

Web scraping vám umožňuje efektivně shromažďovat velké množství dat z internetu velmi rychlým způsobem a je zvláště užitečný v případech, kdy webové stránky nevystavují svá data strukturovaným způsobem pomocí rozhraní API (Application Programming Interfaces).
Představte si například, že vytváříte aplikaci, která porovnává ceny položek na stránkách elektronického obchodu. Jak byste na to šli? Jedním ze způsobů je ručně zkontrolovat cenu položek na všech stránkách a zaznamenat svá zjištění. To však není chytrý způsob, protože na platformách elektronického obchodu existují tisíce produktů a extrahování relevantních dat by vám trvalo věčnost.
Lepší způsob, jak toho dosáhnout, je sešrotování webu. Web scraping je proces automatického získávání dat z webových stránek a webů pomocí softwaru.
Softwarové skripty, označované jako webové škrabky, se používají k přístupu na webové stránky a získávání dat z webových stránek. Získaná data, obvykle v nestrukturované podobě, lze poté analyzovat a uložit strukturovaným způsobem, který je pro uživatele smysluplný.
Web scraping je velmi cenný při extrakci dat, protože poskytuje přístup k velkému množství dat a umožňuje automatizaci, takže můžete naplánovat spuštění skriptu pro web scraping v určitou dobu nebo v reakci na určité spouštěče. Web scraping vám také umožňuje získávat aktualizace v reálném čase a usnadňuje provádění průzkumu trhu.

Mnoho podniků a společností se při získávání dat pro analýzu spoléhá na web scraping. Společnosti specializující se na lidské zdroje, elektronický obchod, finance, nemovitosti, cestování, sociální média a výzkum používají web scraping k extrakci relevantních dat z webových stránek.
Samotný Google používá web scraping k indexování webových stránek na internetu, aby mohl uživatelům poskytovat relevantní výsledky vyhledávání.
Při odstraňování webu je však důležité dbát opatrnosti. Přestože šrotování veřejně přístupných dat není nezákonné, některé weby šrotování neumožňují. Může to být způsobeno tím, že mají citlivé informace o uživatelích, jejich smluvní podmínky výslovně zakazují šrotování webu nebo chrání duševní vlastnictví.
Některé weby navíc neumožňují škrábání webu, protože může přetížit server webu a vést ke zvýšeným nákladům na šířku pásma, zvláště když se škrábání webu provádí ve velkém.
Chcete-li zkontrolovat, zda lze web zrušit, připojte k adrese URL webu soubor robots.txt. robots.txt se používá k označení robotů, které části webu lze smazat. Chcete-li například zkontrolovat, zda můžete Google seškrábat, přejděte na adresu google.com/robots.txt
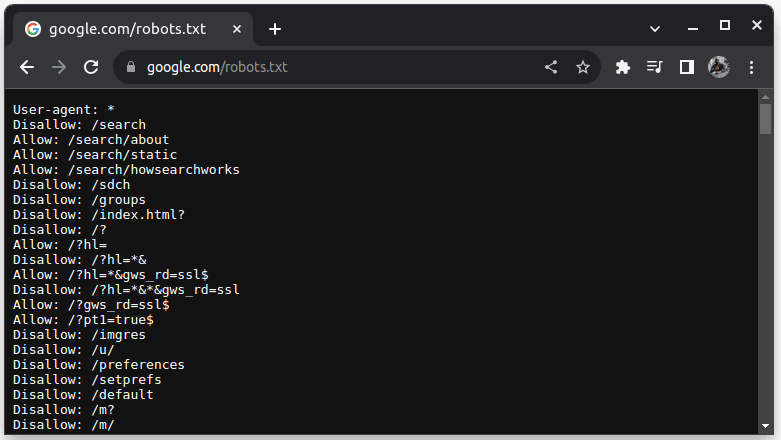
User-agent: * označuje všechny roboty nebo softwarové skripty a prohledávače. Disallow se používá k tomu, aby robotům řekl, že nemají přístup k žádné adrese URL v adresáři, například /search. Povolit označuje adresáře, odkud mohou přistupovat k URL.
