

Table of Contents
Klíčové věci
- Souběžnost a paralelismus jsou základními principy provádění úloh ve výpočetní technice, přičemž každá z nich má své odlišné vlastnosti.
- Souběžnost umožňuje efektivní využití zdrojů a lepší odezvu aplikací, zatímco paralelismus je zásadní pro optimální výkon a škálovatelnost.
- Python poskytuje možnosti pro zpracování souběžnosti, jako je vytváření vláken a asynchronní programování s asyncio, stejně jako paralelismus pomocí modulu multiprocessing.
Souběžnost a paralelismus jsou dvě techniky, které umožňují spouštět několik programů současně. Python má několik možností pro zpracování úloh současně a paralelně, což může být matoucí.
Prozkoumejte dostupné nástroje a knihovny pro správnou implementaci souběžnosti a paralelismu v Pythonu a jak se liší.
Pochopení souběžnosti a paralelismu
Souběžnost a paralelismus odkazují na dva základní principy provádění úloh ve výpočetní technice. Každý má své odlišné vlastnosti.

Význam souběžnosti a paralelismu
Potřebu souběžnosti a paralelismu ve výpočtech nelze přeceňovat. Zde je důvod, proč jsou tyto techniky důležité:
Souběžnost v Pythonu
Souběžnosti v Pythonu můžete dosáhnout pomocí vláken a asynchronního programování s knihovnou asyncio.
Řezání vláken v Pythonu
Threading je souběžný mechanismus Pythonu, který vám umožňuje vytvářet a spravovat úlohy v rámci jednoho procesu. Vlákna jsou vhodná pro určité typy úloh, zejména ty, které jsou I/O vázány a mohou mít prospěch ze souběžného provádění.
Modul vlákna v Pythonu poskytuje rozhraní na vysoké úrovni pro vytváření a správu vláken. I když GIL (Global Interpreter Lock) omezuje vlákna z hlediska skutečného paralelismu, stále mohou dosáhnout souběžnosti efektivním prokládáním úloh.
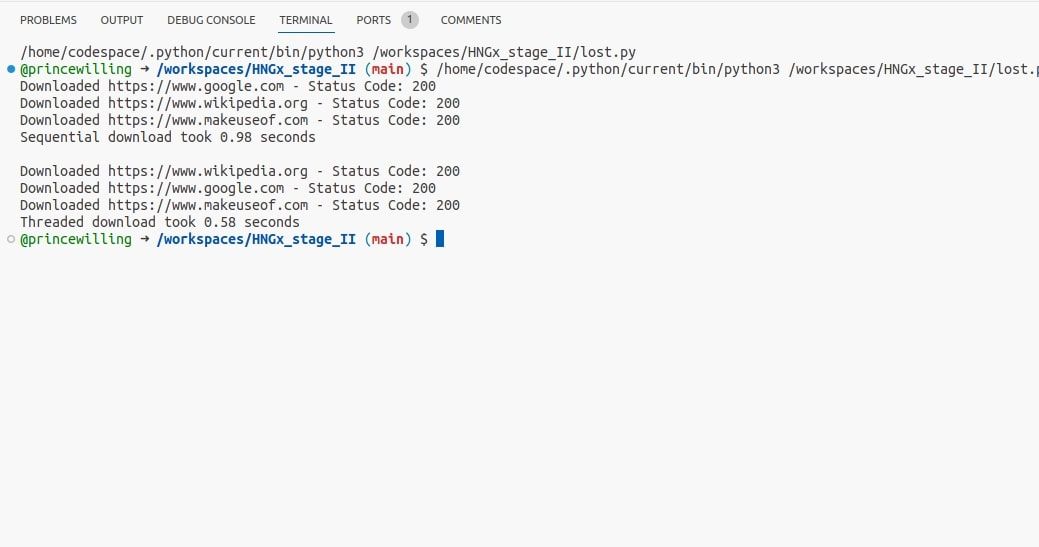
Níže uvedený kód ukazuje příklad implementace souběžnosti pomocí vláken. K odeslání požadavku HTTP používá knihovnu požadavků Pythonu, což je běžná úloha blokování I/O. Také používá časový modul pro výpočet doby provedení.
