
V dnešním světě založeném na datech je tradiční metoda ručního sběru dat zastaralá. Počítač s připojením k internetu na každém stole udělal z webu obrovský zdroj dat. Efektivnější a časově úspornější moderní metodou sběru dat je tedy web scraping. A pokud jde o škrábání webu, Python má nástroj nazvaný Krásná polévka. V tomto příspěvku vás provedu kroky instalace Krásné polévky, abyste mohli začít se škrábáním webu.
Před instalací a prací s Beautiful Soup si pojďme zjistit, proč byste do toho měli jít.
Table of Contents
Co je to krásná polévka?
Předpokládejme, že zkoumáte „Vliv COVIDu na zdraví lidí“ a našli jste několik webových stránek obsahujících relevantní data. Ale co když vám nenabídnou možnost stažení jedním kliknutím a vypůjčit si svá data? Zde přichází na řadu Krásná polévka.
Beautiful Soup je jedním z indexů knihoven Pythonu pro získávání dat z cílových stránek. Pohodlnější je načítání dat z HTML nebo XML stránek.
Leonard Richardson přinesl myšlenku Krásné polévky pro seškrabování webu na světlo v roce 2004. Jeho příspěvek k projektu však pokračuje dodnes. Hrdě aktualizuje každé nové vydání Beautiful Soup na svém Twitteru.
Přestože byl Beautiful Soup for web scraping vyvinut pomocí Pythonu 3.8, funguje perfektně jak s Pythonem 3, tak s Pythonem 2.4.
Webové stránky často používají ochranu captcha k záchraně svých dat z nástrojů AI. V tomto případě může několik změn v hlavičce „user-agent“ v Beautiful Soup nebo pomocí rozhraní API pro řešení Captcha napodobit spolehlivý prohlížeč a oklamat detekční nástroj.
Pokud však nemáte čas prozkoumávat Krásnou polévku nebo chcete, aby se škrábání provádělo efektivně a snadno, pak byste si neměli nechat ujít toto rozhraní API pro škrábání webu, kde stačí zadat URL a získat data do tvé ruce.
Pokud jste již programátor, použití Beautiful Soup pro scraping nebude skličující, protože má přímočarou syntaxi při procházení webových stránek a extrahování požadovaných dat na základě podmíněné analýzy. Zároveň je přátelský i pro nováčky.
Přestože Beautiful Soup není pro pokročilé škrábání, funguje nejlépe škrábání dat ze souborů napsaných ve značkovacích jazycích.
Jasná a podrobná dokumentace je dalším bodem sušenky, který Beautiful Soup zabalil.
Pojďme najít snadný způsob, jak dostat krásnou polévku do vašeho stroje.
Jak nainstalovat krásnou polévku pro škrábání webu?
Pip – Snadný správce balíčků Python vyvinutý v roce 2008 je nyní mezi vývojáři standardním nástrojem pro instalaci libovolných knihoven Pythonu nebo závislostí.
Pip je standardně dodáván s instalací posledních verzí Pythonu. Pokud tedy máte na svém systému nainstalované nějaké nedávné verze Pythonu, můžete začít.
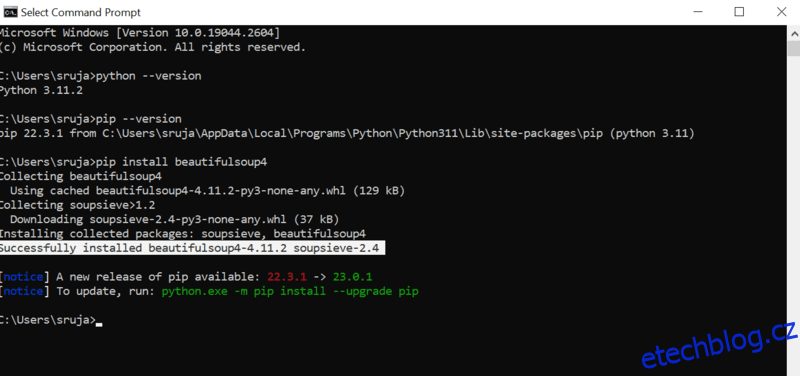
Otevřete příkazový řádek a zadejte následující příkaz pip pro okamžitou instalaci krásné polévky.
pip install beautifulsoup4
Na displeji uvidíte něco podobného jako na následujícím snímku obrazovky.
Ujistěte se, že jste aktualizovali instalační program PIP na nejnovější verzi, abyste předešli běžným chybám.
