
Naučte se vše, co potřebujete vědět o průzkumné analýze dat, kritickém procesu používaném k objevování trendů a vzorců a shrnutí souborů dat pomocí statistických souhrnů a grafických znázornění.
Jako každý projekt je i projekt datové vědy dlouhý proces, který vyžaduje čas, dobrou organizaci a pečlivý respekt k několika krokům. Průzkumná analýza dat (EDA) je jedním z nejdůležitějších kroků v tomto procesu.
Proto se v tomto článku stručně podíváme na to, co je to průzkumná analýza dat a jak ji můžete provést pomocí R!
Table of Contents
Co je průzkumná analýza dat?
Průzkumná analýza dat zkoumá a studuje charakteristiky sady dat před jejím odesláním do aplikace, ať už jde o výhradně obchodní, statistické nebo strojové učení.
Toto shrnutí povahy informace a jejích hlavních zvláštností se obvykle provádí vizuálními metodami, jako jsou grafické znázornění a tabulky. Praxe se provádí předem právě pro posouzení potenciálu těchto dat, která budou v budoucnu komplexněji zpracována.
EDA proto umožňuje:
- Formulujte hypotézy pro použití těchto informací;
- Prozkoumejte skryté detaily v datové struktuře;
- Identifikujte chybějící hodnoty, odlehlé hodnoty nebo abnormální chování;
- Objevte trendy a relevantní proměnné jako celek;
- Zlikvidujte irelevantní proměnné nebo proměnné korelované s jinými;
- Určete formální modelování, které se má použít.
Jaký je rozdíl mezi popisnou a průzkumnou analýzou dat?
Existují dva typy analýzy dat, deskriptivní analýza a průzkumná analýza dat, které jdou ruku v ruce, přestože mají různé cíle.
Zatímco první se zaměřuje na popis chování proměnných, například průměr, medián, režim atd.
Průzkumná analýza má za cíl identifikovat vztahy mezi proměnnými, extrahovat předběžné poznatky a nasměrovat modelování na nejběžnější paradigmata strojového učení: klasifikaci, regresi a shlukování.
Oba se mohou společně zabývat grafickým znázorněním; pouze explorativní analýza se však snaží přinést praktické poznatky, tedy postřehy, které podněcují k jednání rozhodovatele.
A konečně, zatímco explorativní analýza dat se snaží vyřešit problémy a přinést řešení, která povedou kroky modelování, deskriptivní analýza, jak již název napovídá, má za cíl pouze vytvořit podrobný popis příslušné datové sady.
Popisná analýza Průzkumná analýza datAnalyzuje chováníAnalyzuje chování a vztahPoskytuje souhrn Vede ke specifikaci a akcímUspořádá data do tabulek a grafůUspořádá data do tabulek a grafůNemá významnou vysvětlovací schopnostMá významnou vysvětlovací schopnost
Některé praktické případy použití EDA
#1. Digitální marketing
Digitální marketing se vyvinul z kreativního procesu na proces založený na datech. Marketingové organizace používají průzkumnou analýzu dat k určení výsledků kampaní nebo úsilí a k vedení spotřebitelských investic a rozhodnutí o cílení.
Demografické studie, segmentace zákazníků a další techniky umožňují obchodníkům používat velké množství údajů o spotřebitelských nákupech, průzkumech a panelech k pochopení a komunikaci strategického marketingu.
Webová průzkumná analytika umožňuje obchodníkům shromažďovat informace o interakcích na webových stránkách na úrovni relace. Google Analytics je příkladem bezplatného a oblíbeného analytického nástroje, který marketéři používají k tomuto účelu.
Mezi často používané průzkumné techniky v marketingu patří modelování marketingového mixu, analýzy cen a propagace, optimalizace prodeje a průzkumná analýza zákazníků, např. segmentace.
#2. Průzkumná analýza portfolia
Běžnou aplikací exploratorní analýzy dat je exploratorní analýza portfolia. Banka nebo úvěrová agentura má sbírku účtů různé hodnoty a rizika.
Účty se mohou lišit v závislosti na sociálním postavení držitele (bohatí, střední třída, chudí atd.), geografické poloze, čistém jmění a mnoha dalších faktorech. Věřitel musí u každé půjčky vyvážit návratnost půjčky s rizikem nesplácení. Otázkou pak je, jak ocenit portfolio jako celek.
Půjčka s nejnižším rizikem může být pro velmi bohaté lidi, ale existuje velmi omezený počet bohatých lidí. Na druhou stranu mnoho chudých lidí může půjčit, ale s větším rizikem.
Řešení pro průzkumnou analýzu dat může zkombinovat analýzu časových řad s mnoha dalšími problémy při rozhodování o tom, kdy půjčit peníze těmto různým segmentům dlužníků nebo s mírou půjček. Úrok je účtován členům segmentu portfolia ke krytí ztrát mezi členy tohoto segmentu.