import requests
import time
import threadingurls = [
'https://www.google.com',
'https://www.wikipedia.org',
'https://www.makeuseof.com',
]
def download_url(url):
response = requests.get(url)
print(f"Downloaded {url} - Status Code: {response.status_code}")
start_time = time.time()for url in urls:
download_url(url)end_time = time.time()
print(f"Sequential download took {end_time - start_time:.2f} seconds\n")
start_time = time.time()
threads = []for url in urls:
thread = threading.Thread(target=download_url, args=(url,))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()end_time = time.time()
print(f"Threaded download took {end_time - start_time:.2f} seconds")
Při spuštění tohoto programu byste měli vidět, o kolik rychlejší jsou požadavky ve vláknech než sekvenční požadavky. I když je rozdíl jen zlomek sekundy, získáte jasný pocit zlepšení výkonu při použití vláken pro úlohy vázané na I/O.
Asynchronní programování s Asyncio
asyncio poskytuje smyčku událostí, která spravuje asynchronní úlohy zvané korutiny. Coroutines jsou funkce, které můžete pozastavit a obnovit, takže jsou ideální pro úlohy vázané na I/O. Knihovna je užitečná zejména pro scénáře, kde úkoly zahrnují čekání na externí zdroje, jako jsou síťové požadavky.
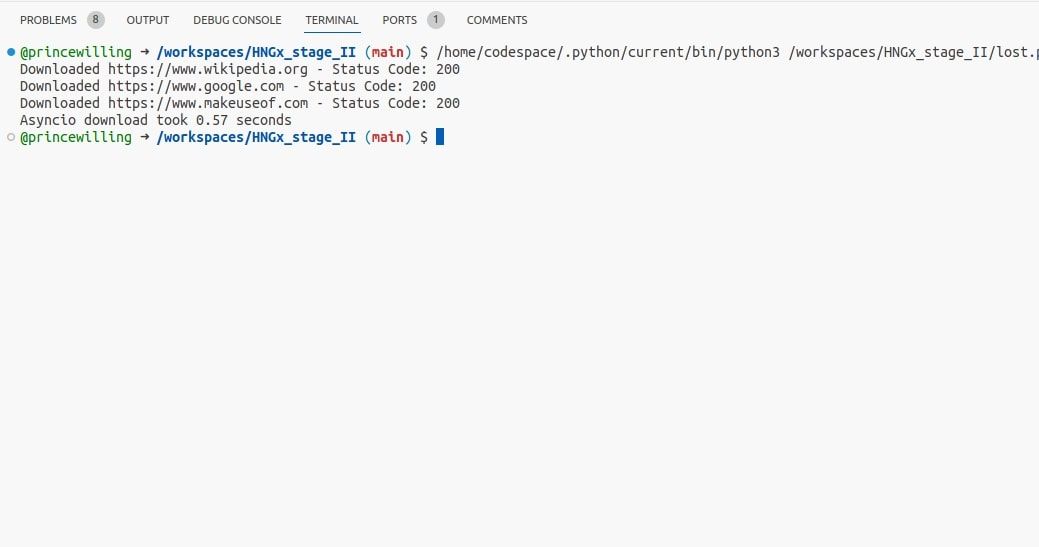
Předchozí příklad odeslání požadavku můžete upravit tak, aby fungoval s asyncio:
import asyncio
import aiohttp
import timeurls = [
'https://www.google.com',
'https://www.wikipedia.org',
'https://www.makeuseof.com',
]
async def download_url(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
content = await response.text()
print(f"Downloaded {url} - Status Code: {response.status}")
async def main():
tasks = [download_url(url) for url in urls]
await asyncio.gather(*tasks)start_time = time.time()
asyncio.run(main())end_time = time.time()
print(f"Asyncio download took {end_time - start_time:.2f} seconds")
Pomocí kódu můžete stahovat webové stránky souběžně pomocí asyncia a využívat výhod asynchronních I/O operací. To může být u úloh vázaných na I/O efektivnější než vytváření vláken.
