

Google Search Console neboli GSC je mocná zbraň v rukou SEO specialistů🧑💻 při interpretaci výkonu webové stránky.
Zavedení REGEX zlepšilo způsob, jak získat užitečné poznatky z obsahu a zároveň vytvářet nové nápady pro tvorbu.
Na funkci REGEX se pro webovou analýzu hodně čekalo. Umožňoval filtrování zvláštních prvků z libovolné adresy URL, což bylo jinak obtížné nebo nemožné.
Zde upozorňuji na tipy a triky, jak používat REGEX ve službě Google Search Console. Dozvíte se také o různých sadách operátorů, které lze použít v kombinaci s kódy REGEX, abyste získali požadovanou interpretaci.
Table of Contents
REGEX nebo regulární výraz: přehled
Google Search Console je zcela bezplatná služba nabízená webmasterům za účelem správy výkonu webových stránek. Poskytuje podrobné zprávy o míře prokliku webu, zobrazení, kliknutí🖱️ a hodnocení klíčových slov, což se využívá k pochopení úspěšnosti SEO kampaní.
Při filtrování úspěšnosti adresy URL však existovala omezení. GSC umožňoval exportovat maximálně 1000 řádků pro analýzu. V adrese URL bylo možné filtrovat pouze konkrétní sekce, jako je definování cesty, vlastnosti domény nebo předpon, přičemž chyběly složité řetězce a varianty.
Regular Expression neboli Regex je účinným doplňkem GSC. Účelem je poskytnout systém, kde mohou SEO experti využít GSC k získání více informací o fungování a výkonu webových stránek.
Regex umožňuje zjistit kritické SEO detaily webu použitím těchto kódů na stránky nebo filtry dotazů. Kódy se skládají z metaznaků obklopujících řetězec související s parametrem filtrování. Když na panelu zadáte Regex, zobrazí se výsledek, který si můžete uložit pro referenci.
Výhody použití Regex na GSC
Účelem práce na Google Search Console je analyzovat web z technického hlediska. SEO tým pracuje s mnoha takovými nástroji a technikami pro optimalizační strategii, díky které se web umístí vysoko📈 ve vyhledávačích a generuje návštěvnost.
Regex poskytuje další výhodu tím, že usnadňuje proces shromažďování užitečných dat, která lze dále využít k improvizaci plánů optimalizace. Zde je to, co můžete interpretovat pomocí přehledu Regex.
✨ Pomocí Regex kódů na dotazy můžete zjistit objem vyhledávání na konkrétní klíčová slova/fráze. To vám pomůže vytvořit nové nápady na obsah vašeho blogu a zvýšit návštěvnost.
✨ Regex kódy šetří spoustu času SEO, kteří pracují ve velkých firmách a zabývají se obrovskými objemy webových dat. K řazení dotazů nebo stránek podle konkrétních požadavků je potřeba pouze několik metaznaků a řetězců ve správné syntaxi.
✨ Jednou z jeho hlavních výhod je práce na typické kombinaci slov, vět a URL. Tyto znaky je třeba umístit ve správném pořadí, aby vytvořily funkční kód Regex.
✨ Nepochybně poskytuje lepší přehled o vašem webu, který zahrnuje stránky s vysokým a nízkým výkonem, spolu s trendy.
✨ Kódy Regex můžete použít na vlastní přehledy a sledovat tok provozu na webových stránkách pro konkrétní dotazy. Později můžete týmu nařídit, aby podle toho pracoval konkrétním směrem.
Můžete nastavit více kombinací znaků Regex k definování kódu a použít jej k interpretaci řešení pro optimalizaci vašeho webu.
Kde použít Regex na Google Search Console?
Chcete-li používat funkci Regex na GSC, potřebujete především přístup k vlastnictví svého webu. Je to nutkavá podmínka, protože ji nebudete moci připojit jako svůj majetek ve službě Google Search Console pro žádný jiný analytický postup.
Musíte se přihlásit do Google Search Console pomocí svého Gmail ID a začít přidáním vlastnosti z možnosti uvedené na postranním panelu. Vlastnost je web, který vlastníte nebo máte oprávnění k přístupu na konzoli.
