

Připravte se na to, že se dozvíte vše o budoucnosti databází nové generace, tj. bezserverových databázích!
Každá databáze, která dodržuje základní principy bezserverového počítání, je bezserverová databáze. Databáze bez serveru byla vytvořena pro zátěže, které jsou nepředvídatelné a mohou se rychle měnit.
Bez serveru neznamená, že nejsou potřeba žádné servery. Znamená to, že základní servery nemusíte spravovat, zajišťovat nebo platit vy.
Platíte za zdroje, které používáte, na základě jejich kapacity CPU a RAM a toho, jak jsou aktivní.
Table of Contents
Jak funguje databáze bez serveru
Model databáze bez serveru spoléhá na oddělení zpracování a úložiště. Musíte vytvořit koncový bod a nastavit minimální a maximální kapacitu.
Obrazový kredit: Simform
Poté můžete zadat dotazy na koncový bod. Tento proxy funguje jako odkaz na velké množství databázových zdrojů. To umožňuje, aby vaše připojení zůstala nedotčená, i když operace škálování probíhají v zákulisí.
Oddělení úložiště od zpracování má ještě jednu výhodu. Snížení na nulové zpracování je možné a musíte platit pouze za úložiště. Změna měřítka může být provedena za pouhých 5 sekund, v závislosti na aplikaci. Máte také přístup k zásobě „teplých“ zdrojů, které vám pomohou s vašimi potřebami.
Databáze bez serveru: Výhody

Efektivita nákladů
Pevný počet serverů je dražší než databáze bez serveru a nákup zabere více času. Může to být levnější než nastavení skupiny automatického škálování a je to také nákladově efektivnější, protože skládání strojových prostředků do přihrádek to zefektivňuje.
To zahrnuje licencování, instalaci, údržbu, podporu a opravy. Účtuje se vám pouze čas a paměť, které používáte ke spuštění kódu.
Automatická škálovatelnost
Vývojáři nepotřebují konfigurovat ani nastavovat žádné zásady nebo systémy automatického škálování, aby dosáhli škálování bez serveru na základě pracovní zátěže. To vše leží na bedrech poskytovatele cloudu, který musí splnit skutečné požadavky s odpovídajícími výkonovými pravomocemi.
Rychlé nasazení a aktualizace
Infrastruktura bez serveru eliminuje potřebu nahrávat kód na servery a konfigurovat nastavení backendu tak, aby fungovala aplikace. Pro vývojáře je snadné nahrát malé kousky kódu a poté vydat nový produkt. Vývojáři mohou nahrát oba kódy najednou a jednu funkci v daný čas.
To usnadňuje aktualizaci, opravy, opravy nebo rychlé přidávání nových funkcí do aplikace. Vývojáři mohou místo aktualizace celé aplikace provádět malé změny v aplikaci.
Vyšší produktivita
Ze svého systému bez serveru získáte více, pokud na něm strávíte méně času, vynaložíte méně úsilí v oblastech, kde je vyžadována interakce, a najmete tým profesionálů, který je optimálně dimenzován pro dosažení lepších výsledků.
Databáze bez serveru: Nevýhody
Problémy se studeným startem
Zvládání studených startů je jedním z nejdůležitějších a nejnáročnějších aspektů v této oblasti. Databáze bez serveru, která se nepoužívá, jednoduše přejde do nečinnosti, aby šetřila zdroje a zabránila zbytečnému výkonu.
Systém se „probudí“ a potřebuje čas na restart všech svých procesů. Pokud jste první, kdo se dotkne systému při jeho studeném startu, můžete zaznamenat zpoždění a pomalou dobu odezvy.
Obtížné testování a ladění aplikací
Model bez serveru představuje další výzvu. Je obtížné replikovat prostředí bez serveru pro testování a monitorování výkonu kódu před jeho uvedením do provozu. Částečně je to způsobeno tím, že vývojáři nemají přístup k backendovým službám poskytovatelů cloudu.
Chcete-li ladit složité systémy do hloubky a efektivně, nemůžete použít profiler nebo debugger. Máte možnost vyzkoušet nástroje třetích stran, které jsou na trhu stále dostupnější.
