Jak používat příkaz join v systému Linux
Pokud si přejete spojit data ze dvou textových souborů na základě shodného pole, může vám pomoci příkaz `join` v Linuxu. Tento nástroj dokáže vnést dynamiku do vašich statických datových souborů. Následující text vám ukáže, jak jej používat.
Propojování dat mezi soubory
Data jsou klíčová. Podporují fungování korporací, firem i domácností. Nicméně data uložená v různých souborech a shromažďovaná různými lidmi mohou být problém. Kromě toho, že musíte vědět, které soubory otevřít, abyste našli potřebné informace, se pravděpodobně liší i struktura a formát těchto souborů.
Musíte se také zabývat administrativními záležitostmi, jako je rozhodování, které soubory je třeba aktualizovat, zálohovat, které jsou zastaralé a které lze archivovat.
A pokud potřebujete sloučit svá data nebo analyzovat celou datovou sadu, máte ještě větší výzvu. Jak sladíte data v různých souborech, abyste s nimi mohli dělat, co potřebujete? Jak přistoupíte k přípravné fázi dat?
Dobrou zprávou je, že pokud soubory sdílejí alespoň jeden společný datový prvek, příkaz `join` v Linuxu vám může pomoci z této situace.
Ukázkové datové soubory
Všechna data, která použijeme pro demonstraci příkazu `join`, jsou fiktivní. Začneme s následujícími dvěma soubory:
cat file-1.txt
cat file-2.txt
Níže je zobrazen obsah souboru `file-1.txt`:
1 Adore Varian [email protected] Female 192.57.150.231 2 Nancee Merrell [email protected] Female 22.198.121.181 3 Herta Friett [email protected] Female 33.167.32.89 4 Torie Venmore [email protected] Female 251.9.204.115 5 Deni Sealeaf [email protected] Female 210.53.81.212 6 Fidel Bezley [email protected] Male 72.173.218.75 7 Ulrikaumeko Standen [email protected] Female 4.204.0.237 8 Odell Jursch [email protected] Male 1.138.85.117
Máme sadu očíslovaných řádků a každý řádek obsahuje následující informace:
Číslo
Křestní jméno
Příjmení
E-mailová adresa
Pohlaví osoby
IP adresa
Následuje obsah souboru `file-2.txt`:
1 Varian [email protected] Female Western New York $535,304.73 2 Merrell [email protected] Female Finger Lakes $309,033.10 3 Friett [email protected] Female Southern Tier $461,664.44 4 Venmore [email protected] Female Central New York $175,818.02 5 Sealeaf [email protected] Female North Country $126,690.15 6 Bezley [email protected] Male Mohawk Valley $366,733.78 7 Standen [email protected] Female Capital District $674,634.93 8 Jursch [email protected] Male Hudson Valley $663,821.09
Každý řádek v souboru `file-2.txt` obsahuje tyto údaje:
Číslo
Příjmení
E-mailová adresa
Pohlaví osoby
Oblast v New Yorku
Finanční částka
Příkaz `join` pracuje s "poli", což v tomto kontextu znamená část textu ohraničenou mezerami, začátkem řádku nebo koncem řádku. Aby mohl `join` spojit řádky ze dvou souborů, musí každý řádek obsahovat alespoň jedno společné pole.
Pole tedy můžeme porovnat pouze pokud se vyskytuje v obou souborech. IP adresa se objevuje pouze v jednom souboru, takže ji nemůžeme použít. Křestní jméno také není vhodné. Příjmení se sice objevuje v obou souborech, ale není to dobrá volba, protože různí lidé mohou mít stejné příjmení.
Pohlaví také nemůžeme použít, protože je příliš obecné. Oblasti New Yorku a finanční částky se také objevují pouze v jednom souboru.
Můžeme však použít e-mailovou adresu, která je v obou souborech a je jedinečná pro každého člověka. Rychlý pohled na soubory také potvrzuje, že řádky v každém souboru odpovídají stejné osobě, takže můžeme použít čísla řádků jako pole pro porovnávání (později použijeme i jiné pole).
Je třeba si uvědomit, že v obou souborech je rozdílný počet polí, což je v pořádku. Důležité je, abychom v každém souboru mohli říct, které pole se má použít pro spojení.
