Budování datového skladu a Data Lake v AWS
Úložiště dat, datové jezero, nebo třeba dům u jezera... Pokud vás tato spojení nechávají chladnými, pravděpodobně se daty ve své práci nezabýváte.
To by byl ovšem nepravděpodobný scénář, protože v současnosti se zdá, že všechno s daty souvisí. Nebo jak rádi říkají manažeři korporací:
- Data-centrické a data-řízené podnikání.
- Data dostupná kdekoliv, kdykoliv a v jakékoliv podobě.
Klíčové Aktivum
Zdá se, že data se stávají tím nejcennějším, co firmy mají. Pamatuji si, že velké korporace vždy generovaly ohromné množství dat – měsíčně snad terabajty. A to mluvím o době před 10-15 lety. Dnes je však možné takové množství dat vyprodukovat během několika dnů. Nabízí se otázka, zda je to vůbec nutné, a zda je to obsah, který někdo využije. Odpověď zní: rozhodně ne 🙂.
Ne všechna data jsou zbytečná, ale některé části se nemusí nikdy využít. Často jsem byl svědkem toho, jak společnosti generovaly obrovské objemy dat, která se po načtení do systému stala prakticky bezcenná.
Dnes už je ale situace jiná. Úložiště dat – nyní v cloudu – jsou cenově dostupná, zdroje dat exponenciálně rostou a nikdo nedokáže s jistotou říci, co bude potřebovat za rok, až se do systému integrují nové služby. I starší data mohou najednou nabýt na hodnotě.
Proto je strategií ukládat co nejvíce dat, a to v co nejefektivnější podobě. Tak, aby data bylo nejen možné uložit, ale také efektivně vyhledávat, opakovaně používat nebo dále transformovat a distribuovat.
Podívejme se na tři základní způsoby, jak toho dosáhnout v rámci AWS:
- Databáze Athena – cenově výhodný a efektivní, i když jednoduchý způsob, jak vytvořit datové jezero v cloudu.
- Redshift Database – robustní cloudová varianta datového skladu, která má potenciál nahradit většinu současných on-premise řešení a dokáže zvládnout exponenciální nárůst dat.
- Databricks – kombinace datového jezera a datového skladu do jednoho řešení s přidanou hodnotou.
Datové jezero s AWS Athena
Zdroj: aws.amazon.com
Datové jezero slouží jako prostor pro rychlé ukládání příchozích dat v nestrukturované, polostrukturované nebo strukturované podobě. Neočekává se, že se tato data po uložení budou měnit. Měly by být naopak co nejvíce atomické a neměnné. Jen tak se maximalizuje potenciál pro jejich opětovné využití v pozdějších fázích. Pokud bychom o tuto atomicitu dat přišli hned po prvním načtení do datového jezera, neexistuje způsob, jak ztracené informace obnovit.
AWS Athena je databáze, jejíž úložiště je umístěno přímo na S3 bucketech, a nevyužívá serverové clustery na pozadí. Díky tomu se jedná o velmi cenově dostupnou službu pro datové jezero. Organizaci dat zajišťují strukturované formáty souborů, jako jsou Parquet nebo CSV (Comma-Separated Values). S3 bucket uchovává soubory a Athena na ně odkazuje při dotazování dat z databáze.
Athena nepodporuje některé funkce, které jsou běžně považovány za standardní, jako jsou například příkazy pro aktualizaci dat. Z tohoto důvodu je třeba na Athenu nahlížet jako na velmi jednoduchou variantu. Na druhou stranu to zabraňuje úpravám vašeho atomického datového jezera, a to jednoduše proto, že to není možné 😐.
Podporuje indexování a dělení, což umožňuje efektivní provádění výběrových dotazů a vytváření logicky oddělených částí dat (například rozdělených podle sloupců s datem nebo klíči). Lze ji velmi snadno horizontálně škálovat, protože to je stejně složité, jako přidávat další buckety do infrastruktury.

