Co je Confusion Matrix ve strojovém učení?
Matice záměn je neocenitelný nástroj pro posouzení efektivity klasifikačních algoritmů, které spadají do kategorie strojového učení s dohledem.
Co je to matice záměn?
Je fascinující, jak my, lidé, vnímáme realitu různými způsoby. Dokonce i pohled na pravdu či lež se může lišit. Co se mně může jevit jako čára dlouhá 10 cm, vy můžete vnímat jako 9 cm. Skutečná délka však může být 9, 10, nebo i jiná. To, co my odhadujeme, je pouze námi vnímaná, předpokládaná hodnota!
Jak uvažuje lidský mozek
Podobně jako náš mozek používá svou vlastní logiku k předpovídání událostí, stroje využívají rozličné algoritmy (označované jako algoritmy strojového učení) k dosažení předpokládané hodnoty v určitém kontextu. Opět platí, že tyto hodnoty se mohou shodovat, ale i lišit od skutečnosti.
V dynamickém prostředí plném konkurence chceme přesně vědět, zda naše predikce byly správné, abychom mohli objektivně posoudit naši výkonnost. Stejný princip platí i pro algoritmy strojového učení – jejich úspěšnost můžeme měřit podle toho, kolik predikcí provedly správně.
Co přesně je tedy algoritmus strojového učení?
Stroje se snaží dospět k relevantním odpovědím na specifické problémy, a to aplikováním určité logiky nebo sady přesných instrukcí, které se nazývají algoritmy strojového učení. Tyto algoritmy se dělí do tří hlavních kategorií: s dohledem, bez dohledu a s posilováním.
Typy algoritmů strojového učení
Nejjednodušší variantou jsou algoritmy s dohledem, u kterých již předem známe správnou odpověď. Trénujeme stroje tak, aby k této odpovědi docházely samy, a to pomocí velkého množství dat. Stejně tak se i dítě učí rozlišovat mezi lidmi různého věku – opakovaným pozorováním jejich specifických rysů.
Algoritmy ML s dohledem se dále dělí na dva typy – klasifikační a regresní.
Klasifikační algoritmy seskupují nebo třídí data na základě konkrétních kritérií. Například, pokud chcete, aby váš algoritmus rozdělil zákazníky do skupin na základě jejich preferencí v jídle – tedy na ty, kteří mají rádi pizzu, a ty, kteří ji nemají rádi, použijete klasifikační algoritmus, jako je rozhodovací strom, náhodný les, naivní Bayes nebo SVM (Support Vector Machine).
Který z těchto algoritmů však splní tento úkol nejlépe? A proč bychom měli dát přednost jednomu algoritmu před druhým?
Zde vstupuje na scénu matice záměn…
Matice záměn je v podstatě tabulka, která poskytuje ucelený přehled o tom, jak přesný je klasifikační algoritmus při třídění daného datového souboru. Její název sice není záměrně matoucí, ale příliš velké množství nesprávných předpovědí může naznačovat, že algoritmus je skutečně „zmatený“ 😉!
Zjednodušeně řečeno, matice záměn je metodou pro hodnocení účinnosti klasifikačních algoritmů.
Jak to funguje?
Představme si, že jste aplikovali různé algoritmy na již zmiňovaný binární problém: klasifikaci (rozdělení) lidí podle toho, zda mají rádi pizzu, nebo ne. Pro vyhodnocení algoritmu, jehož výsledky se nejvíce blíží správné odpovědi, byste využili matici záměn. Pro binární klasifikaci (líbí se/nelíbí se, pravda/nepravda, 1/0) poskytuje matice záměn čtyři základní hodnoty:
- Skutečně pozitivní (TP)
- Skutečně negativní (TN)
- Falešně pozitivní (FP)
- Falešně negativní (FN)
Co znamenají čtyři kvadranty v matici záměn?
Čtyři výše zmíněné hodnoty tvoří základní strukturu matice záměn.