Příkladem webu, který neumožňuje scraping, je LinkedIn. Chcete-li zkontrolovat, zda můžete LinkedIn odstranit, přejděte na adresu linkedin.com/robots.txt
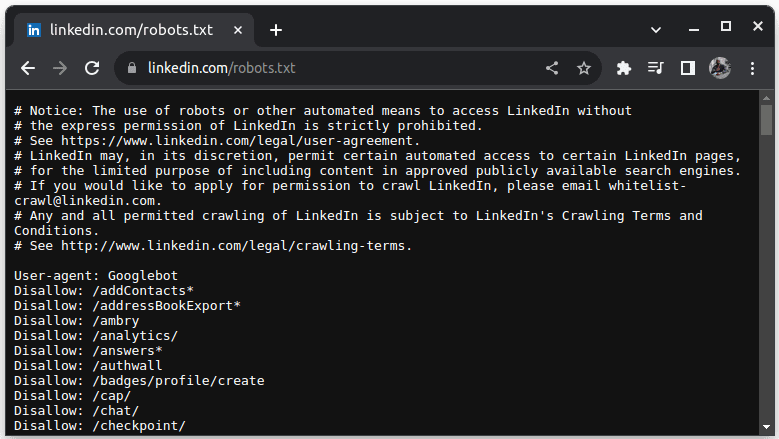
Jak vidíte, nemáte dovoleno škrábat LinkedIn bez jejich svolení. Vždy zkontrolujte, zda web umožňuje scraping, abyste se vyhnuli právním problémům.
Table of Contents
Proč je Java vhodným jazykem pro škrábání webu
Zatímco webovou škrabku můžete vytvořit pomocí různých programovacích jazyků, Java je pro tuto práci obzvláště ideální z mnoha důvodů. Za prvé, Java má bohatý ekosystém a rozsáhlou komunitu a poskytuje řadu webových scraping knihoven, jako jsou JSoup, WebMagic a HTMLUnit, které usnadňují psaní webových scraperů.

Poskytuje také knihovny HTML Parsing Libraries pro zjednodušení procesu extrahování dat z dokumentů HTML a síťových knihoven, jako je HttpURLConnection, pro vytváření požadavků na různé adresy URL webových stránek.
Silná podpora souběžnosti a multithreadingu v Javě je také prospěšná při odstraňování webových stránek, protože umožňuje paralelní zpracování a zpracování úloh webového scrapingu s více požadavky, což vám umožňuje seškrabovat více stránek současně. Vzhledem k tomu, že škálovatelnost je klíčovou silou Javy, můžete pohodlně odstraňovat webové stránky v masivním měřítku pomocí webového škrabáku napsaného v Javě.
Podpora mezi platformami Java se také hodí, protože vám umožňuje napsat webový škrabák a spustit jej v jakémkoli systému, který má kompatibilní Java Virtual Machine. Proto můžete napsat webovou škrabku v jednom operačním systému nebo zařízení a spustit ji v jiném operačním systému, aniž byste museli webovou škrabku upravovat.
Java lze také používat s bezhlavými prohlížeči, jako jsou mimo jiné Headless Chrome, HTML Unit, Headless Firefox a PhantomJs. Bezhlavý prohlížeč je prohlížeč bez grafického uživatelského rozhraní. Bezhlavé prohlížeče dokážou simulovat uživatelské interakce a jsou velmi užitečné při scrapingu webových stránek, které vyžadují interakci uživatele.
Abychom to shrnuli, Java je velmi oblíbený a široce používaný jazyk, který je podporován a lze jej snadno integrovat s řadou nástrojů, jako jsou databáze a rámce pro zpracování dat. To je výhodné, protože to zajišťuje, že když stahujete data, všechny nástroje, které budete potřebovat pro seškrabování, zpracování a ukládání dat, pravděpodobně podporují Javu.
Podívejme se, jak můžeme použít Java pro šrotování webu.
Java pro Web Scraping: Předpoklady
Chcete-li používat Java ve webovém scrapingu, měly by být splněny následující předpoklady:
1. Java – měli byste mít nainstalovanou Javu, nejlépe nejnovější verzi dlouhodobé podpory. V případě, že nemáte nainstalovanou Javu, přejděte k instalaci Javy a zjistěte, jak nainstalovat Javu do vašeho počítače
2. Integrované vývojové prostředí (IDE) – Na vašem počítači byste měli mít nainstalované IDE. V tomto tutoriálu použijeme IntelliJ IDEA, ale můžete použít jakékoli IDE, které znáte.
