

Příkazy cat a tac zobrazují obsah textových souborů, ale je v nich víc, než se na první pohled zdá. Ponořte se trochu hlouběji a naučte se pár produktivních triků příkazového řádku Linuxu.
Jsou to dva jednoduché malé příkazy, které jsou často odmítány jako takové – příliš jednoduché na to, aby byly k nějakému skutečnému použití. Jakmile se však seznámíte s různými způsoby, jak je můžete použít, uvidíte, že jsou dokonale schopné vykonávat svůj spravedlivý podíl na těžké zátěži, pokud jde o práci se soubory.
Table of Contents
Kočičí příkaz
kočka je zvyklá zkoumat obsah textových souborůa ke spojení částí souborů k vytvoření většího souboru.
Najednou — zpět v éře vytáčeného připojení modem—binární soubory byly často rozděleny na několik menších souborů, aby bylo stahování snazší. Místo stahování jednoho velkého souboru jste stáhli každý menší soubor. Pokud by se nepodařilo správně stáhnout jeden soubor, znovu byste načetli tento jeden soubor.
Samozřejmě jste pak potřebovali způsob, jak rekonstruovat kolekci menších souborů zpět do jediného funkčního binárního souboru. Tento proces se nazýval zřetězení. A odtud přišla kočka a odtud dostala své jméno.
Širokopásmová a optická připojení způsobila, že tato zvláštní potřeba vybledla – podobně jako skřípavé zvuky vytáčeného připojení – takže co dnes kočce zbývá? Vlastně docela hodně.
Zobrazení textového souboru
Chcete-li, aby cat vypsal obsah textového souboru do okna terminálu, použijte následující příkaz.
Ujistěte se, že soubor je textový soubor. Pokud se pokusíte vypsat obsah binárního souboru do okna terminálu, výsledky budou nepředvídatelné. Můžete skončit s uzamčenou relací terminálu nebo ještě hůř.
cat poem1.txt

Obsah souboru poem1.txt se zobrazí v okně terminálu.
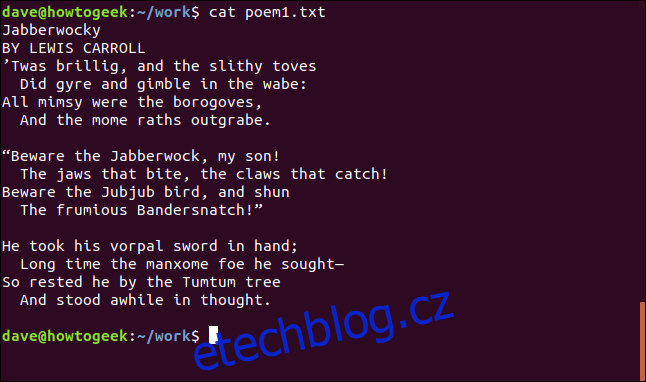
To je jen polovina slavné básně. Kde je zbytek? Je zde další soubor s názvem poem2.txt. Jedním příkazem můžeme vytvořit seznam cat vypsat obsah více souborů. Vše, co musíme udělat, je vypsat soubory v pořadí na příkazovém řádku.
cat poem1.txt poem2.txt

To vypadá lépe; už máme celou báseň.

Používání kočky s méně
Báseň je tam celá, ale proletěla oknem příliš rychle, než aby přečetla prvních pár veršů. Můžeme propojit výstup z cat do less a posouvat se dolů v textu vlastním tempem.
cat poem1.txt poem2.txt | less

Nyní se můžeme pohybovat textem vzad a vpřed v jednom proudu, i když je uložen ve dvou samostatných textových souborech.

Číslování řádků v souboru
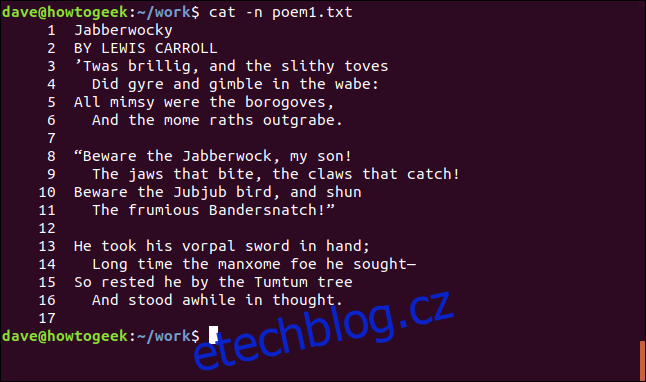
Řádky v souboru můžeme očíslovat tak, jak je zobrazen. K tomu použijeme volbu -n (číslo).
cat -n poem1.txt