Dávejte si pozor na pole, jako jsou názvy regionů New Yorku. V souboru odděleném mezerami se každé slovo názvu regionu jeví jako samostatné pole. Jelikož některé oblasti mají dvou- nebo tříslabičné názvy, můžete mít ve stejném souboru různý počet polí. To nevadí, pokud se shodujete v polích, která se v řádku objevují před regionem New York.
Použití příkazu join
Nejprve je potřeba seřadit pole, které chceme porovnat. V obou souborech jsou čísla vzestupně, takže to kritérium splňujeme. `join` ve výchozím nastavení používá první pole v souboru, což je to, co chceme. Další rozumné výchozí nastavení je, že `join` očekává, že oddělovače polí budou prázdné znaky. To také splňujeme, takže můžeme pokračovat a spojit soubory.
Protože používáme výchozí nastavení, náš příkaz je jednoduchý:
join file-1.txt file-2.txt
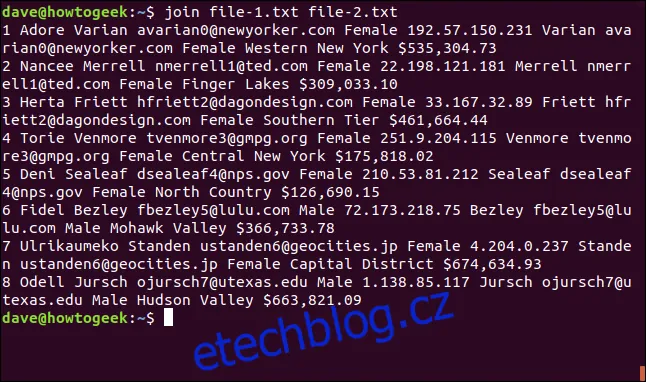
`join` považuje soubory za "soubor jedna" a "soubor dva" podle pořadí, v jakém jsou uvedeny v příkazovém řádku.
Výstup je následující:
1 Adore Varian [email protected] Female 192.57.150.231 Varian [email protected] Female Western New York $535,304.73 2 Nancee Merrell [email protected] Female 22.198.121.181 Merrell [email protected] Female Finger Lakes $309,033.10 3 Herta Friett [email protected] Female 33.167.32.89 Friett [email protected] Female Southern Tier $461,664.44 4 Torie Venmore [email protected] Female 251.9.204.115 Venmore [email protected] Female Central New York $175,818.02 5 Deni Sealeaf [email protected] Female 210.53.81.212 Sealeaf [email protected] Female North Country $126,690.15 6 Fidel Bezley [email protected] Male 72.173.218.75 Bezley [email protected] Male Mohawk Valley $366,733.78 7 Ulrikaumeko Standen [email protected] Female 4.204.0.237 Standen [email protected] Female Capital District $674,634.93 8 Odell Jursch [email protected] Male 1.138.85.117 Jursch [email protected] Male Hudson Valley $663,821.09
Výstup je formátován takto: Nejprve se vytiskne pole, na kterém byly řádky spárovány, následují další pole ze souboru jedna a poté pole ze souboru dva bez pole, na kterém se shodovaly.
Netříděná pole
Zkusíme něco, o čem víme, že nebude fungovat. Umístíme řádky do jednoho souboru mimo pořadí, aby `join` nemohl soubor správně zpracovat. Obsah souboru `file-3.txt` je stejný jako obsah souboru `file-2.txt`, ale řádek osm je mezi řádky pět a šest.
Následuje obsah souboru `file-3.txt`:
1 Varian [email protected] Female Western New York $535,304.73 2 Merrell [email protected] Female Finger Lakes $309,033.10 3 Friett [email protected] Female Southern Tier $461,664.44 4 Venmore [email protected] Female Central New York $175,818.02 5 Sealeaf [email protected] Female North Country $126,690.15 8 Jursch [email protected] Male Hudson Valley $663,821.09 6 Bezley [email protected] Male Mohawk Valley $366,733.78 7 Standen [email protected] Female Capital District $674,634.93
Zadáme následující příkaz, abychom se pokusili spojit soubor `file-3.txt` se souborem `file-1.txt`:
join file-1.txt file-3.txt
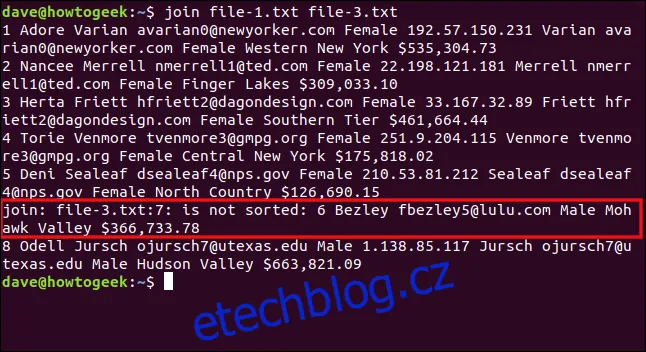
`join` hlásí, že sedmý řádek v souboru `file-3.txt` je mimo pořadí, takže se nezpracuje. Řádek sedm je ten, který začíná číslem šest, které by v seřazeném seznamu mělo být před osmičkou. Šestý řádek v souboru (který začíná "8 Odell") byl poslední zpracovaný, takže vidíme jeho výstup.
