
Představte si, že máte velkou infrastrukturu různých druhů zařízení, která musíte pravidelně udržovat nebo zajistit, aby nebyla nebezpečná pro okolní prostředí.
Jedním ze způsobů, jak toho dosáhnout, je pravidelné vysílání lidí na každé místo, aby zkontrolovali, zda je vše v pořádku. To je nějakým způsobem proveditelné, ale také časově a finančně nákladné. A pokud je infrastruktura dostatečně velká, možná ji nebudete schopni pokrýt celou do jednoho roku.
Dalším způsobem je automatizovat tento proces a nechat úlohy v cloudu ověřit za vás. Aby k tomu došlo, budete muset provést následující:
👉 Rychlý postup, jak získat obrázky zařízení. To mohou stále provádět osoby, protože je stále mnohem rychlejší udělat jen obrázek, jako všechny procesy ověření zařízení. To lze provést také fotografiemi pořízenými z automobilů nebo dokonce dronů, v takovém případě se stává mnohem rychlejším a automatizovanějším procesem shromažďování obrázků.
👉 Poté je potřeba všechny získané obrázky odeslat na jedno vyhrazené místo v cloudu.
👉 V cloudu potřebujete automatizovanou úlohu k vyzvednutí obrázků a jejich zpracování pomocí modelů strojového učení vyškolených k rozpoznání poškození nebo anomálií zařízení.
👉 Nakonec musí být výsledky viditelné pro požadované uživatele, aby bylo možné naplánovat opravu pro zařízení s problémy.
Podívejme se, jak můžeme dosáhnout detekce anomálií z obrázků v cloudu AWS. Amazon má několik předpřipravených modelů strojového učení, které můžeme pro tento účel použít.
Table of Contents
Jak vytvořit model pro detekci vizuálních anomálií
Chcete-li vytvořit model pro detekci vizuálních anomálií, budete muset provést několik kroků:
Krok 1: Jasně definujte problém, který chcete vyřešit, a typy anomálií, které chcete detekovat. To vám pomůže určit vhodnou testovací datovou sadu, kterou budete potřebovat k trénování modelu.
Krok 2: Shromážděte velkou datovou sadu snímků představujících normální a anomální podmínky. Označte obrázky, abyste označili, které jsou normální a které obsahují anomálie.
Krok 3: Vyberte architekturu modelu, která je vhodná pro daný úkol. To může zahrnovat výběr předem vyškoleného modelu a jeho doladění pro váš konkrétní případ použití nebo vytvoření vlastního modelu od začátku.
Krok 4: Trénujte model pomocí připravené datové sady a zvoleného algoritmu. To znamená použití přenosového učení k využití předem trénovaných modelů nebo trénování modelu od nuly pomocí technik, jako jsou konvoluční neuronové sítě (CNN).
Jak trénovat model strojového učení
Zdroj: aws.amazon.com
Proces trénování modelů strojového učení AWS pro detekci vizuálních anomálií obvykle zahrnuje několik důležitých kroků.
#1. Sbírejte data
Na začátku musíte shromáždit a označit velkou datovou sadu obrázků, které představují normální i anomální podmínky. Čím větší je soubor dat, tím lépe a přesněji lze model trénovat. Ale také to vyžaduje mnohem více času věnovaného trénování modelu.
Obvykle chcete mít v testovací sadě kolem 1000 obrázků, abyste měli dobrý začátek.
#2. Připravte Data
Obrazová data musí být nejprve předzpracována, aby je modely strojového učení mohly zachytit. Předběžné zpracování může znamenat různé věci, například:
- Čištění vstupních obrázků do samostatných podsložek, oprava metadat atd.
- Změna velikosti obrázků tak, aby splňovaly požadavky na rozlišení modelu.
- Rozdělte je na menší kousky obrázků pro efektivnější a paralelní zpracování.
#3. Vyberte model
Nyní si vyberte ten správný model pro správnou práci. Buď si vyberete předem trénovaný model, nebo si můžete vytvořit vlastní model vhodný pro detekci vizuálních anomálií na modelu.
#4. Vyhodnoťte výsledky
Jakmile model zpracuje váš soubor dat, musíte ověřit jeho výkon. Chcete také zkontrolovat, zda jsou výsledky vyhovující potřebám. To může například znamenat, že výsledky jsou správné na více než 99 % vstupních dat.