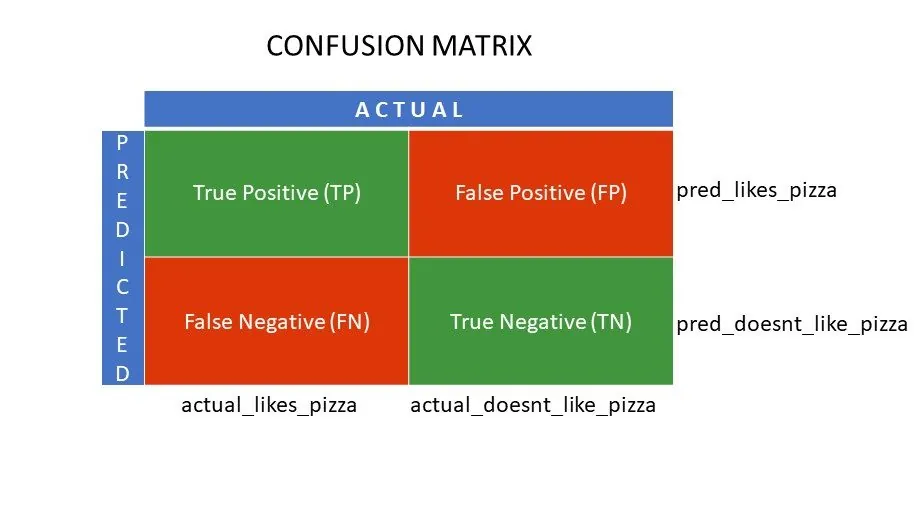 Kvadranty matice záměn
Kvadranty matice záměn
Skutečně pozitivní (TP) a Skutečně negativní (TN) jsou hodnoty, které klasifikační algoritmus předpověděl správně:
- TP reprezentuje ty, kteří mají rádi pizzu a model je správně klasifikoval.
- TN reprezentuje ty, kteří pizzu nemají rádi a model je opět správně zařadil.
Falešně pozitivní (FP) a Falešně negativní (FN) jsou naopak hodnoty, které klasifikátor předpověděl nesprávně:
- FP reprezentuje ty, kteří pizzu nemají rádi (negativní), ale klasifikátor nesprávně určil, že pizzu mají rádi (falešně pozitivní). FP je také označován jako chyba I. typu.
- FN reprezentuje ty, kteří pizzu mají rádi (pozitivní), ale klasifikátor chybně předpověděl, že ji nemají rádi (falešně negativní). FN se také označuje jako chyba II. typu.
Pro lepší pochopení tohoto konceptu si představme konkrétní situaci z reálného života.
Předpokládejme, že máte datový soubor se 400 lidmi, kteří podstoupili test na COVID. K dispozici jsou vám výsledky různých algoritmů, které predikují počet osob s pozitivním a negativním výsledkem testu.
Níže uvádíme dvě matice záměn pro srovnání:
Při pohledu na obě matice by vás mohlo napadnout, že první algoritmus je přesnější. Nicméně, pro dosažení objektivního závěru potřebujeme metriky, které jsou schopné změřit přesnost a další parametry, které nám jednoznačně ukáží, který algoritmus si vede lépe.
Metriky odvozené z matice záměn a jejich význam
Mezi nejdůležitější metriky, které nám pomáhají posoudit, zda klasifikátor provedl správné předpovědi, patří:
#1. Výtěžnost/senzitivita
Výtěžnost (Recall), senzitivita nebo míra skutečně pozitivních výsledků (TPR), případně pravděpodobnost detekce, je poměr mezi správně identifikovanými pozitivními případy (TP) a všemi pozitivními případy (TP a FN).
R = TP/(TP + FN)
Výtěžnost (Recall) kvantifikuje, jak dobře model odhaluje skutečné pozitivní případy z celkového počtu, které mohl odhalit. Vyšší hodnota výtěžnosti naznačuje menší počet falešně negativních výsledků, což je u algoritmu považováno za pozitivní. Pokud je klíčové vědět o existenci falešně negativních výsledků, měli bychom se zaměřit právě na výtěžnost (Recall). Například, pokud má pacient vážné srdeční obtíže a model mylně indikuje, že je naprosto zdravý, může to mít fatální důsledky.
#2. Přesnost
Přesnost je definována jako míra správných pozitivních výsledků mezi všemi predikovanými pozitivními výsledky, včetně skutečně pozitivních i falešně pozitivních.