Výhody a nevýhody
Výhody, které stojí za zvážení:
- Nejvýznamnější výhodou je, že Athena je cenově velmi dostupná (skládá se pouze z S3 bucketů a nákladů na použití SQL). Pokud hledáte cenově výhodné datové jezero v AWS, je to správná volba.
- Jako nativní služba se Athena bez problémů integruje s dalšími užitečnými AWS službami, jako je Amazon QuickSight pro vizualizaci dat nebo AWS Glue Data Catalog pro vytváření trvalých strukturovaných metadat.
- Nejlépe se hodí pro ad hoc dotazy nad velkým množstvím strukturovaných i nestrukturovaných dat, bez nutnosti údržby rozsáhlé infrastruktury.
Nevýhody, které stojí za zvážení:
- Athena není příliš efektivní při rychlém vracení složitých výběrových dotazů, obzvláště pokud dotazy neodpovídají předpokladům datového modelu, který byl navržen pro dotazování dat z datového jezera.
- Z tohoto důvodu je také méně flexibilní s ohledem na potenciální budoucí změny v datovém modelu.
- Athena nemá v základu žádné pokročilé funkce. Pokud tedy potřebujete specifické funkcionality, musíte si je implementovat sami.
- Pokud plánujete využívat datové jezero v pokročilejší prezentační vrstvě, často je jedinou možností kombinovat Athenu s jinou databázovou službou, která je pro tento účel vhodnější, jako například AWS Aurora nebo AWS Dynamo DB.
Účel a využití v praxi
Volte Athenu, pokud je vaším cílem vytvořit jednoduché datové jezero bez pokročilých funkcí datového skladu. Pokud tedy neočekáváte, že se nad datovým jezerem budou pravidelně spouštět náročné analytické dotazy vyžadující vysoký výkon. Prioritou je v tomto případě spíše mít úložiště neměnných dat se snadnou škálovatelností.
Již se nemusíte obávat nedostatku místa. Dokonce i náklady na úložiště v S3 bucketech lze snížit implementací politiky životního cyklu dat. To v podstatě znamená přesouvání dat mezi různými typy S3 bucketů, které jsou určené spíše k archivaci, mají pomalejší časy načítání, ale nižší náklady.
Skvělá vlastnost Atheny je, že automaticky vytváří soubor obsahující data, která jsou výsledkem vašeho SQL dotazu. Tento soubor můžete následně využít k libovolnému účelu. Je to tedy dobrá volba, pokud máte mnoho lambda funkcí, které dále zpracovávají data v několika krocích. Každý výsledek lambda funkce bude automaticky strukturovaným souborem, připraveným jako vstup pro další zpracování.
Athena je vhodnou volbou v situacích, kdy do vaší cloudové infrastruktury přichází velké množství nezpracovaných dat, a vy je nepotřebujete zpracovávat ihned při načítání. V takovém případě potřebujete pouze rychlé cloudové úložiště v přehledné struktuře.
Dalším příkladem využití je vytvoření vyhrazeného prostoru pro archivaci dat pro jinou službu. V takovém případě se Athena DB stane levným zálohovacím místem pro všechna data, která momentálně nepotřebujete, ale v budoucnu se to může změnit. V současné době data pouze zpracujete a odešlete dál.