Pokud si chcete ověřit, zda je `join` spokojen s řazením souborů, ale nechcete provádět spojování, můžete použít volbu `--check-order`.
Za tímto účelem zadáme následující:
join --check-order file-1.txt file-3.txt
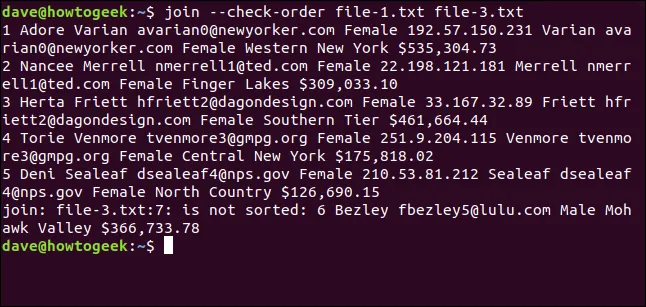
`join` vám předem oznámí, že bude problém se sedmým řádkem souboru `file-3.txt`.
Soubory s chybějícími řádky
V souboru `file-4.txt` byl odstraněn poslední řádek, takže tam není řádek osm. Obsah je následující:
1 Varian [email protected] Female Western New York $535,304.73 2 Merrell [email protected] Female Finger Lakes $309,033.10 3 Friett [email protected] Female Southern Tier $461,664.44 4 Venmore [email protected] Female Central New York $175,818.02 5 Sealeaf [email protected] Female North Country $126,690.15 6 Bezley [email protected] Male Mohawk Valley $366,733.78 7 Standen [email protected] Female Capital District $674,634.93
Napíšeme následující příkaz, a překvapivě, `join` si nestěžuje a zpracuje všechny řádky, které může:
join file-1.txt file-4.txt
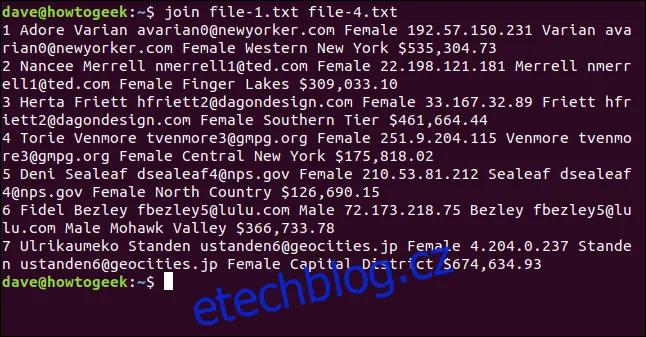
Výstup zobrazí sedm sloučených řádků.
Volba `-a` (vytiskni nespárované) říká `join`, aby vytiskl i řádky, které nelze spárovat.
Zadáme následující příkaz, který `join` nařídí vytisknout řádky ze souboru jedna, které nelze přiřadit řádkům v souboru dva:
join -a 1 file-1.txt file-4.txt
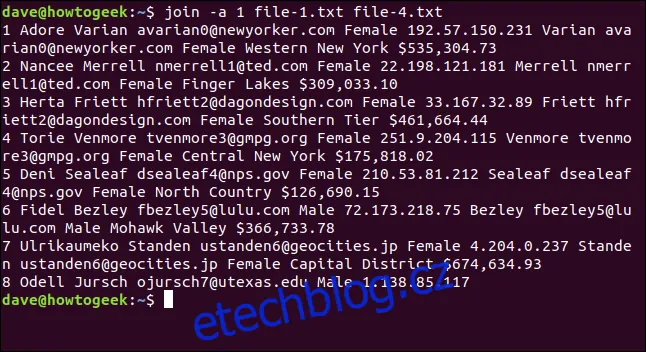
Sedm řádků se shoduje a řádek osm ze souboru jedna se vytiskne bez shody. Nejsou zde žádné sloučené informace, protože soubor `file-4.txt` neobsahoval řádek osm, ke kterému by se dal přiřadit. Nicméně, alespoň se stále zobrazuje ve výstupu, takže víte, že nemá shodu v souboru `file-4.txt`.
