Implementace třídicích algoritmů v Pythonu
Přehled základních třídicích algoritmů
Třídění představuje klíčovou operaci v programování a efektivní algoritmus má zásadní vliv na rychlost zpracování dat. Správná volba třídicího postupu může ušetřit značné množství času a výpočetních zdrojů.
V tomto článku se seznámíme s několika různými třídicími algoritmy, které jsou základem algoritmické práce.
Projdeme si implementaci každého algoritmu krok za krokem, přičemž budeme využívat jazyk Python. Jakmile si osvojíte principy fungování daného algoritmu, budete moci jeho implementaci snadno přepsat do libovolného programovacího jazyka. Zde hraje roli pouze syntaxe cílového jazyka.
V tomto tutoriálu budeme algoritmy prezentovat od nejméně efektivních po ty s nejlepšími výkonnostními charakteristikami. Postupujte krok za krokem a sami si algoritmy vyzkoušejte.
Pojďme se tedy podívat na jednotlivé algoritmy podrobněji.
Třídění vkládáním (Insertion Sort)
Třídění vkládáním je jeden z nejjednodušších třídicích algoritmů, který je snadný na implementaci. Nicméně jeho nevýhodou je časová náročnost při třídění velkého množství dat. Proto se zpravidla nepoužívá pro větší datové sady.
Algoritmus pracuje na principu rozdělení pole na seřazenou a neseřazenou část. Seřazená část na začátku procesu obsahuje pouze první prvek. Následně se iteruje neseřazená část a každý prvek se vkládá na správnou pozici v seřazené části.
Pro lepší pochopení si algoritmus představíme na vizuální ukázce krok za krokem.
Nyní se podíváme na implementační kroky:
- Inicializujeme pole s libovolnými číselnými daty.
- Procházíme pole od druhého prvku.
- Uložíme aktuální pozici a prvek do proměnných.
- Vytvoříme cyklus, který se opakuje, dokud nenarazíme na první prvek pole nebo prvek menší než aktuální prvek.
- Aktualizujeme aktuální prvek předchozím prvkem.
- Snížíme aktuální pozici o 1.
- Nakonec umístíme aktuální prvek na určenou pozici.
Časová složitost algoritmu vkládáním je O(n^2) a prostorová O(1).
Nyní se podíváme na implementaci v Pythonu. Pokud nemáte Python nainstalovaný, můžete využít online kompilátor.
def insertion_sort(arr, n): for i in range(1, n): ## aktuální pozice a element current_position = i current_element = arr[i] ## iterace dokud ### nedosáhneme prvního prvku nebo ### aktuální prvek není menší než předchozí while current_position > 0 and current_element < arr[current_position - 1]: ## aktualizace aktuálního prvku předchozím arr[current_position] = arr[current_position - 1] ## posun na předchozí pozici current_position -= 1 ## aktualizace prvku na aktuální pozici arr[current_position] = current_element if __name__ == '__main__': ## inicializace pole arr = [3, 4, 7, 8, 1, 9, 5, 2, 6] insertion_sort(arr, 9) ## výpis pole print(str(arr))
Třídění výběrem (Selection Sort)
Třídění výběrem je podobné třídění vkládáním, ovšem s drobným rozdílem. I tento algoritmus rozděluje pole na seřazenou a neseřazenou část. V každé iteraci vybere nejmenší prvek z neseřazené části a umístí ho na konec seřazené části.
Pro lepší představu se podívejme na vizuální ilustraci:

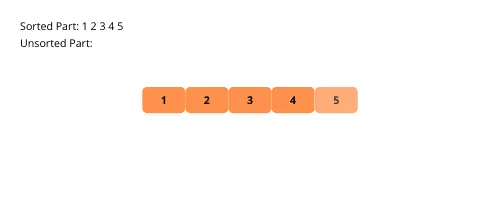
Nyní se podíváme na implementační kroky:
- Inicializujeme pole s libovolnými číselnými daty.
- Procházíme pole.
- Ukládáme index minimálního prvku.
- Vytvoříme cyklus, který iteruje od aktuálního prvku do posledního.
- Porovnáváme aktuální prvek s minimálním prvkem.
- Pokud je aktuální prvek menší než minimum, aktualizujeme index.
- Zaměníme aktuální prvek s prvkem na minimálním indexu.
Časová složitost třídění výběrem je O(n^2) a prostorová O(1).
