
Agregační kanál je doporučený způsob spouštění složitých dotazů v MongoDB. Pokud jste používali MapReduce od MongoDB, raději přepněte na agregační kanál pro efektivnější výpočty.
Table of Contents
Co je agregace v MongoDB a jak to funguje?
Agregační kanál je vícestupňový proces pro spouštění pokročilých dotazů v MongoDB. Zpracovává data prostřednictvím různých fází nazývaných potrubí. Výsledky vygenerované z jedné úrovně můžete použít jako šablonu operace v jiné.
Můžete například předat výsledek operace shody do jiné fáze pro třídění v tomto pořadí, dokud nezískáte požadovaný výstup.
Každá fáze agregačního kanálu obsahuje operátora MongoDB a generuje jeden nebo více transformovaných dokumentů. V závislosti na vašem dotazu se úroveň může objevit vícekrát v kanálu. Například možná budete muset použít fáze operátoru $count nebo $sort více než jednou v agregačním kanálu.
Fáze agregačního potrubí
Agregační kanál předává data několika fázemi v jediném dotazu. Existuje několik fází a jejich podrobnosti najdete v MongoDB dokumentace.
Níže definujeme některé z nejčastěji používaných.
$match Stage
Tato fáze vám pomůže definovat konkrétní podmínky filtrování před zahájením dalších fází agregace. Můžete jej použít k výběru odpovídajících dat, která chcete zahrnout do agregačního kanálu.
$group Stage
Fáze skupiny rozděluje data do různých skupin na základě specifických kritérií pomocí párů klíč–hodnota. Každá skupina představuje klíč ve výstupním dokumentu.
Zvažte například následující ukázková data prodeje:
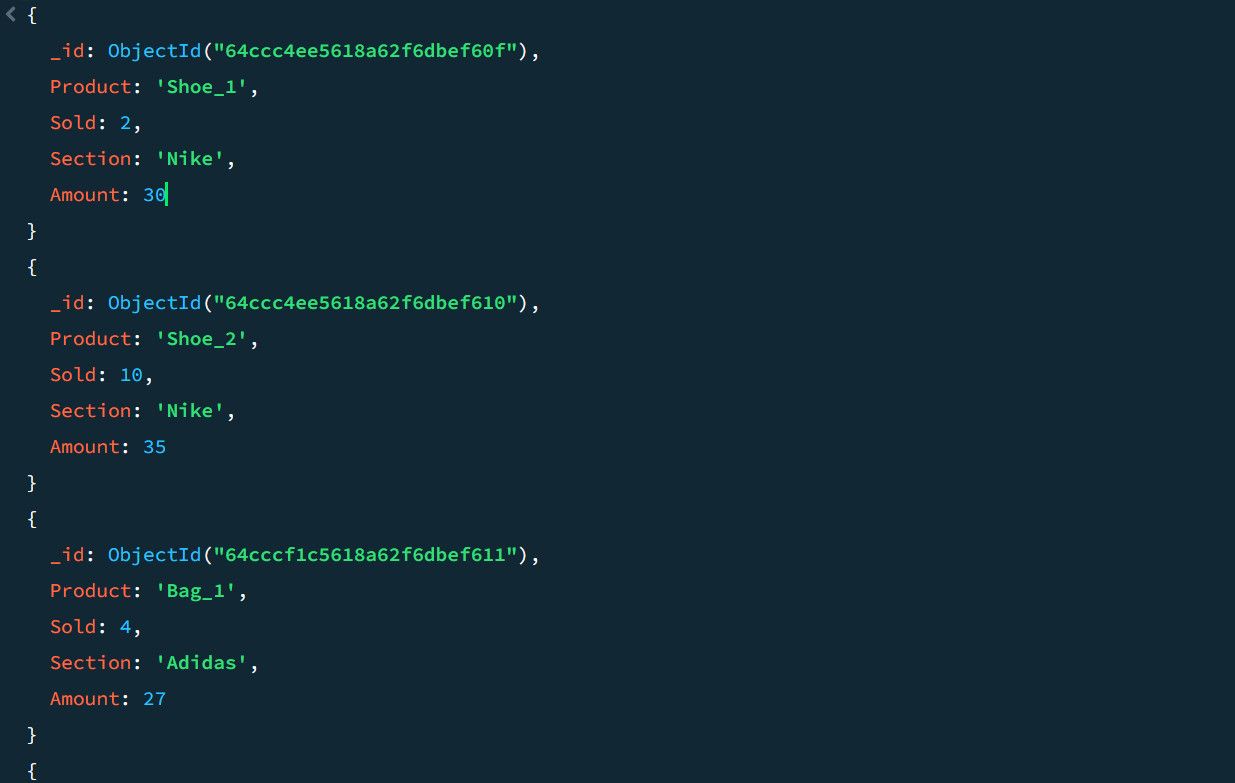
Pomocí agregačního kanálu můžete vypočítat celkový počet prodejů a nejvyšší prodeje pro každou sekci produktu:
{
$group: {
_id: $Section,
total_sales_count: {$sum : $Sold},
top_sales: {$max: $Amount},
}
}
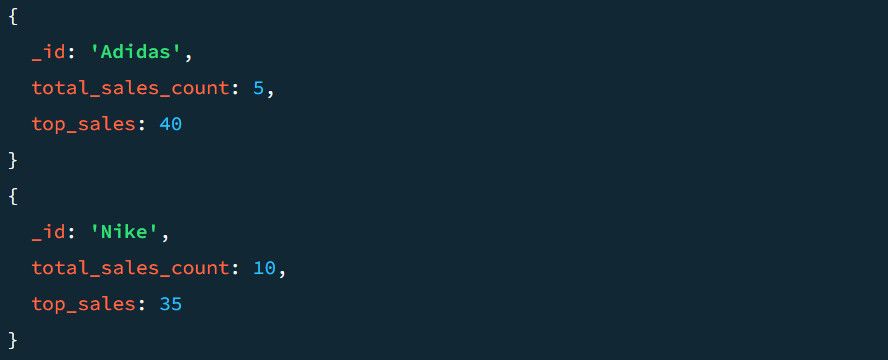