Řádky jsou číslovány tak, jak jsou zobrazeny v okně terminálu.
Nečíslujte prázdné řádky
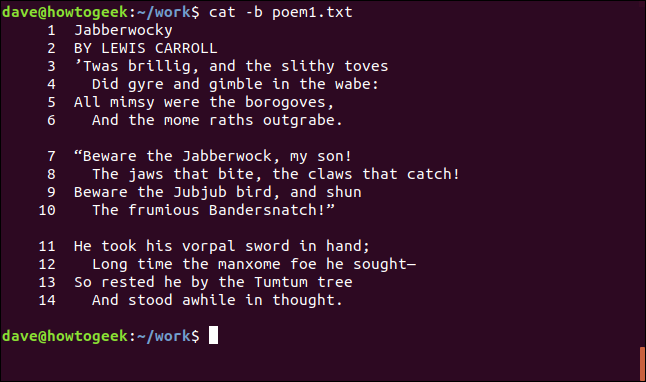
Podařilo se nám očíslovat řádky kočkou, ale počítají se i prázdné řádky mezi verši. Chcete-li mít textové řádky očíslované, ale ignorovat prázdné řádky, použijte volbu -b (číslo-neprázdné).
cat -b poem1.txt

Nyní jsou textové řádky očíslovány a prázdné řádky jsou přeskočeny.
Nezobrazovat více prázdných řádků
Pokud jsou v souboru části po sobě jdoucích prázdných řádků, můžeme požádat cat, aby ignoroval všechny kromě jednoho prázdného řádku. Podívejte se na tento soubor.
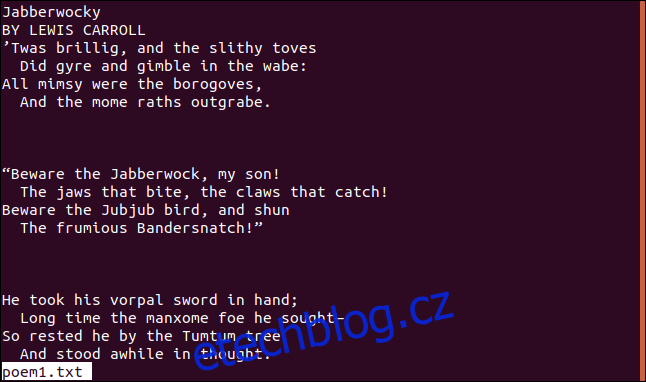
Další příkaz způsobí, že cat zobrazí pouze jeden prázdný řádek z každé skupiny prázdných řádků. Možnost, kterou k tomu potřebujeme, je volba -s (squeeze-blank).
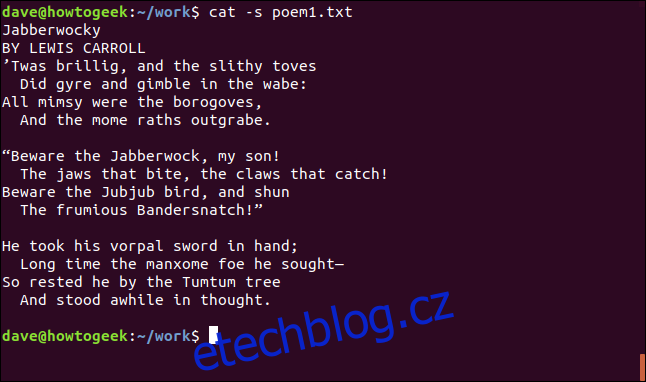
cat -s poem1.txt

To nijak neovlivní obsah souboru; jen změní způsob, jakým cat zobrazuje soubor.
Zobrazit karty
Pokud chcete vědět, zda jsou mezery způsobeny mezerami nebo tabulátory, můžete to zjistit pomocí volby -T (show-tabs).
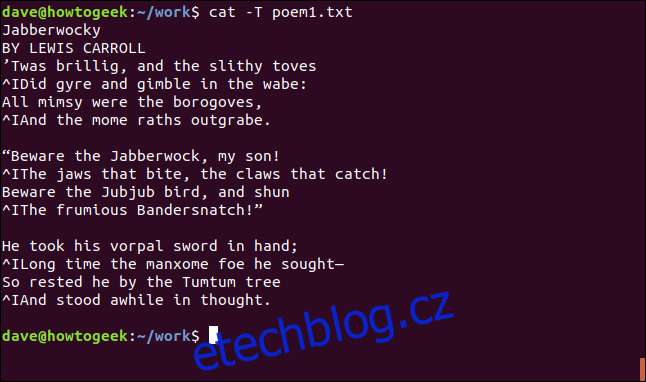
cat -T poem1.txt

