Vysvětlení algoritmů zpracování přirozeného jazyka (NLP).
Lidská řeč je pro počítače obtížně zpracovatelná kvůli své komplexnosti, která zahrnuje zkratky, víceznačnosti, gramatiku, kontext, slang a mnoho dalších proměnných.
Nicméně, mnoho obchodních procesů a operací spoléhá na stroje a vyžaduje interakci mezi lidmi a těmito systémy.
Vědci proto hledali řešení, které by umožnilo strojům dekódovat a učit se lidské jazyky s větší lehkostí.
Tak se zrodilo zpracování přirozeného jazyka (NLP), neboli algoritmy NLP. Tato technologie umožňuje vytvářet počítačové programy, které dokáží pochopit lidskou řeč, ať už v písemné nebo mluvené formě.
NLP využívá různorodé algoritmy pro interpretaci jazyků. Díky NLP se tato technologie stala klíčovou součástí umělé inteligence (AI) a pomáhá efektivněji zpracovávat nestrukturovaná data.
V tomto článku se podrobně podíváme na NLP a některé z nejdiskutovanějších algoritmů, které tato oblast zahrnuje.
Pojďme se do toho pustit!
Co je to NLP?
Zpracování přirozeného jazyka (NLP) je vědní obor na pomezí informatiky, lingvistiky a umělé inteligence. Zabývá se interakcí mezi lidským jazykem a počítači. Umožňuje programovat stroje tak, aby dokázaly analyzovat a zpracovávat rozsáhlá data v přirozeném jazyce.
Jinými slovy, NLP je moderní technologie, kterou stroje používají k porozumění, analýze a interpretaci lidské řeči. Dává strojům schopnost chápat texty i mluvený projev. S NLP mohou stroje provádět překlady, rozpoznávání řeči, shrnování textů, tematickou segmentaci a mnoho dalších úloh, které programátoři požadují.
Největší výhodou je, že NLP zpracovává veškeré úkoly v reálném čase pomocí sofistikovaných algoritmů, čímž se zvyšuje efektivita. Jde o technologii, která kombinuje strojové učení, hluboké učení a statistické modely s lingvistickými pravidly založenými na výpočetním modelování.
Algoritmy NLP umožňují počítačům zpracovávat jazyk prostřednictvím textů či hlasových dat a dekódovat jejich význam pro různé účely. Interpretační schopnosti počítačů se vyvinuly natolik, že dokáží porozumět i lidským pocitům a úmyslům skrytým v textu. NLP dokáže také predikovat nadcházející slova nebo věty, které uživatele napadají při psaní nebo mluvení.
Tato technologie existuje už desítky let a postupně se vyhodnocovala a zpřesňovala. Kořeny NLP sahají do lingvistiky a pomáhaly vývojářům při vytváření vyhledávačů. S rozvojem technologií se rozšířily i možnosti využití NLP.
Dnes se NLP uplatňuje v mnoha oblastech, od financí, přes vyhledávače a business intelligence, až po zdravotnictví a robotiku. Navíc se NLP stalo nedílnou součástí moderních systémů. Používá se v mnoha populárních aplikacích, jako jsou hlasově ovládané GPS navigace, chatboti pro zákaznickou podporu, digitální asistenti, převod řeči na text a mnoho dalších.
Jak NLP funguje?
NLP je dynamická technologie, která využívá různé metodiky pro překlad komplexního lidského jazyka pro stroje. Zejména využívá umělou inteligenci pro zpracování a překlad psaných či mluvených slov tak, aby jim počítače rozuměly.
Stejně jako lidé mají mozek pro zpracování veškerých vstupů, počítače využívají specializovaný program, který jim pomáhá zpracovat vstup na srozumitelný výstup. NLP funguje ve dvou fázích – zpracování dat a vývoj algoritmů.
Zpracování dat představuje první fázi, kdy se vstupní textová data připravují a čistí, aby je stroj dokázal analyzovat. Data se upravují tak, aby obsahovala veškeré relevantní informace pro počítačové algoritmy. Fáze zpracování dat v podstatě formátuje data do podoby, které stroj rozumí.
Techniky, které se používají v této fázi, zahrnují:
Zdroj: Amazonum
- Tokenizace: Vstupní text se rozděluje do menších jednotek, s kterými může NLP pracovat.
- Odstranění stopwords: Tato technika eliminuje z textu běžná a málo významná slova, a to tak, aby se zachovaly všechny relevantní informace v minimální formě.
- Lemmatizace a stemming: Lemmatizace a stemming redukují slova na jejich kořenovou formu, což usnadňuje jejich zpracování pro stroje.