3. Maven – bude použit pro správu závislostí a instalaci webové knihovny scraping.
V případě, že nemáte nainstalovaný Maven, můžete jej nainstalovat otevřením terminálu a provedením:
sudo apt install maven
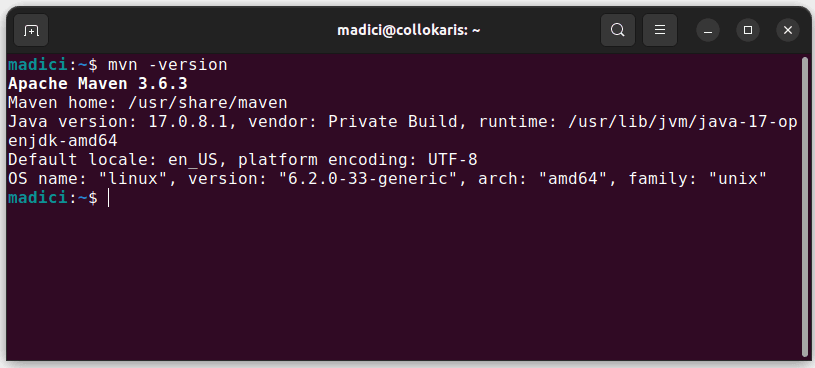
Tím se nainstaluje Maven z oficiálního úložiště. Můžete potvrdit, že Maven byl úspěšně nainstalován, provedením:
mvn -version
V případě, že instalace proběhla úspěšně, měli byste získat takový výstup:
Nastavení prostředí
Nastavení prostředí:
1. Otevřete IntelliJ IDEA. Na levém panelu nabídek klikněte na Projekty a poté vyberte Nový projekt.
2. V okně Nový projekt, které se otevře, jej vyplňte, jak je znázorněno níže. Ujistěte se, že je jazyk nastaven na Java a Build System na Maven. Projektu můžete dát libovolný název a poté pomocí Umístění určit složku, ve které chcete projekt vytvořit. Po dokončení klikněte na Vytvořit.
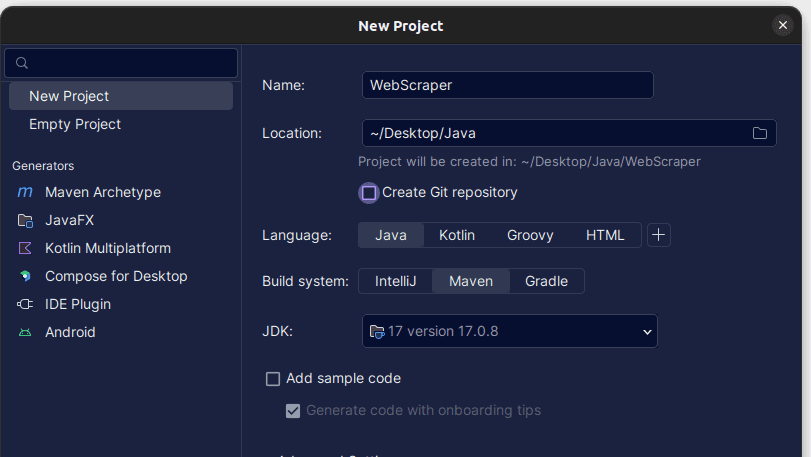
3. Jakmile je váš projekt vytvořen, měli byste mít ve svém projektu pom.xml, jak je znázorněno níže.
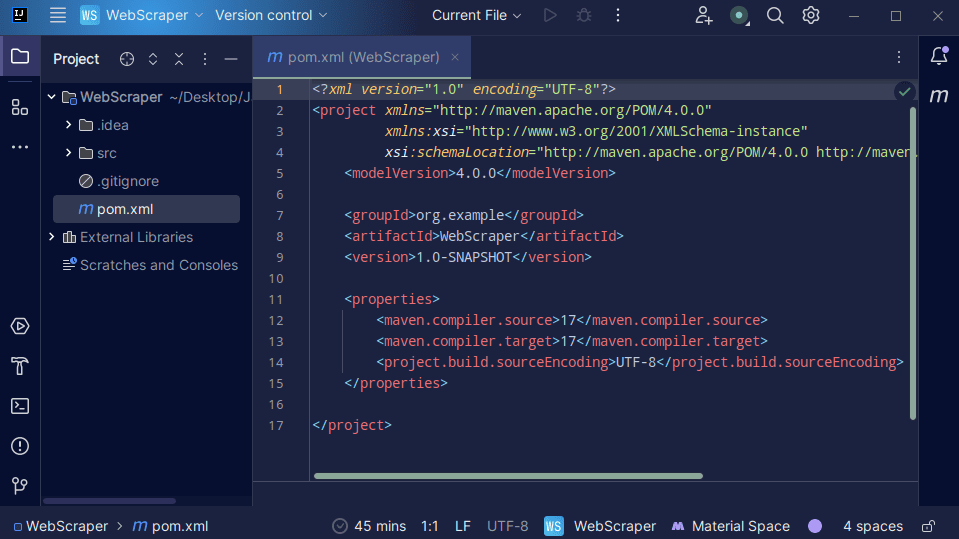
Soubor pom.xml vytvořil Maven a obsahuje informace o projektu a podrobnosti o konfiguraci použité Mavenem k sestavení projektu. Právě tento soubor také používáme k označení toho, že budeme používat externí knihovny.