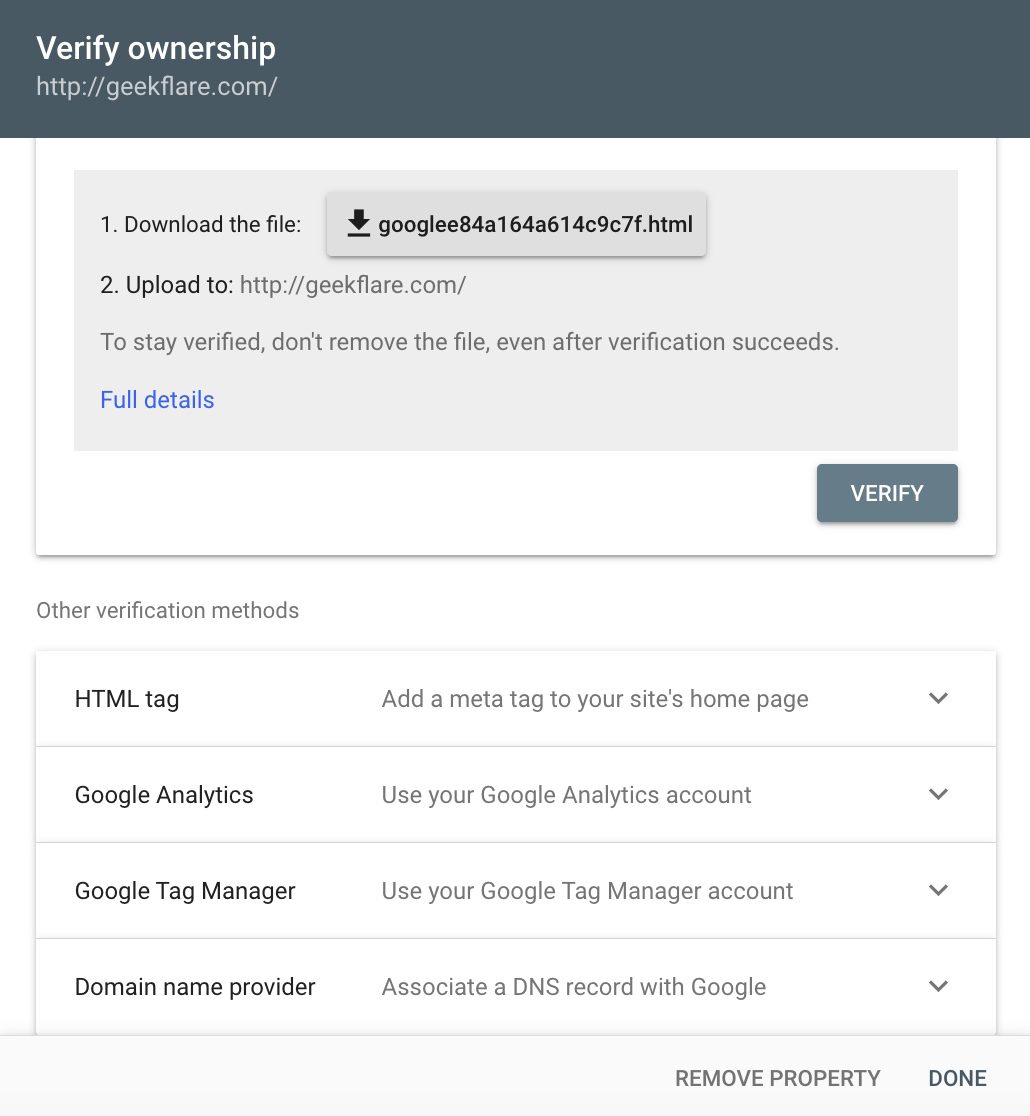
Jakmile do dané možnosti přidáte webovou stránku nebo jakoukoli adresu URL, panel vás požádá o její ověření✅. Ověřovací postup je uveden ve sloupci a po jeho dokončení můžete svou nemovitost vybrat pro další postupy.