- Part-of-Speech Tagging: Tato metoda označuje vstupní slova podle jejich slovního druhu (podstatná jména, přídavná jména, slovesa) pro následné zpracování.
Poté, co vstupní data projdou první fází, následuje fáze vývoje algoritmů, ve které se data zpracují. Mezi nejpoužívanější algoritmy NLP patří systémy založené na pravidlech a strojovém učení:
- Systémy založené na pravidlech: Tyto systémy využívají lingvistická pravidla pro konečné zpracování slov. Je to starší algoritmus, který se však stále hojně využívá.
- Systémy založené na strojovém učení: Jedná se o pokročilejší algoritmus, který kombinuje neuronové sítě, hluboké učení a strojové učení, aby si systém sám stanovil pravidla pro zpracování slov. Protože tento algoritmus používá statistické metody, rozhoduje o zpracování slov na základě trénovacích dat a průběžně provádí úpravy.
Různé kategorie algoritmů NLP
Algoritmy NLP jsou algoritmy nebo instrukce založené na strojovém učení, které se používají při zpracování přirozených jazyků. Zabývají se vývojem protokolů a modelů, které strojům umožňují interpretovat lidské jazyky.

Algoritmy NLP se mohou měnit v závislosti na přístupu umělé inteligence a trénovacích datech. Hlavním úkolem těchto algoritmů je efektivně transformovat matoucí a nestrukturované vstupy do informací, z nichž se stroj může učit.
Algoritmy NLP využívají principy přirozeného jazyka pro lepší srozumitelnost vstupů pro stroje. Jsou zodpovědné za to, aby stroj pochopil kontext daného vstupu, jinak by nemohl zpracovat daný požadavek.
Algoritmy NLP se dělí do tří základních kategorií. Modely umělé inteligence si vybírají kategorii v závislosti na přístupu datového vědce. Jsou to tyto kategorie:
#1. Symbolické algoritmy
Symbolické algoritmy tvoří jeden ze základních pilířů NLP. Analyzují význam vstupního textu a vytvářejí vztahy mezi různými pojmy.
Symbolické algoritmy používají symboly k reprezentaci znalostí a vztahů mezi koncepty. Tyto algoritmy pracují s logikou a přiřazují význam slovům na základě kontextu, díky čemuž dosahují vysoké přesnosti.
Znalostní grafy hrají klíčovou roli při definování pojmů vstupního jazyka a vztahů mezi nimi. Díky schopnosti přesně definovat pojmy a porozumět kontextům slov pomáhá tento algoritmus budovat vysvětlitelnou umělou inteligenci (XAI).
Symbolické algoritmy však mají omezenou škálovatelnost kvůli omezením daných pravidly.
#2. Statistické algoritmy
Statistické algoritmy strojům usnadňují práci tím, že procházejí texty, rozumí jim a hledají jejich význam. Je to velmi efektivní algoritmus NLP, protože umožňuje strojům učit se o lidském jazyce rozpoznáváním vzorců a trendů v textových vstupech. Tato analýza pomáhá strojům predikovat, které slovo bude pravděpodobně následovat za slovem aktuálním v reálném čase.
Statistické algoritmy se používají v mnoha aplikacích – od rozpoznávání řeči, přes analýzu sentimentu a strojové překlady, až po návrh textu. Důvodem jejich širokého použití je schopnost zpracovávat velké objemy dat.
Statistické algoritmy dokáží také rozpoznat, zda mají dvě věty v odstavci podobný význam, a určit, kterou z nich použít. Hlavní nevýhodou tohoto algoritmu je však jeho částečná závislost na inženýrství složitých funkcí.
#3. Hybridní algoritmy
Tento typ algoritmu NLP kombinuje sílu symbolických i statistických algoritmů a vytváří efektivnější výsledek. Zaměřuje se na hlavní výhody obou přístupů a potlačuje jejich nedostatky, což je klíčové pro dosažení vysoké přesnosti.

Existuje několik způsobů, jak lze tyto dva přístupy zkombinovat:
- Symbolické metody podporující strojové učení
- Strojové učení podporující symbolické metody
- Symbolické metody a strojové učení fungující paralelně
Symbolické algoritmy mohou podporovat strojové učení tak, že pomáhají trénovat model a snižují tak náročnost samostatného učení jazyka. Naopak strojové učení může podpořit symbolické metody tím, že vytvoří výchozí sadu pravidel pro symbolické metody, což ušetří datové vědce od manuálního vytváření pravidel.
Když symbolické metody a strojové učení pracují společně, vede to k lepším výsledkům, protože modely lépe rozumí konkrétnímu textu.