#3. Průzkumná analýza rizik
Prediktivní modely v bankovnictví jsou vyvíjeny, aby poskytovaly jistotu ohledně rizikových skóre pro jednotlivé zákazníky. Kreditní skóre je navrženo tak, aby předpovídalo delikventní chování jednotlivce a široce se používá k posouzení bonity každého žadatele.
Kromě toho se ve vědeckém světě a v pojišťovnictví provádí analýza rizik. Je také široce používán ve finančních institucích, jako jsou společnosti využívající online platební brány, k analýze, zda je transakce pravá nebo podvodná.
K tomuto účelu využívají transakční historii zákazníka. Běžněji se používá při nákupech kreditní kartou; když dojde k náhlému nárůstu objemu klientských transakcí, klient obdrží potvrzovací hovor, zda transakci zahájil. Pomáhá také snižovat ztráty způsobené těmito okolnostmi.
Průzkumná analýza dat s R
První věc, kterou musíte provést EDA s R, je stáhnout si R base a R Studio (IDE), poté nainstalovat a načíst následující balíčky:
#Installing Packages
install.packages("dplyr")
install.packages("ggplot2")
install.packages("magrittr")
install.packages("tsibble")
install.packages("forecast")
install.packages("skimr")
#Loading Packages
library(dplyr)
library(ggplot2)
library(magrittr)
library(tsibble)
library(forecast)
library(skimr)
V tomto tutoriálu použijeme sadu ekonomických dat, která je integrována s R a poskytuje roční údaje o ekonomických ukazatelích americké ekonomiky, a pro jednoduchost změníme její název na econ:
econ <- ggplot2::economics
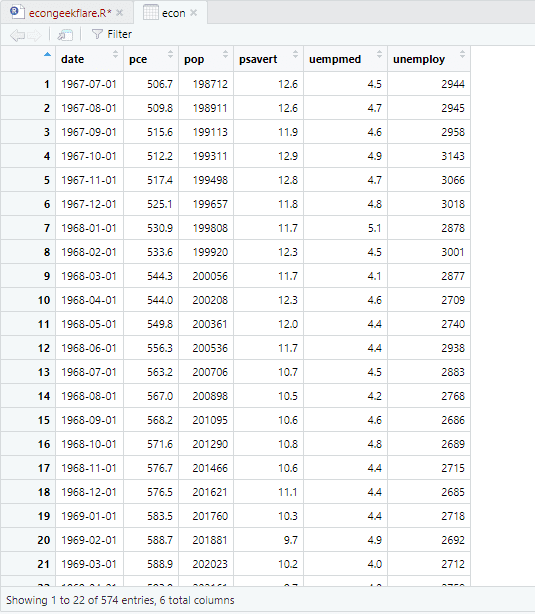
K provedení deskriptivní analýzy použijeme balíček skimr, který tyto statistiky vypočítá jednoduchým a dobře prezentovaným způsobem:
#Descriptive Analysis skimr::skim(econ)

Pro popisnou analýzu můžete také použít souhrnnou funkci:
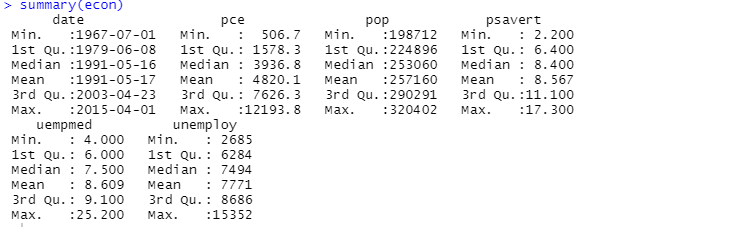
Zde popisná analýza ukazuje 547 řádků a 6 sloupců v datové sadě. Minimální hodnota je pro 1967-07-01 a maximální je pro 2015-04-01. Podobně také ukazuje střední hodnotu a směrodatnou odchylku.
Nyní máte základní představu o tom, co je uvnitř econ datasetu. Pojďme si vykreslit histogram proměnné uempmed, abychom se lépe podívali na data:
#Histogram of Unemployment econ %>% ggplot2::ggplot() + ggplot2::aes(x = uempmed) + ggplot2::geom_histogram() + labs(x = "Unemployment", title = "Monthly Unemployment Rate in US between 1967 to 2015")
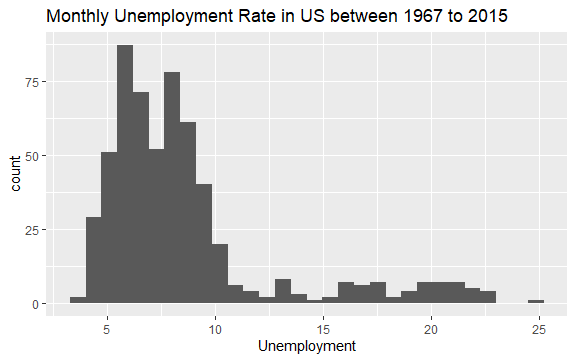
Rozložení histogramu ukazuje, že má napravo prodloužený ocas; to znamená, že možná existuje několik pozorování této proměnné s „extrémnějšími“ hodnotami. Nabízí se otázka: v jakém období k těmto hodnotám došlo a jaký je trend proměnné?
