13 Nástroje pro generování syntetických dat pro trénování modelů strojového učení
Význam syntetických dat v současném světě
V dnešní době se data stávají klíčovým prvkem při tvorbě modelů strojového učení, testování softwarových aplikací a odhalování důležitých obchodních informací.
Nicméně, kvůli přísným nařízením o ochraně osobních údajů jsou tato data často uschována v bezpečí a podléhají silné ochraně. Získání přístupu k takovým datům může trvat i několik měsíců, než se podaří získat všechna potřebná povolení. Jako alternativní řešení mohou organizace využít syntetická data.
Co to jsou syntetická data?
Syntetická data představují uměle vytvořené datové soubory, které se statisticky podobají reálným datům. Mohou být použita v kombinaci se skutečnými daty pro zlepšení modelů umělé inteligence nebo jako plnohodnotná náhrada.
Jelikož syntetická data nepatří žádným konkrétním subjektům a neobsahují osobní identifikační údaje ani citlivé informace, jako jsou rodná čísla, mohou sloužit jako alternativa, která chrání soukromí, na rozdíl od skutečných produkčních dat.
Rozdíly mezi reálnými a syntetickými daty
- Nejvýznamnějším rozdílem je způsob, jakým jsou tyto dva druhy dat generovány. Reálná data pocházejí od skutečných lidí, jejichž informace byly získány během průzkumů nebo používání aplikací. Naopak, syntetická data jsou uměle vytvořena, avšak stále zachovávají statistické charakteristiky původního datového souboru.
- Druhý rozdíl spočívá v regulacích týkajících se ochrany dat, které se vztahují na reálná, ale nikoliv na syntetická data. V případě reálných dat mají subjekty právo vědět, jaké údaje o nich jsou shromažďovány a z jakého důvodu, a existují omezení, jak s nimi lze dále nakládat. Tato pravidla se na syntetická data nevztahují, protože je nelze přiřadit konkrétní osobě a neobsahují žádné osobní informace.
- Třetí rozdíl se týká množství dostupných dat. V případě reálných dat jste omezeni pouze tím, co vám uživatelé poskytnou. Na druhou stranu, syntetických dat můžete vygenerovat libovolné množství.
Proč se zamyslet nad využitím syntetických dat
- Syntetická data jsou relativně levnější na produkci, protože můžete vytvářet obrovské datové sady, které se podobají menšímu souboru dat, který již máte. To znamená, že vaše modely strojového učení budou mít více dat pro trénování.
- Vygenerovaná data jsou automaticky označena a vyčištěna. Ušetří vám to čas a námahu spojenou s přípravou dat pro strojové učení nebo analýzu.
- S syntetickými daty nevznikají žádné problémy s ochranou soukromí, protože neidentifikují konkrétní osoby a nepatří žádným subjektům údajů. To vám dává volnost při jejich používání a sdílení.
- Můžete překonat zkreslení v umělé inteligenci tím, že zajistíte dostatečné zastoupení menšinových skupin, čímž se dopracujete ke spravedlivé a odpovědné umělé inteligenci.
Jak generovat syntetická data
Proces generování se liší podle používaného nástroje, ale obecně začíná připojením generátoru k existujícímu datovému souboru. Následně identifikujete datové položky a označíte ty, které mají být vyloučeny nebo upraveny.
Generátor poté začne identifikovat datové typy zbývajících sloupců a statistické vzory v nich obsažené. Od této chvíle můžete vytvářet libovolné množství syntetických dat.
Vygenerovaná data lze obvykle porovnat s původním datovým souborem, abyste viděli, jak dobře se syntetická data podobají reálným datům.
Nyní se podíváme na nástroje pro generování syntetických dat, které se dají využít při trénování modelů strojového učení.
Nástroje pro generování syntetických dat
Mostly AI
Mostly AI nabízí generátor syntetických dat, který využívá umělou inteligenci, aby se učil statistickým vzorům z původních datových sad. Následně AI vytváří fiktivní entity, které odpovídají naučeným vzorům.
S Mostly AI můžete generovat celé databáze, včetně referenční integrity. Můžete vytvářet různé typy syntetických dat pro podporu vývoje lepších modelů umělé inteligence.