Více monitorování
Bezserverová řešení vyžadují, abyste kladli větší důraz na sledování a upozorňování na problémy s výkonem nebo nadměrné využívání zdrojů. To je z velké části způsobeno tím, že cloudová řešení jsou zřídkakdy open source.
Uzamčení dodavatele
Při migraci k jinému poskytovateli může výběr modelu bez serveru představovat problémy. To je způsobeno skutečností, že každý poskytovatel má jiné pracovní postupy a funkce.
Vlastnosti databáze bez serveru
Databáze bez serveru nabízejí některé z nejzajímavějších funkcí, jako například:
#1. Architektura pro více nájemců
Bezserverové databáze nabízejí tu výhodu, že mohou používat jeden zdroj fondu, který lze použít pro více projektů ve vaší organizaci. To je velké plus pro vývojáře, protože nemusí vytvářet datové zdroje specifické pro aplikaci.
Architektura s více nájemci to umožňuje. Vývojáři mohou nastavit, nakonfigurovat a nasadit více aplikací v rámci jednoho databázového clusteru.
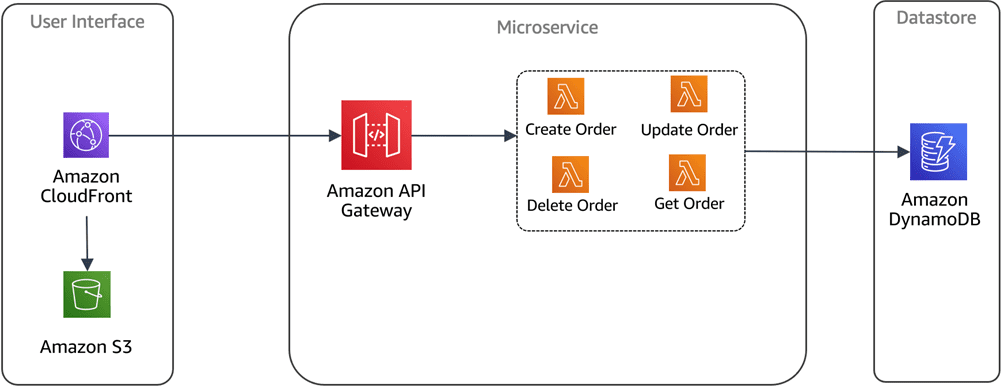 Obrazový kredit: AWS
Obrazový kredit: AWS
#2. Geo distribuce
Protože většina podniků působí na globální bázi, je nezbytné, aby data byla dostupná po celém světě. Zážitek v reálném čase lze zlepšit blízkostí datových center. Odpadá také bod selhání, takže možnost výpadku je velmi nepravděpodobná.
Bezserverové databáze umožňují replikovat více datových sad po celém světě bez dalších nástrojů nebo vlastního vývoje.
#3. Malá nebo žádná ruční správa serveru
Serverless je nesprávné označení. Jedná se o soubor serverů, které byly odebrány a jsou automatizované, aby vám usnadnily jejich správu. Všechny manuální úlohy, jako je zajišťování, plánování kapacity, škálování, údržba, aktualizace atd., se stále provádějí za scénou. Jsou velmi snadno použitelné a vyžadují malý nebo žádný ruční zásah.
#4. Fakturace na základě spotřeby
Bezserverová databáze, protože její poplatky jsou založeny na využití, je cenově nejefektivnější. Skladování není nutné. Platíte pouze za to, co používáte. Pokud se chcete vyhnout překročení rozpočtu, můžete nastavit limit útraty.
Relační vs. nerelační databáze bez serveru

Data digitálního věku lze rozdělit na provozní a analytická data. Podívejme se na několik různých možností databází, po kterých vývojáři sahají, a uvidíme, jak se porovnávají.
Většina společností vyžaduje k ukládání dat systémy OLTP (provozní) a OLAP (analytické). K podpoře svých obchodních potřeb mohou použít relační nebo nerelační databázi.
Relační databáze bez serveru
Relační databáze je typ databáze, který organizuje a shromažďuje data podle předem definovaných vztahů mezi klíčovými datovými body. Organizuje data tak, aby je mohlo najít a třídit více uživatelů bez změny logické kategorizace dat.
Eliminuje duplicitu dat v procesech ukládání. Structured Query Language je aplikační programové rozhraní (API) pro relační databanku.
