10 nejlepších řešení databáze grafů k vyzkoušení
Grafové databáze se specializují na ukládání a efektivní zpracování dat s rozsáhlými vzájemnými propojeními. Chcete vědět, kdy je nejvhodnější použít konkrétní grafovou databázi? Čtěte dále a dozvíte se více.
„Data jsou novým palivem.“ Úspěch každé organizace závisí na efektivitě, s jakou ukládá a využívá svá data. Každý den je vygenerováno přibližně 2,5 kvintilionu bajtů dat. To vyžaduje robustní a spolehlivé systémy, kde lze data bezpečně ukládat a efektivně spravovat. Původně se k tomuto účelu využívaly relační databáze.
S postupem času se však objem a rozmanitost dat rychle měnily. Objevila se potřeba ukládat videa, audia, obrázky a další typy dat. To vedlo k vývoji databází SQL, NoSQL, Hadoop, a také grafových databází. Každá z nich má specifické případy použití a je určena pro různé formáty dat. Grafové databáze byly vytvořeny s cílem zjednodušit práci s daty a efektivně je ukládat.
Grafové databáze
Graf je datová struktura, která se skládá z uzlů a hran. Databáze je strukturovaný soubor tabulek, které ukládají data a vztahy mezi nimi. Grafová databáze specificky ukládá data do uzlů a vztahy mezi nimi do hran. Tyto databáze jsou navrženy pro zpracování dotazů v reálném čase a pro efektivní správu vztahů mnoho-k-mnoha mezi různými entitami.
Mezi oblíbené modely grafů patří grafy vlastností a RDF grafy. Grafy vlastností se obvykle používají pro analýzy a dotazy, zatímco RDF grafy jsou vhodné pro integraci dat. Rozdíl spočívá v tom, že RDF grafy jsou reprezentovány jako trojice – subjekt, predikát a objekt.
Grafové databáze ukládají data v uzlech a vztahy mezi nimi jako hrany mezi těmito uzly. Hrany mohou být orientované (jednosměrné) nebo neorientované (obousměrné).
Zpracování dotazů probíhá procházením grafu. K efektivnímu vyhodnocování dotazů se používají algoritmy pro procházení grafů, které umožňují hledat cesty mezi uzly, určovat vzdálenosti, detekovat vzory a smyčky a vytvářet shluky.
Využití grafových databází
Grafové databáze se často využívají při odhalování podvodů. Uzly mohou reprezentovat osoby, adresy, data narození apod. Hrany pak mohou vyjadřovat interakce. Pokud podvodný uzel interaguje s uzlem, který není označen jako podvodný, vytvoří se spojení, které se následně označí jako podezřelé.
Sociální sítě využívají grafové databáze k zobrazování doporučení osob, které byste mohli znát, a obsahu, který by vás mohl zajímat. To je umožněno díky algoritmům procházení grafů.
Grafové databáze se také efektivně využívají pro síťové mapování, správu infrastruktury a konfigurací.
Grafová databáze vs. relační databáze
V grafové databázi jsou tabulky s řádky a sloupci nahrazeny uzly a hranami. Vztahy mezi daty jsou v grafové databázi uloženy přímo na hranách.
Relační databáze naopak ukládají vztahy mezi tabulkami pomocí cizích klíčů a referencí mezi tabulkami. V grafové databázi je extrahování dat a dotazování jednodušší a nevyžaduje složitá spojení. To není případ relačních databází.
Relační databáze jsou nejvhodnější pro transakční operace, zatímco grafové databáze jsou ideální pro aplikace, které vyžadují složité vztahy a práci s velkým objemem dat.
Grafové databáze podporují strukturovaná, polostrukturovaná i nestrukturovaná data, zatímco relační databáze vyžadují striktně definované schéma.
Grafové databáze se lépe hodí pro dynamické požadavky, zatímco relační databáze se tradičně používají pro známé a statické problémy.
