

Meta vydala Llama 2 v létě 2023. Nová verze Llama je vyladěna o 40 % více tokenů než původní model Llama, čímž se zdvojnásobila délka kontextu a výrazně předčí ostatní dostupné modely s otevřeným zdrojovým kódem. Nejrychlejší a nejsnadnější způsob, jak získat přístup k Llama 2, je prostřednictvím API prostřednictvím online platformy. Pokud však chcete ten nejlepší zážitek, je nejlepší nainstalovat a načíst Llama 2 přímo na váš počítač.
S ohledem na to jsme vytvořili podrobného průvodce, jak používat Text-Generation-WebUI k načtení kvantizovaného Llama 2 LLM lokálně do vašeho počítače.
Table of Contents
Proč instalovat Llama 2 lokálně
Existuje mnoho důvodů, proč se lidé rozhodnou spustit Llamu 2 přímo. Někteří to dělají kvůli ochraně soukromí, někteří kvůli přizpůsobení a další kvůli možnostem offline. Pokud zkoumáte, dolaďujete nebo integrujete Llama 2 pro své projekty, pak přístup k Llama 2 přes API nemusí být pro vás. Smyslem spuštění LLM lokálně na vašem PC je snížit závislost na nástrojích umělé inteligence třetích stran a používat umělou inteligenci kdykoli a kdekoli, aniž byste se museli obávat úniku potenciálně citlivých dat do společností a dalších organizací.
S tím, co bylo řečeno, začněme s podrobným průvodcem pro místní instalaci Llama 2.
Pro zjednodušení použijeme instalátor na jedno kliknutí pro Text-Generation-WebUI (program používaný k načtení Llama 2 s GUI). Aby však tento instalační program fungoval, musíte si stáhnout nástroj Visual Studio 2019 Build Tool a nainstalovat potřebné prostředky.
Stažení: Visual Studio 2019 (Volný, uvolnit)
Nyní, když máte nainstalovaný vývoj Desktop s C++, je čas stáhnout si instalační program Text-Generation-WebUI na jedno kliknutí.
Krok 2: Nainstalujte Text-Generation-WebUI
Instalační program na jedno kliknutí Text-Generation-WebUI je skript, který automaticky vytvoří požadované složky a nastaví prostředí Conda a všechny nezbytné požadavky pro spuštění modelu AI.
Chcete-li skript nainstalovat, stáhněte si instalační program na jedno kliknutí kliknutím na Kód > Stáhnout ZIP.
Stažení: Text-Generation-WebUI Installer (Volný, uvolnit)
- Pokud používáte Windows, vyberte dávkový soubor start_windows
- pro MacOS vyberte skript shellu start_macos
- pro Linux, skript shell start_linux.
Program je však pouze modelovým zavaděčem. Pojďme si stáhnout Llamu 2 pro model loader ke spuštění.
Krok 3: Stáhněte si model Llama 2
Při rozhodování, jakou iteraci Llama 2 potřebujete, je třeba vzít v úvahu několik věcí. Patří mezi ně parametry, kvantizace, optimalizace hardwaru, velikost a využití. Všechny tyto informace budou uvedeny v názvu modelu.
- Parametry: Počet parametrů použitých k trénování modelu. Větší parametry dělají schopnější modely, ale za cenu výkonu.
- Použití: Může být standardní nebo chatovací. Chatovací model je optimalizován pro použití jako chatbot jako ChatGPT, zatímco standardní je výchozí model.
- Hardware Optimization: Odkazuje na hardware, který nejlépe provozuje model. GPTQ znamená, že model je optimalizován pro běh na vyhrazeném GPU, zatímco GGML je optimalizován pro běh na CPU.
- Kvantizace: Označuje přesnost vah a aktivací v modelu. Pro odvození je optimální přesnost q4.
- Velikost: Vztahuje se na velikost konkrétního modelu.
Všimněte si, že některé modely mohou být uspořádány odlišně a nemusí mít dokonce zobrazeny stejné typy informací. Tento typ konvence pojmenování je však v knihovně HuggingFace Model poměrně běžný, takže stále stojí za pochopení.

V tomto příkladu lze model identifikovat jako středně velký model Llama 2 trénovaný na 13 miliardách parametrů optimalizovaných pro odvození chatu pomocí vyhrazeného CPU.
