

Web scraping je myšlenka extrahování informací z webové stránky a jejich použití pro konkrétní případ použití.
Řekněme, že se pokoušíte extrahovat tabulku z webové stránky, převést ji na soubor JSON a použít soubor JSON k vytvoření některých interních nástrojů. Pomocí webového škrabání můžete extrahovat data, která chcete, zacílením na konkrétní prvky na webové stránce. Web scraping pomocí Pythonu je velmi oblíbenou volbou, protože Python poskytuje více knihoven jako BeautifulSoup nebo Scrapy pro efektivní extrakci dat.
Mít schopnost efektivně extrahovat data je také velmi důležité jako vývojář nebo datový vědec. Tento článek vám pomůže pochopit, jak efektivně oškrábat web a získat potřebný obsah, abyste s ním mohli manipulovat podle vašich potřeb. V tomto tutoriálu budeme používat balíček BeautifulSoup. Je to trendy balíček pro scrapování dat v Pythonu.
Table of Contents
Proč používat Python pro Web Scraping?
Python je pro mnoho vývojářů první volbou při vytváření webových scraperů. Existuje mnoho důvodů, proč je Python první volbou, ale v tomto článku si proberme tři hlavní důvody, proč se Python používá pro škrabání dat.
Podpora knihoven a komunity: Existuje několik skvělých knihoven, jako je BeautifulSoup, Scrapy, Selenium atd., které poskytují skvělé funkce pro efektivní odstraňování webových stránek. Vybudoval vynikající ekosystém pro web scraping, a také proto, že mnoho vývojářů po celém světě již Python používá, můžete rychle získat pomoc, když se zaseknete.
Automatizace: Python je známý svými automatizačními schopnostmi. Pokud se snažíte vytvořit komplexní nástroj, který se spoléhá na škrábání, je zapotřebí více než škrábání webu. Chcete-li například vytvořit nástroj, který sleduje cenu položek v internetovém obchodě, budete muset přidat nějakou funkci automatizace, aby mohl denně sledovat sazby a přidávat je do vaší databáze. Python vám dává možnost takové procesy snadno automatizovat.
Vizualizace dat: Web scraping je velmi využíván datovými vědci. Datoví vědci často potřebují extrahovat data z webových stránek. S knihovnami jako Pandas Python zjednodušuje vizualizaci dat z nezpracovaných dat.
Knihovny pro Web Scraping v Pythonu
V Pythonu je k dispozici několik knihoven, které zjednodušují škrábání webu. Pojďme si zde probrat tři nejoblíbenější knihovny.
#1. Krásná polévka
Jedna z nejpopulárnějších knihoven pro web scraping. BeautifulSoup pomáhá vývojářům seškrábat webové stránky od roku 2004. Poskytuje jednoduché metody pro navigaci, vyhledávání a úpravu stromu analýzy. Samotný Beautifulsoup také provádí kódování pro příchozí a odchozí data. Je dobře udržovaný a má skvělou komunitu.
#2. špinavý
Další populární framework pro extrakci dat. Scrapy má na GitHubu více než 43 000 hvězdiček. Může být také použit k seškrabování dat z API. Má také několik zajímavých vestavěných podpory, jako je odesílání e-mailů.
#3. Selen
Selenium není hlavně knihovna pro seškrabování webu. Místo toho je to balíček pro automatizaci prohlížeče. Ale můžeme snadno rozšířit jeho funkce pro scraping webových stránek. Pro ovládání různých prohlížečů používá protokol WebDriver. Selen je na trhu již téměř 20 let. Ale pomocí Selenium můžete snadno automatizovat a seškrabovat data z webových stránek.
Výzvy s Python Web Scraping
Člověk může čelit mnoha problémům, když se snaží získat data z webových stránek. Existují problémy, jako jsou pomalé sítě, nástroje proti škrábání, blokování založené na IP, blokování captcha atd. Tyto problémy mohou způsobit obrovské problémy při pokusu o seškrábnutí webové stránky.
Výzvy však můžete účinně obejít tím, že budete postupovat podle několika způsobů. Například ve většině případů je IP adresa blokována webem, když je v určitém časovém intervalu odesláno více než určité množství požadavků. Abyste se vyhnuli blokování IP adres, budete muset škrabku nakódovat tak, aby po odeslání požadavků vychladla.

Vývojáři také mají tendenci dávat honeypot pasti pro škrabky. Tyto pasti jsou obvykle neviditelné pro holé lidské oči, ale lze je prolézt škrabkou. Pokud škrábete web, který umístí takovou past na honeypot, budete muset svůj škrabák odpovídajícím způsobem nakódovat.
Captcha je další vážný problém se škrabkami. Většina webových stránek dnes používá captcha k ochraně přístupu robotů na jejich stránky. V takovém případě možná budete muset použít řešič captcha.
Smazání webu pomocí Pythonu
Jak jsme diskutovali, použijeme BeautifulSoup k odstranění webové stránky. V tomto tutoriálu seškrábneme historická data Etherea z Coingecka a uložíme data tabulky jako soubor JSON. Pojďme ke stavbě škrabky.