#5. Nasadit model
Pokud jste s výsledky a výkonem spokojeni, nasaďte model s konkrétní verzí do prostředí účtu AWS, aby jej procesy a služby mohly začít používat.
#6. Sledovat a zlepšovat
Nechte jej procházet různými testovacími úlohami a soubory obrazových dat a neustále vyhodnocujte, zda jsou požadované parametry pro správnost detekce stále na místě.
Pokud ne, přeškolte model tak, že zahrnete nové datové sady, u kterých model poskytl nesprávné výsledky.
Modely strojového učení AWS
Nyní se podívejte na některé konkrétní modely, které můžete využít v cloudu Amazon.
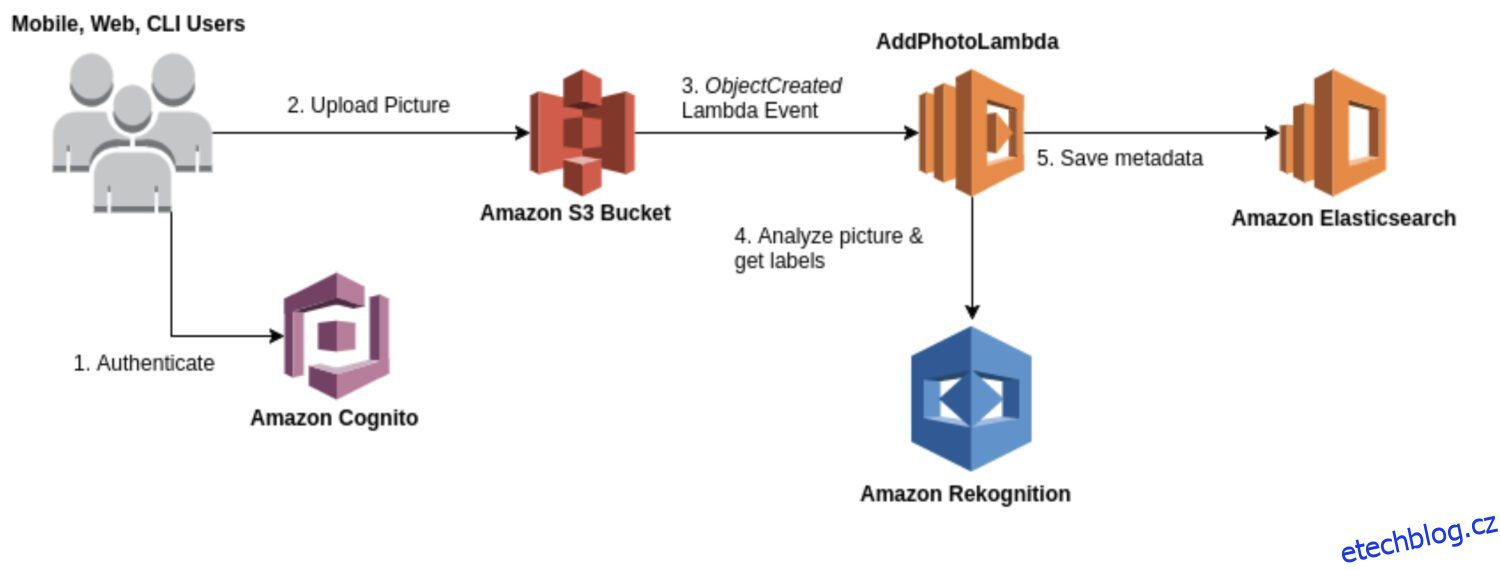
Rozpoznání AWS
 Zdroj: aws.amazon.com
Zdroj: aws.amazon.com
Rekognition je univerzální služba pro analýzu obrazu a videa použitelná pro různé případy použití, jako je rozpoznávání obličeje, detekce objektů a rozpoznávání textu. Většinu času budete používat model Rekognition pro počáteční hrubé generování výsledků detekce k vytvoření datového jezera identifikovaných anomálií.
Poskytuje řadu předpřipravených modelů, které můžete používat bez školení. Rekognition také poskytuje analýzu obrázků a videí v reálném čase s vysokou přesností a nízkou latencí.
Zde je několik typických případů použití, kdy je Rekognition dobrou volbou pro detekci anomálií:
- Mějte obecný případ použití pro detekci anomálií, jako je detekce anomálií v obrázcích nebo videích.
- Provádějte detekci anomálií v reálném čase.