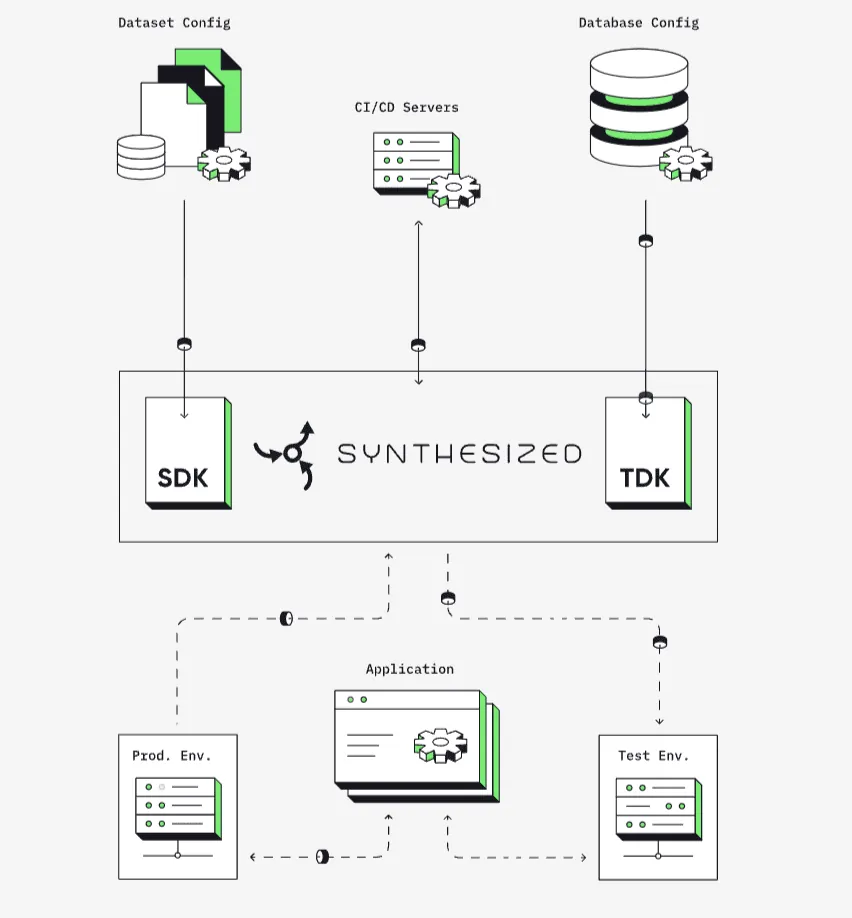
Synthesized.io
Synthesized.io je používán předními společnostmi pro jejich projekty v oblasti umělé inteligence. Pro jeho použití zadejte své požadavky na data do konfiguračního souboru YAML.
Poté vytvoříte úlohu a spustíte ji jako součást datového toku. Nabízí také bezplatnou verzi, která vám umožní experimentovat a zjistit, zda splňuje vaše datové potřeby.
YData

S YData můžete generovat tabulková data, časové řady, transakční, multi-tabulková a relační data. Tím se vyhnete problémům spojeným se sběrem, sdílením a kvalitou dat.
YData nabízí AI a SDK, které můžete používat pro interakci s jejich platformou. K dispozici je také bezplatná verze pro demo produktu.
Gretel AI

Gretel AI nabízí API pro generování neomezeného množství syntetických dat. Má generátor dat s otevřeným zdrojovým kódem, který si můžete nainstalovat a používat.
Alternativně můžete využít jejich REST API nebo CLI za poplatek. Jejich ceny jsou přiměřené a závisí na velikosti vaší firmy.
Copulas
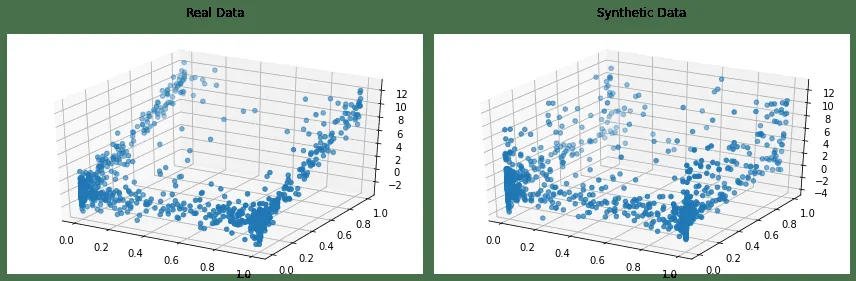
Copulas je open-source knihovna pro Python, která umožňuje modelovat vícerozměrná rozdělení pomocí kopulových funkcí a generovat syntetická data se stejnými statistickými vlastnostmi.