Nejlepší algoritmy NLP
Existuje mnoho algoritmů NLP, které pomáhají počítačům napodobovat lidský jazyk. Zde jsou některé z nejlepších algoritmů NLP, které můžete využít:
#1. Modelování témat
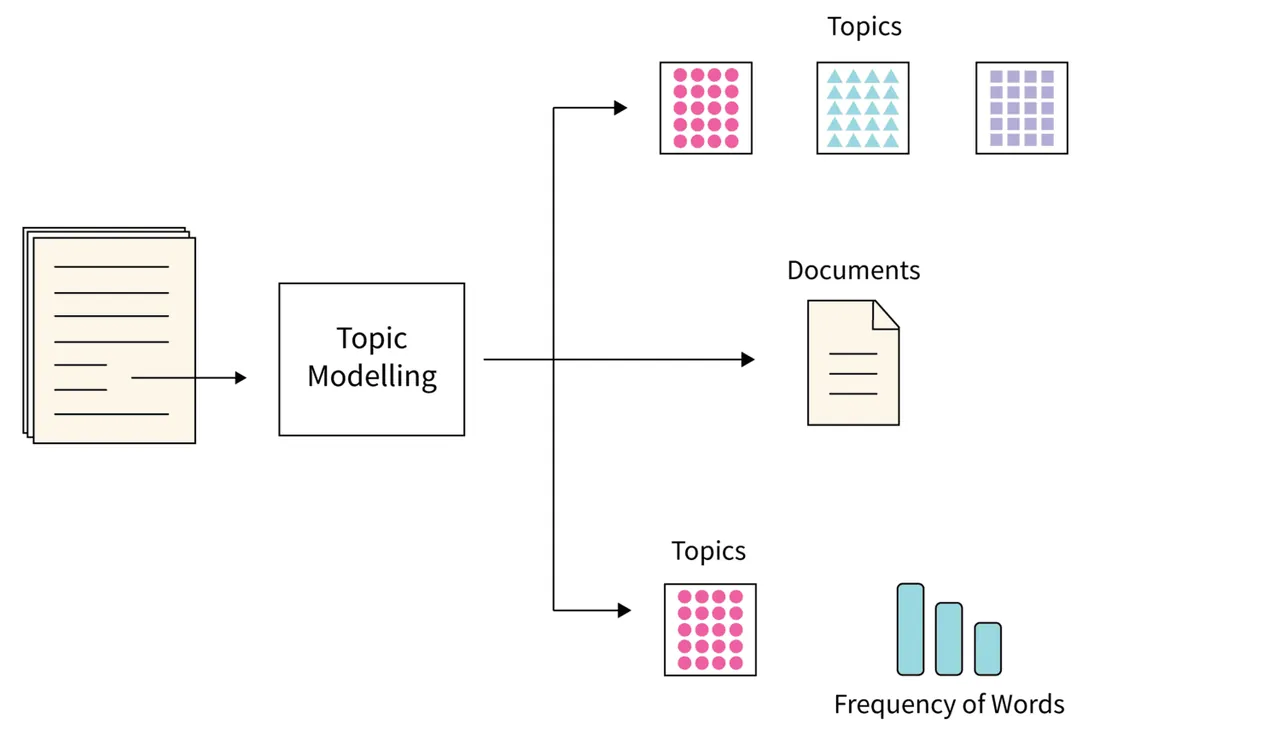 Zdroj obrázku: Scaler
Zdroj obrázku: Scaler
Modelování témat je algoritmus, který využívá statistické techniky NLP k nalezení klíčových témat v rozsáhlých textech.
Pomáhá strojům nalézt téma, které definuje konkrétní textovou sadu. Protože každý soubor textů může obsahovat více témat, tento algoritmus používá různé techniky k nalezení každého tématu, a to tak, že analyzuje konkrétní sady slovní zásoby.
Latentní Dirichletova alokace je oblíbená technika pro modelování témat. Je to algoritmus strojového učení bez dozoru, který shromažďuje a organizuje archivy velkých objemů dat, což není možné pomocí ruční anotace.
#2. Sumarizace textu
Jedná se o komplexní techniku NLP, ve které algoritmus shrnuje text stručným a srozumitelným způsobem. Sumarizace umožňuje rychle extrahovat klíčové informace bez nutnosti procházet každé slovo.
Sumarizaci lze provést dvěma způsoby:
- Sumarizace založená na extrakci: Stroj vybere klíčová slova a fráze z dokumentu bez úpravy originálu.
- Sumarizace založená na abstrakci: V tomto procesu se z textového dokumentu vytvářejí nové fráze a věty, které obsahují veškeré informace a záměry.