- Integrujte svůj model detekce anomálií se službami AWS, jako je Amazon S3, Amazon Kinesis nebo AWS Lambda.
A zde jsou některé konkrétní příklady anomálií, které můžete pomocí Rekognition zjistit:
- Anomálie ve tvářích, jako je detekce výrazů obličeje nebo emocí mimo normální rozsah.
- Chybějící nebo špatně umístěné objekty ve scéně.
- Nesprávně napsaná slova nebo neobvyklé vzory textu.
- Neobvyklé světelné podmínky nebo neočekávané objekty ve scéně.
- Nevhodný nebo urážlivý obsah na obrázcích nebo videích.
- Náhlé změny v pohybu nebo neočekávané vzorce pohybu.
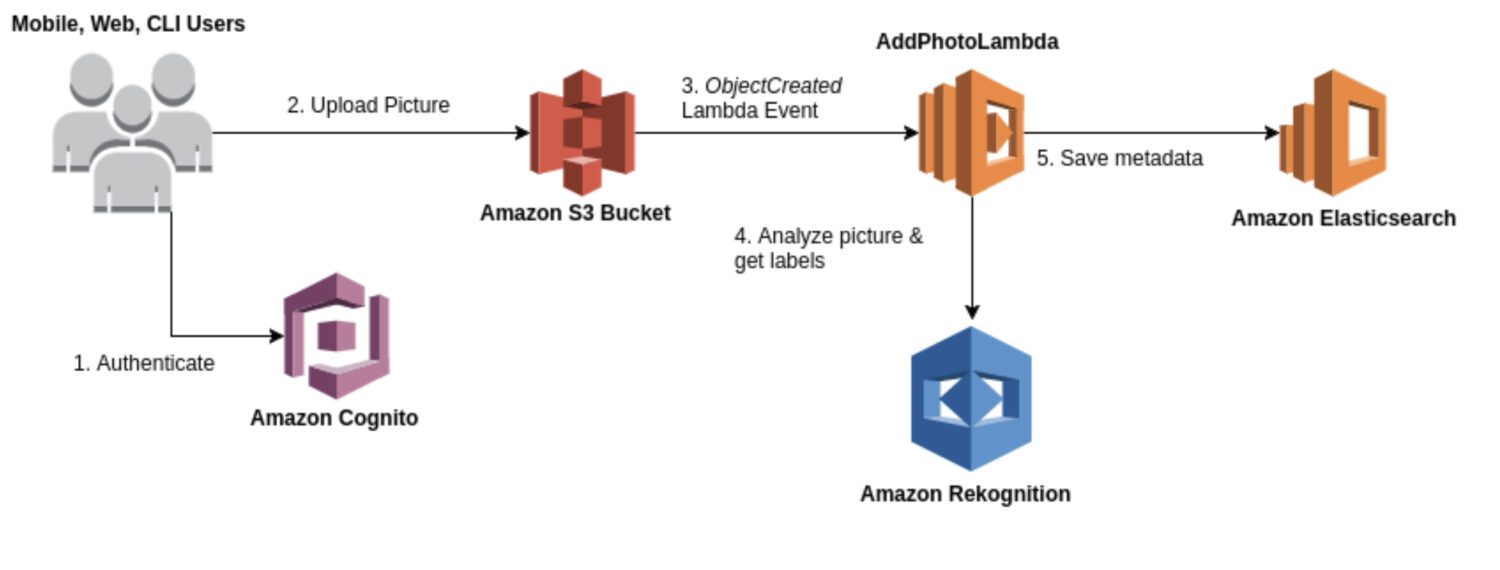
AWS Lookout for Vision
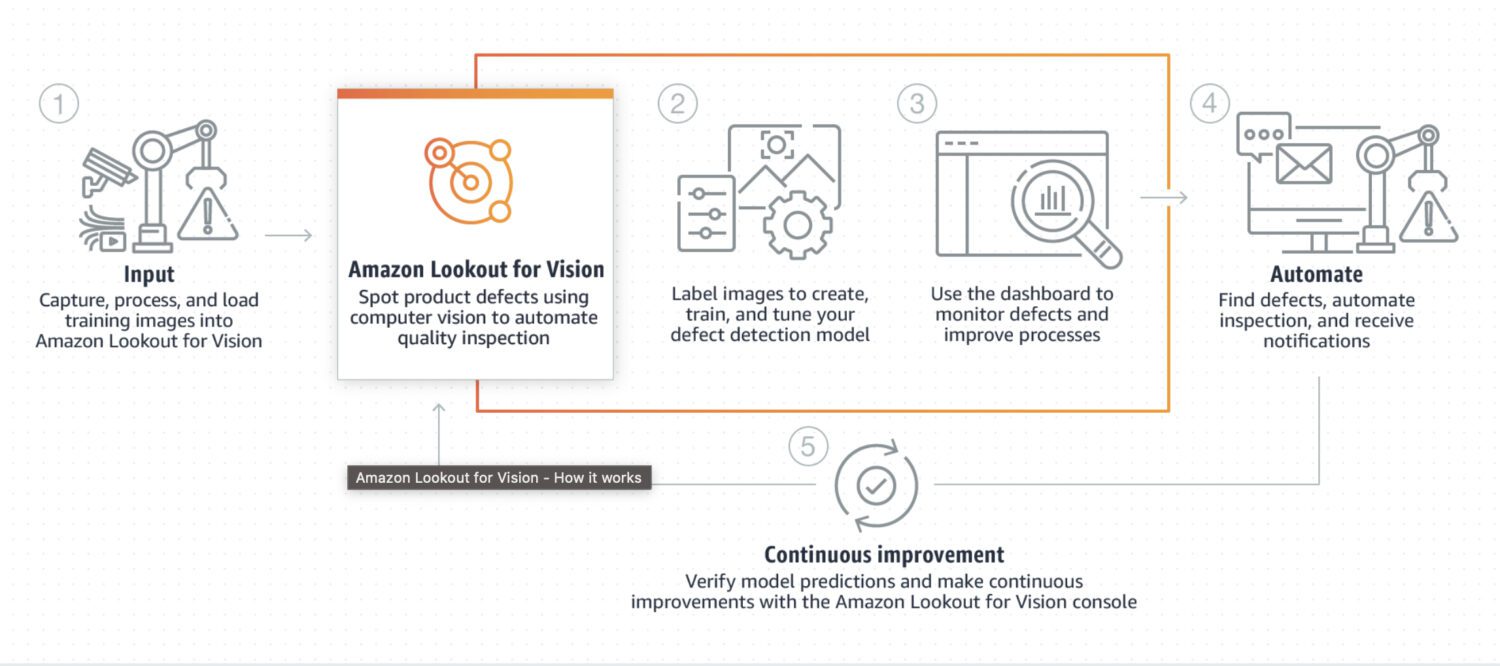 Zdroj: aws.amazon.com
Zdroj: aws.amazon.com
Lookout for Vision je model speciálně navržený pro detekci anomálií v průmyslových procesech, jako jsou výrobní a výrobní linky. Obvykle to vyžaduje určité vlastní předzpracování kódu a následné zpracování obrázku nebo konkrétní výřez obrázku, obvykle prováděný pomocí programovacího jazyka Python. Většinou se specializuje na některé velmi zvláštní problémy na obrázku.