Pro ty, kteří používají dedikovaný GPU, zvolte GPTQ model, zatímco pro ty, kteří používají CPU, zvolte GGML. Pokud chcete s modelem chatovat jako s ChatGPT, zvolte chat, ale pokud chcete experimentovat s modelem s jeho plnými možnostmi, použijte standardní model. Pokud jde o parametry, vězte, že použití větších modelů poskytne lepší výsledky na úkor výkonu. Osobně bych vám doporučil začít s modelem 7B. Pokud jde o kvantování, použijte q4, protože slouží pouze k vyvozování.
Stažení: GGML (Volný, uvolnit)
Stažení: GPTQ (Volný, uvolnit)
Nyní, když víte, jakou iteraci Llama 2 potřebujete, pokračujte a stáhněte si model, který chcete.
V mém případě, protože to provozuji na ultrabooku, budu používat model GGML vyladěný pro chat, lama-2-7b-chat-ggmlv3.q4_K_S.bin.
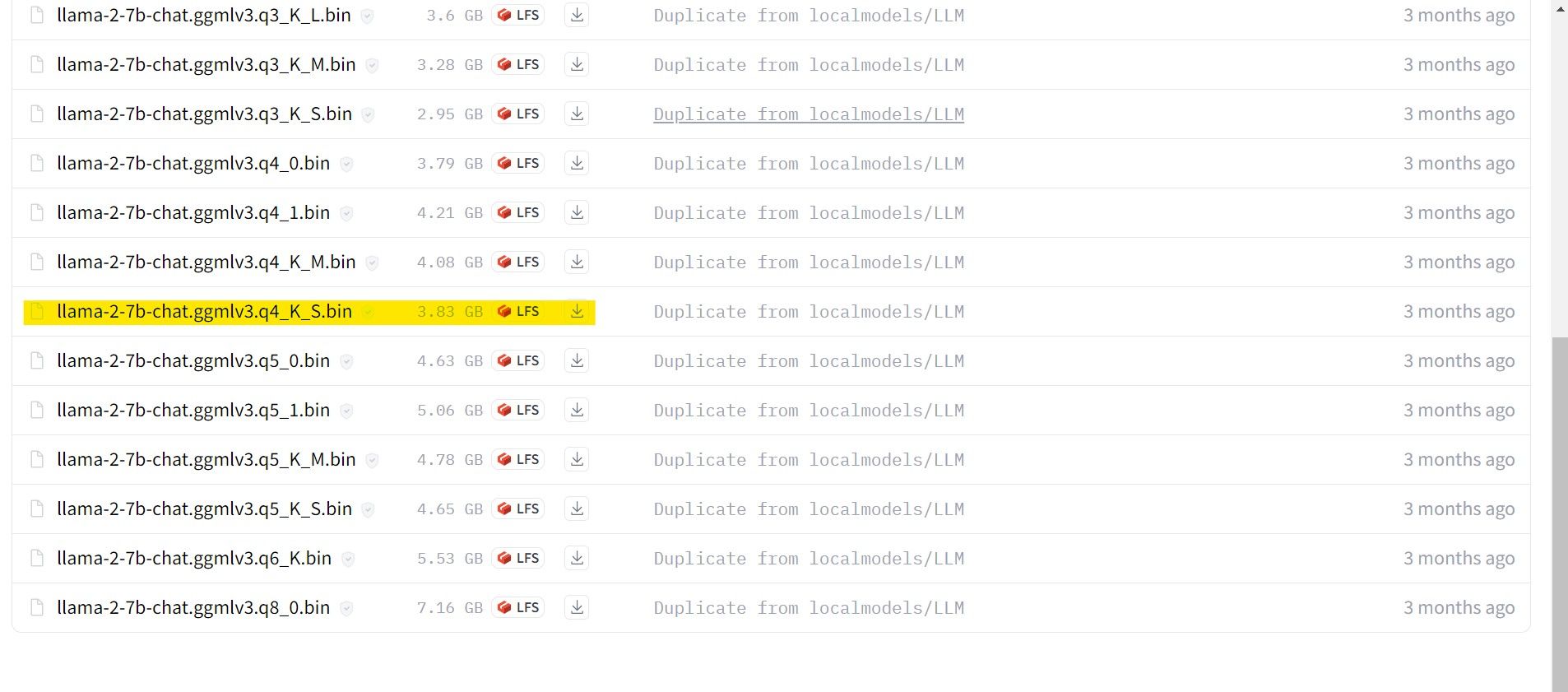
Po dokončení stahování umístěte model do text-generation-webui-main > models.