Zadáme následující příkaz s `-v` (potlačit spojené řádky), abychom odhalili všechny řádky, které nemají shodu:
join -v file-1.txt file-4.txt

Vidíme, že řádek osm je jediný, který nemá shodu v souboru dva.
Porovnávání ostatních polí
Pojďme spárovat dva nové soubory v poli, které není výchozí (pole jedna). Níže je uveden obsah souboru `file-7.txt`:
[email protected] Female 192.57.150.231 [email protected] Female 210.53.81.212 [email protected] Male 72.173.218.75 [email protected] Female 33.167.32.89 [email protected] Female 22.198.121.181 [email protected] Male 1.138.85.117 [email protected] Female 251.9.204.115 [email protected] Female 4.204.0.237
A následující je obsah souboru `file-8.txt`:
Female [email protected] Western New York $535,304.73 Female [email protected] North Country $126,690.15 Male [email protected] Mohawk Valley $366,733.78 Female [email protected] Southern Tier $461,664.44 Female [email protected] Finger Lakes $309,033.10 Male [email protected] Hudson Valley $663,821.09 Female [email protected] Central New York $175,818.02 Female [email protected] Capital District $674,634.93
Jediné rozumné pole pro spojení je e-mailová adresa, což je pole jedna v prvním souboru a pole dva v druhém. Abychom to provedli, můžeme použít volby `-1` (pole souboru jedna) a `-2` (pole souboru dva). Za nimi následuje číslo, které označuje, které pole v každém souboru by se mělo použít pro spojení.
Zadáme následující příkaz, aby `join` věděl, že má použít první pole v souboru jedna a druhé pole v souboru dva:
join -1 1 -2 2 file-7.txt file-8.txt
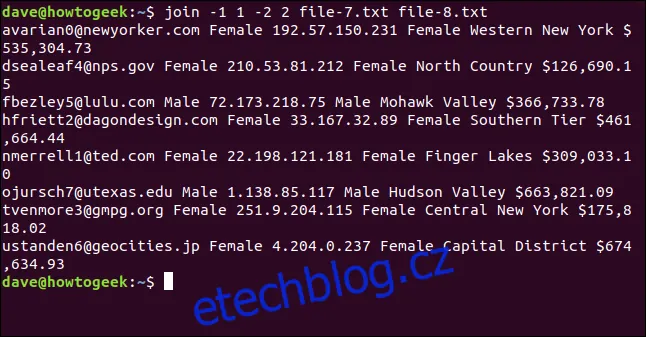
Soubory se spojí na základě e-mailové adresy, která se zobrazí jako první pole každého řádku ve výstupu.
Použití různých oddělovačů polí
Co když máte soubory s poli, která jsou oddělena něčím jiným než mezerami?