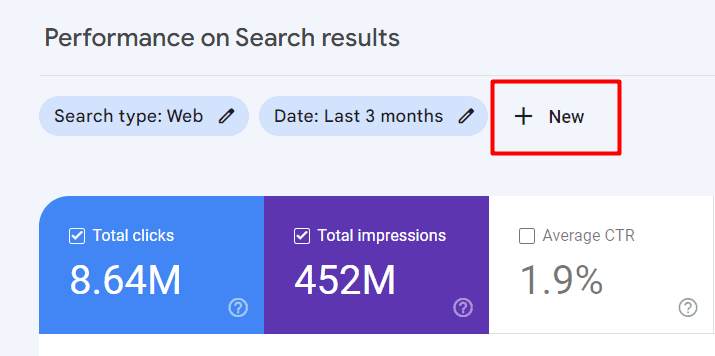
Pod uvedeným názvem vlastnosti klikněte na parametr „Výkon“ a klikněte na tlačítko „Nový“ nad grafem pro možnosti filtrování.
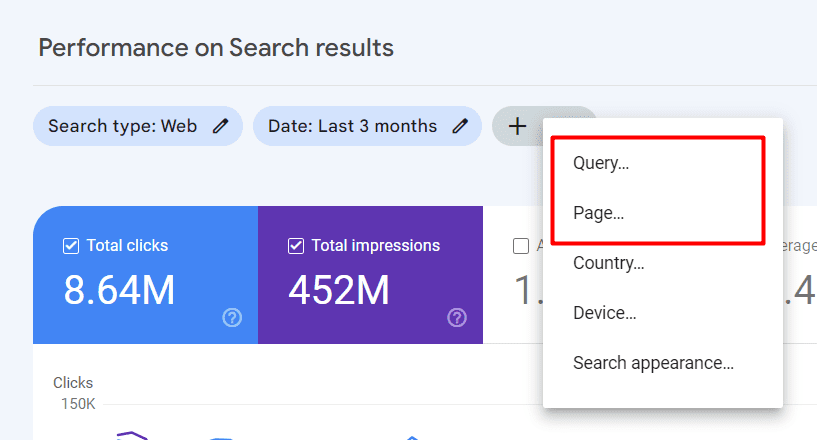
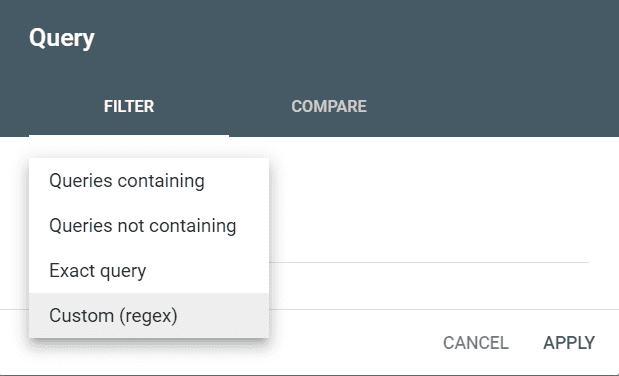
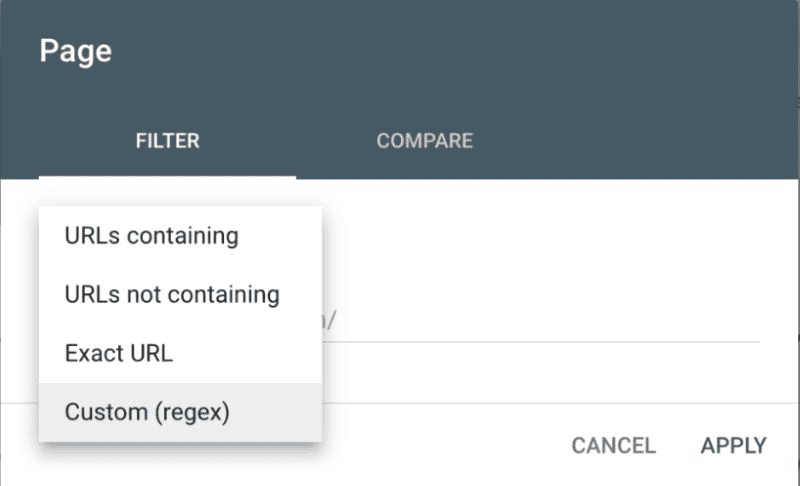
Chcete-li k filtrování výsledků použít kód Regex, můžete zvolit Dotaz nebo Stránky.