Pr = TP/(TP + FP)
Přesnost hraje zásadní roli tam, kde je klíčové nezapomínat na falešně pozitivní výsledky. Například, pokud pacient nemá cukrovku, ale model tuto skutečnost chybně identifikuje, a lékař následně předepíše léky, může to vést k závažným nežádoucím účinkům.
#3. Specificita
Specificita, nebo míra skutečně negativních výsledků (TNR), představuje podíl správně rozpoznaných negativních případů ze všech potenciálních negativních případů.
S = TN/(TN + FP)
Tato metrika ukazuje, jak efektivně je váš klasifikátor schopen identifikovat negativní hodnoty.
#4. Úspěšnost
Úspěšnost vyjadřuje procento správně predikovaných případů ze všech předpovědí. Pokud tedy ze vzorku 50 hodnot správně identifikujete 20 pozitivních a 10 negativních, úspěšnost vašeho modelu bude 30/50.
Úspěšnost A = (TP + TN)/(TP + TN + FP + FN)
#5. Prevalence
Prevalence vyjadřuje podíl pozitivních výsledků ze všech celkových výsledků.
P = (TP + FN)/(TP + TN + FP + FN)
#6. F-skóre
Někdy je obtížné porovnávat dva různé klasifikátory (modely) pouze na základě přesnosti a výtěžnosti, které jsou pouhými aritmetickými průměry kombinací čtyř kvadrantů matice. V takových případech můžeme použít F-skóre, případně F1-skóre, které je harmonickým průměrem. Harmonický průměr je přesnější, jelikož se příliš neliší v případě extrémně vysokých hodnot. Vyšší F-skóre (maximum je 1) indikuje lepší model.
F-skóre = 2 * přesnost * výtěžnost / (výtěžnost + přesnost)
Pokud je klíčové věnovat pozornost jak falešně pozitivním, tak i falešně negativním výsledkům, pak je F1-skóre vhodnou metrikou. Například lidé, kteří nejsou COVID pozitivní (ale algoritmus to ukazuje), by neměli být zbytečně izolováni. Stejně tak je nutné izolovat ty, kteří jsou COVID pozitivní (ale algoritmus to vyhodnotil negativně).
#7. ROC křivky
Parametry, jako je přesnost a úspěšnost, jsou efektivní metriky v případě, že jsou data vyvážená. U nevyváženého datového souboru nemusí vysoká úspěšnost nutně znamenat, že je klasifikátor skutečně kvalitní. Například, pokud 90 ze 100 studentů ve skupině mluví španělsky, a váš algoritmus tvrdí, že mluví španělsky všech 100, jeho úspěšnost bude 90%, což zkresluje realitu. V případech nevyvážených datových souborů jsou metriky jako ROC efektivnějším měřítkem.
 Příklad ROC křivky
Příklad ROC křivky
Křivka ROC (Receiver Operating Characteristic) vizualizuje výkon binárního klasifikačního modelu při různých prahových hodnotách. Jedná se o graf zobrazující TPR (míra skutečně pozitivních výsledků) proti FPR (míra falešně pozitivních výsledků), která se počítá jako (1 – Specificita), při různých prahových hodnotách. Hodnota, která je v grafu nejblíže 45 stupňům (v levém horním rohu), reprezentuje nejpřesnější prahovou hodnotu. Pokud je prahová hodnota příliš vysoká, nezískáme mnoho falešně pozitivních výsledků, ale získáme více falešně negativních, a naopak.
Obecně se při porovnávání ROC křivek pro různé modely, za lepší model považuje ten, který má největší plochu pod křivkou (AUC).