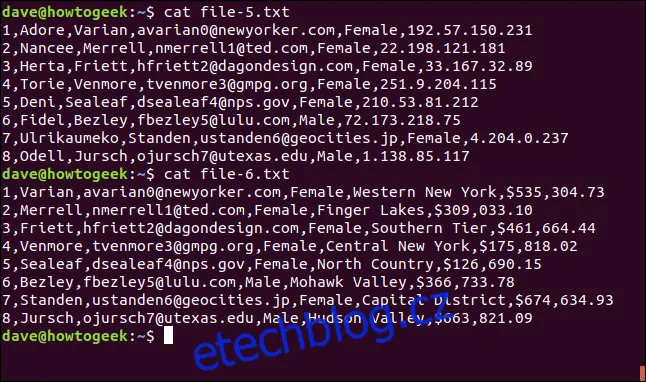
Následující dva soubory jsou odděleny čárkami. Jediné mezery jsou mezi víceslovnými názvy míst:
cat file-5.txt
cat file-6.txt
Můžeme použít volbu `-t` (znak oddělovače), abychom sdělili `join`, který znak má použít jako oddělovač pole. V tomto případě je to čárka, takže zadáme následující příkaz:
join -t, file-5.txt file-6.txt
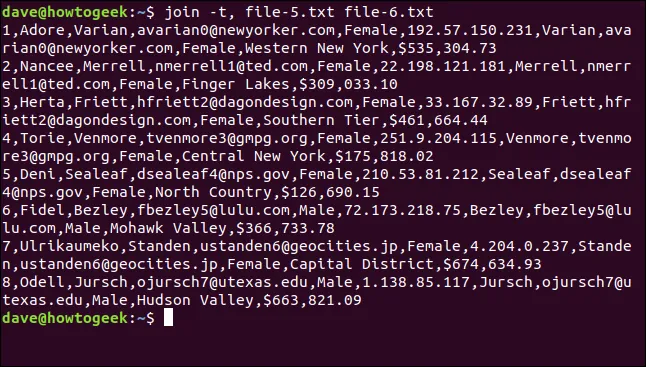
Všechny řádky se shodují a mezery v názvech míst zůstanou zachovány.
Ignorování velikosti písmen
Další soubor, `file-9.txt`, je téměř totožný se souborem `file-8.txt`. Jediný rozdíl je v tom, že některé e-mailové adresy mají velké písmeno, jak je uvedeno níže:
Female [email protected] Western New York $535,304.73 Female [email protected] North Country $126,690.15 Male [email protected] Mohawk Valley $366,733.78 Female [email protected] Southern Tier $461,664.44 Female [email protected] Finger Lakes $309,033.10 Male [email protected] Hudson Valley $663,821.09 Female [email protected] Central New York $175,818.02 Female [email protected] Capital District $674,634.93
Když jsme spojili soubory `file-7.txt` a `file-8.txt`, fungovalo to perfektně. Podívejme se, co se stane s `file-7.txt` a `file-9.txt`.
Zadáme následující příkaz:
join -1 1 -2 2 file-7.txt file-9.txt
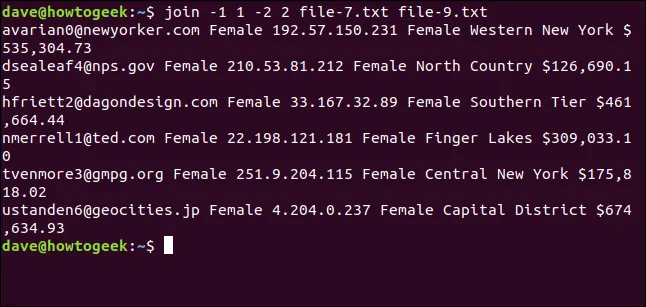
Shodovali jsme pouze šest řádků. Rozdíly ve velikosti písmen zabránily spojení dalších dvou e-mailových adres.
Můžeme však použít volbu `-i` (ignorovat velikost písmen) a vynutit `join`, aby ignoroval rozdíly ve velikosti písmen a porovnával pole, která obsahují stejný text, bez ohledu na to, zda jsou písmena velká nebo malá.
Zadáme následující příkaz:
join -1 1 -2 2 -i file-7.txt file-9.txt
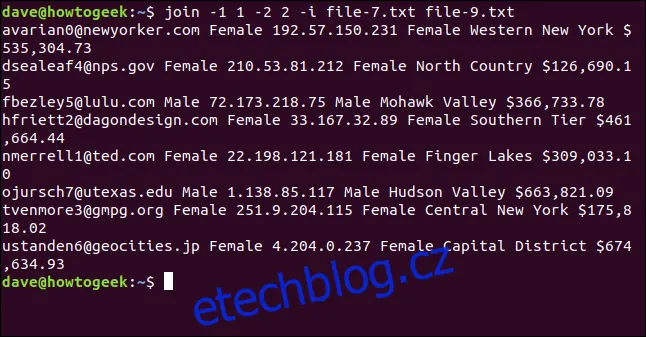
Všech osm řádků je spárováno a úspěšně spojeno.
Kombinace a přizpůsobení
Pokud bojujete s obtížnou přípravou dat, máte silného spojence. Možná potřebujete analyzovat data, nebo se je možná pokoušíte převést do formátu, který lze importovat do jiného systému.
Bez ohledu na situaci budete rádi, že máte k dispozici `join`!