Vysvětlení Regex znaků
Při filtrování dotazů a stránek ve službě Google Search Console se jako regulární výraz používá několik sad znaků. Každý metaznak představuje na filtru jiný význam. Pokud jim dobře rozumíte, nebude těžké provést analýzu GSC pomocí Regex.
Zde, v grafu níže, jsem vysvětlil některé symboly a znaky používané v Regex kódu na vhodném příkladu.
CharactersUsage()Tyto závorky se používají pro seskupování znaků nebo výrazů, známé také jako zachycení skupin. (Geek) Získáte všechny webové stránky se slovem „Mobile“ na začátku názvu nebo značky. [^\mobile] Pokud zpětné lomítko následuje za stříškou, bude filtrovat adresy URL s daným slovem mobile. |Toto je symbol NEBO, který se jednoduše používá k použití voleb v kódu.Mobile|PCSestava načte všechny stránky s kterýmkoli ze dvou slov. ^Symbol stříšky bude odpovídat pouze slovu nebo frázi na začátku řetězce.^Mobil Všechny webové stránky budou mít slovo „Mobile“ na začátku názvu nebo značky. [^\mobile] Pokud zpětné lomítko následuje za stříškou, bude filtrovat adresy URL s daným slovem mobile. $Symbol dolaru bude odpovídat pouze slovu nebo frázi na konci řetězce.Mobile$Všechny webové stránky získáte se slovem „Mobile“ na začátku názvu nebo značky. [^\mobile] Pokud zpětné lomítko následuje za stříškou, bude filtrovat adresy URL s daným slovem mobile. .Tečka se používá pro shodu libovolného jednotlivého znaku v řetězci.to. Všechny webové stránky budou mít na konci názvu nebo značky slovo „Mobile“. \Zpětné lomítko se používá k přeskočení doslovného významu znaků.\dTo bude odpovídat stránkám s číslicemi 0-9. [xyz]Tento kód RegEx bude odpovídat dotazu s jedním nebo všemi těmito znaky v závorce; x, y nebo z.Mobile[xyz]Kód se bude shodovat se stránkami, které obsahují všechna slova v kombinaci mobile s x, y nebo z, jako je mobilex, mobilezy a mobilezxy. [c-m]Tento kód RegEx bude odpovídat dotazu jakémukoli malému nebo velkému písmenu mezi c a m.Mobile[c-m]Kód se bude shodovat se stránkami, které obsahují všechna slova v kombinaci mobilních s písmeny mezi c a m; jako například mobilecjg, mobileeel, mobilecdf. [3-7]Tento RegEx kód bude odpovídat dotazu s čísly mezi 3 a 7.Mobile[0-9]Kód se bude shodovat se stránkami obsahujícími všechna slova v kombinaci mobilní s čísly mezi 3 a 7; například mobile73, mobile654, mobile445. [\w]To bude odpovídat každému slovu na webových stránkách s písmeny „to“ jako směrem, do, do.[\w]*Mobilní, pohybliví[\w]Zpětné lomítko následované malým písmenem „w“ uvnitř závorky. To bude odpovídat libovolnému slovu nebo znaku, jako je písmeno (malé i velké), číslo nebo podtržítko. [\W]Tento Regex kód porovná stránky se slovem „mobilní“ s jinými slovy, ať už v názvu, meta nebo článku, jako je mobilní telefon, mobilní aplikace[\W]*Mobilní, pohybliví[\W]Zpětné lomítko následované písmenem „W“ velkým písmenem uvnitř závorky. To bude odpovídat všemu kromě písmen nebo číslic. Znamená mezery a symboly jako; ?:#@$%.
Pomocí těchto znaků můžete vytvořit více kódů a filtrovat složité dotazy na GSC.
Konkrétní regulární výrazy ve službě Google Search Console
Pomocí metaznaků ve službě Google Search Console můžete vytvářet jedinečné vzory nebo kódy pro konkrétní účely. Zde jsou některé z nich, které si můžete vyzkoušet na svém portálu GSC.