K vytvoření vlastního modelu pro detekci anomálií vyžaduje vlastní školení na datové sadě normálních a anomálních snímků. Není tak zaměřen v reálném čase; spíše je určen pro dávkové zpracování obrázků se zaměřením na přesnost a preciznost.
Zde je několik typických případů použití, kdy je Lookout for Vision dobrou volbou, pokud potřebujete zjistit:
- Vady ve vyrobených produktech nebo identifikace poruch zařízení na výrobní lince.
- Velká datová sada obrázků nebo jiných dat.
- Anomálie v reálném čase v průmyslovém procesu.
- Anomálie integrovaná s dalšími službami AWS, jako je Amazon S3 nebo AWS IoT.
A zde je několik konkrétních příkladů anomálií, které můžete zjistit pomocí Lookout for Vision:
- Vady vyrobených produktů, jako jsou škrábance, promáčkliny nebo jiné nedokonalosti, mohou ovlivnit kvalitu produktu.
- Selhání zařízení na výrobní lince, jako je detekce rozbitých nebo nefunkčních strojů, které mohou způsobit zpoždění nebo bezpečnostní rizika.
- Problémy kontroly kvality na výrobní lince zahrnují detekci produktů, které nesplňují požadované specifikace nebo tolerance.
- Bezpečnostní rizika na výrobní lince zahrnují detekci předmětů nebo materiálů, které mohou představovat riziko pro pracovníky nebo zařízení.