Při vytváření webového škrabáku budeme používat knihovnu jsoup. Proto ji musíme přidat jako závislost v souboru pom.xml, aby ji Maven mohl zpřístupnit v našem projektu.
4. Přidejte závislost jsoup do souboru pom.xml zkopírováním níže uvedeného kódu a jeho přidáním do souboru pom.xml
<dependencies>
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.16.1</version>
</dependency>
</dependencies>
Výsledek by měl vypadat následovně:
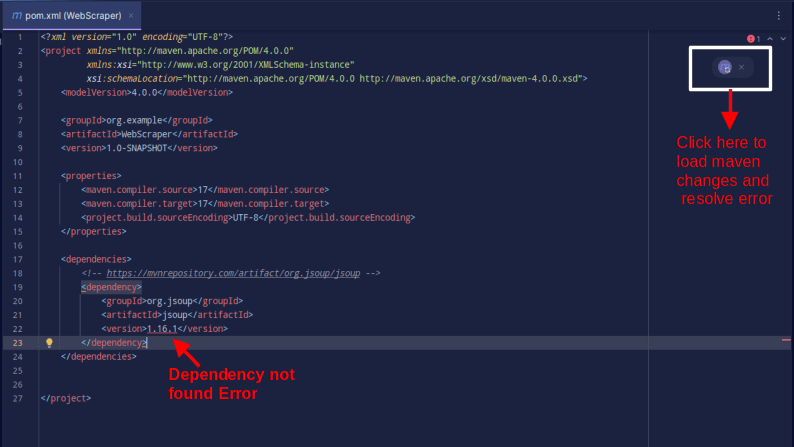
V případě, že narazíte na chybu, že závislost nelze najít, klikněte na indikovanou ikonu pro Maven pro načtení provedených změn, načtení závislosti a odstranění chyby.
Díky tomu je vaše prostředí plně nastaveno.
Web škrábání s Java
Pro web scraping budeme seškrabovat data z ScrapeThisSitekterý poskytuje sandbox, kde si vývojáři mohou procvičovat web scraping, aniž by narazili na právní problémy.
Chcete-li seškrábat web pomocí Javy
1. Na levém panelu nabídek na IntelliJ otevřete adresář src a poté hlavní adresář, který je v adresáři src. Hlavní adresář obsahuje adresář nazvaný java; klikněte na něj pravým tlačítkem a vyberte Nový, poté Java Class
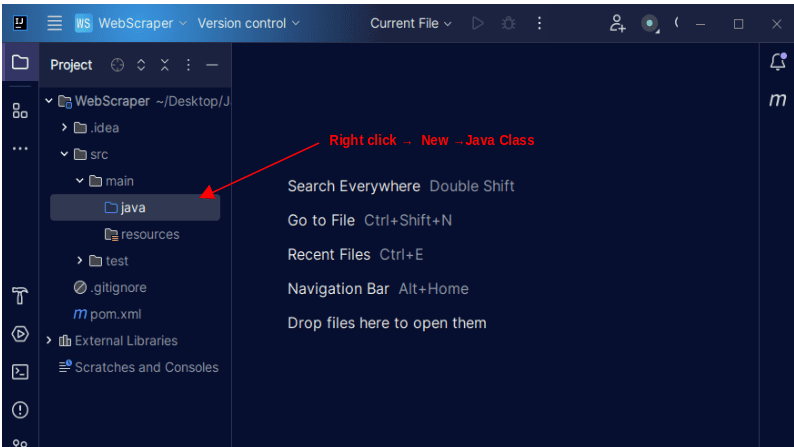
Dejte třídě libovolný název, například WebScraper, a poté stisknutím klávesy Enter vytvořte novou třídu Java.
Otevřete nově vytvořený soubor obsahující třídy Java, které jste právě vytvořili.
2. Web scraping zahrnuje získávání dat z webových stránek. Musíme tedy zadat URL, ze které chceme data seškrabovat. Jakmile určíme adresu URL, musíme se k adrese URL připojit a provést požadavek GET pro načtení obsahu HTML stránky.