🔶 ^[\w\W\s\S]{70,}$
Následně bude kód odpovídat všem slovům, číslům, neslovným nebo speciálním znakům, symbolům, mezerám a jiným než bílým nebo novým řádkům na stránce. Zatímco kvantifikátor „70“ znamená, že řetězec je dlouhý nebo alespoň 70 znaků.
Příklad: Tyto typy kódů lze použít při ověřování hesel, třídění seznamů produktů s propracovaným popisem nebo jinde.
🔶 (\w+\s){6,}\w+
Tento Regex kód má tři sekce. Jeho cílem je porovnat slova a čísla s mezerami mezi nimi. Proto kód načte řetězce, které jsou alespoň 6 slov nebo delší, jako je tato věta; „Řetězce, které jsou alespoň 6 slov nebo delší.“
Příklad: Tyto kódy lze použít při filtrování článků s delšími názvy, delšími komentáři na sociálních sítích atd.
🔶 ^(kdo|co|kde|kdy|proč|jak)[“ “]
Tento kód Regex je jednoduchý a docela přínosný pro blogery a odborníky na SEO. Je snadné pochopit, že bude odpovídat všem dotazům ve vyhledávačích, které začínají kterýmkoli z těchto slov; kdo, nebo co, nebo kde, a další v závorce. Řetězec by měl začínat kterýmkoli z těchto slov, za nímž by měla následovat mezera. Proto nenačte slova jako „nicméně“, „celý“ atd.
Příklad: Tyto kódy jsou vhodné pro pochopení tržních trendů a diskusí uživatelů za účelem získání nových nápadů na obsah.
🔶 „kdo|co|kde|kdy|proč|jak“
Podobá se výše uvedenému kódu Regex, ale zde bude funkce odpovídat všem řetězcům, které obsahují kterékoli z těchto slov, bez ohledu na to, zda řetězec těmito slovy začíná nebo ne.
Příklad: Kód je vhodný pro zvýraznění pochybných tvrzení, filtrování uživatelských vstupů atd.
🔶 .*
Období metaznaku následované hvězdičkou se často nazývá výraz se zástupným znakem, protože jej můžete použít ke spárování jakéhokoli konkrétního řetězce tím, že jej vložíte pod tento kód.
Příklad: Regex .*Android.* načte všechny stránky ve vaší službě, které obsahují slovo Android. Přímým použitím kódu .* na filtru vytáhne všechny stránky, které se objeví ve vyhledávači za měsíc.
🔶 [^\/\.\-:0-9A-Za-z_]
Za symbolem stříšky následuje zpětné lomítko, které vyloučí znaky uvedené v kódu. Zde se kód bude shodovat s řetězci, které nemají lomítko, číslice, tečku, dvojtečku, pomlčku a všechna písmena jak velká, tak malá.
Příklad: Proto je kód použitelný při zachycování adres URL, metapopisů nebo obsahu, který má speciální znaky jako &%$@.
🔶 ?i)(((je|jsou).(značka|stránka|společnost)|(značka|stránka|společnost).(je|jsou)).*(zmetek|spolehlivý))
Je to dlouhý kód Regex se specifickými sekcemi. Znak „?i“ použitý na začátku kódu je pro příznak nerozlišující malá a velká písmena. To znamená, že kód bude odpovídat řetězcům bez ohledu na to, zda jsou velká nebo malá písmena. Závorky za ním obsahují některá slova oddělená svislou čarou (OR).
Kód Regex detekuje dotazy bez ohledu na předpokládaná písmena, která zahrnují slova je nebo jsou, značka, společnost nebo web, spolu s odpadem nebo spolehlivým.
Příklad: Tento Regex kód lze opatrně použít při hledání vzoru dotazů zákazníků. Budete moci vědět, zda má vaše webové stránky pozitivní nebo negativní recenze.
🔶 (kwd1|kwd2).*
Jde o zjednodušené použití disjunkčního regulárního kódu, kdy GSC odfiltruje stránky nebo dotazy obsahující buď slovo kwd1 nebo kwd2, za kterým následuje jakékoli jiné písmeno nebo číslo.