Dvojice _id: $Section seskupuje výstupní dokument na základě sekcí. Zadáním polí top_sales_count a top_sales vytvoří MongoDB nové klíče na základě operace definované agregátorem; to může být $sum, $min, $max nebo $avg.
$skip Stage
Fázi $skip můžete použít k vynechání zadaného počtu dokumentů ve výstupu. Obvykle to přichází po skupinové fázi. Pokud například očekáváte dva výstupní dokumenty, ale jeden přeskočíte, agregace vytiskne pouze druhý dokument.
Chcete-li přidat fázi přeskočení, vložte operaci $skip do agregačního kanálu:
...,
{
$skip: 1
},
Fáze $sort
Fáze řazení vám umožňuje uspořádat data v sestupném nebo vzestupném pořadí. Například můžeme dále seřadit data v předchozím příkladu dotazu v sestupném pořadí, abychom určili, která sekce má nejvyšší prodeje.
Přidejte operátor $sort k předchozímu dotazu:
...,
{
$sort: {top_sales: -1}
},
$limit Stage
Operace omezení pomáhá snížit počet výstupních dokumentů, které má agregační kanál zobrazovat. Například pomocí operátoru $limit získáte sekci s nejvyšším prodejem vráceným předchozí fází:
...,
{
$sort: {top_sales: -1}
},{"$limit": 1}
Výše uvedené vrátí pouze první dokument; toto je sekce s nejvyšším prodejem, jak se objevuje v horní části seřazeného výstupu.
$projektová fáze
Fáze $project vám umožňuje tvarovat výstupní dokument tak, jak chcete. Pomocí operátoru $project můžete určit, které pole má být zahrnuto do výstupu, a přizpůsobit jeho název klíče.
Například ukázkový výstup bez fáze $project vypadá takto:
Pojďme se podívat, jak to vypadá s $project stage. Chcete-li přidat projekt $ do kanálu:
...,{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",}
}
Protože jsme dříve seskupovali data podle sekcí produktu, výše uvedené zahrnuje každou sekci produktu ve výstupním dokumentu. Zajišťuje také, že agregovaný počet prodejů a nejvyšší prodeje jsou ve výstupu uvedeny jako TotalSold a TopSale.