Tento projekt vznikl v roce 2018 na MIT v rámci projektu Synthetic Data Vault.
CTGAN
CTGAN se skládá z generátorů, které jsou schopny se učit ze skutečných dat s jednou tabulkou a generovat syntetická data z identifikovaných vzorů.
Je implementována jako open-source Python knihovna. CTGAN, spolu s Copulas, je součástí projektu Synthetic Data Vault.
DoppelGANger
DoppelGANger je open-source implementace Generative Adversarial Networks pro generování syntetických dat.
DoppelGANger je užitečný při generování časových řad a používají jej společnosti jako Gretel AI. Knihovna Python je dostupná zdarma a s otevřeným zdrojovým kódem.
Synth
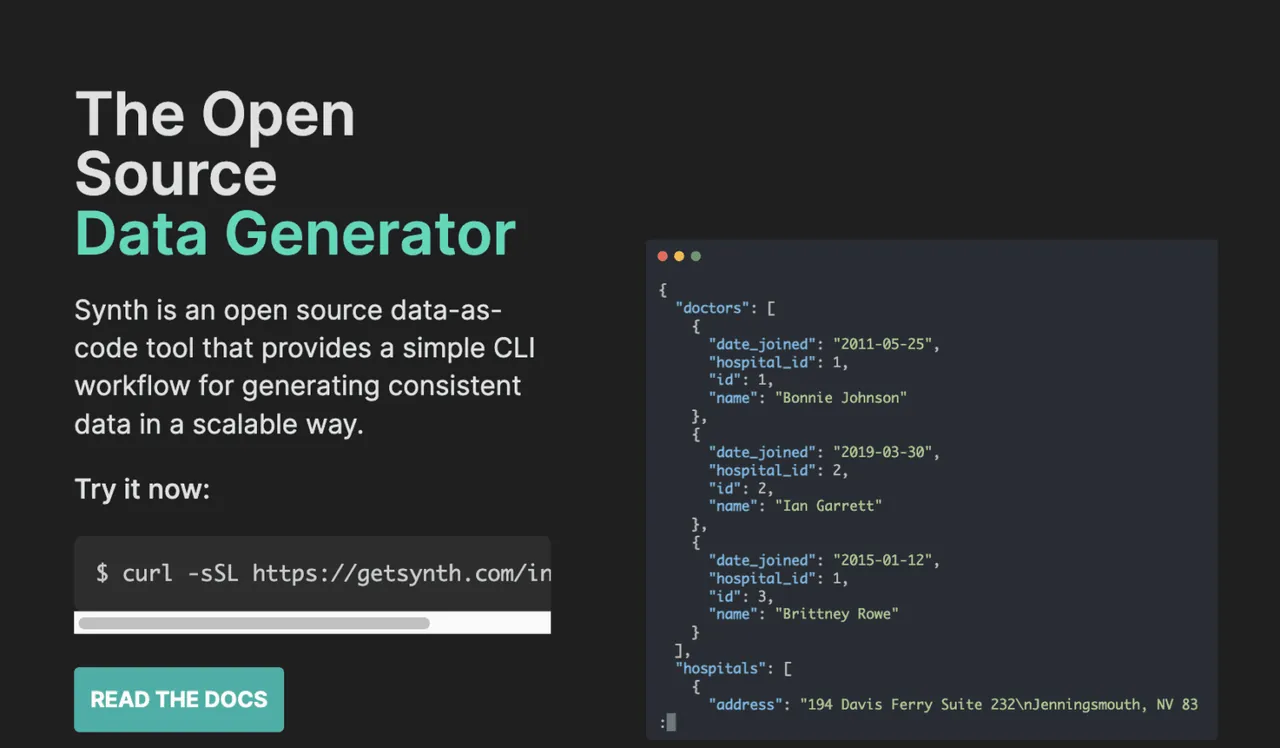
Synth je open-source generátor dat, který vám pomůže vytvářet realistická data dle vašich specifikací, skrýt osobní informace a generovat testovací data pro vaše aplikace.