Příklad: Vzor můžete použít k extrahování stránek na vašem webu, které mají kterékoli z těchto slov spojené s jinými slovy nebo čísly v adrese URL, názvu, meta nebo obsahu.
🔶 (Klíčové slovo1 A Klíčové slovo2)
Tento kód je jasným příkladem výrazu konjunkce. „AND“ je operátor používaný v kódu Regex. Používá se k získání stránek, které mají tato dvě daná slova ve stejném pořadí.
Příklad: Kód můžete použít na GSC a získat stránky, název nebo meta se dvěma konkrétními slovy ve stejném pořadí.
🔶 „klíčové slovo1 klíčové slovo2“
Kód je vhodný pro shodu fráze nebo přesného pořadí slov na webové stránce.
Příklad: Použijte kód na GSC, abyste našli stránky s názvem, popisem nebo obsahem, který obsahuje konkrétní frázi.
🔶 (Klíčové slovo 1 | Klíčové slovo 2)
Tento kód má dvě slova a svislý znak. Znamená to, že GSC zobrazí stránky vašeho webu, které mají buď „Keyword1“ nebo „Keyword2“, ale ne obojí.
Příklad: Použijte kód k extrahování stránek z vašeho webu, které mají kterékoli ze dvou nebo více slov oddělených svislou čarou.
🔶 (Klíčové slovo1)\b(Klíčové slovo2)\b
Tento Regex kód má dvě specifická slova se znakem „\b“, což je symbol pro hranici slova. Poskytne stránky s těmito dvěma slovy a žádné další slovo, číslici nebo znak mezi nimi.
Příklad: Použijte tento kód ve svém filtru GSC, abyste věděli o stránkách, které mají dvě samostatná slova v pokračování.
🔶 (Klíčové slovo1)\w+(Klíčové slovo2)
Kód obsahuje dvě slova s metaznakem „\w+“ mezi nimi, kde „w“ je malé. Proto načte všechny stránky, které obsahují tato dvě slova, ať už v názvu, popisu nebo obsahu, bez ohledu na počet slov mezi nimi.
Příklad: Tento kód můžete použít k extrahování všech stránek na vašem webu, které obsahují alespoň tato dvě slova kdekoli v názvu, obsahu nebo meta.
🔶 (klíčové slovo)\bfráze
Jedná se o jednoduchý Regex kód, který spojuje řetězec se slovem v závorkách a za ním následuje slovní fráze. Metaznak „\b“ označuje hranici slova nebo žádný jiný znak mezi danými slovy.
Příklad: Tento kód Regex na vašem GSC zobrazí stránky, které mají daná slova v řadě kdekoli v článku, například „klíčové slovo“.
🔶 a-url.|.b-url.|.c-url.|.e-url.|.f-url.|.g-url.|.h-url.|.i-url.|.j -url.|.k-url.|.l-url.|.m-url.|.n-url.|.o-url.|.p-url.|.
Tento kód Regex uvádí několik adres URL „a,b,c,e,g….“ oddělených svislou čarou. Proto odfiltruje řetězce s některou z těchto adres URL.
Příklad: Na panelu GSC můžete použít takové vzory, abyste získali webové stránky, které mají v názvu nebo článku nějaké konkrétní adresy URL.
🔶 ^(jablko|koule|kočka|kachní farma)$
Daný kód implikuje shodu začátku řetězce s jedním z těchto daných slov, „jablko, míč, kočka nebo kachní farma“, protože je odděluje svislý znak. I když to také zajišťuje, že nebude mít žádné jiné slovo nebo znak.
Příklad: Kód můžete použít k získání podrobností o stránkách, které mají na začátku nějaká konkrétní klíčová slova.
🔶 .*\/$
Daný kód Regex má za cíl zachytit každý řetězec, ať už slova nebo čísla, ale měl by končit lomítkem.
Příklad: Můžete jej použít ke spárování stránek, které mají adresy URL končící lomítkem.
🔶 .(nejlepší|nahoře|vs|recenze).*
Tento kód bude odpovídat řetězcům, které mají na začátku tečku spolu s jedním z daných slov (oddělených svislou čarou) a dalšími slovy, čísly nebo speciálními znaky v pokračování.