Tabulátory jsou reprezentovány znaky „^I“.
Zobrazení konců řádků
Koncové mezery můžete zkontrolovat pomocí volby -E (show-ends).
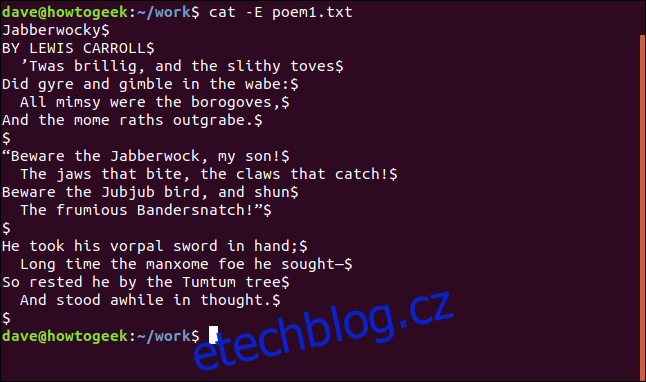
cat -E poem1.txt

Konce řádků jsou reprezentovány znakem „$“.
Zřetězení souborů
Nemá smysl mít báseň uloženou ve dvou souborech, přičemž v každém je jedna polovina. Spojme je dohromady a vytvořme nový soubor s celou básničkou.
cat poem1.txt poem2.txt > jabberwocky.txt

Náš nový soubor obsahuje obsah dalších dvou souborů.

Připojení textu k existujícímu souboru
To je lepší, ale ve skutečnosti to není celá báseň. Chybí poslední verš. Poslední verš v Jabberwocky je stejný jako první verš.
Pokud máme první verš v souboru, můžeme ho přidat na konec souboru jabberwocky.txt a budeme mít kompletní báseň.
V tomto dalším příkazu musíme použít >>, nejen >. Pokud použijeme jeden > přepíšeme jabberwocky.txt. To dělat nechceme. Chceme přidat text na konec.
cat first_verse.txt >> jabberwocky.txt

A nakonec jsou všechny části básně pohromadě.
Přesměrování stdin
Vstup z klávesnice můžete přesměrovat do souboru pomocí cat. Vše, co zadáte, je přesměrováno do souboru, dokud nestisknete Ctrl+D. Všimněte si, že používáme jeden >, protože chceme soubor vytvořit (nebo jej přepsat, pokud existuje).
cat > my_poem.txt

Ten zvuk jako vzdálená turbína je pravděpodobně Lewis Carroll točící se v hrobě vysokou rychlostí.
Příkaz tac
tac je podobný cat, ale uvádí obsah souborů v opačném pořadí.
Podívejme se na to:
tac my_poem.txt

A soubor se zobrazí v okně terminálu v opačném pořadí. V tomto případě to nemá žádný vliv na jeho literární zásluhy.
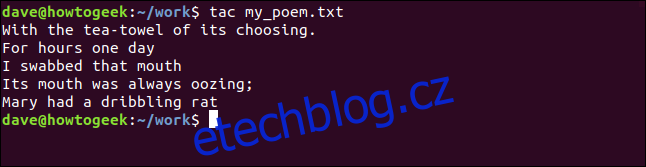
Použití tac s stdin
Použití tac bez názvu souboru způsobí, že bude fungovat na vstupu z klávesnice. Stisknutím Ctrl+D zastavíte vstupní fázi a tac zobrazí v opačném pořadí vše, co jste zadali.
tac

Po stisknutí Ctrl+D se vstup obrátí a zobrazí se v okně terminálu.
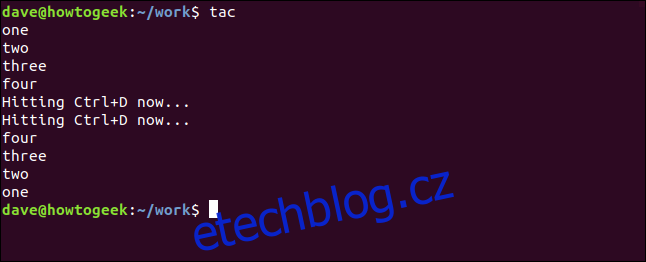
Použití tac With Log Files
Může tac kromě triků v salonu dělat něco užitečného? Ano, může. Mnoho souborů protokolu připojuje své nejnovější položky na konec souboru. Pomocí tac (a v rozporu s intuicí i hlavy) můžeme otevřít poslední položku do okna terminálu.
Použijeme tac k vypsání souboru syslog obráceně a vložíme jej do hlavy. Když řeknete hlavě, aby vytiskla pouze první řádek, který obdrží (který je díky tac posledním řádkem v souboru), uvidíme nejnovější záznam v souboru syslog.
tac /var/log/syslog | head -1