Prvním krokem je instalace BeautifulSoup a Requests. Pro tento tutoriál budu používat Pipenv. Pipenv je správce virtuálního prostředí pro Python. Pokud chcete, můžete také použít Venv, ale preferuji Pipenv. Diskuse o Pipenv je nad rámec tohoto návodu. Pokud se však chcete dozvědět, jak lze Pipenv používat, postupujte podle tohoto průvodce. Nebo, pokud chcete porozumět virtuálním prostředím Pythonu, postupujte podle tohoto průvodce.
Spusťte prostředí Pipenv v adresáři projektu spuštěním příkazu pipenv shell. Spustí subshell ve vašem virtuálním prostředí. Nyní, chcete-li nainstalovat BeautifulSoup, spusťte následující příkaz:
pipenv install beautifulsoup4
A pro instalaci požadavků spusťte příkaz podobný výše uvedenému:
pipenv install requests
Po dokončení instalace importujte potřebné balíčky do hlavního souboru. Vytvořte soubor s názvem main.py a importujte balíčky jako níže:
from bs4 import BeautifulSoup import requests import json
Dalším krokem je získat obsah stránky s historickými daty a analyzovat je pomocí analyzátoru HTML dostupného v BeautifulSoup.
r = requests.get('https://www.coingecko.com/en/coins/ethereum/historical_data#panel')
soup = BeautifulSoup(r.content, 'html.parser')
Ve výše uvedeném kódu je stránka přístupná pomocí metody get dostupné v knihovně požadavků. Analyzovaný obsah je pak uložen do proměnné zvané polévka.
Nyní začíná původní škrabací část. Nejprve budete muset správně identifikovat tabulku v DOM. Pokud otevřete tuto stránku a prohlédnete si ji pomocí vývojářských nástrojů dostupných v prohlížeči, uvidíte, že tabulka obsahuje tyto třídy table-stripped text-sm text-lg-normal.
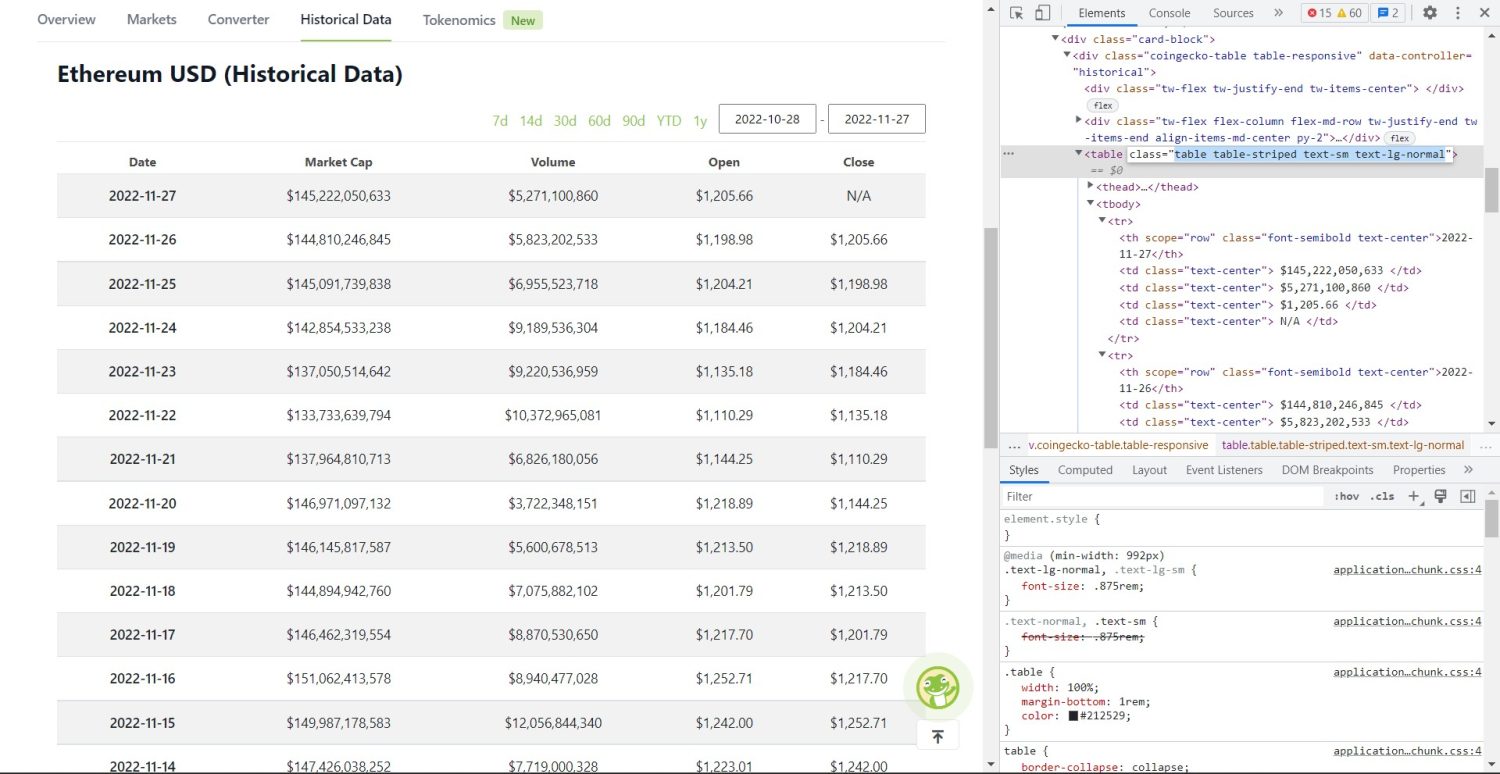 Tabulka historických dat Coingecko Ethereum
Tabulka historických dat Coingecko Ethereum
Pro správné zacílení této tabulky můžete použít metodu find.