Příkaz pro aktualizaci instalátoru pip na nejnovější verzi je:
pip install --upgrade pip
V tomto příspěvku jsme úspěšně pokryli polovinu země.
Nyní máte na svém počítači nainstalovanou polévku Beautiful Soup, takže se pojďme ponořit do toho, jak ji použít pro škrábání webu.
Jak importovat a pracovat s krásnou polévkou pro škrábání webu?
Chcete-li importovat krásnou polévku do aktuálního skriptu pythonu, zadejte do svého python IDE následující příkaz.
from bs4 import BeautifulSoup
Nyní je Krásná polévka ve vašem souboru Python a můžete ji použít pro seškrabování.
Podívejme se na příklad kódu, abychom se naučili, jak extrahovat požadovaná data pomocí krásné polévky.
Můžeme říct krásné polévce, aby hledala konkrétní značky HTML na zdrojovém webu a seškrábala data přítomná v těchto značkách.
V tomto díle budu používat marketwatch.com, který aktualizuje ceny akcií různých společností v reálném čase. Vyberme si některá data z tohoto webu, abyste se seznámili s knihovnou Krásná polévka.
Importujte balíček „requests“, který nám umožní přijímat a reagovat na požadavky HTTP, a „urllib“ pro načtení webové stránky z její adresy URL.
from urllib.request import urlopen import requests
Uložte odkaz na webovou stránku do proměnné, abyste k němu měli později snadný přístup.
url="https://www.marketwatch.com/investing/stock/amzn"
Dalším by bylo použití metody „urlopen“ z knihovny „urllib“ k uložení stránky HTML do proměnné. Předejte URL funkci „urlopen“ a uložte výsledek do proměnné.
page = urlopen(url)
Vytvořte objekt Beautiful Soup a analyzujte požadovanou webovou stránku pomocí „html.parser“.
soup_obj = BeautifulSoup(page, 'html.parser')
Nyní je celý HTML skript cílené webové stránky uložen v proměnné ‚soup_obj‘.
Než budeme pokračovat, podívejme se na zdrojový kód cílené stránky, abychom se dozvěděli více o skriptu HTML a značkách.
Klepněte pravým tlačítkem myši kdekoli na webové stránce. Poté najdete možnost kontroly, jak je zobrazeno níže.
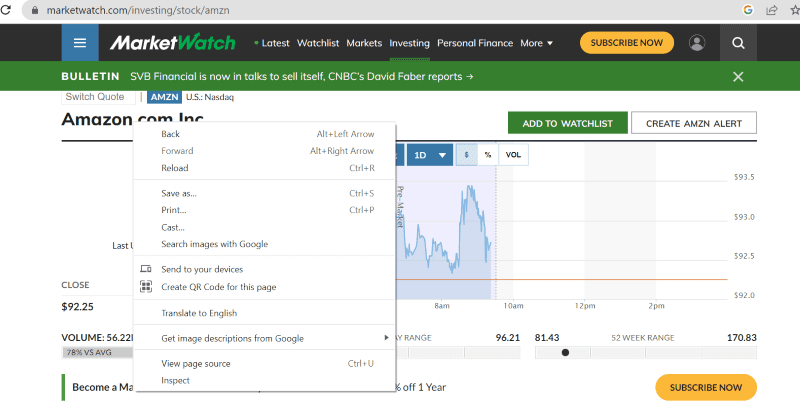
Kliknutím na prozkoumat zobrazíte zdrojový kód.
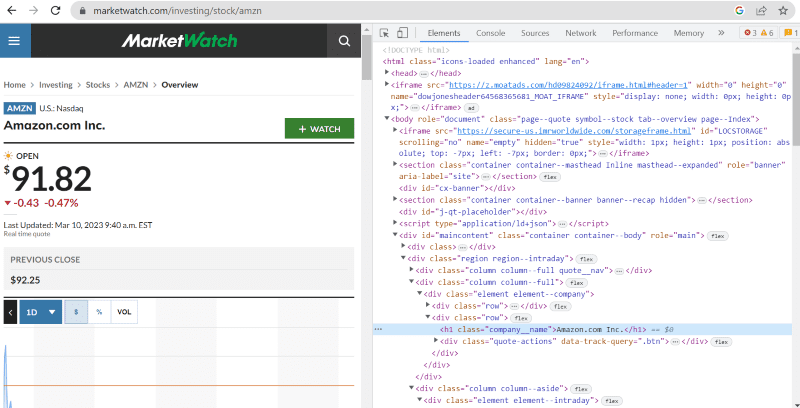
Ve výše uvedeném zdrojovém kódu můžete najít značky, třídy a konkrétnější informace o každém prvku viditelném na rozhraní webu.