Nejpřímější způsob, jak identifikovat trend proměnné, je pomocí spojnicového grafu. Níže vygenerujeme čárový graf a přidáme vyhlazovací čáru:
#Line Graph of Unemployment econ %>% ggplot2::autoplot(uempmed) + ggplot2::geom_smooth()
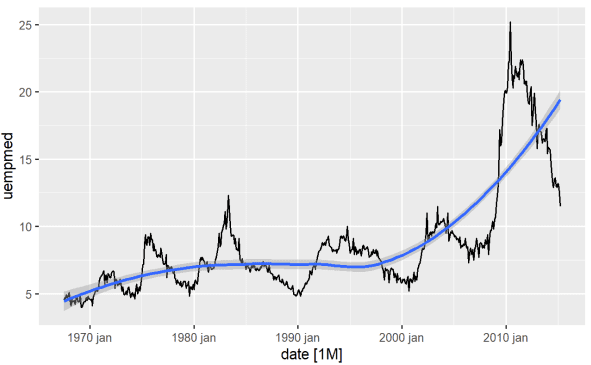
Pomocí tohoto grafu můžeme identifikovat, že v posledním období, v posledních pozorováních z roku 2010, existuje tendence k nárůstu nezaměstnanosti, která překonává historii pozorovanou v předchozích desetiletích.
Dalším důležitým bodem, zejména v kontextu ekonometrického modelování, je stacionarita řad; to znamená, jsou průměr a rozptyl konstantní v průběhu času?
Když tyto předpoklady u proměnné nejsou pravdivé, říkáme, že řada má jednotkový kořen (nestacionární), takže šoky, kterými proměnná trpí, generují trvalý účinek.
Zdá se, že tomu tak bylo v případě dotyčné proměnné, délky nezaměstnanosti. Viděli jsme, že fluktuace proměnné se značně změnily, což má silné důsledky související s ekonomickými teoriemi, které se zabývají cykly. Ale odhlédneme-li od teorie, jak prakticky zkontrolujeme, zda je proměnná stacionární?
Prognostický balíček má vynikající funkci umožňující aplikovat testy, jako je ADF, KPSS a další, které již vracejí počet rozdílů potřebný k tomu, aby série byla stacionární:
#Using ADF test for checking stationarity forecast::ndiffs( x = econ$uempmed, test = "adf")

Zde p-hodnota větší než 0,05 ukazuje, že data jsou nestacionární.
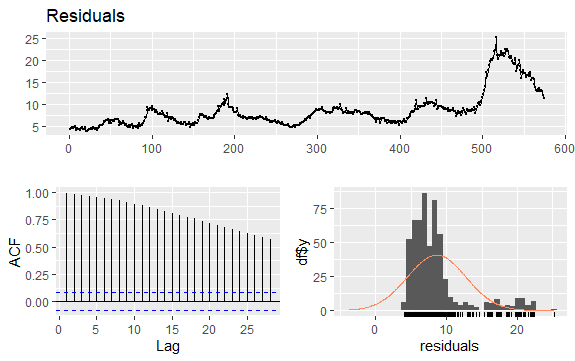
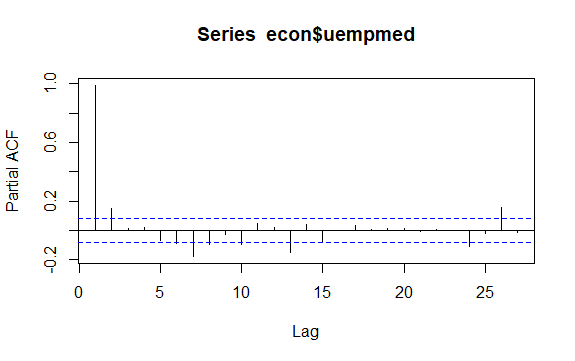
Další důležitou otázkou v časových řadách je identifikace možných korelací (lineární vztah) mezi zpožděnými hodnotami řady. K jeho identifikaci pomáhají korelogramy ACF a PACF.
Vzhledem k tomu, že řada nemá sezónnost, ale má určitý trend, bývají počáteční autokorelace velké a pozitivní, protože pozorování blízká v čase mají také blízkou hodnotu.
Autokorelační funkce (ACF) trendové časové řady má tedy tendenci mít kladné hodnoty, které pomalu klesají, jak se zpoždění zvětšuje.
#Residuals of Unemployment checkresiduals(econ$uempmed) pacf(econ$uempmed)
Závěr
Když se nám dostanou do rukou data, která jsou víceméně čistá, tedy již vyčištěná, jsme okamžitě v pokušení ponořit se do fáze konstrukce modelu, abychom nakreslili první výsledky. Musíte odolat tomuto pokušení a začít provádět průzkumnou analýzu dat, která je jednoduchá, ale pomáhá nám získat do dat silné vhledy.
Můžete také prozkoumat některé nejlepší zdroje pro získání statistik pro Data Science.