- Anomálie ve výrobním procesu, jako je detekce neočekávaných změn v toku materiálů nebo produktů výrobní linkou.
AWS Sagemaker
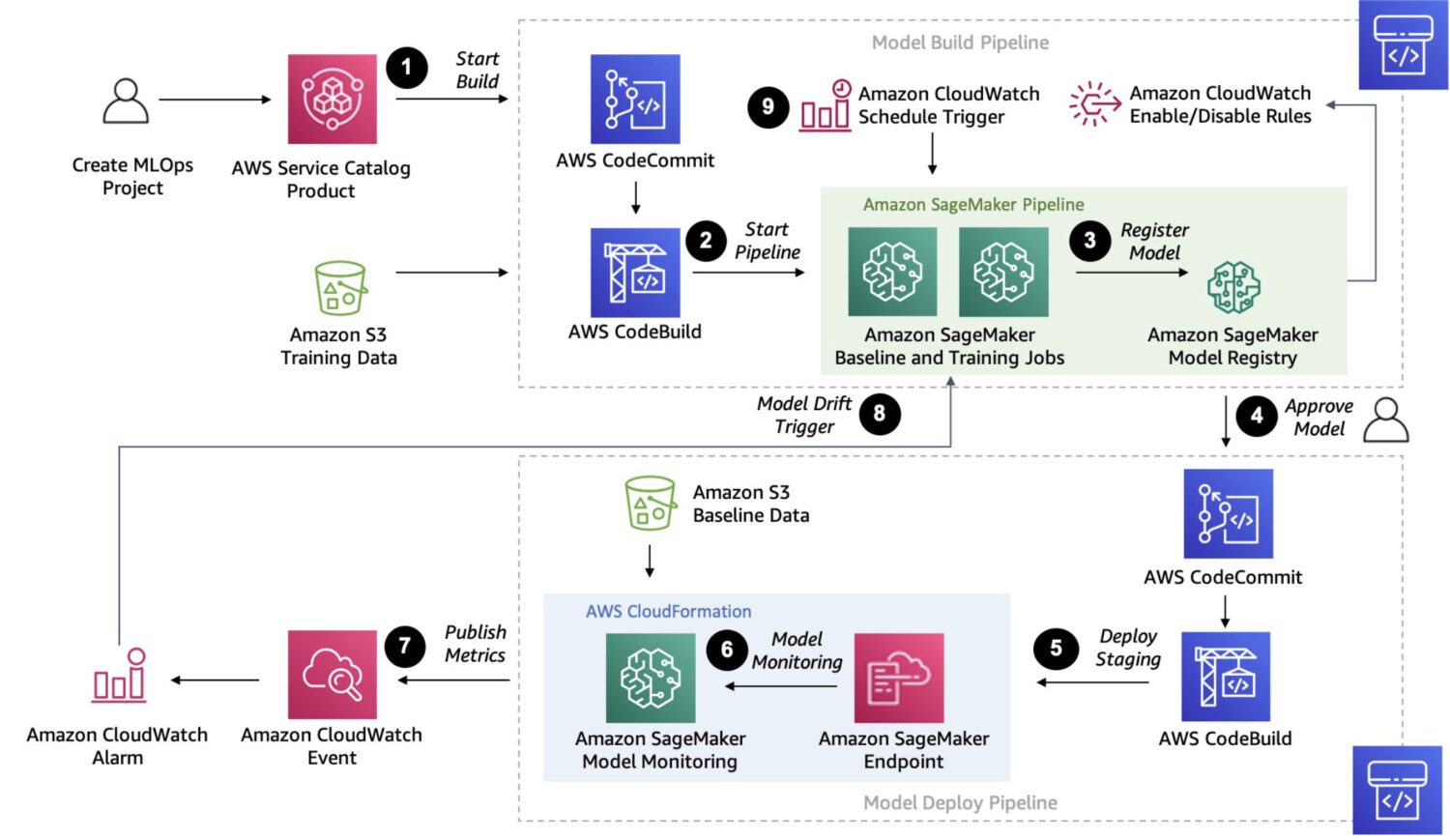 Zdroj: aws.amazon.com
Zdroj: aws.amazon.com
Sagemaker je plně spravovaná platforma pro vytváření, školení a nasazení vlastních modelů strojového učení.