Kód, který to dělá, je zobrazen níže:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
System.out.println(doc);
} catch (IOException e) {
System.out.println("An IOException occurred. Please try again.");
}
}
}
Výstup:
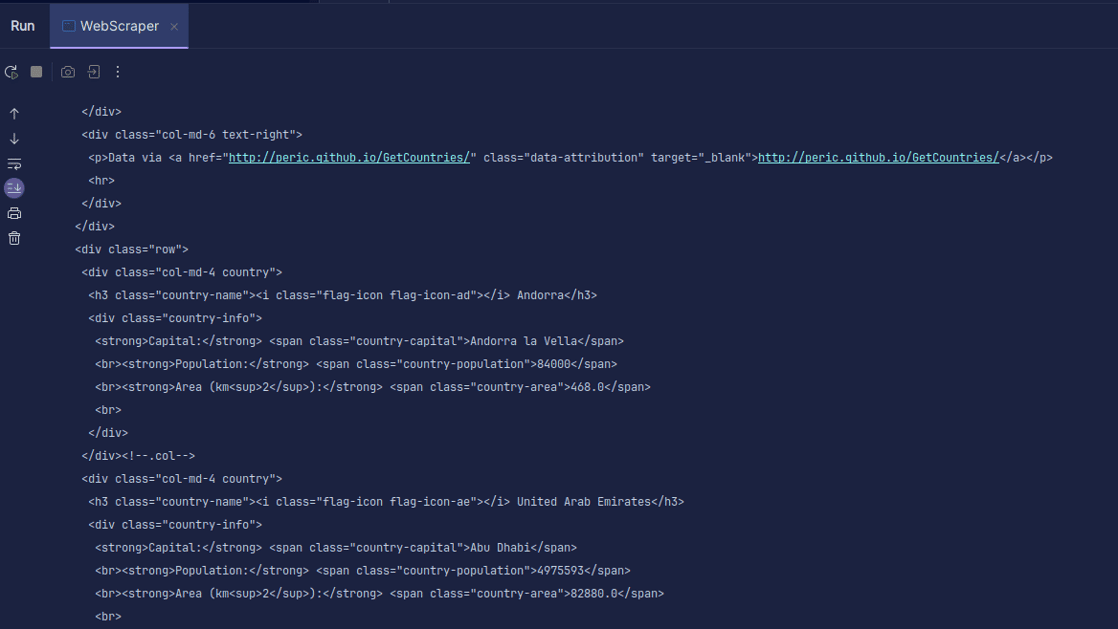
Jak můžete vidět, HTML stránky je vráceno a je to, co tiskneme. Při scrapingu může mít zadaná adresa URL chybu a zdroj, který se pokoušíte odstranit, nemusí vůbec existovat. Proto je důležité zabalit náš kód do příkazu try-catch.
Linie:
Document doc = Jsoup.connect(url).get();
Slouží k připojení k adrese URL, kterou chcete seškrábat. Metoda get() se používá k vytvoření požadavku GET a načtení HTML na stránce. Vrácený výsledek je pak uložen v objektu dokumentu JSOUP s názvem doc. Uložení výsledku do dokumentu JSOUP vám umožňuje používat rozhraní JSOUP API k manipulaci s vráceným HTML.
3. Přejděte na ScrapeThisSite a prohlédněte si stránku. V HTML byste měli vidět strukturu zobrazenou níže:
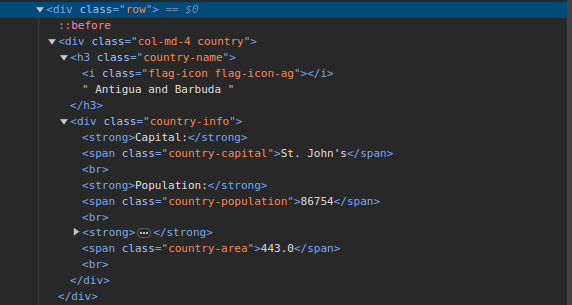
Všimněte si, že všechny země na stránce jsou uloženy pod podobnou strukturou. Existuje div s třídou nazvanou country s prvkem h3 s třídou country-name obsahující název každé země na stránce.
Uvnitř hlavního divu je další div s třídou informací o zemi a obsahuje informace, jako je hlavní město, počet obyvatel a oblast země. Tyto názvy tříd můžeme použít k výběru prvků HTML a extrahování informací z nich.