Nyní se podívejme na některá z nejlepších řešení grafových databází.
Cayley
Cayley je grafová databáze s otevřeným zdrojovým kódem pod licencí Apache 2.0. Je napsána v jazyce Go a pracuje s propojenými daty. Cayley se používala například při vývoji Freebase a znalostního grafu Google. Podporuje více dotazovacích jazyků jako MQL a Javascript s grafovým objektem založeným na Gremlinu.

Cayley je uživatelsky přívětivá, rychlá a má modulární strukturu. Lze ji integrovat s různými backendovými úložišti, jako je LevelDB, MongoDB a Bolt. Podporuje různé API třetích stran napsané v jazycích jako Java, .NET, Rust, Haskell, Ruby, PHP, Javascript a Clojure. Může být nasazena v Dockeru a Kubernetes. Cayley se používá v informačních technologiích, softwarovém inženýrství a finančních službách.
Amazon Neptune
Amazon Neptune je známý svou vysokou efektivitou při práci s datovými sadami s rozsáhlými propojeními. Je to spolehlivá, bezpečná a plně spravovaná služba, která podporuje API s otevřeným grafem. Dokáže ukládat miliardy vztahů a zpracovávat dotazy s extrémně nízkou latencí (v řádu milisekund).
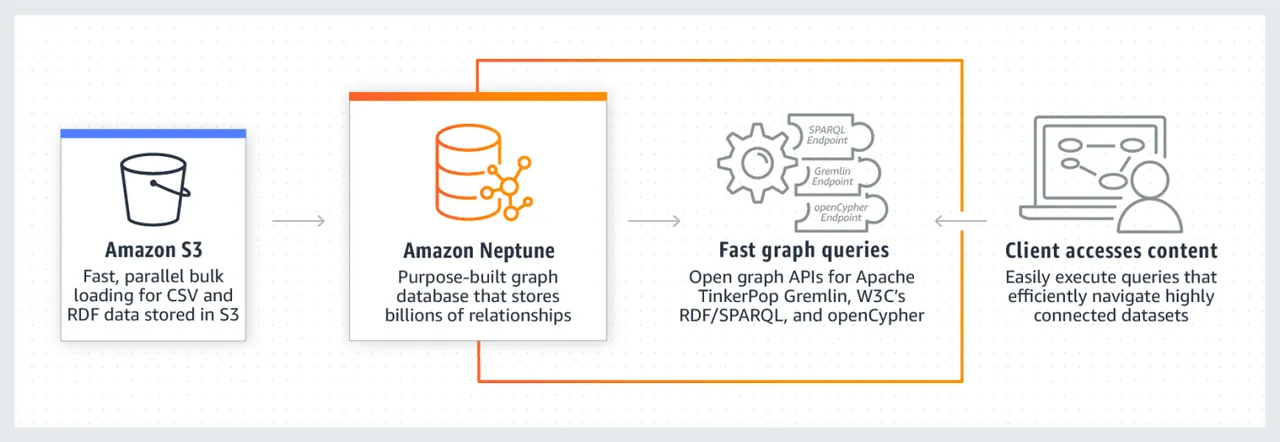
Datový model grafu Neptune se skládá ze čtyř pozic: subjekt (S), predikát (P), objekt (O) a graf (G). Každá pozice slouží k uložení zdrojového uzlu, cílového uzlu, vztahu mezi nimi a jejich vlastností. Neptune také využívá mezipaměť, která urychluje provádění čtecích dotazů. Data jsou uložena ve formě databázových clusterů, kde každý cluster obsahuje primární instanci databáze a repliky pro čtení. Zabezpečení databáze Neptune je zajištěno pomocí ověřování IAM, certifikace SSL a monitorování protokolů. Migrace dat do Neptune je snadná. Databáze zajišťuje odolnost vytvářením replik a pravidelných záloh. Mezi společnosti, které Neptune využívají, patří například Herren, Onedot, Juncture a Hi Platform.