table = soup.find('table', attrs={'class': 'table table-striped text-sm text-lg-normal'})
table_data = table.find_all('tr')
table_headings = []
for th in table_data[0].find_all('th'):
table_headings.append(th.text)
Ve výše uvedeném kódu je nejprve pomocí metody soup.find nalezena tabulka a poté pomocí metody find_all jsou prohledány všechny prvky tr uvnitř tabulky. Tyto prvky tr jsou uloženy v proměnné s názvem table_data. Tabulka obsahuje několik prvků pro nadpis. Nová proměnná s názvem table_headings je inicializována pro uchování názvů v seznamu.
Poté se pro první řádek tabulky spustí cyklus for. V tomto řádku jsou prohledány všechny prvky s th a jejich textová hodnota je přidána do seznamu table_headings. Text je extrahován pomocí textové metody. Pokud nyní vytisknete proměnnou table_headings, budete moci vidět následující výstup:
['Date', 'Market Cap', 'Volume', 'Open', 'Close']
Dalším krokem je seškrábat zbytek prvků, vygenerovat slovník pro každý řádek a pak přidat řádky do seznamu.
for tr in table_data:
th = tr.find_all('th')
td = tr.find_all('td')
data = {}
for i in range(len(td)):
data.update({table_headings[0]: th[0].text})
data.update({table_headings[i+1]: td[i].text.replace('n', '')})
if data.__len__() > 0:
table_details.append(data)
Toto je podstatná část kódu. Pro každý tr v proměnné table_data se nejprve prohledají th prvky. Prvky th jsou datum uvedené v tabulce. Tyto th prvky jsou uloženy uvnitř proměnné th. Podobně jsou všechny prvky td uloženy v proměnné td.
Inicializují se prázdná data slovníku. Po inicializaci procházíme rozsahem prvků td. U každého řádku nejprve aktualizujeme první pole slovníku první položkou tl. Kód table_headings[0]: čt[0].text přiřadí dvojici klíč-hodnota datum a první prvek.
Po inicializaci prvního prvku jsou ostatní prvky přiřazeny pomocí data.update({table_headings[i+1]: td[i].text.replace(‚n‘, ”)}). Zde je text prvků td nejprve extrahován pomocí textové metody a poté je vše n nahrazeno pomocí metody nahradit. Hodnota je pak přiřazena k i+1. prvku seznamu table_headings, protože i. prvek je již přiřazen.
Pokud pak délka datového slovníku překročí nulu, připojíme slovník k seznamu table_details. Pro kontrolu si můžete vytisknout seznam table_details. Hodnoty ale zapíšeme do souboru JSON. Podívejme se na tento kód,
with open('table.json', 'w') as f:
json.dump(table_details, f, indent=2)
print('Data saved to json file...')
K zápisu hodnot do souboru JSON s názvem table.json zde používáme metodu json.dump. Jakmile je zápis dokončen, vytiskneme data uložená do souboru json… do konzole.
Nyní spusťte soubor pomocí následujícího příkazu,
python run main.py
Po nějaké době uvidíte v konzole text Data uložená do souboru JSON…. V adresáři pracovních souborů také uvidíte nový soubor s názvem table.json. Soubor bude vypadat podobně jako následující soubor JSON:
[
{
"Date": "2022-11-27",
"Market Cap": "$145,222,050,633",
"Volume": "$5,271,100,860",
"Open": "$1,205.66",
"Close": "N/A"
},
{
"Date": "2022-11-26",
"Market Cap": "$144,810,246,845",
"Volume": "$5,823,202,533",
"Open": "$1,198.98",
"Close": "$1,205.66"
},
{
"Date": "2022-11-25",
"Market Cap": "$145,091,739,838",
"Volume": "$6,955,523,718",
"Open": "$1,204.21",
"Close": "$1,198.98"
},
// ...
// ...
]
Úspěšně jste implementovali webový škrabák pomocí Pythonu. Chcete-li zobrazit úplný kód, můžete navštívit toto úložiště GitHub.
Závěr
Tento článek pojednával o tom, jak byste mohli implementovat jednoduchý scrape Pythonu. Diskutovali jsme o tom, jak lze BeautifulSoup použít k rychlému odstranění dat z webu. Také jsme diskutovali o dalších dostupných knihovnách a o tom, proč je Python pro mnoho vývojářů první volbou pro scraping webových stránek.
Můžete se také podívat na tyto rámce pro stírání webu.