

Chcete přidat datové struktury do svého programovacího nástroje? Udělejte první kroky ještě dnes tím, že se dozvíte o datových strukturách v Pythonu.
Když se učíte nový programovací jazyk, je důležité porozumět základním datovým typům a vestavěným datovým strukturám, které jazyk podporuje. V této příručce o datových strukturách v Pythonu probereme následující:
- výhody datových struktur
- vestavěné datové struktury v Pythonu, jako jsou seznamy, n-tice, slovníky a sady
- implementace abstraktních datových typů, jako jsou zásobníky a fronty.
Pojďme začít!
Table of Contents
Proč jsou datové struktury užitečné?
Než se podíváme na různé datové struktury, podívejme se, jak může být použití datových struktur užitečné:
- Efektivní zpracování dat: Výběr správné datové struktury pomáhá efektivněji zpracovávat data. Pokud například potřebujete uložit kolekci položek stejného datového typu – s konstantní dobou vyhledávání a těsnou vazbou – můžete si vybrat pole.
- Lepší správa paměti: Ve větších projektech může být pro ukládání stejných dat jedna datová struktura paměťově efektivnější než jiná. Například v Pythonu lze seznamy i n-tice použít k ukládání kolekcí dat stejného nebo různých typů dat. Pokud však víte, že kolekci nemusíte upravovat, můžete si vybrat n-tici, která zabírá relativně méně paměti než seznam.
- Více uspořádaný kód: Použití správné datové struktury pro konkrétní funkci dělá váš kód organizovanější. Ostatní vývojáři, kteří čtou váš kód, budou očekávat, že budete používat specifické datové struktury v závislosti na požadovaném chování. Například: pokud potřebujete mapování párů klíč–hodnota s konstantními časy vyhledávání a vkládání, můžete data uložit do slovníku.
Seznamy
Když potřebujeme v Pythonu vytvořit dynamická pole – od rozhovorů s kódováním po běžné případy použití – seznamy jsou základní datové struktury.
Seznamy Pythonu jsou datové typy kontejnerů, které jsou proměnlivé a dynamické, takže můžete přidávat a odebírat prvky ze seznamu na místě – aniž byste museli vytvářet kopii.
Při použití seznamů Pythonu:
- Indexování do seznamu a přístup k prvku na konkrétním indexu je operace s konstantním časem.
- Přidání prvku na konec seznamu je operace s konstantním časem.
- Vložení prvku na konkrétní index je lineární časovou operací.
Existuje sada metod seznamů, které nám pomáhají efektivně provádět běžné úkoly. Fragment kódu níže ukazuje, jak provést tyto operace na příkladu seznamu:
>>> nums = [5,4,3,2] >>> nums.append(7) >>> nums [5, 4, 3, 2, 7] >>> nums.pop() 7 >>> nums [5, 4, 3, 2] >>> nums.insert(0,9) >>> nums [9, 5, 4, 3, 2]
Seznamy Pythonu také podporují dělení a testování členství pomocí operátoru in:
>>> nums[1:4] [5, 4, 3] >>> 3 in nums True
Struktura dat seznamu je nejen flexibilní a jednoduchá, ale také nám umožňuje ukládat prvky různých datových typů. Python má také vyhrazenou datovou strukturu pole pro efektivní úložné prvky stejného datového typu. O tom se dozvíme později v této příručce.
N-tice
V Pythonu jsou n-tice další oblíbenou vestavěnou datovou strukturou. Jsou jako seznamy Pythonu v tom, že je můžete indexovat v konstantním čase a rozdělit je na plátky. Jsou však neměnné, takže je nemůžete na místě upravovat. Následující fragment kódu vysvětluje výše uvedené s příkladem nums n-tice:
>>> nums = (5,4,3,2) >>> nums[0] 5 >>> nums[0:2] (5, 4) >>> 5 in nums True >>> nums[0] = 7 # not a valid operation! Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'tuple' object does not support item assignment
Takže když chcete vytvořit neměnnou kolekci a být schopni ji efektivně zpracovat, měli byste zvážit použití n-tice. Pokud chcete, aby byla kolekce proměnlivá, raději použijte seznam.