head vytiskne nejnovější záznam ze souboru syslog a poté skončí.
Všimněte si, že hlava tiskne pouze jeden řádek – jak jsme požadovali – ale řádek je tak dlouhý, že se obtáčí dvakrát. Proto to vypadá jako tři řádky výstupu v okně terminálu.
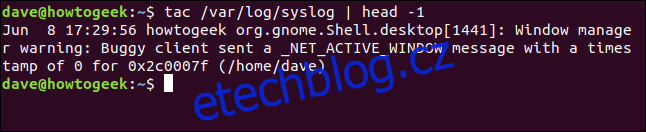
Použití tac s textovými záznamy
Poslední trik, který má v rukávu, je krása.
Tac obvykle pracuje s textovými soubory tak, že je prochází řádek po řádku, zdola nahoru. Řádek je posloupnost znaků ukončená znakem nového řádku. Ale můžeme říct tac, aby pracovala s jinými oddělovači. To nám umožňuje zacházet s „kusy“ dat v textovém souboru jako s datovými záznamy.
Řekněme, že máme soubor protokolu z nějakého programu, který potřebujeme zkontrolovat nebo analyzovat. Pojďme se podívat na jeho formát s méně.
less logfile.dat

Jak vidíme, soubor má opakující se formát. Existují sekvence tří řádků hexadecimální hodnoty. Každá sada tří šestnáctkových řádků má řádek štítku, který začíná „=SEQ“, za nímž následuje sekvence číslic.
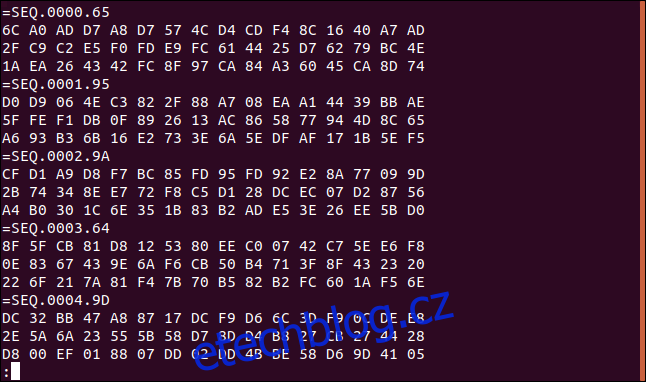
Pokud se posuneme na konec souboru, můžeme vidět, že těchto záznamů je hodně. Poslední má číslo 865.
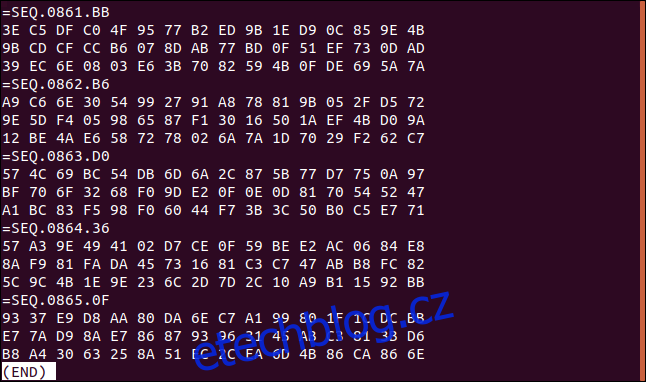
Předpokládejme, že z jakéhokoli důvodu potřebujeme pracovat s tímto souborem v opačném pořadí, záznam dat po záznamu. Pořadí řádků tří hexadecimálních řádků v každém datovém záznamu musí být zachováno.
Všimneme si, že poslední tři řádky v souboru začínají hexadecimálními hodnotami 93, E7 a B8 v tomto pořadí.
Použijme tac k obrácení souboru. Je to velmi dlouhý soubor, takže jej zařadíme do méně.
tac logfile.dat | less