4. Extrahujte konkrétní obsah z HTML na stránce pomocí následujících řádků:
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " Population - " + population);
}
Používáme metodu select() k výběru prvků z HTML stránky, které odpovídají konkrétnímu CSS selektoru, který předáme. V našem případě předáme názvy tříd. Při kontrole stránky jsme zjistili, že všechny informace o zemi na stránce jsou uloženy pod div s třídou země.
Každá země má svůj vlastní div s třídou země a div obsahuje informace, jako je název země, hlavní město a populace.
Proto nejprve vybereme všechny země na stránce pomocí třídy .country. Tu pak uložíme do proměnné země typu Elements, která funguje stejně jako seznam. Poté pomocí for-loop procházíme zeměmi a extrahujeme název země, hlavní město a obyvatelstvo a vytiskneme, co bylo nalezeno.
Celá naše kódová základna je zobrazena níže:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import org.jsoup.nodes.Element;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " - Population - " + population);
}
} catch (IOException e) {
System.out.println("An IOException occurred. Please try again.");
}
}
}
Výstup:
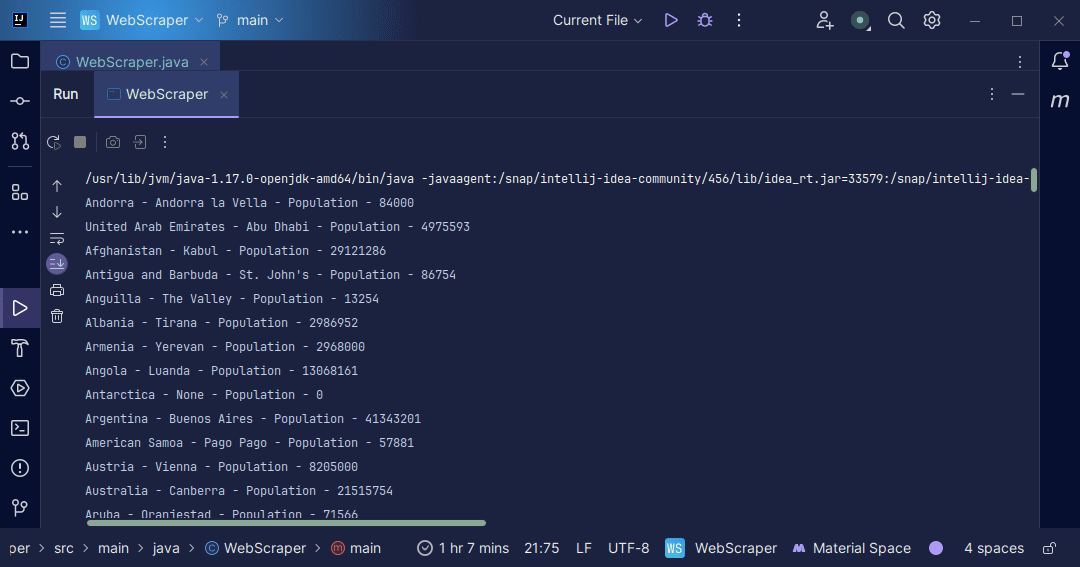
S informacemi, které získáme zpět ze stránky, můžeme dělat různé věci, například je vytisknout tak, jak jsme to právě udělali, nebo je uložit do souboru pro případ, že bychom chtěli provést další zpracování dat.
Závěr
Web scraping je vynikající způsob, jak extrahovat nestrukturovaná data z webových stránek, ukládat data strukturovaným způsobem a zpracovávat data za účelem získání smysluplných informací. Je však důležité dbát zvýšené opatrnosti při seškrabávání webu, protože některé weby seškrabování webu neumožňují.
Chcete-li být na bezpečné straně, použijte webové stránky, které poskytují sandboxy k procvičování šrotování. V opačném případě vždy zkontrolujte soubor robots.txt každé webové stránky, kterou chcete odstranit, abyste zjistili, zda webová stránka umožňuje sešrotování.
při psaní webového scrapperu je Java vynikající jazyk, protože poskytuje knihovny, které usnadňují a zefektivňují web scrapper. Jako vývojáři v jazyce Java vám sestavení webového škrabáku pomůže dále rozvíjet vaše programátorské dovednosti. Takže pokračujte a napište si svůj vlastní webový scrapper nebo upravte ten, který je použit v článku, abyste získali různé druhy informací. Šťastné kódování!
Můžete také prozkoumat některá oblíbená cloudová řešení pro stírání webu.