Metoda „najít“ v krásné polévce nám umožňuje vyhledat požadované HTML tagy a získat data. Za tímto účelem dáme metodě, která extrahuje konkrétní data, název třídy a značky.
Například „Amazon.com Inc.“ zobrazený na webové stránce má název třídy: ‚company__name‘ označený pod ‚h1‘. Tyto informace můžeme vložit do metody ‚najít‘ a extrahovat příslušný fragment HTML do proměnné.
name = soup_obj.find('h1', attrs={'class': 'company__name'})
Vypíšeme HTML skript uložený v proměnné „name“ a požadovaný text na obrazovku.
print(name) print(name.text)

Extrahovaná data můžete sledovat vytištěná na obrazovce.
Web Scrape web IMDb
Mnozí z nás před zhlédnutím filmu hledají hodnocení filmů na stránkách IMBb. Tato ukázka vám poskytne seznam nejlépe hodnocených filmů a pomůže vám zvyknout si na krásnou polévku pro seškrabování z webu.
Krok 1: Importujte krásné knihovny polévek a požadavků.
from bs4 import BeautifulSoup import requests
Krok 2: Přiřaďme adresu URL, kterou chceme seškrábat, do proměnné nazvané „url“ pro snadný přístup v kódu.
Balíček „requests“ se používá k získání stránky HTML z adresy URL.
url = requests.get('https://www.imdb.com/search/title/?count=100&groups=top_1000&sort=user_rating')
Krok 3: V následujícím úryvku kódu analyzujeme stránku HTML aktuální adresy URL, abychom vytvořili objekt krásné polévky.
soup_obj = BeautifulSoup(url.text, 'html.parser')
Proměnná „soup_obj“ nyní obsahuje celý HTML skript požadované webové stránky, jako na následujícím obrázku.
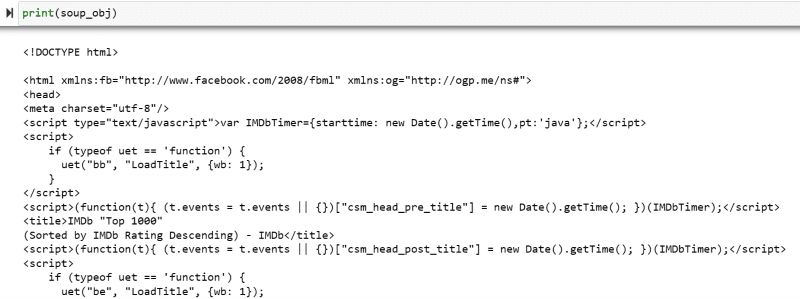
Prozkoumáme zdrojový kód webové stránky, abychom našli HTML skript dat, která chceme seškrábat.
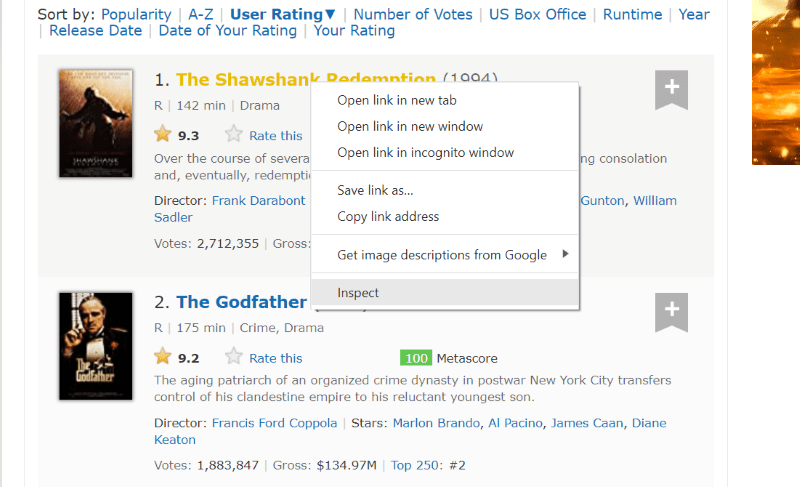
Najeďte kurzorem na prvek webové stránky, který chcete extrahovat. Dále na něj klikněte pravým tlačítkem myši a přejděte na možnost prohlédnout a zobrazte zdrojový kód tohoto konkrétního prvku. Lépe vás navedou následující vizuály.