To obrátí soubor, ale není to výsledek, který chceme. Chceme, aby byl soubor obrácen, ale řádky v každém datovém záznamu musí být v původním pořadí.
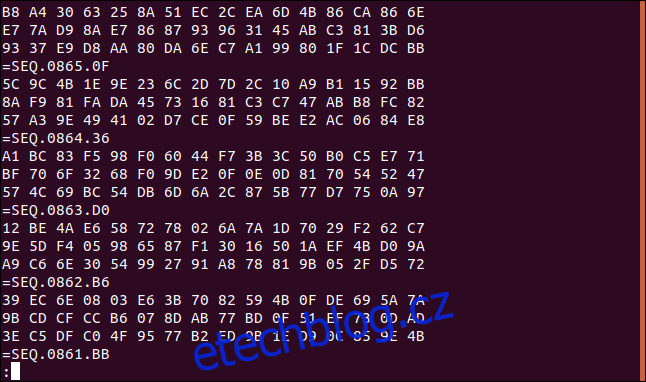
Již dříve jsme zaznamenali, že poslední tři řádky v souboru začínají hexadecimálními hodnotami 93, E7 a B8 v tomto pořadí. Pořadí těchto řádků bylo obráceno. Také řádky „=SEQ“ jsou nyní pod každou sadou tří hexadecimálních řádků.
tak k záchraně.
tac -b -r -s ^=SEQ.+[0-9]+*$ logfile.dat | less

Pojďme to rozebrat.
Volba -s (oddělovač) informuje tac, co chceme použít jako oddělovač mezi našimi záznamy. Říká tac, aby nepoužíval svůj obvyklý znak nového řádku, ale místo toho použil náš oddělovač.
Volba -r (regulární výraz) říká tac, aby s oddělovacím řetězcem zacházel jako s a regulární výraz.
Volba -b (před) způsobí, že tac vypíše oddělovač před každým záznamem místo za ním (což je obvyklá pozice jeho výchozího oddělovače, znaku nového řádku).
Řetězec -s (oddělovač) ^=SEKV.+[0-9]+*$ se dešifruje takto:
Znak ^ představuje začátek řádku. Následuje =SEKV.+[0-9]+*$. To instruuje tac, aby hledal každý výskyt "=SEQ." na začátku řádku, za kterým následuje libovolná posloupnost číslic (označená pomocí [0-9]) a následuje jakákoli další sada znaků (označená *$).
Jako obvykle dáváme všechno do méně peněz.
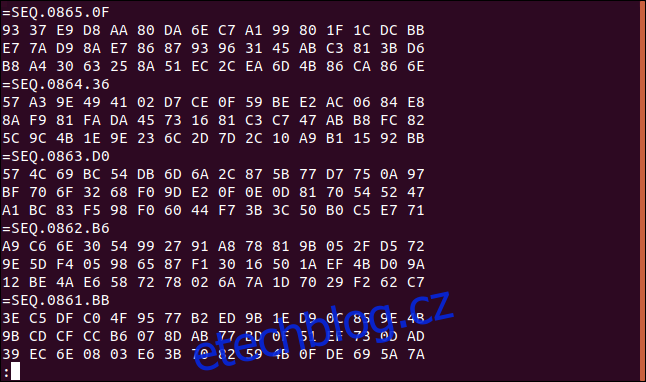
Náš soubor je nyní prezentován v obráceném pořadí, přičemž každý řádek štítku „=SEQ“ je uveden před jeho třemi řádky hexadecimálních dat. Tři řádky hexadecimálních hodnot jsou v každém datovém záznamu v původním pořadí.
Můžeme to jednoduše zkontrolovat. První hodnota prvních tří řádků šestnáctkové soustavy (což byly poslední tři řádky před obrácením souboru) se shodují s hodnotami, které jsme zaznamenali dříve: 93, E7 a B8 v tomto pořadí.
To je docela trik pro jednořádkové okno terminálu.
Všechno má svůj účel
Ve světě Linuxu mohou mít i ty zdánlivě nejjednodušší příkazy a nástroje překvapivé a výkonné vlastnosti.
Filozofie designu jednoduchých utilit které dělají jednu věc dobře, a které snadno spolupracují s jinými utilitami, daly vzniknout některým podivným malým příkazům, jako je tac. Na první pohled se zdá, že je to trochu zvláštnost. Ale když nahlédnete pod povrch, je tu nečekaná síla, kterou můžete využít ve svůj prospěch.
Nebo, jak říká jiná filozofie: „Nepohrdej hadem za to, že nemá rohy, protože kdo by řekl, že se nestane drakem?