Datový sklad s AWS Redshift
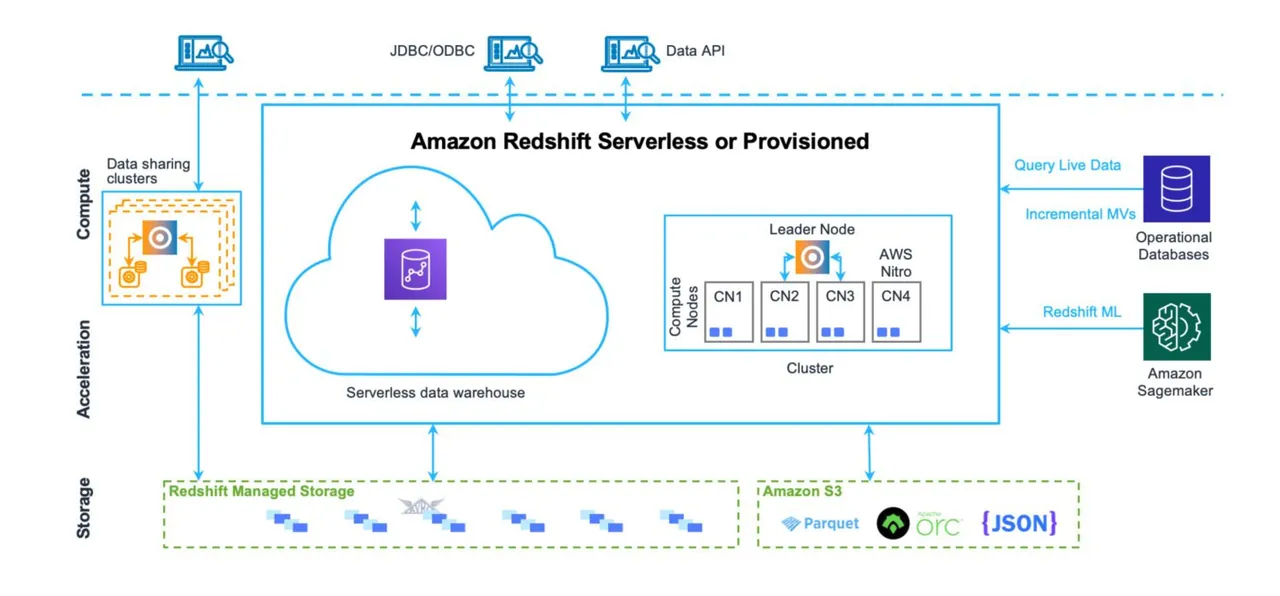 Zdroj: aws.amazon.com
Zdroj: aws.amazon.com
Datový sklad je místo, kde jsou data uložena velmi strukturovaným způsobem, což usnadňuje jejich vkládání a vyjímání. Jeho cílem je spouštět rozsáhlé množství komplexních dotazů, které propojují mnoho tabulek pomocí složitých spojení. K dispozici jsou různé analytické funkce pro výpočet různých statistik na základě stávajících dat. Konečným cílem je získávat budoucí predikce a fakta pro využití v budoucím podnikání, a to na základě existujících dat.
Redshift je plnohodnotný systém datového skladu. Využívá clusterové servery, které lze optimalizovat a škálovat – horizontálně i vertikálně. Systém databázového úložiště je optimalizován pro rychlé vracení komplexních dotazů. Dnes je však možné Redshift provozovat i v bezserverovém režimu. Neukládá žádné soubory na S3, ani nic podobného. Jedná se o standardní databázový clusterový server s vlastním formátem úložiště.
Disponuje nástroji pro monitorování výkonu, a to ihned po spuštění. K dispozici jsou i přizpůsobitelné metriky na řídicím panelu, které můžete používat a sledovat, a tím optimalizovat výkon pro vaše konkrétní použití. Administrace je přístupná prostřednictvím samostatných řídicích panelů. Porozumění všem možným funkcím a nastavením, a tomu, jak ovlivňují cluster, vyžaduje určitou snahu. Přesto to není zdaleka tak složité, jako byla administrace serverů Oracle u on-premise řešení.
I když v Redshiftu existují různá omezení ze strany AWS, která stanovují určité hranice jeho každodenního používání (například pevné limity na počet souběžných aktivních uživatelů nebo relací v jednom databázovém clusteru), skutečnost, že operace probíhají velmi rychle, pomáhá tato omezení částečně obejít.