📋 Zjistěte více o podobnostech a rozdílech mezi seznamy Python a n-ticemi.
Pole
Pole jsou v Pythonu méně známé datové struktury. Jsou podobné seznamům Pythonu, pokud jde o operace, které podporují, jako je indexování v konstantním čase a vkládání prvku na konkrétní index v lineárním čase.
Klíčový rozdíl mezi seznamy a poli je však v tom, že pole ukládají prvky jednoho datového typu. Proto jsou pevně spojeny a jsou efektivnější z hlediska paměti.
K vytvoření pole můžeme použít konstruktor array() z vestavěného modulu pole. Konstruktor array() přijímá řetězec určující datový typ prvků a prvků. Zde vytvoříme nums_f, pole čísel s plovoucí desetinnou čárkou:
>>> from array import array
>>> nums_f = array('f',[1.5,4.5,7.5,2.5])
>>> nums_f
array('f', [1.5, 4.5, 7.5, 2.5])
Můžete indexovat do pole (podobně jako seznamy Python):
>>> nums_f[0] 1.5
Pole jsou měnitelná, takže je můžete upravit:
>>> nums_f[0]=3.5
>>> nums_f
array('f', [3.5, 4.5, 7.5, 2.5])
Ale nemůžete upravit prvek tak, aby měl jiný datový typ:
>>> nums_f[0]='zero' Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: must be real number, not str
Struny
V Pythonu jsou řetězce neměnné kolekce znaků Unicode. Na rozdíl od programovacích jazyků, jako je C, Python nemá vyhrazený datový typ znaku. Znak je tedy také řetězec délky jedna.
Jak již bylo zmíněno, řetězec je neměnný:
>>> str_1 = 'python' >>> str_1[0] = 'c' Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'str' object does not support item assignment
Řetězce Pythonu podporují krájení řetězců a sadu metod pro jejich formátování. Zde jsou nějaké příklady:
>>> str_1[1:4] 'yth' >>> str_1.title() 'Python' >>> str_1.upper() 'PYTHON' >>> str_1.swapcase() 'PYTHON'
⚠ Pamatujte, že všechny výše uvedené operace vrací kopii řetězce a nemění původní řetězec. Máte-li zájem, podívejte se na příručku Python Programs on String Operations.
Sady
V Pythonu jsou sady kolekce jedinečných a hašovatelných položek. Můžete provádět operace se společnými sadami, jako je sjednocení, průnik a rozdíl:
>>> set_1 = {3,4,5,7}
>>> set_2 = {4,6,7}
>>> set_1.union(set_2)
{3, 4, 5, 6, 7}
>>> set_1.intersection(set_2)
{4, 7}
>>> set_1.difference(set_2)
{3, 5}
Sady jsou ve výchozím nastavení měnitelné, takže můžete přidávat nové prvky a upravovat je:
>>> set_1.add(10)
>>> set_1
{3, 4, 5, 7, 10}
📚 Přečtěte si sady v Pythonu: Kompletní průvodce s příklady kódu
FrozenSets
Pokud chcete neměnnou sadu, můžete použít zmrazenou sadu. Můžete vytvořit zmrazenou sadu z existujících sad nebo jiných iterovatelných.
>>> frozenset_1 = frozenset(set_1)
>>> frozenset_1
frozenset({3, 4, 5, 7, 10, 11})
Protože zmrazená sada_1 je zmrazená sada, narazíme na chyby, pokud se pokusíme přidat prvky (nebo ji jinak upravit):
>>> frozenset_1.add(15) Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'frozenset' object has no attribute 'add'
Slovníky
Slovník Pythonu je funkčně podobný hash mapě. Slovníky se používají k ukládání párů klíč–hodnota. Klíče slovníku by měly být hašovatelné. To znamená, že hodnota hash objektu se nemění.
K hodnotám můžete přistupovat pomocí klíčů, vkládat nové položky a odstraňovat stávající položky v konstantním čase. Pro provádění těchto operací existují slovníkové metody.