Tento systém prezentuje data v tabulkovém formátu. Tato tabulka představuje entitu, jako je produkt nebo mobilní aplikace. Každý řádek je skutečnou hodnotou a každý řádek má jedinečný identifikátor, který je instancí tohoto typu entity. Proto se říká rekordům.
Sloupce na druhé straně obsahují atributy dat. Jsou skutečnou hodnotou entity. Přístup k datům je možný bez nutnosti reorganizace databázové tabulky.
NoSQL (nerelační) databáze bez serveru
Distribuce nerelačních databází (NoSQL) je pravděpodobnější než u SQL databází. Lze jej použít s velkým množstvím databází. Podniky potřebují k vytváření cloudových nativních aplikací využívat moderní možnosti, jako jsou databáze NoSQL.
Bezserverové databáze NoSQL se používají ve webových aplikacích v reálném čase. Mají jednoduchý design a dokážou rychle zpracovat velké množství dat s horizontálním měřítkem. To je ideální pro situace, kdy je schéma nejasné a může být vyžadována vysoká rychlost příjmu.
Databáze NoSQL bez serveru jsou velmi oblíbené, protože ukládají velké množství dat v mnoha formách, včetně grafů, dokumentů, párů klíč/hodnota a datových struktur orientovaných na sloupce. To vývojářům usnadňuje úpravu datové struktury.
Proč bychom měli používat databáze bez serveru?
Bezserverové databáze jsou skvělou volbou pro malé týmy, které nemají dostatek zaměstnanců na správu a škálování tradičních databází. Bezserverové databáze vyžadují malou infrastrukturu a údržbu. To znamená, že váš tým bude muset trávit méně času údržbou systému. Je také snadné vytvářet nové tabulky a testovat nové funkce pomocí databáze bez serveru.
Konečně náklady. Bezserverové databáze vám umožňují platit pouze za to, co používáte, aniž byste museli konfigurovat a dolaďovat náklady jako tradiční databáze. Databáze bez serveru jsou skvělé pro vývojáře a týmy, které potřebují rychle zavést nové funkce.
Případy použití databáze bez serveru

#1. Nové aplikace
Několik minut používání v průběhu týdne nebo dne. Pokud vlastníte blog s nízkou návštěvností a chcete platit pouze za dobu, po kterou některý uživatel přistupuje na vaše stránky, je tato možnost. Platíte za sekundu za databázové zdroje, které používáte.
#2. Elastická změna velikosti pro živé vysílání videa
Živé vysílání videa umožňuje architektura bez serveru. Ve scénářích živého vysílání videa může komunikovat více členů publika. Hostitel může být připojen k více mikrofonům současně. Hostitel může k obrazovce připojit několik členů publika nebo přátel a poté syntetizovat obraz do jednoho scénáře, který je prezentován divákům živého přenosu.
#3. Málo používané aplikace
Pokud máte aplikaci, na kterou jste hrdí a nevíte, jak bude přijata, a protože nechcete, aby aplikace selhala, je tato metoda pro vás. Jednoduše vytvořte koncový bod a databáze bez serveru se automaticky přizpůsobí potřebám vaší aplikace.
#4. Internet věcí (IoT)
IoT lze popsat jako termín, který popisuje zařízení, která se dnes nacházejí v domácnostech a která se mohou připojit k internetu a provádět různé funkce. FaaS tato zařízení stále více využívají k plnění svých úkolů. Odesílají a přijímají data pouze tehdy, když je spustí událost.
Firmy šetří peníze tím, že nemusí platit navíc za výpočetní výkon, který nevyužívají. FaaS umožňuje rychlé a automatické škálování, takže se vývojáři nemusí obávat nepředvídatelných vzorců používání.
Závěr
Tyto scénáře ukazují, že architektura bez serveru má mnoho výhod pro vývojáře a podniky. Bezserverové databáze mohou zlepšit vaši výpočetní rychlost a odolnost a zároveň snížit čas a náklady na škálování a zdroje. Existuje mnoho typů bezserverových databází, relačních i nerelačních. Všechny však mají stejný cíl: škálovat na požádání, aniž by se zvyšovalo zatížení managementu, a pouze snížit náklady