Výhody a nevýhody
Výhody, které stojí za zvážení:
- Nativní služba cloudového datového skladu od AWS, kterou lze snadno integrovat s dalšími službami.
- Centrální místo pro ukládání, monitorování a příjímání různých typů dat z mnoha odlišných zdrojových systémů.
- Pokud jste někdy chtěli bezserverový datový sklad bez nutnosti údržby infrastruktury, nyní je to možné.
- Optimalizováno pro vysoce výkonnou analýzu a vytváření reportů. Na rozdíl od řešení datového jezera, disponuje silným relačním datovým modelem pro ukládání všech příchozích dat.
- Databázový engine Redshift vychází z PostgreSQL, což zajišťuje vysokou kompatibilitu s ostatními databázovými systémy.
- Velmi užitečné jsou příkazy COPY a UNLOAD pro načítání a vyjímání dat z S3 bucketů.
Nevýhody, které stojí za zvážení:
- Redshift nepodporuje velké množství souběžných aktivních relací. Relace budou pozastaveny a zpracovány postupně. I když to ve většině případů nemusí být problém, protože operace jsou rychlé, je to limitující faktor v systémech s velkým počtem aktivních uživatelů.
- Ačkoli Redshift podporuje mnoho funkcí známých z vyspělých systémů Oracle, stále není na stejné úrovni. Některé z očekávaných funkcí tam prostě nemusí být (například triggery databáze). Nebo je Redshift podporuje v poměrně omezené podobě (například materializované pohledy).
- Kdykoliv potřebujete pokročilejší zpracování dat na míru, musíte si ho vyvinout sami. Většinou se k tomu používá jazyk Python nebo Javascript. Není to tak přirozené, jako PL/SQL v případě systému Oracle, kde i funkce a procedury používají jazyk velmi podobný SQL dotazům.
Účel a využití v praxi
Redshift může být vaším centrálním úložištěm pro všechny různé zdroje dat, které dříve žily mimo cloud. Je to vhodná náhrada za starší řešení datových skladů Oracle. Vzhledem k tomu, že se také jedná o relační databázi, je migrace z Oracle poměrně snadná operace.
Pokud máte stávající řešení datového skladu na mnoha místech, která nejsou jednotná, pokud jde o přístup, strukturu nebo sadu standardních procesů, které mají být nad daty spouštěny, je Redshift skvělou volbou.
Dává vám možnost sloučit všechny různé systémy datových skladů z různých míst a zemí pod jednu střechu. Stále je můžete oddělit podle zemí, aby data zůstala v bezpečí a dostupná pouze těm, kteří je potřebují. Zároveň vám ale umožní vybudovat jednotné skladové řešení pokrývající všechna firemní data.
Další možností je vybudovat platformu datového skladu s rozsáhlou podporou samoobsluhy. Můžete si to představit jako sadu procesů, které si mohou jednotliví uživatelé systému sestavit. Přitom však nikdy nejsou součástí řešení společné platformy. To znamená, že tyto služby zůstanou dostupné pouze tvůrci nebo skupině lidí, kterou vytvořil. Žádným způsobem neovlivní ostatní uživatele.
Podívejte se na naše srovnání mezi Datalake a Datawarehouse.