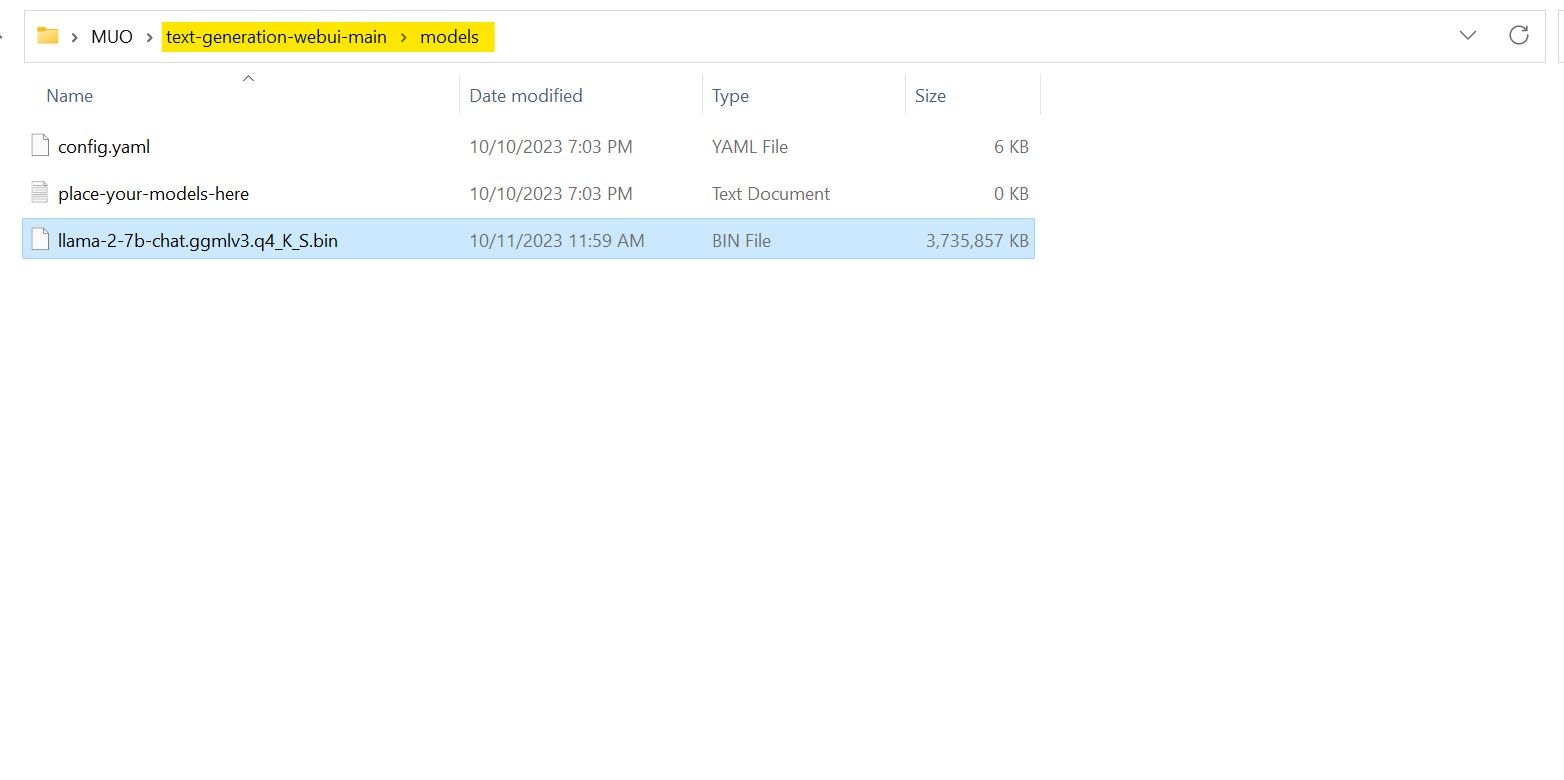
Nyní, když máte svůj model stažený a umístěný ve složce modelu, je čas nakonfigurovat zavaděč modelu.