Algoritmus je podobný třídění vkládáním, níže najdete jeho implementaci.
def selection_sort(arr, n): for i in range(n): ## uložení indexu minimálního prvku min_element_index = i for j in range(i + 1, n): ## kontrola a nahrazení indexu minimálního prvku if arr[j] < arr[min_element_index]: min_element_index = j ## výměna aktuálního prvku s minimálním prvkem arr[i], arr[min_element_index] = arr[min_element_index], arr[i] if __name__ == '__main__': ## inicializace pole arr = [3, 4, 7, 8, 1, 9, 5, 2, 6] selection_sort(arr, 9) ## výpis pole print(str(arr))
Bublinkové třídění (Bubble Sort)
Bublinkové třídění je jednoduchý algoritmus, který opakovaně zaměňuje sousední prvky, dokud není pole seřazené. V každé iteraci se posouvá aktuální prvek na další pozici, dokud není menší než následující prvek.
Pro vizuální pochopení algoritmu se podívejte na následující obrázky:

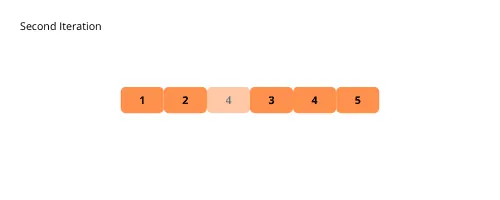
Nyní se podíváme na implementační kroky:
Časová složitost bublinkového třídění je O(n^2) a prostorová O(1).
Implementace je poměrně jednoduchá, podívejme se na kód:
def bubble_sort(arr, n): for i in range(n): ## iterace od 0 do n-i-1, jelikož posledních i prvků je již seřazeno for j in range(n - i - 1): ## kontrola následujícího prvku if arr[j] > arr[j + 1]: ## výměna sousedních prvků arr[j], arr[j + 1] = arr[j + 1], arr[j] if __name__ == '__main__': ## inicializace pole arr = [3, 4, 7, 8, 1, 9, 5, 2, 6] bubble_sort(arr, 9) ## výpis pole print(str(arr))
Třídění slučováním (Merge Sort)
Třídění slučováním je rekurzivní algoritmus, který je efektivnější než předchozí algoritmy z hlediska časové složitosti. Využívá metodu rozděl a panuj. Algoritmus rozdělí pole na dvě poloviny, které se samostatně seřadí a následně sloučí do jednoho seřazeného pole.
Jelikož se jedná o rekurzivní algoritmus, pole se dělí, dokud se nedostane do nejjednodušší podoby (jednoprvkové pole), které je triviálně seřazené.
Podívejme se na vizuální ukázku:
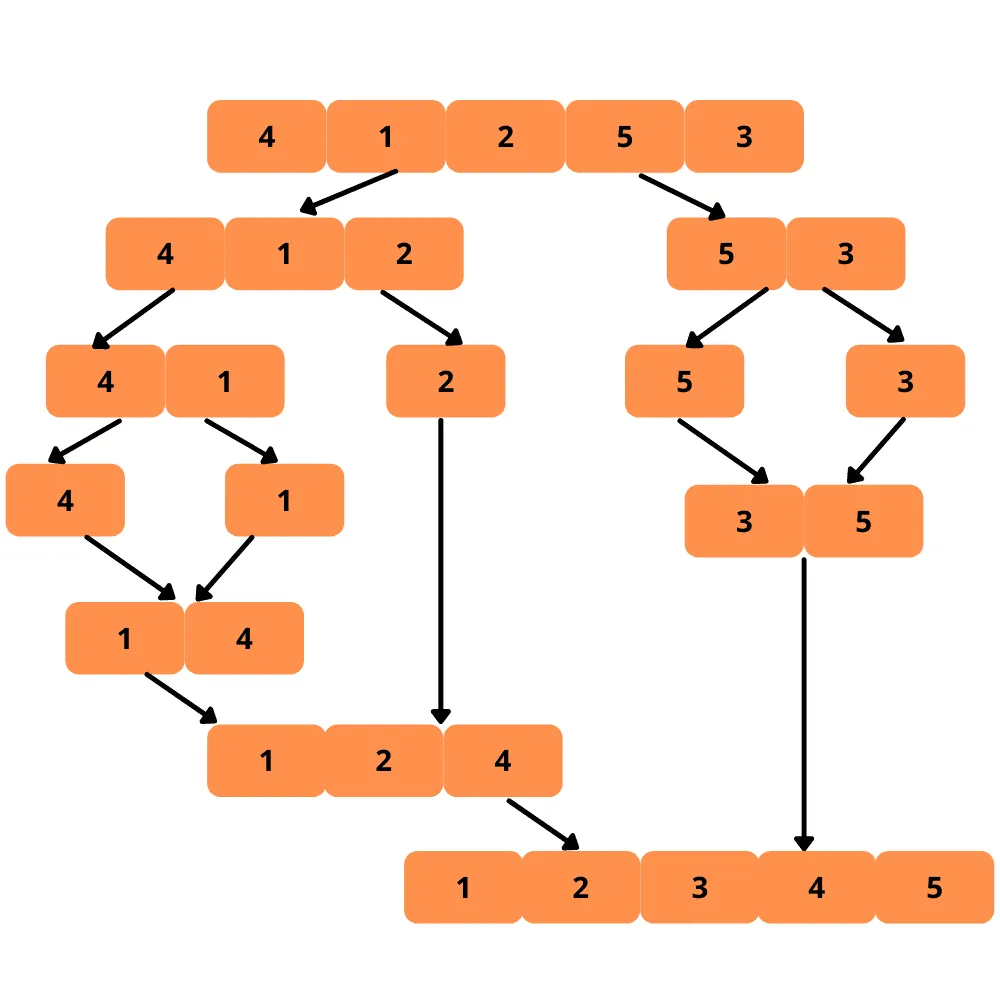
Nyní se podíváme na implementační kroky:
- Inicializujeme pole s libovolnými číselnými daty.
- Vytvoříme funkci `merge`, která sloučí podpole do jednoho seřazeného pole. Parametry funkce jsou pole, levý, střední a pravý index.
- Získáme délky levého a pravého podpole.