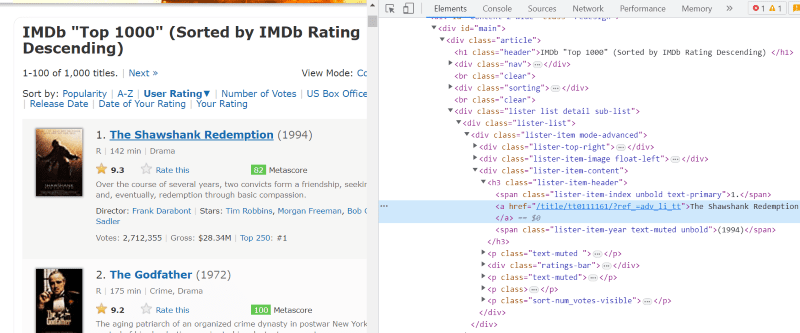
Třída ‚lister-list‘ obsahuje všechna nejlépe hodnocená data související s filmem jako pododdělení v po sobě jdoucích značkách div.
Ve skriptu HTML každé filmové karty pod třídou ‚lister-item mode-advanced‘ máme značku ‚h3‘, která ukládá název filmu, hodnocení a rok vydání, jak je zvýrazněno na obrázku níže.
Poznámka: Metoda „najít“ v krásné polévce vyhledává první značku, která odpovídá vstupnímu názvu, který jí byl přidělen. Na rozdíl od „find“ metoda „find_all“ hledá všechny tagy, které odpovídají danému vstupu.
Krok 4: Pomocí metod „find“ a „find_all“ můžete uložit HTML skript každého názvu, hodnocení a roku filmu do proměnné seznamu.
top_movies = soup_obj.find('div',attrs={'class': 'lister-list'}).find_all('h3')
Krok 5: Projděte seznam filmů uložených v proměnné: „top_movies“ a pomocí níže uvedeného kódu extrahujte název, pořadí a rok každého filmu v textovém formátu z jeho HTML skriptu.
for movie in top_movies:
movi_name = movie.a.text
rank = movie.span.text.rstrip('.')
year = movie.find('span', attrs={'class': 'lister-item-year text-muted unbold'})
year = year.text.strip('()')
print(movi_name + " ", rank+ " ", year+ " ")
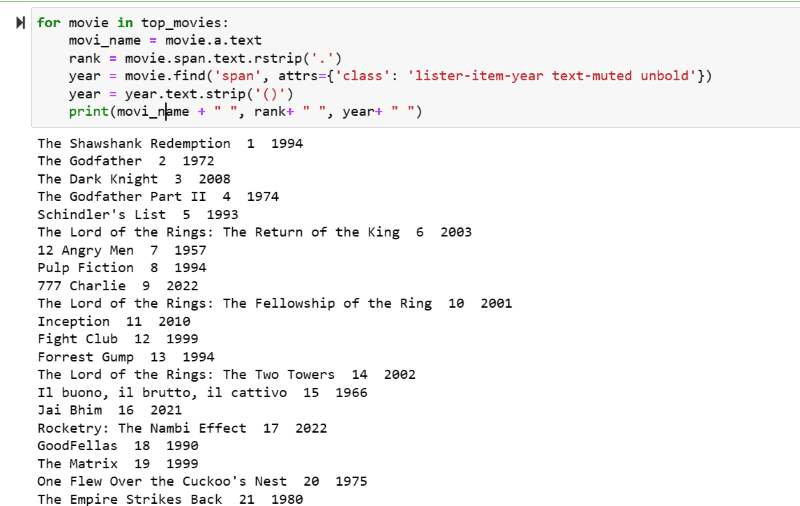
Na výstupním snímku obrazovky můžete vidět seznam filmů s jejich názvem, hodností a rokem vydání.
Vytištěná data můžete bez námahy přesunout do excelového listu s nějakým kódem pythonu a použít je pro svou analýzu.
Závěrečná slova
Tento příspěvek vás provede instalací krásné polévky pro škrábání webu. Také příklady škrábání, které jsem ukázal, by vám měly pomoci začít s Krásnou polévkou.
Protože vás zajímá, jak nainstalovat Beautiful Soup pro web scraping, vřele doporučuji, abyste si prohlédli tohoto srozumitelného průvodce, kde se dozvíte více o web scraping pomocí Pythonu.