>>> favorites = {'book':'Orlando'}
>>> favorites
{'book': 'Orlando'}
>>> favorites['author']='Virginia Woolf'
>>> favorites
{'book': 'Orlando', 'author': 'Virginia Woolf'}
>>> favorites.pop('author')
'Virginia Woolf'
>>> favorites
{'book': 'Orlando'}
OrderedDict
Ačkoli slovník Pythonu poskytuje mapování klíč-hodnota, jedná se ze své podstaty o neuspořádanou datovou strukturu. Od Pythonu 3.7 je zachováno pořadí vkládání prvků. Ale můžete to udělat jasnější pomocí OrderedDict z modulu kolekcí.
Jak je znázorněno, OrderedDict zachovává pořadí klíčů:
>>> from collections import OrderedDict
>>> od = OrderedDict()
>>> od['first']='one'
>>> od['second']='two'
>>> od['third']='three'
>>> od
OrderedDict([('first', 'one'), ('second', 'two'), ('third', 'three')])
>>> od.keys()
odict_keys(['first', 'second', 'third'])
Výchozí diktát
Klíčové chyby jsou při práci se slovníky Pythonu poměrně časté. Kdykoli se pokusíte získat přístup ke klíči, který nebyl přidán do slovníku, narazíte na výjimku KeyError.
Ale pomocí modulu defaultdict from collections můžete tento případ řešit nativně. Když se pokusíme o přístup ke klíči, který není ve slovníku přítomen, klíč je přidán a inicializován s výchozími hodnotami určenými výchozí továrnou.
>>> from collections import defaultdict >>> prices = defaultdict(int) >>> prices['carrots'] 0
Hromady
Zásobník je datová struktura typu last-in-first-out (LIFO). Na zásobníku můžeme provádět následující operace:
- Přidání prvků na vrchol zásobníku: operace push
- Odebrání prvků z horní části zásobníku: operace pop
Příklad pro ilustraci toho, jak fungují operace stack push a pop:
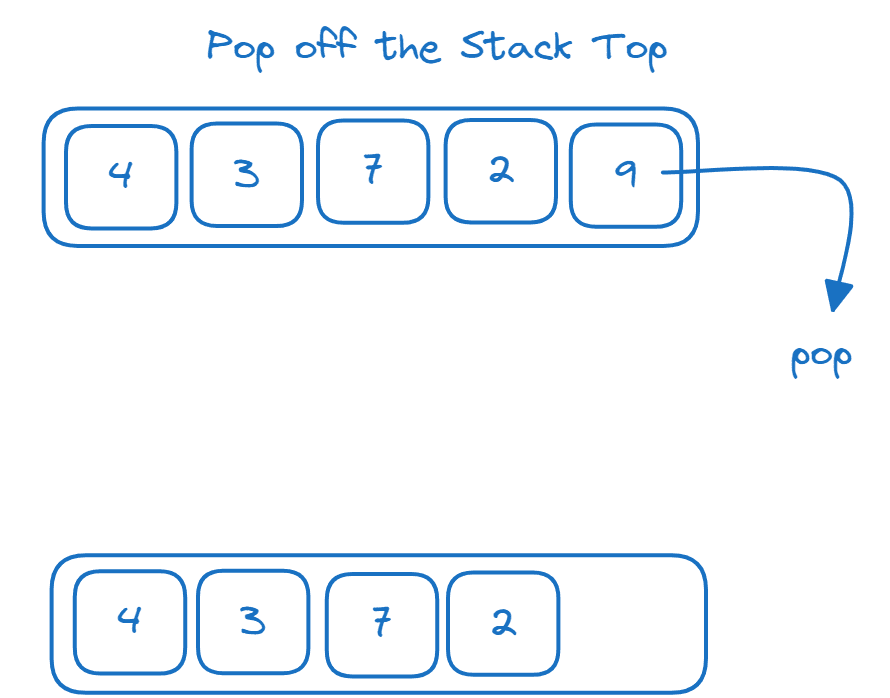
Jak implementovat zásobník pomocí seznamu
V Pythonu můžeme implementovat datovou strukturu zásobníku pomocí seznamu Python.