- Zkopírujeme prvky z pole do odpovídajících levých a pravých polí.
- Procházíme obě podpole.
- Porovnáme dva prvky podpolí.
- Nahradíme prvek v původním poli menším z obou prvků pro zachování seřazení.
- Zkontrolujeme, zda nezůstaly nějaké prvky v obou podpolích a případně je přidáme do pole.
- Vytvoříme funkci `merge_sort` s parametry pole, levý a pravý index.
- Pokud je levý index větší nebo roven pravému, vrátíme se.
- Najdeme středový bod pole a rozdělíme ho na dvě poloviny.
- Rekurzivně voláme funkci `merge_sort` pro levou a pravou polovinu.
- Po rekurzivních voláních sloučíme pole pomocí funkce `merge`.
Časová složitost třídění slučováním je O(n log n) a prostorová O(1).
Implementaci tohoto algoritmu naleznete níže.
def merge(arr, left_index, mid_index, right_index): ## levé a pravé pole left_array = arr[left_index:mid_index+1] right_array = arr[mid_index+1:right_index+1] ## ziskání délky levého a pravého pole left_array_length = mid_index - left_index + 1 right_array_length = right_index - mid_index ## indexy pro slučování dvou polí i = j = 0 ## index pro nahrazování prvků pole k = left_index ## iterace přes dvě podpole while i < left_array_length and j < right_array_length: ## porovnání prvků z levého a pravého pole if left_array[i] < right_array[j]: arr[k] = left_array[i] i += 1 else: arr[k] = right_array[j] j += 1 k += 1 ## přidání zbývajících prvků z levého a pravého pole while i < left_array_length: arr[k] = left_array[i] i += 1 k += 1 while j < right_array_length: j += 1 k += 1 def merge_sort(arr, left_index, right_index): ## základní případ pro rekurzivní funkci if left_index >= right_index: return ## hledání středového indexu mid_index = (left_index + right_index) // 2 ## rekurzivní volání merge_sort(arr, left_index, mid_index) merge_sort(arr, mid_index + 1, right_index) ## slučování dvou podpolí merge(arr, left_index, mid_index, right_index) if __name__ == '__main__': ## inicializace pole arr = [3, 4, 7, 8, 1, 9, 5, 2, 6] merge_sort(arr, 0, 8) ## výpis pole print(str(arr))
Závěr
Existuje velké množství dalších třídicích algoritmů, ale výše uvedené patří mezi ty nejčastěji používané. Doufám, že vám tento přehled algoritmů byl užitečný.
V budoucnu se budeme věnovat vyhledávacím algoritmům.
Šťastné kódování 🙂 👨💻