Neo4j
Neo4j je škálovatelná, bezpečná, spolehlivá a plně spravovaná grafová databáze. Je napsaná v Javě a jako dotazovací jazyk používá Cypher. Komunikace s databází probíhá přes protokol Bolt a všechny transakce se realizují přes HTTP. Neo4j je výrazně rychlejší při vyhodnocování dotazů ve srovnání s tradičními relačními databázemi. Neo4j nemá režii složitých spojení a jeho optimalizace funguje dobře i u velkých a vysoce propojených datových sad. Nabízí možnost ukládání grafů spolu s vlastnostmi ACID, které se obvykle spojují s relačními databázemi.

Neo4j podporuje řadu jazyků jako Java, .NET, Node.js, Ruby, Python atd. prostřednictvím ovladačů. Používá se také v oblasti vědy o grafech, analytiky a strojového učení. Neo4j Aura DB je cloudová grafová databáze, která je odolná proti chybám a plně spravovaná. Neo4j používají společnosti jako Microsoft, Cisco, Adobe, eBay, IBM a Samsung.
ArangoDB
ArangoDB je multimodelová databáze s otevřeným zdrojovým kódem. Multimodelový přístup umožňuje uživatelům dotazovat se na data pomocí libovolného jazyka. Uzly a hrany ArangoDB jsou reprezentovány jako dokumenty JSON. Každý dokument má unikátní ID. Vztahy mezi dvěma uzly jsou označeny jako hrany s uloženými jedinečnými ID. Dobrý výkon je zajištěn hash indexy.

Procházení, spojování a vyhledávání v ArangoDB jsou optimalizované. Databáze umožňuje navrhovat, škálovat a přizpůsobovat různé architektury. Hraje klíčovou roli v komplexních úlohách datové vědy, jako je extrakce funkcí a pokročilé vyhledávání. ArangoDB může běžet v cloudu a je kompatibilní s Mac OS, Linuxem a Windows. Zabezpečení dat je zajištěno pomocí autentizace LDAP, maskování dat a šifrovacích algoritmů. ArangoDB se používá v oblasti řízení rizik, správy identit, detekce podvodů, správy síťové infrastruktury a doporučovacích systémů. ArangoDB používají například společnosti Accenture, Cisco, Dish a VMware.
DataStax
DataStax je cloudová databáze NoSQL nabízená jako služba (DBaaS), která je postavena na Apache Cassandra. Je vysoce škálovatelná a využívá cloudovou nativní architekturu. Je spolehlivá a bezpečná. Každý dokument v DataStax má index, který umožňuje rychlé a snadné vyhledávání a načítání dat. Indexovaná data se rozdělují do fragmentů. K vytváření aplikací lze využít různé zdroje dat, jako jsou Datastax Enterprise, Kafka a Docker.