Operace na StackEquivalent List OperationPush to stack topPřipojte na konec seznamu pomocí metody append()Vyjměte stack topRemove a vraťte poslední prvek pomocí metody pop()
Níže uvedený fragment kódu ukazuje, jak můžeme emulovat chování zásobníku pomocí seznamu Python:
>>> l_stk = [] >>> l_stk.append(4) >>> l_stk.append(3) >>> l_stk.append(7) >>> l_stk.append(2) >>> l_stk.append(9) >>> l_stk [4, 3, 7, 2, 9] >>> l_stk.pop() 9
Jak implementovat Stack pomocí Deque
Další metodou implementace zásobníku je použití deque z modulu kolekcí. Deque znamená dvojitou frontu a podporuje přidávání a odebírání prvků z obou konců.
Chcete-li emulovat zásobník, můžeme:
- připojit na konec deque pomocí append() a
- vyskočí poslední přidaný prvek pomocí pop().
>>> from collections import deque >>> stk = deque() >>> stk.append(4) >>> stk.append(3) >>> stk.append(7) >>> stk.append(2) >>> stk.append(9) >>> stk deque([4, 3, 7, 2,9]) >>> stk.pop() 9
Fronty
Fronta je datová struktura „first-in-first-out“ (FIFO). Prvky se přidávají na konec fronty a odebírají se ze začátku fronty (hlavní konec fronty), jak je znázorněno:
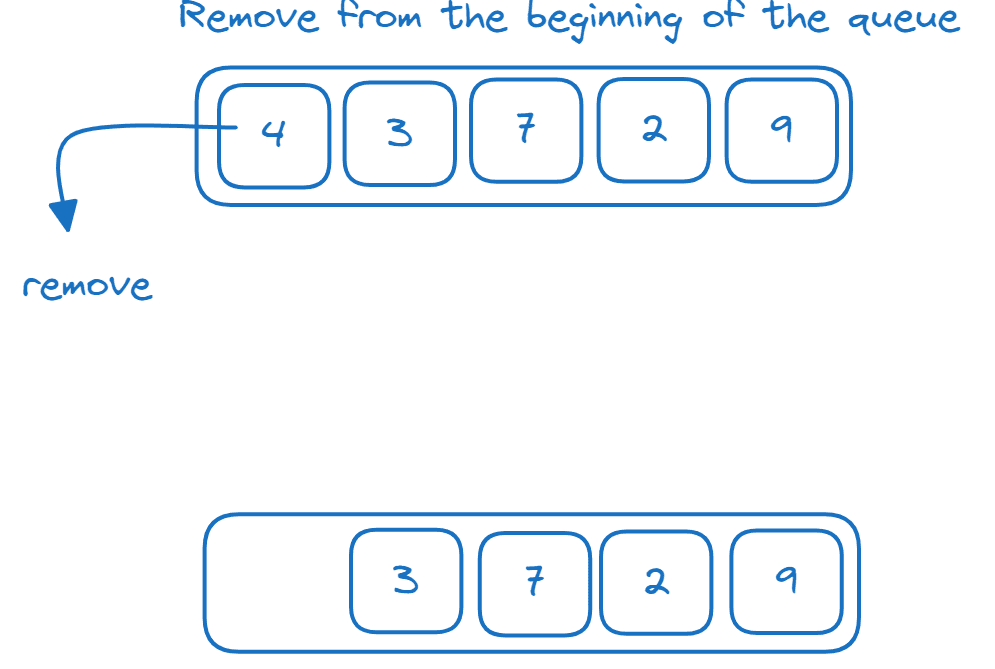
Můžeme implementovat datovou strukturu fronty pomocí deque:
- přidat prvky na konec fronty pomocí append()
- použijte metodu popleft() k odstranění prvku ze začátku fronty
>>> from collections import deque >>> q = deque() >>> q.append(4) >>> q.append(3) >>> q.append(7) >>> q.append(2) >>> q.append(9) >>> q.popleft() 4
Hromady
V této části budeme diskutovat o binárních hromadách. Zaměříme se na minimální hromady.