Konečný výstup je mnohem čistší ve srovnání s předchozím:

Fáze $unwind
Fáze $unwind rozloží pole v dokumentu na jednotlivé dokumenty. Vezměte si například následující údaje o objednávkách:
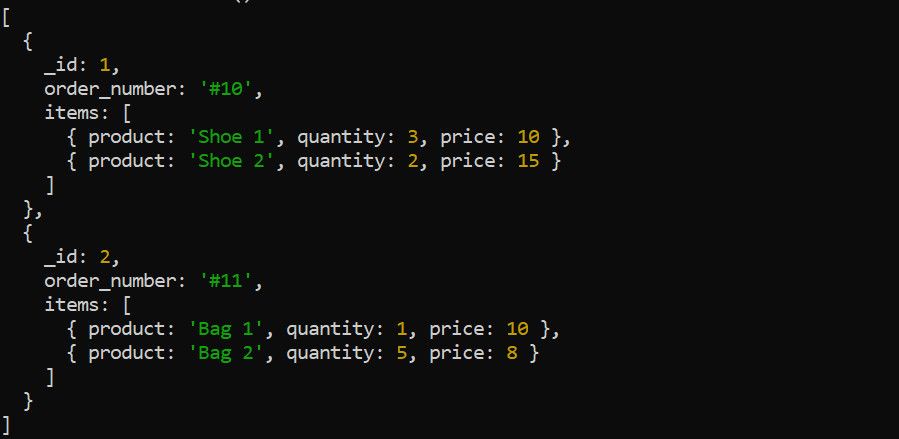
Pomocí fáze $unwind dekonstruujte pole položek před použitím dalších fází agregace. Například rozbalení pole položek má smysl, pokud chcete vypočítat celkový příjem pro každý produkt:
db.Orders.aggregate(
[
{
"$unwind": "$items"
},
{
"$group": {
"_id": "$items.product",
"total_revenue": { "$sum": { "$multiply": ["$items.quantity", "$items.price"] } }
}
},
{
"$sort": { "total_revenue": -1 }
},{
"$project": {
"_id": 0,
"Product": "$_id",
"TotalRevenue": "$total_revenue",}
}
])
Zde je výsledek výše uvedeného agregačního dotazu:

Jak vytvořit agregační kanál v MongoDB
Zatímco kanál agregace zahrnuje několik operací, dříve uvedené fáze vám poskytnou představu o tom, jak je v potrubí použít, včetně základního dotazu pro každou z nich.
Pomocí předchozího vzorku dat o prodeji si ukažme některé z výše uvedených fází v jednom kuse, abychom získali širší pohled na agregační kanál:
db.sales.aggregate([{
"$match": {
"Sold": { "$gte": 5 }
}
},{
"$group": {
"_id": "$Section",
"total_sales_count": { "$sum": "$Sold" },
"top_sales": { "$max": "$Amount" },
}},
{
"$sort": { "top_sales": -1 }
},{"$skip": 0},
{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",}
}
])
Konečný výstup vypadá jako něco, co jste viděli dříve:
Agregation Pipeline vs. MapReduce
Až do ukončení podpory od MongoDB 5.0 byl konvenčním způsobem agregace dat v MongoDB přes MapReduce. Ačkoli MapReduce má širší aplikace nad rámec MongoDB, je méně efektivní než agregační kanál a vyžaduje skriptování třetích stran k samostatnému psaní mapy a redukci funkcí.
Na druhé straně agregační kanál je specifický pouze pro MongoDB. Poskytuje však čistší a efektivnější způsob provádění složitých dotazů. Kromě jednoduchosti a škálovatelnosti dotazů umožňují jednotlivé fáze kanálu výstup lépe přizpůsobit.
Mezi agregačním kanálem a MapReduce je mnohem více rozdílů. Uvidíte je, když přepnete z MapReduce na agregační kanál.
Zefektivněte dotazy na velká data v MongoDB
Pokud chcete provádět hloubkové výpočty na komplexních datech v MongoDB, musí být váš dotaz co nejefektivnější. Agregační kanál je ideální pro pokročilé dotazování. Namísto manipulace s daty v samostatných operacích, které často snižují výkon, vám agregace umožňuje sbalit je všechna do jednoho výkonného kanálu a provést je jednou.
Zatímco agregační kanál je efektivnější než MapReduce, můžete agregaci zrychlit a zefektivnit indexováním dat. To omezuje množství dat, které MongoDB potřebuje ke skenování během každé fáze agregace.