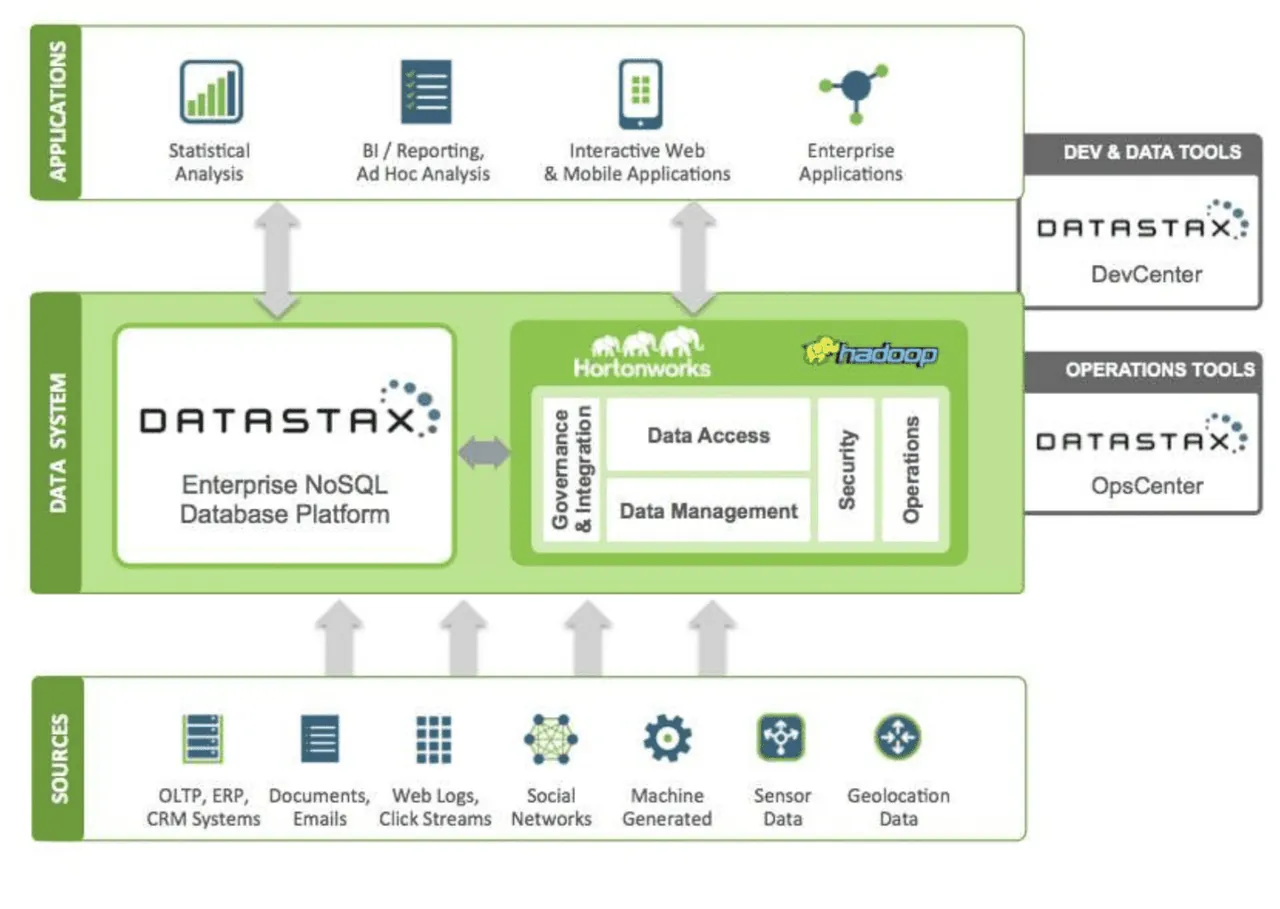
Data shromážděná ze zdrojů se odesílají do ekosystému Hadoop a DataStax. Hadoop zajišťuje zabezpečení, operace, přístup k datům a správu v rámci interakce s DataStax. Data se dále zpracovávají pomocí vývojových a provozních nástrojů Datastax. Analyzované informace se pak používají pro statistické analýzy, podnikové aplikace a reporting. DataStax je cloudová služba s flexibilním modelem plateb dle využití. DataStax používají například Verizon, CapitalOne, TMobile a Overstock.
OrientDB
OrientDB je grafová databáze, která efektivně spravuje data a pomáhá vytvářet vizuální reprezentace. Je to multimodelová grafová databáze napsaná v Javě. Data ukládá ve formě párů klíč-hodnota, dokumentů a objektových modelů. OrientDB se skládá ze tří hlavních komponent: grafový editor, dotazovací studio a konzole příkazového řádku.