Min halda je kompletní binární strom. Pojďme si rozebrat, co znamená úplný binární strom:
- Binární strom je stromová datová struktura, kde každý uzel má nejvýše dva podřízené uzly, takže každý uzel je menší než jeho potomek.
- Termín kompletní znamená, že strom je zcela zaplněn, snad kromě poslední úrovně. Pokud je poslední úroveň částečně vyplněna, je naplněna zleva doprava.
Protože každý uzel má maximálně dva podřízené uzly. A také splňuje vlastnost, že je menší než jeho potomek, kořen je minimální prvek v min hromadě.
Zde je příklad min haldy:
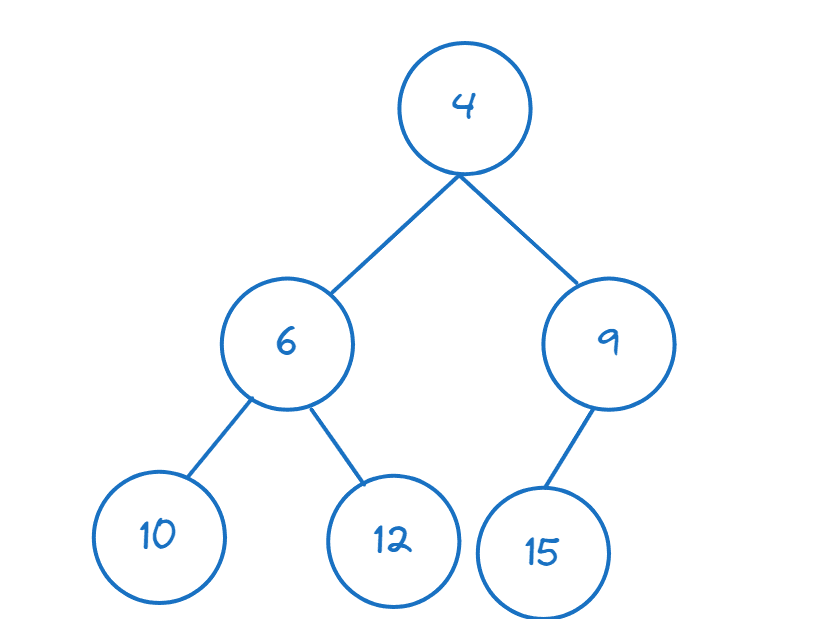
V Pythonu nám modul heapq pomáhá vytvářet hromady a provádět operace na hromadě. Pojďme importovat požadované funkce z heapq:
>>> from heapq import heapify, heappush, heappop
Pokud máte seznam nebo jiný iterovatelný seznam, můžete z něj vytvořit haldu voláním heapify():
>>> nums = [11,8,12,3,7,9,10] >>> heapify(nums)
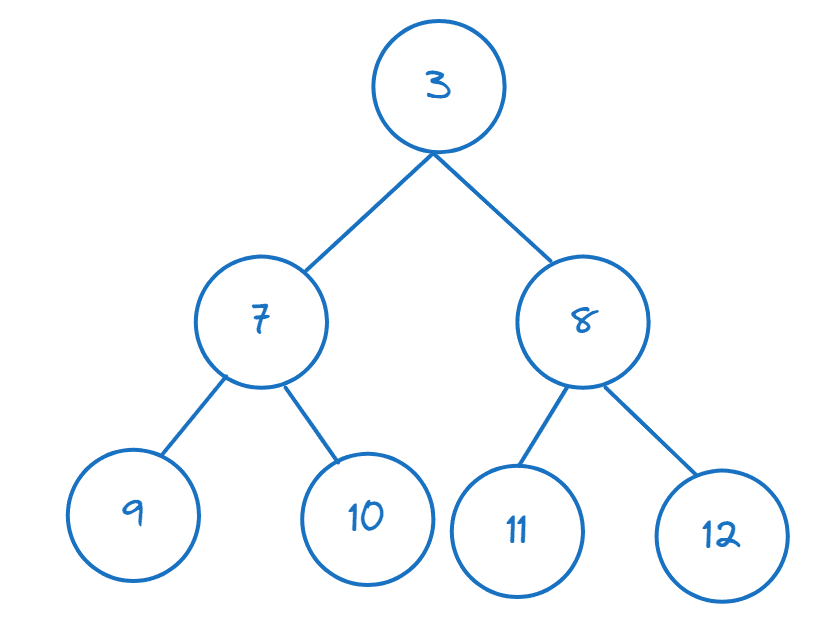
První prvek můžete indexovat a zkontrolovat, zda se jedná o minimální prvek:
>>> nums[0] 3
Nyní, když vložíte prvek do haldy, uzly se přeuspořádají tak, aby splňovaly vlastnost min haldy.