Krok 4: Nakonfigurujte Text-Generation-WebUI
Nyní zahájíme fázi konfigurace.
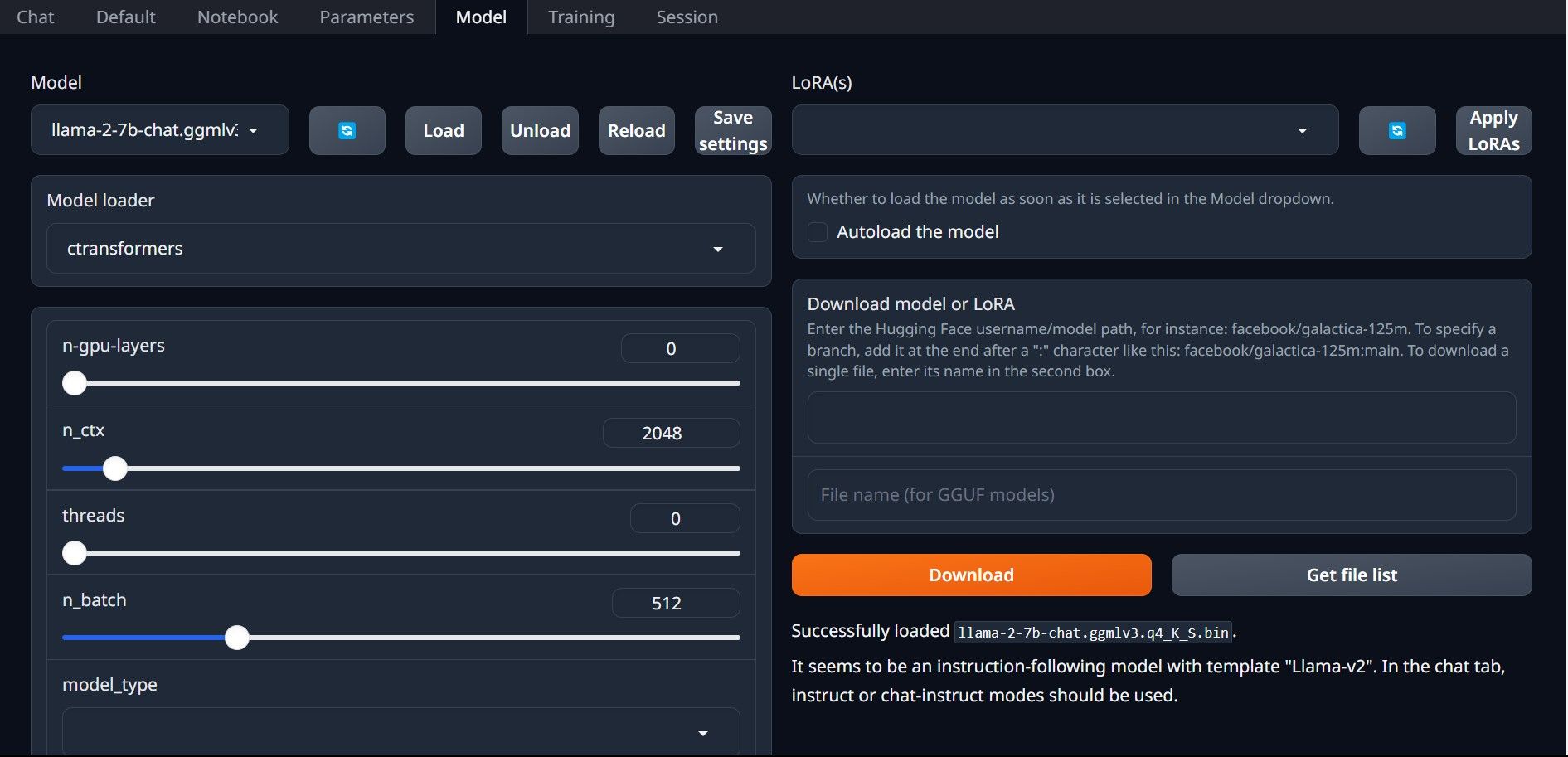
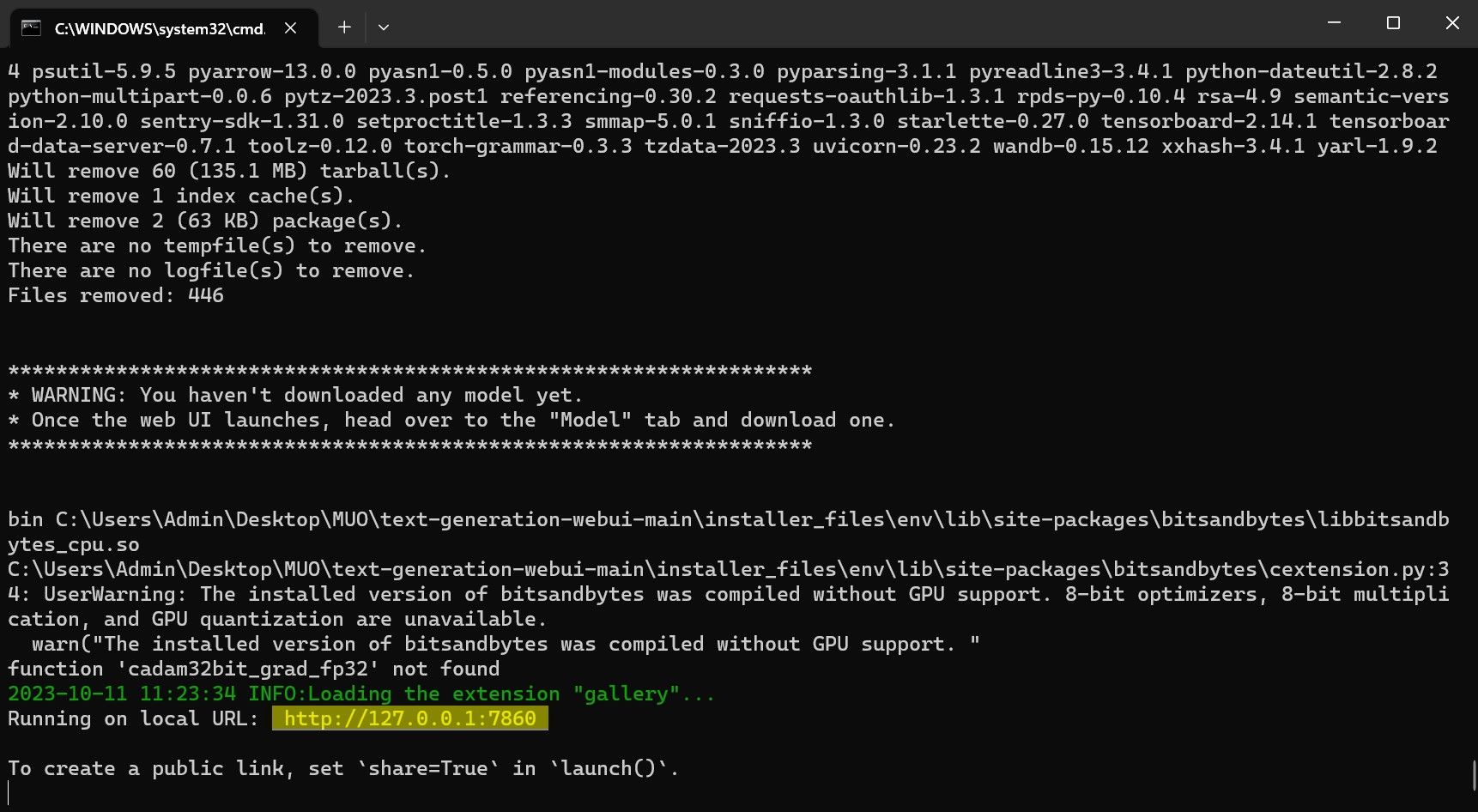
Gratulujeme, úspěšně jste nahráli Llama2 do svého místního počítače!
Vyzkoušejte jiné LLM
Nyní, když víte, jak spustit Llama 2 přímo na vašem počítači pomocí Text-Generation-WebUI, měli byste být schopni spouštět i další LLM kromě Llama. Stačí si pamatovat konvence pojmenování modelů a to, že na běžné počítače lze načíst pouze kvantované verze modelů (obvykle s přesností q4). Na HuggingFace je k dispozici mnoho kvantovaných LLM. Pokud chcete prozkoumat další modely, vyhledejte TheBloke v knihovně modelů HuggingFace a měli byste najít mnoho dostupných modelů.