Nyní vypočítáme všechny metrické hodnoty pro naše matice záměn klasifikátoru I a klasifikátoru II:
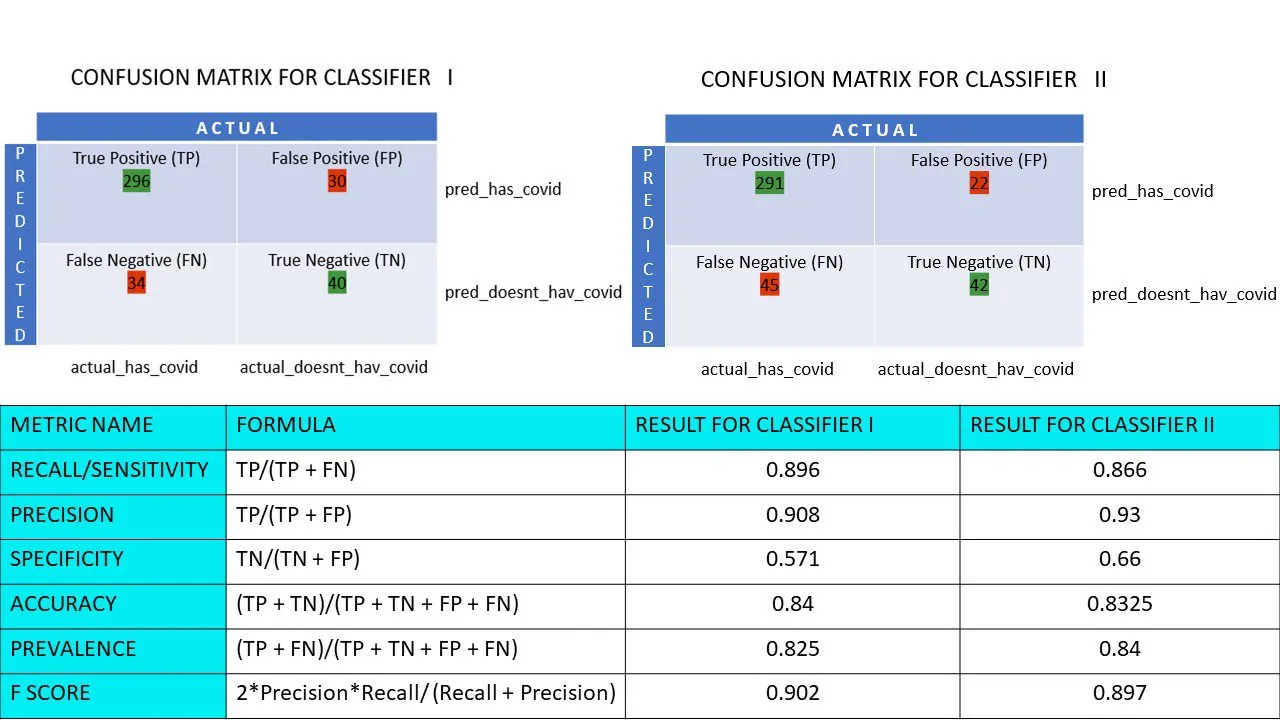 Srovnání metrik pro klasifikátory 1 a 2 v průzkumu o pizze
Srovnání metrik pro klasifikátory 1 a 2 v průzkumu o pizze
Vidíme, že úspěšnost je vyšší u klasifikátoru II, zatímco přesnost je mírně vyšší u klasifikátoru I. Na základě konkrétního problému, mohou osoby s rozhodovací pravomocí zvolit klasifikátor I nebo II.
Matice záměn N x N
Dosud jsme se zaměřovali na matice záměn pro binární klasifikátory. Co když však existuje více kategorií než pouhé ano/ne, nebo líbí se/nelíbí se? Například, pokud má váš algoritmus klasifikovat obrázky do kategorií červená, zelená a modrá. Tento typ klasifikace je označován jako klasifikace s více třídami. Velikost matice je dána počtem výstupních proměnných. V tomto případě tedy bude matice záměn 3×3.
 Matice záměn pro vícetřídní klasifikátor
Matice záměn pro vícetřídní klasifikátor
Shrnutí
Matice záměn je cenný systém hodnocení, protože nabízí podrobný přehled o výkonnosti klasifikačního algoritmu. Je vhodná jak pro binární, tak i pro vícetřídní klasifikátory, kde je potřeba brát v úvahu více než 2 parametry. Matice záměn je snadno vizualizovatelná a z jejího základě je možné generovat všechny ostatní metriky výkonnosti, jako jsou F-skóre, přesnost, ROC a úspěšnost.
Můžete se také podívat na postupy výběru algoritmů ML pro regresní problémy.