>>> heappush(nums,1)
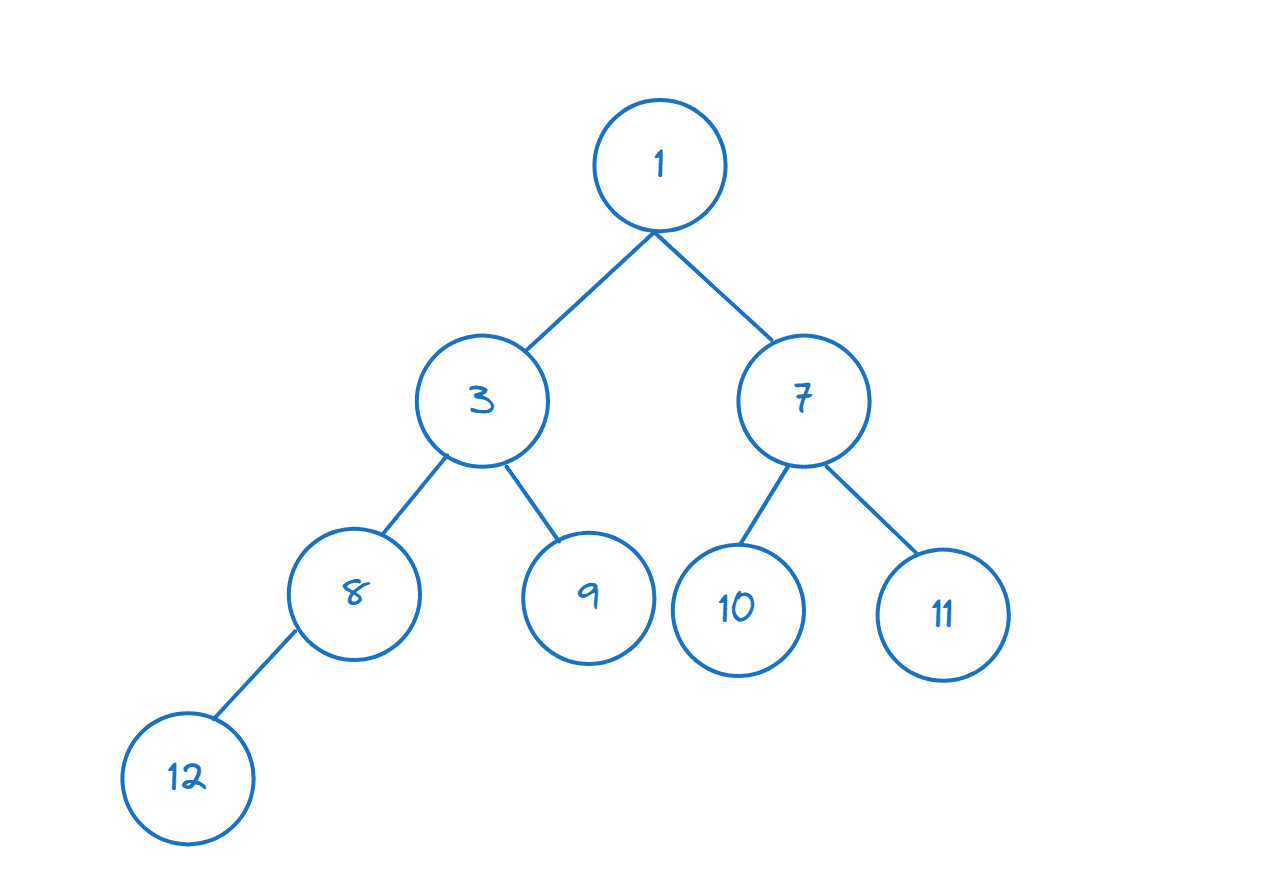
Když jsme vložili 1 (1 < 3), vidíme, že num[0] vrátí 1, což je nyní minimální prvek (a kořenový uzel).