Je to mnohem robustnější řešení. Ve skutečnosti poskytuje způsob, jak propojit a provést několik vícekrokových procesů do jednoho řetězce úloh, které následují jedna po druhé, podobně jako to umí funkce AWS Step.
Ale protože Sagemaker používá pro své zpracování ad-hoc instance EC2, neexistuje žádný limit 15 minut pro zpracování jedné úlohy, jako v případě funkcí lambda AWS ve funkcích AWS Step Functions.
Pomocí Sagemaker můžete také provádět automatické ladění modelu, což je rozhodně funkce, která z něj dělá vynikající volbu. Nakonec může Sagemaker bez námahy nasadit model do produkčního prostředí.
Zde je několik typických případů použití, kdy je SageMaker dobrou volbou pro detekci anomálií:
- Konkrétní případ použití, který nepokrývají předem vytvořené modely nebo rozhraní API, a pokud potřebujete vytvořit vlastní model přizpůsobený vašim konkrétním potřebám.
- Pokud máte velkou datovou sadu obrázků nebo jiných dat. Předem postavené modely v takových případech vyžadují určité předběžné zpracování, ale Sagemaker to zvládne i bez něj.
- Pokud potřebujete provést detekci anomálií v reálném čase.
- Pokud potřebujete integrovat svůj model s dalšími službami AWS, jako je Amazon S3, Amazon Kinesis nebo AWS Lambda.
A zde jsou některé typické detekce anomálií, které je Sagemaker schopen provést:
- Odhalování podvodů ve finančních transakcích, například neobvyklé vzorce výdajů nebo transakce mimo normální rozsah.
- Kybernetická bezpečnost v síťovém provozu, jako jsou neobvyklé vzorce přenosu dat nebo neočekávaná připojení k externím serverům.
- Lékařská diagnóza v lékařských snímcích, jako je detekce nádorů.
- Anomálie ve výkonu zařízení, jako je detekce změn vibrací nebo teploty.
- Kontrola kvality ve výrobních procesech, jako je zjišťování vad ve výrobcích nebo zjišťování odchylek od očekávaných norem kvality.
- Neobvyklé vzorce spotřeby energie.
Jak začlenit modely do architektury bez serveru
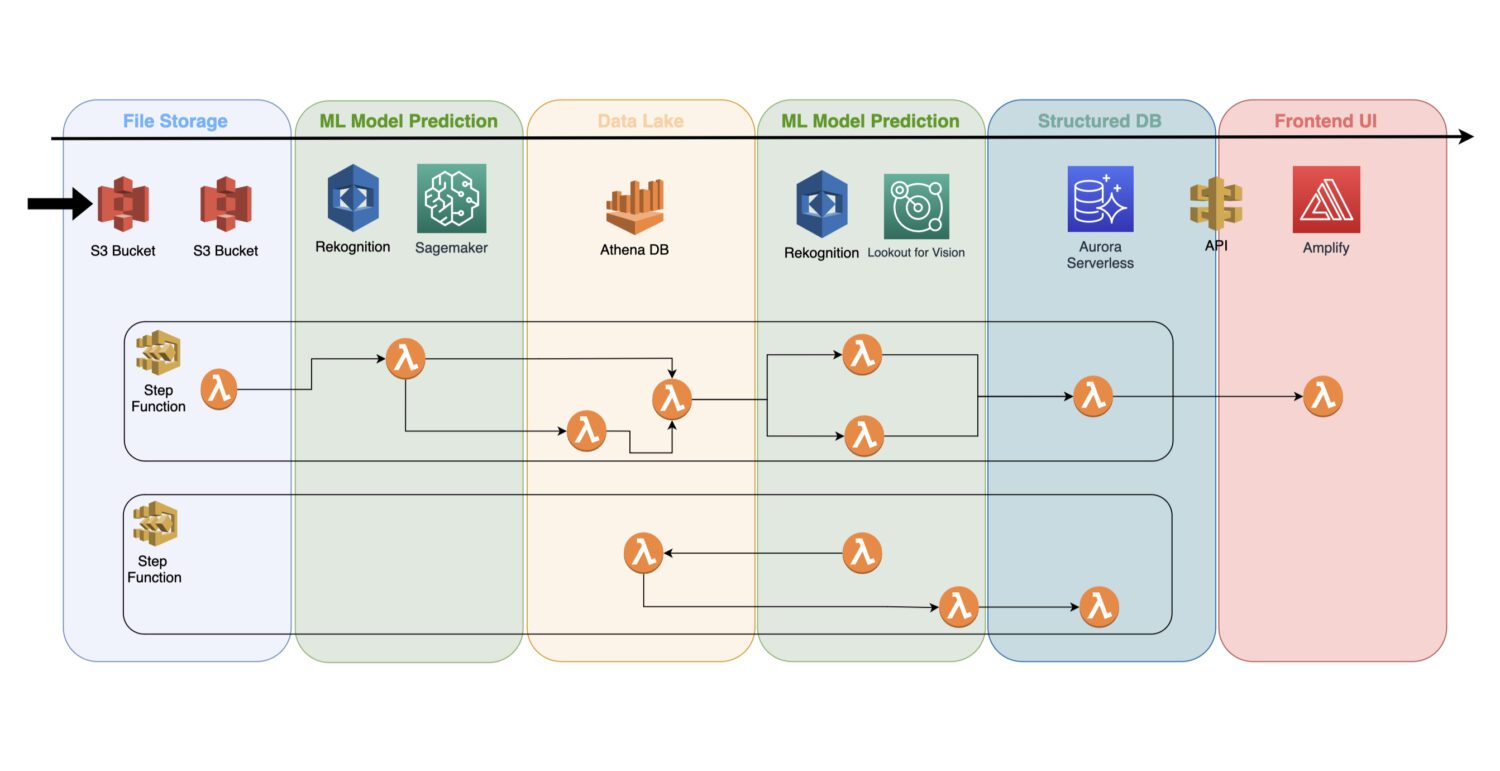
Trénovaný model strojového učení je cloudová služba, která na pozadí nepoužívá žádné clusterové servery; lze jej tedy snadno začlenit do stávající architektury bez serveru.
Automatizace se provádí pomocí funkcí lambda AWS, které jsou propojeny do úlohy několika kroků v rámci služby AWS Step Functions.