Lakehouse od Databricks na AWS
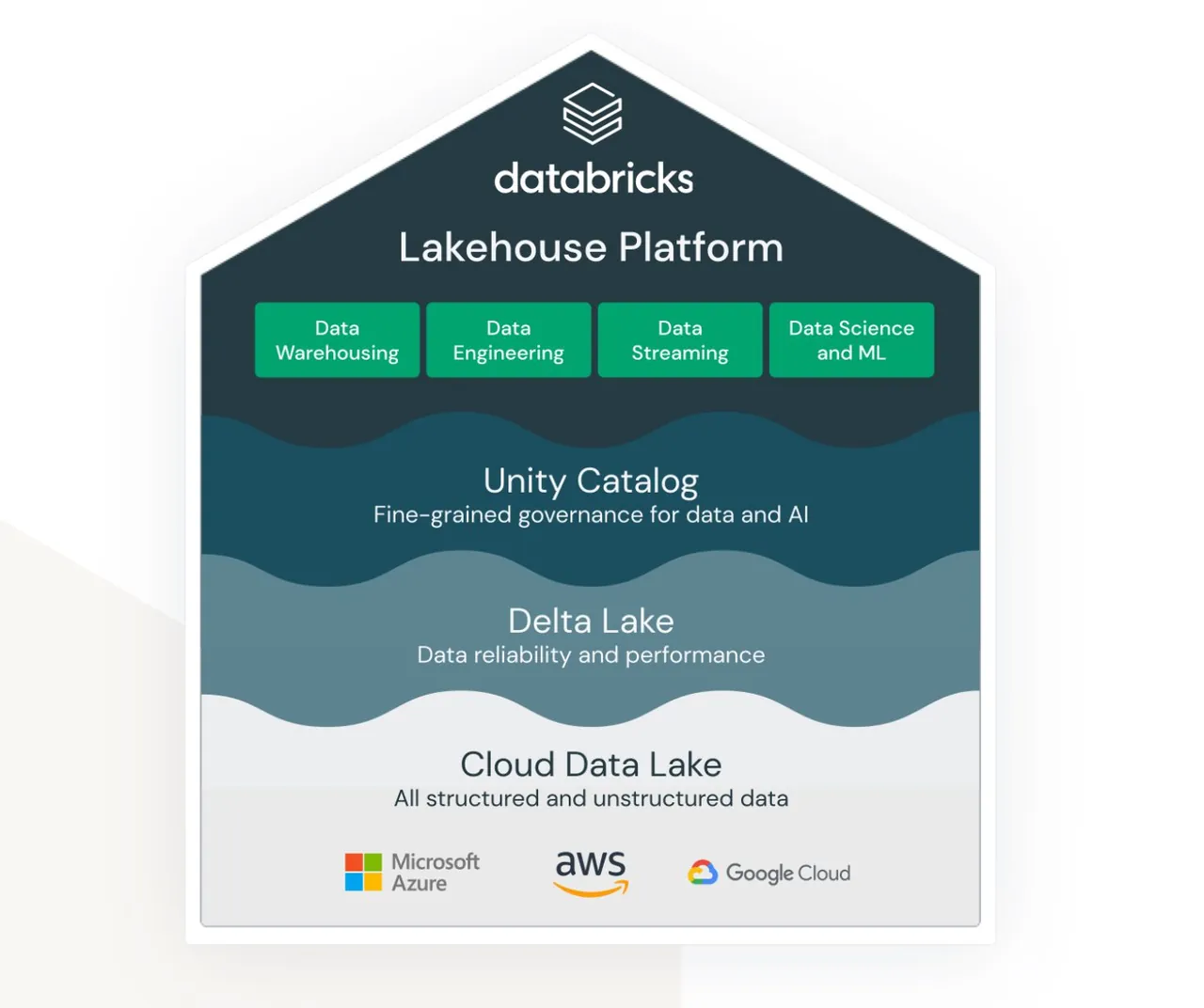 Zdroj: databricks.com
Zdroj: databricks.com
Lakehouse je termín, který je úzce spjatý se službou Databricks. I když se nejedná o nativní službu AWS, velmi dobře funguje v rámci ekosystému AWS a poskytuje různé možnosti propojení a integrace s dalšími službami AWS.
Cílem Databricks je propojit dříve velmi odlišné oblasti:
- Řešení pro ukládání nestrukturovaných, polostrukturovaných a strukturovaných dat v datovém jezeře.
- Řešení pro strukturovaná a rychle dostupná data z datového skladu (označované také jako Delta Lake).
- Řešení pro analýzu a výpočty strojového učení nad datovým jezerem.