Grafový editor se používá k vizualizaci a interakci s daty. Rozhraní dotazovacího studia umožňuje provádět dotazy a okamžitě zobrazovat výstupy v grafické i tabulkové podobě. Konzole příkazového řádku slouží k dotazování na data z OrientDB. Databáze má distribuovanou architekturu s více servery, které mohou provádět operace čtení i zápisu. Replikované servery slouží k operacím čtení a dotazování. OrientDB podporuje indexování a je kompatibilní s ACID. OrientDB používají například Comcast Corporation a Blackfriars Group.
Dgraph
Dgraph je cloudová grafová databáze, která podporuje GraphQL. Je napsaná v jazyce Go. Dgraph minimalizuje síťová volání a snižuje latenci díky maximalizaci souběžného zpracování dotazů. Bezproblémová integrace Dgraph s GraphQL usnadňuje vývoj backendových aplikací. Mutace GraphQL prochází funkcí Lambda, která interaguje s databází a datovým kanálem, což zjednodušuje zpracování dotazů. Dgraph je horizontálně škálovatelná, což znamená, že se počet zdrojů automaticky zvyšuje s rostoucím objemem dat a dotazů. Dgraph nabízí různé funkce, jako je autorizace založená na JWT, vizualizace dat, cloudová autentizace a zálohování dat. Dgraph používají například Intuit, Intel a Factset.
TigerGraph
Tigergraph je grafová databáze založená na modelu vlastností, která byla vyvinuta v jazyce C++. Je vysoce škálovatelná a umožňuje pokročilé analýzy vysoce propojených dat. Pro ukládání dat využívá nativní grafovou strukturu a pro zpracování grafový engine. Databáze je uložena na disku i v paměti a využívá CPU cache pro rychlé načítání. Pro paralelní zpracování dat využívá funkci Map Reduce.
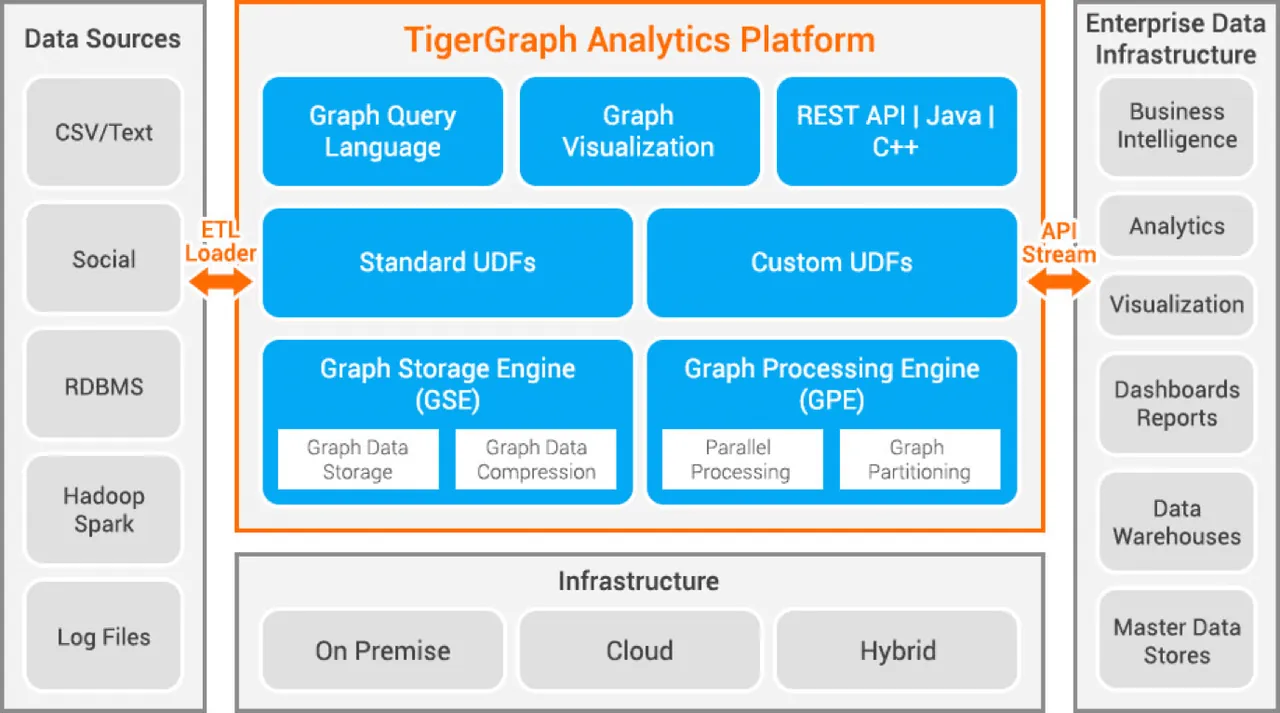
Tigergraph je mimořádně rychlý a škálovatelný. Umožňuje paralelní výpočty a poskytuje aktualizace v reálném čase. Využívá techniky komprese dat a komprimuje data až 10x. Data jsou automaticky distribuována mezi servery, což uživatelům šetří čas a námahu. Tigergraph se používá například pro odhalování podvodů v domácnostech, řízení dodavatelského řetězce a zlepšování zdravotní péče. Tigergraph používají například JPMorgan Chase, Intuit a United Health Group.
AllegroGraph