Příklad: Takové vzory Regex můžete použít v komerčních zprávách, abyste pochopili trendy na trhu.
🔶 (koupit|levně|cena|koupit|objednat).
Tento kód bude odpovídat řetězcům, které mají jedno z daných slov oddělené svislou čarou a za nimi následují další slova, čísla nebo znaky.
Příklad: Tyto kódy jsou užitečné při vyhledávání transakčních vyhledávání nebo dotazů souvisejících s produkty vašeho webu.
🔶 (obličej(b|be)ook) 🔶 (f(a|e)ce(b|be)ook 🔶 (fa(c|s)(e|i)kniha)
Tyto kódy obsahují kombinaci slov v závorkách spolu se svislými znaky mezi nimi.
První regulární výraz bude odpovídat řetězcům, které obsahují slovo „face“ následované „b“ nebo „be“ a končí „ook“. Načtené stránky tedy budou mít slovo facebook nebo facebeook.
Druhý regulární výraz bude odpovídat řetězcům, které obsahují slovo „f“ následované „a“ nebo „e“ následovaným „ce“ následovaným „b“ nebo „be“ a končí „ook“. Načtené stránky tedy budou mít libovolnou jednu kombinaci, například facebook, fecebook, facebeook nebo fecebeook.
Třetí regulární výraz bude odpovídat řetězcům, které obsahují slovo „fa“ následované „c“ nebo „s“ následovaným „e“ nebo „I“ a končí „kniha“. Načtené stránky tedy budou mít libovolnou kombinaci, například facebook, facibook, fasebook nebo fasibook.
Příklad: Tyto kódy můžete použít k nalezení pravopisných chyb na vašich webových stránkách.
🔶 .wp-.
Daný kód bude odpovídat řetězcům s tečkou následovanou „wp-“ následovanými dalšími znaky.
Příklad: Je vhodný pro extrahování stránek s WordPress URL.
🔶 .*/url-1/.* vs.*/url-2/.*
Daný kód má dvě různé adresy URL s porovnávacím znakem Regex. Z vašeho webu načte dvě konkrétní adresy URL, aby se porovnaly jejich metriky.
Příklad: Tento kód můžete použít k porovnání návštěvnosti, návštěvnosti uživatelů a dalšího pokroku mezi dvěma konkrétními webovými stránkami na vašem webu.
Další méně časté regexy
🔺 (?i)\bklíčové slovo\b
Tento kód bude odpovídat řetězci, který obsahuje slovo „klíčové slovo“. Vyhledávání je bez ohledu na velikost písmen slova na webových stránkách.
🔺 „fráze“
Tento kód bude jednoduše odpovídat stránkám, které obsahují slovní spojení.
🔺 \w{5}
Kód bude odpovídat dotazům, které mají 5-slovné znaky.
🔺 \d{3}
Tento kód bude odpovídat dotazům, které mají přesně 3 číslice.
🔺 ([^” “]*)
Tento kód Regex bude odpovídat řetězcům, které neobsahují žádné znaky v uvozovkách.
🔺 (?i)\b(klíčové slovo1|klíčové slovo2|klíčové slovo3)\b
Tento daný kód se bude shodovat s řetězci, které mají kterékoli ze slov oddělené svislou čarou a jsou napsána jakýmikoli velkými nebo malými písmeny.
🔺 \W+
Kód bude odpovídat libovolnému počtu neslovních znaků, obvykle speciálních znaků.
🔺 \d{3,5}
Kód bude odpovídat všem řetězcům, které mají čísla 3 číslice a maximálně 5 číslic.
🔺 \b\w+\b
Kód bude odpovídat libovolnému počtu slovních znaků s hranicemi slov.
Závěrečná slova
Vyhledávač Google se po zavedení kódů Regex do výkonnostních filtrů stal zdrojem rozsáhlých informací. Vše, co vyžaduje, je pochopení struktury kódů pro extrakci analytických zpráv.
Na panelu můžete vytvořit několik kódů Regex, abyste získali zvláštní podrobnosti o výkonu svého webu a použili je k improvizaci pro lepší výsledky.
Dále se podívejte na triky vyhledávání Google, které vám pomohou zlepšit se ve vyhledávání online.