- Správa dat pro všechny výše uvedené oblasti s centralizovanou správou a hotovými nástroji pro podporu produktivity pro různé typy vývojářů a uživatelů.
Jedná se o jednotnou platformu, kterou mohou datoví inženýři, SQL vývojáři a datoví vědci strojového učení používat současně. Každá ze skupin má k dispozici nástroje pro plnění svých úkolů.
Databricks se tedy zaměřuje na univerzální řešení a snaží se spojit výhody datového jezera a datového skladu do jediného řešení. Navíc poskytuje nástroje pro testování a spouštění modelů strojového učení přímo nad vytvořenými datovými úložišti.

Výhody a nevýhody
Výhody, které stojí za zvážení:
- Databricks je vysoce škálovatelná datová platforma. Škáluje se v závislosti na velikosti zátěže, a to i automaticky.
- Jedná se o prostředí pro spolupráci mezi datovými vědci, datovými inženýry a obchodními analytiky. Možnost dělat vše v jednom prostoru a společně je velkou výhodou. Nejen z organizačního hlediska, ale pomáhá to šetřit náklady, které by jinak byly nutné pro samostatná prostředí.
- AWS Databricks se hladce integruje s dalšími službami AWS, jako jsou Amazon S3, Amazon Redshift a Amazon EMR. Uživatelé tak mohou snadno přenášet data mezi službami a využívat celou škálu cloudových služeb AWS.
Nevýhody, které stojí za zvážení:
- Databricks může být složité nastavit a spravovat, zejména pro uživatele, kteří nemají zkušenosti se zpracováním velkých dat. Pro maximální využití platformy je zapotřebí značná úroveň technických znalostí.
- I když je Databricks cenově efektivní, pokud jde o průběžný cenový model, může být stále drahý pro rozsáhlé projekty zpracování dat. Náklady na používání platformy se mohou rychle sčítat, zejména pokud uživatelé potřebují rozšiřovat své zdroje.
- Databricks poskytuje řadu předpřipravených nástrojů a šablon, což ale může být také omezení pro uživatele, kteří vyžadují více možností přizpůsobení. Platforma nemusí být vhodná pro uživatele, kteří požadují větší flexibilitu a kontrolu nad svými pracovními postupy zpracování velkých dat.
Účel a využití v praxi
AWS Databricks se nejlépe hodí pro velké korporace s velmi velkým množstvím dat. Zde může pokrýt požadavek na načítání a kontextualizaci různých datových zdrojů z různých externích systémů.
Často je požadavkem poskytovat data v reálném čase. To znamená, že od okamžiku, kdy se data objeví ve zdrojovém systému, procesy okamžitě, nebo s minimálním zpožděním, vyzvednou a zpracují, a uloží data do Databricks. Pokud je zpoždění něco málo přes minutu, považuje se to za zpracování téměř v reálném čase. V každém případě jsou oba scénáře s platformou Databricks dosažitelné. To je dáno především velkým počtem adaptérů a rozhraní v reálném čase, které se připojují k různým dalším nativním službám AWS.
Databricks se také snadno integruje se systémy Informatica ETL. Pokud organizace již intenzivně využívá ekosystém Informatica, jeví se Databricks jako dobrý kompatibilní doplněk platformy.
Závěrem
S tím, jak objem dat exponenciálně roste, je dobré vědět, že existují řešení, která si s tím efektivně poradí. Správa a údržba toho, co bylo kdysi noční můrou, dnes vyžaduje velmi málo administrativní práce. Tým se může soustředit na vytváření hodnoty z dat.
Podle vašich potřeb si stačí vybrat službu, která je zvládne. Zatímco AWS Databricks je něco, čeho se budete muset po rozhodnutí pravděpodobně držet, ostatní alternativy jsou poměrně flexibilnější, i když méně schopné, a to zejména jejich bezserverové režimy. Později je poměrně snadné přejít na jiné řešení.