>>> nums[0] 1
Prvky z minimální haldy můžete odstranit voláním funkce heappop() podle obrázku:
>>> while nums: ... print(heappop(nums)) ...
# Output 1 3 7 8 9 10 11 12
Max Heaps v Pythonu
Nyní, když víte o minimálních haldách, můžete uhodnout, jak můžeme implementovat maximální haldu?
No, můžeme převést implementaci minimální haldy na maximální haldu vynásobením každého čísla -1. Negovaná čísla uspořádaná do minimální hromady jsou ekvivalentní původním číslům uspořádaným do maximální hromady.
V implementaci Pythonu můžeme prvky vynásobit -1 při přidávání prvku do haldy pomocí heappush():
>>> maxHeap = [] >>> heappush(maxHeap,-2) >>> heappush(maxHeap,-5) >>> heappush(maxHeap,-7)
Kořenový uzel – vynásobený -1 – bude maximálním prvkem.
>>> -1*maxHeap[0] 7
Při odstraňování prvků z haldy použijte heappop() a vynásobte -1, abyste získali zpět původní hodnotu:
>>> while maxHeap: ... print(-1*heappop(maxHeap)) ...
# Output 7 5 2
Prioritní fronty
Zakončíme diskuzi tím, že se seznámíme s datovou strukturou fronty priorit v Pythonu.
Víme: Ve frontě jsou prvky odstraňovány ve stejném pořadí, v jakém vstupují do fronty. Ale prioritní fronta obsluhuje prvky podle priority – velmi užitečné pro aplikace, jako je plánování. V každém okamžiku je tedy vrácen prvek s nejvyšší prioritou.
K definování priority můžeme použít klávesy. Zde použijeme číselné váhy pro klíče.
Jak implementovat prioritní fronty pomocí Heapq
Zde je implementace prioritní fronty pomocí heapq a seznamu Python:
>>> from heapq import heappush,heappop >>> pq = [] >>> heappush(pq,(2,'write')) >>> heappush(pq,(1,'read')) >>> heappush(pq,(3,'code')) >>> while pq: ... print(heappop(pq)) ...
Při odstraňování prvků fronta obsluhuje nejprve prvek s nejvyšší prioritou (1,’čtení‘), následovaný (2,’zápis‘) a poté (3,’kód‘).
# Output (1, 'read') (2, 'write') (3, 'code')
Jak implementovat prioritní fronty pomocí PriorityQueue
K implementaci prioritní fronty můžeme také použít třídu PriorityQueue z modulu fronty. Toto také používá haldu interně.
Zde je ekvivalentní implementace prioritní fronty pomocí PriorityQueue:
>>> from queue import PriorityQueue >>> pq = PriorityQueue() >>> pq.put((2,'write')) >>> pq.put((1,'read')) >>> pq.put((3,'code')) >>> pq <queue.PriorityQueue object at 0x00BDE730> >>> while not pq.empty(): ... print(pq.get()) ...
# Output (1, 'read') (2, 'write') (3, 'code')
Shrnutí
V tomto tutoriálu jste se dozvěděli o různých vestavěných datových strukturách v Pythonu. Také jsme prošli různými operacemi podporovanými těmito datovými strukturami – a vestavěnými metodami, jak udělat totéž.
Poté jsme prošli dalšími datovými strukturami, jako jsou zásobníky, fronty a prioritní fronty – a jejich implementace v Pythonu pomocí funkcí z modulu kolekcí.
Dále se podívejte na seznam projektů Pythonu pro začátečníky.