#3. Analýza sentimentu
Jedná se o algoritmus NLP, který pomáhá stroji pochopit význam nebo záměr textu od uživatele. Je široce používán v různých modelech umělé inteligence v podnicích, protože pomáhá společnostem pochopit, co si zákazníci myslí o jejich produktech a službách.
Díky analýze sentimentu v zákaznických textech či hlasových datech mohou modely umělé inteligence zjistit pocity zákazníků a pomoci vám k nim vhodně přistupovat.
#4. Extrakce klíčových slov
Extrakce klíčových slov je dalším populárním algoritmem NLP, který pomáhá získat relevantní slova a fráze z velkého množství textových dat.
Existují různé algoritmy pro extrakci klíčových slov, včetně populárních metod jako TextRank, Term Frequency a RAKE. Některé z těchto algoritmů mohou extrahovat dodatečná slova, zatímco jiné extrahují klíčová slova na základě obsahu textu.
Každý z algoritmů extrakce klíčových slov používá své vlastní teoretické a základní metody. Extrakce klíčových slov je užitečná pro mnoho organizací, protože pomáhá při ukládání, vyhledávání a načítání obsahu z rozsáhlých nestrukturovaných dat.
#5. Znalostní grafy
Znalostní grafy jsou považovány za jeden z nejlepších algoritmů NLP. Jedná se o techniku, která pro ukládání informací využívá trojice.
Algoritmus vytváří relace skládající se z předmětu, predikátu a entity. Vytvoření znalostního grafu vyžaduje více technik NLP. Přístup založený na předmětech se používá pro extrahování strukturovaných informací z nestrukturovaných textů.
#6. TF-IDF
TF-IDF je statistický algoritmus NLP, který se používá pro posouzení důležitosti slova pro konkrétní dokument v rámci rozsáhlé sbírky. Tato technika zahrnuje násobení charakteristických hodnot, kterými jsou:
- Frekvence termínu: Frekvence termínu udává, kolikrát se slovo v konkrétním dokumentu objeví. Stop slova mají v dokumentech obecně vysokou frekvenci.
- Inverzní frekvence dokumentu: Inverzní frekvence dokumentu naopak vyzdvihuje výrazy, které jsou vysoce specifické pro dokument, nebo slova, která se v celém korpusu dokumentů objevují méně často.
#7. Slovní mrak
Slovní mrak je vizualizační technika NLP, která zvýrazňuje nejdůležitější slova v textu tím, že je zobrazuje v tabulce.
Klíčová slova v textu se zobrazí větším písmem, zatímco málo významná slova jsou zobrazena malým písmem. Někdy se ty málo důležité položky ani nezobrazují.
Výukové zdroje
Pokud se chcete dozvědět více o zpracování přirozeného jazyka (NLP), můžete se podívat na následující kurzy a knihy.
#1. Data Science: Zpracování přirozeného jazyka v Pythonu
Tento kurz od Udemy je vysoce hodnocen studenty a byl pečlivě vytvořen společností Lazy Programmer Inc. Naučíte se vše o NLP a algoritmech NLP a naučíte se, jak psát analýzu sentimentu. Kurz se skládá z 88 přednášek a trvá celkem 11 hodin a 52 minut.
#2. Zpracování přirozeného jazyka: NLP s transformátory v Pythonu
V tomto populárním kurzu na Udemy se naučíte nejen NLP s modely transformátorů, ale také se naučíte vytvářet vyladěné modely. Kurz poskytuje kompletní pokrytí NLP pomocí 11,5 hodin videa na vyžádání a 5 článků. Kromě toho se seznámíte s technikami pro vytváření vektorů a předzpracování textových dat pro NLP.
#3. Zpracování přirozeného jazyka pomocí transformátorů
Tato kniha byla poprvé vydána v roce 2017 a jejím cílem je pomoci datovým vědcům a programátorům se naučit o NLP. Naučíte se stavět a optimalizovat modely transformátorů pro různé úkoly NLP. Dozvíte se také, jak využít transformátory pro učení mezijazykového přenosu.
#4. Praktické zpracování přirozeného jazyka
Autoři této knihy vysvětlují úkoly, problémy a přístupy k řešení v NLP. Kniha učí také o implementaci a hodnocení různých aplikací NLP.
Závěr
NLP je nedílnou součástí moderního světa umělé inteligence, která pomáhá strojům porozumět a interpretovat lidské jazyky. Algoritmy NLP jsou užitečné pro různé aplikace, od vyhledávačů a IT až po finance, marketing a mnoho dalších.
V článku byly zmíněny také nejlepší kurzy a knihy o NLP, které vám pomohou rozšířit vaše znalosti v této oblasti.