Počáteční detekci obvykle potřebujete hned po shromáždění obrázků a jejich předběžném zpracování na kbelíku S3. Zde vygenerujete detekci atomových anomálií na vstupních obrázcích a výsledky uložíte do datového jezera, například reprezentovaného databází Athena.
V některých případech tato počáteční detekce nestačí pro váš konkrétní případ použití. Možná budete potřebovat další, podrobnější detekci. Například počáteční (např. Rozpoznávací) model může detekovat nějaký problém na zařízení, ale není možné spolehlivě identifikovat, o jaký druh problému se jedná.
K tomu možná budete potřebovat jiný model s jinými schopnostmi. V takovém případě můžete spustit druhý model (např. Lookout for Vision) na podmnožině obrázků, kde původní model identifikoval problém.
Je to také dobrý způsob, jak ušetřit nějaké náklady, protože nemusíte spustit druhý model na celé sadě obrázků. Místo toho jej spustíte pouze na smysluplné podmnožině.
Funkce AWS Lambda pokryje všechna taková zpracování pomocí kódu Python nebo Javascript uvnitř. Záleží pouze na povaze procesů a na tom, kolik funkcí lambda AWS budete muset zahrnout do toku. 15minutový limit pro maximální dobu trvání volání lambda AWS určí, kolik kroků musí takový proces obsahovat.
Závěrečná slova
Práce s cloudovými modely strojového učení je velmi zajímavá práce. Když se na to podíváte z pohledu dovedností a technologií, zjistíte, že potřebujete mít tým s velkým množstvím dovedností.
Tým musí porozumět tomu, jak trénovat model, ať už je předem postavený nebo vytvořený od začátku. To znamená, že do vyvažování spolehlivosti a výkonnosti výsledků je zapojeno hodně matematiky nebo algebry.
Potřebujete také nějaké pokročilé dovednosti v kódování Python nebo Javascript, databáze a dovednosti SQL. A až bude veškerá práce s obsahem hotová, potřebujete dovednosti DevOps, abyste jej mohli zapojit do kanálu, který z něj udělá automatizovanou úlohu připravenou k nasazení a provedení.
Definování anomálie a trénování modelu je jedna věc. Ale je to výzva integrovat to všechno do jednoho funkčního týmu, který dokáže zpracovat výsledky modelů a ukládat data efektivním a automatizovaným způsobem, aby je mohla poskytovat koncovým uživatelům.
Dále se podívejte na vše o rozpoznávání obličeje pro firmy.