Paralelnost v Pythonu
Paralelismus můžete implementovat pomocí Multiprocessingový modul Pythonukterý vám umožní plně využít výhod vícejádrových procesorů.
Multiprocessing v Pythonu
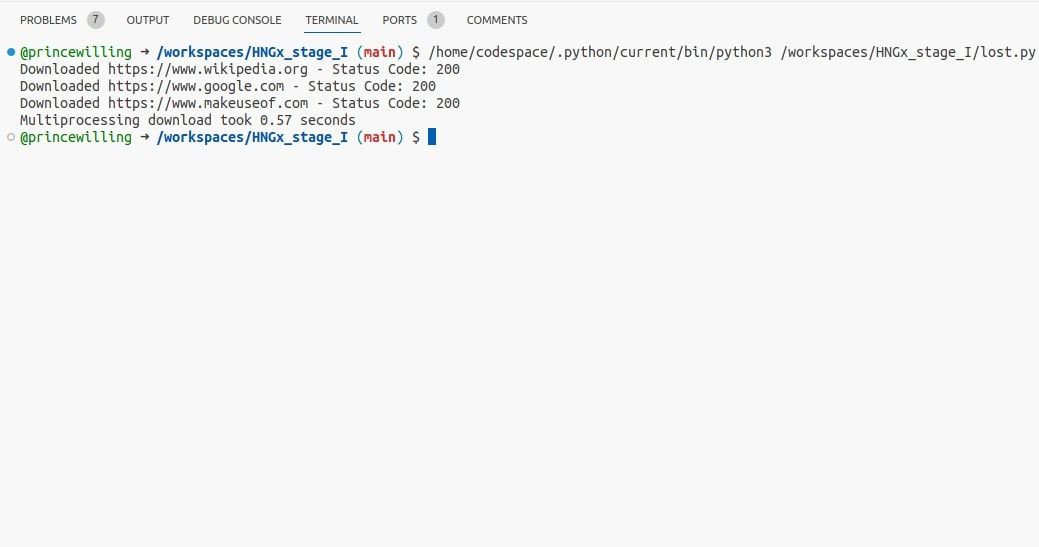
Modul multiprocessingu Pythonu poskytuje způsob, jak dosáhnout paralelismu vytvořením samostatných procesů, z nichž každý má svůj vlastní interpret Pythonu a paměťový prostor. To efektivně obchází Global Interpreter Lock (GIL), takže je vhodný pro úlohy vázané na CPU.
import requests
import multiprocessing
import timeurls = [
'https://www.google.com',
'https://www.wikipedia.org',
'https://www.makeuseof.com',
]
def download_url(url):
response = requests.get(url)
print(f"Downloaded {url} - Status Code: {response.status_code}")def main():
num_processes = len(urls)
pool = multiprocessing.Pool(processes=num_processes)start_time = time.time()
pool.map(download_url, urls)
end_time = time.time()
pool.close()
pool.join()print(f"Multiprocessing download took {end_time-start_time:.2f} seconds")
main()
V tomto příkladu multiprocessing vytváří více procesů, což umožňuje funkci download_url běžet paralelně.
Kdy použít souběžnost nebo paralelismus
Volba mezi souběžností a paralelismem závisí na povaze vašich úloh a dostupných hardwarových prostředcích.
Souběžnost můžete použít při řešení úloh vázaných na I/O, jako je čtení a zápis do souborů nebo vytváření síťových požadavků, a když jsou problémem omezení paměti.
Multiprocessing použijte, když máte úlohy vázané na CPU, které mohou těžit ze skutečného paralelismu, a když máte robustní izolaci mezi úlohami, kde by selhání jedné úlohy nemělo mít dopad na ostatní.
Využijte výhody souběžnosti a paralelismu
Paralelnost a souběžnost jsou efektivní způsoby, jak zlepšit odezvu a výkon vašeho kódu Python. Je důležité porozumět rozdílům mezi těmito pojmy a vybrat nejúčinnější strategii.
Python nabízí nástroje a moduly, které potřebujete, aby byl váš kód efektivnější prostřednictvím souběžnosti nebo paralelismu, bez ohledu na to, zda pracujete s procesy vázanými na CPU nebo I/O.