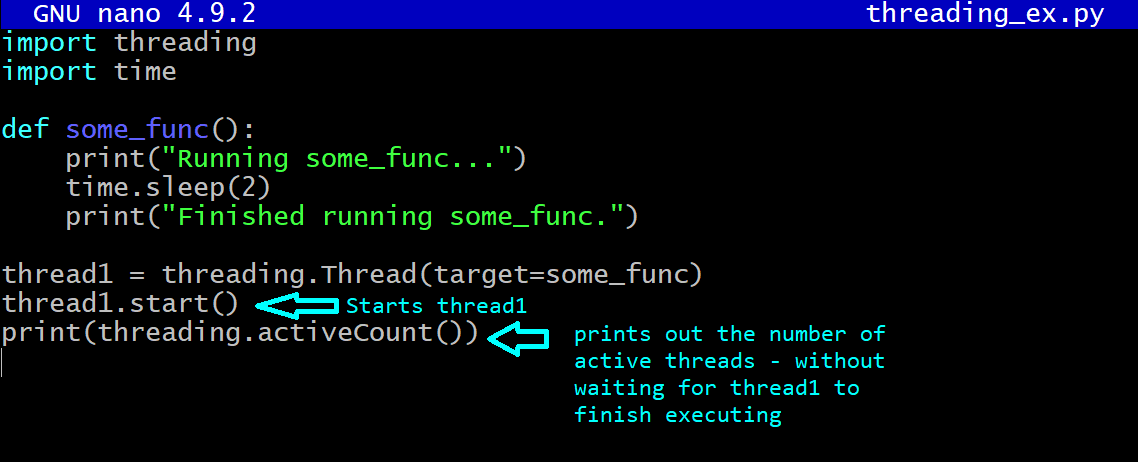
Čekání na dokončení zpracování vláken
Pokud chcete, aby vlákno1 dokončilo provádění, můžete na něm po spuštění vlákna zavolat metodu join(). Pokud tak učiníte, počká se, až vlákno1 dokončí provádění, aniž by se přepnulo na hlavní vlákno.
import threading
import time
def some_func():
print("Running some_func...")
time.sleep(2)
print("Finished running some_func.")
thread1 = threading.Thread(target=some_func)
thread1.start()
thread1.join()
print(threading.active_count())
Nyní vlákno1 dokončilo provádění, než vytiskneme počet aktivních vláken. Takže běží pouze hlavní vlákno, což znamená, že počet aktivních vláken je jedna. ✅
# Output Running some_func... Finished running some_func. 1
Jak spustit více vláken v Pythonu
Dále vytvoříme dvě vlákna pro spuštění dvou různých funkcí.
Count_down je zde funkce, která bere jako argument číslo a odpočítává od tohoto čísla k nule.
def count_down(n):
for i in range(n,-1,-1):
print(i)
Definujeme count_up, další funkci Pythonu, která počítá od nuly do daného čísla.
def count_up(n):
for i in range(n+1):
print(i)
📑 Při použití funkce range() s rozsahem syntaxe (start, stop, step) je koncový bod ve výchozím nastavení vyloučen.
– Chcete-li odpočítávat od určitého čísla k nule, můžete použít zápornou hodnotu kroku -1 a nastavit koncovou hodnotu na -1, aby byla zahrnuta nula.
– Podobně, abyste mohli počítat do n, musíte nastavit koncovou hodnotu na n + 1. Protože výchozí hodnoty start a krok jsou 0 a 1, můžete použít range(n + 1) k získání sekvence 0 přes n.
Dále definujeme dvě vlákna, vlákno1 a vlákno2 pro spouštění funkcí count_down a count_up. Pro obě funkce přidáváme tiskové příkazy a operace spánku.
Při vytváření objektů vláken si všimněte, že argumenty cílové funkce by měly být zadány jako n-tice – do parametru args. Protože obě funkce (count_down a count_up) mají jeden argument. Za hodnotu budete muset explicitně vložit čárku. To zajistí, že argument bude stále předán jako n-tice, protože následující prvky jsou odvozeny jako Žádné.
import threading
import time
def count_down(n):
for i in range(n,-1,-1):
print("Running thread1....")
print(i)
time.sleep(1)
def count_up(n):
for i in range(n+1):
print("Running thread2...")
print(i)
time.sleep(1)
thread1 = threading.Thread(target=count_down,args=(10,))
thread2 = threading.Thread(target=count_up,args=(5,))
thread1.start()
thread2.start()
Na výstupu:
- Funkce count_up běží na vláknu2 a počítá až do 5 počínaje 0.
- Funkce count_down běží na vlákně1 odpočítávání od 10 do 0.
# Output Running thread1.... 10 Running thread2... 0 Running thread1.... 9 Running thread2... 1 Running thread1.... 8 Running thread2... 2 Running thread1.... 7 Running thread2... 3 Running thread1.... 6 Running thread2... 4 Running thread1.... 5 Running thread2... 5 Running thread1.... 4 Running thread1.... 3 Running thread1.... 2 Running thread1.... 1 Running thread1.... 0
Můžete vidět, že vlákno1 a vlákno2 se spouštějí střídavě, protože oba zahrnují operaci čekání (uspání). Jakmile funkce count_up dokončí počítání do 5, vlákno 2 již není aktivní. Dostaneme tedy výstup odpovídající pouze vláknu1.
Shrnutí
V tomto tutoriálu jste se naučili, jak používat vestavěný modul pro vytváření vláken v Pythonu k implementaci multithreadingu. Zde je souhrn nejdůležitějších poznatků:
- Konstruktor vlákna lze použít k vytvoření objektu vlákna. Pomocí threading.Thread(target=
,args=( ))) vytvoří vlákno, které spustí cílový volatelný s argumenty zadanými v args. - Program Python běží na hlavním vlákně, takže objekty vlákna, které vytvoříte, jsou další vlákna. Můžete zavolat funkci active_count(), která vrátí počet aktivních vláken v jakékoli instanci.
- Vlákno můžete spustit pomocí metody start() na objektu vlákna a počkat, až dokončí provádění pomocí metody join().
Můžete kódovat další příklady vyladěním čekacích dob, pokusem o jinou I/O operaci a dalšími. Ujistěte se, že implementujete multithreading ve svých nadcházejících projektech Pythonu. Veselé kódování!🎉