AllegroGraph využívá technologii znalostních grafů entit a událostí k provádění analýz a rozhodování na základě vysoce propojených, komplexních a rozsáhlých dat. Data jsou v grafových uzlech uložena ve formátu JSON a JSON-LD. AllegroGraph využívá architekturu protokolu REST. Dokáže pracovat s obrovskými datovými sadami díky sdílení dat na základě specifických kritérií a jejich distribuci do více úložišť znalostní báze. To je umožněno díky funkci FedShard databáze AllegroGraph. Dotazy jsou zpracovávány kombinací federací s repozitáři znalostní báze. Databáze podporuje typy schémat XML a používá trojité indexy. Ukládá geoprostorová data jako zeměpisné šířky a délky a časová data jako datum a časové razítko. Je kompatibilní s Windows, Mac a Linuxem. AllegroGraph se používá v oblasti odhalování podvodů, zdravotnictví, identifikace subjektů a predikce rizik.
Stardog
Stardog je grafová databáze, která umožňuje virtualizaci dat a propojuje data z datových skladů a datových jezer, aniž by bylo nutné fyzicky kopírovat data do nového úložiště. Stardog je postaven na otevřených standardech RDF. Podporuje strukturovaná, polostrukturovaná i nestrukturovaná data. Stardog nabízí flexibilitu díky virtualizaci dat. Je to jediná grafová databáze, která kombinuje znalostní grafy a virtualizaci.

Stardog využívá inferenční engine poháněný umělou inteligencí, který efektivně zpracovává a poskytuje výstupy dotazů. Jedná se o databázi grafů kompatibilní s ACID. Je podporováno souběžné čtení i zápis. Díky moderní architektuře dokáže snadno zpracovávat složité dotazy. Stardog se používá v oblasti IT asset managementu, správy a analýzy dat a poskytuje vysokou dostupnost. Stardog používají například Cisco, eBay, NASA a Finra.
Závěrečné myšlenky
Grafové databáze umožňují snadné dotazování vztahů mnoho-k-mnoha a efektivní ukládání dat. Jsou škálovatelné, bezpečné a lze je integrovat s mnoha nástroji, API a programovacími jazyky třetích stran. V posledních letech byly grafové databáze integrovány s cloudovými technologiemi a poskytují vynikající výkon.
Zjednodušují složité dotazy tím, že eliminují nutnost složitých spojení, což je pro vývojáře výhodné. Grafové databáze se také uplatňují v aplikacích náročných na data, jako je IoT a Big Data. Tyto databáze se budou i nadále vyvíjet a v budoucnu se jistě rozšíří na další oblasti použití.