Synth můžete využít pro generování řad a relačních dat v reálném čase pro potřeby strojového učení. Je také databázově agnostický, takže jej můžete používat s SQL i NoSQL databázemi.
SDV.dev
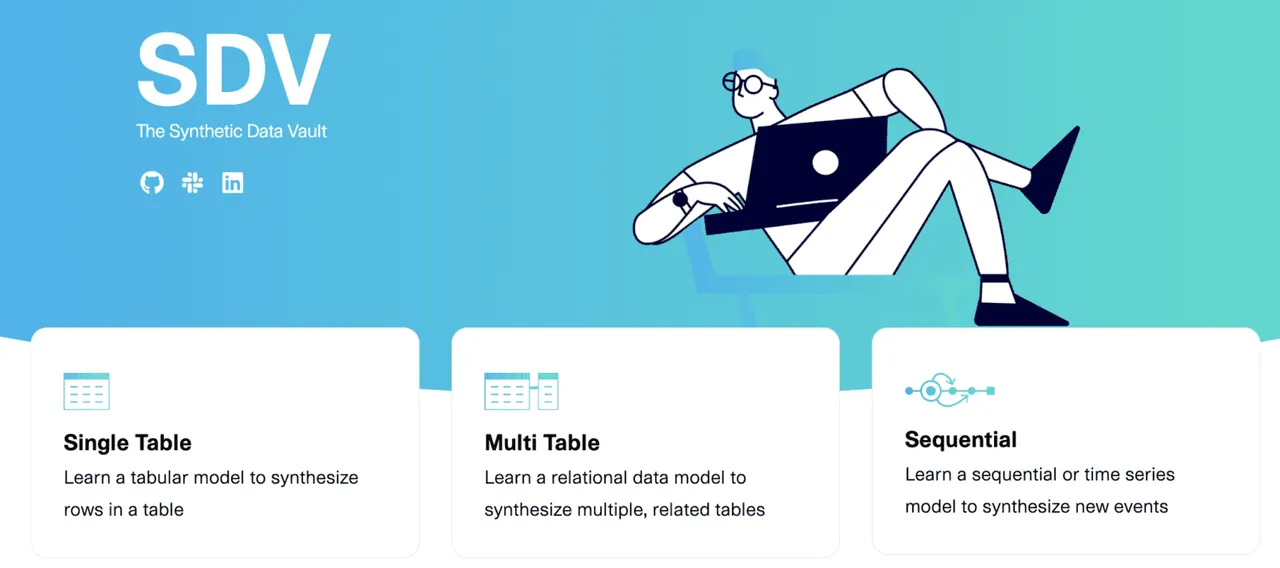
SDV je zkratka pro Synthetic Data Vault. SDV.dev je softwarový projekt, který začal na MIT v roce 2016 a vyvinul různé nástroje pro generování syntetických dat.
Mezi tyto nástroje patří Copulas, CTGAN, DeepEcho a RDT. Všechny jsou implementovány jako open-source Python knihovny, které se snadno používají.
Tofu
Tofu je open-source Python knihovna pro generování syntetických dat založených na britských biobankách. Na rozdíl od výše uvedených nástrojů, které vám pomohou generovat jakýkoli druh dat na základě vašeho stávajícího datového souboru, Tofu generuje data, která se podobají pouze těm z biobanky.
UK Biobank je studie o fenotypových a genotypových charakteristikách 500 000 dospělých ve středním věku ze Spojeného království.
Twinify
Twinify je softwarový balík, který se používá jako knihovna nebo nástroj příkazového řádku pro vytváření syntetických dat s identickým statistickým rozdělením, a tak zdvojování citlivých dat.

Při použití Twinify stačí poskytnout reálná data ve formátu CSV. Z těchto dat se naučí vytvořit model, který se pak dá využít pro generování syntetických dat. Twinify je zcela zdarma k použití.
Datanamic
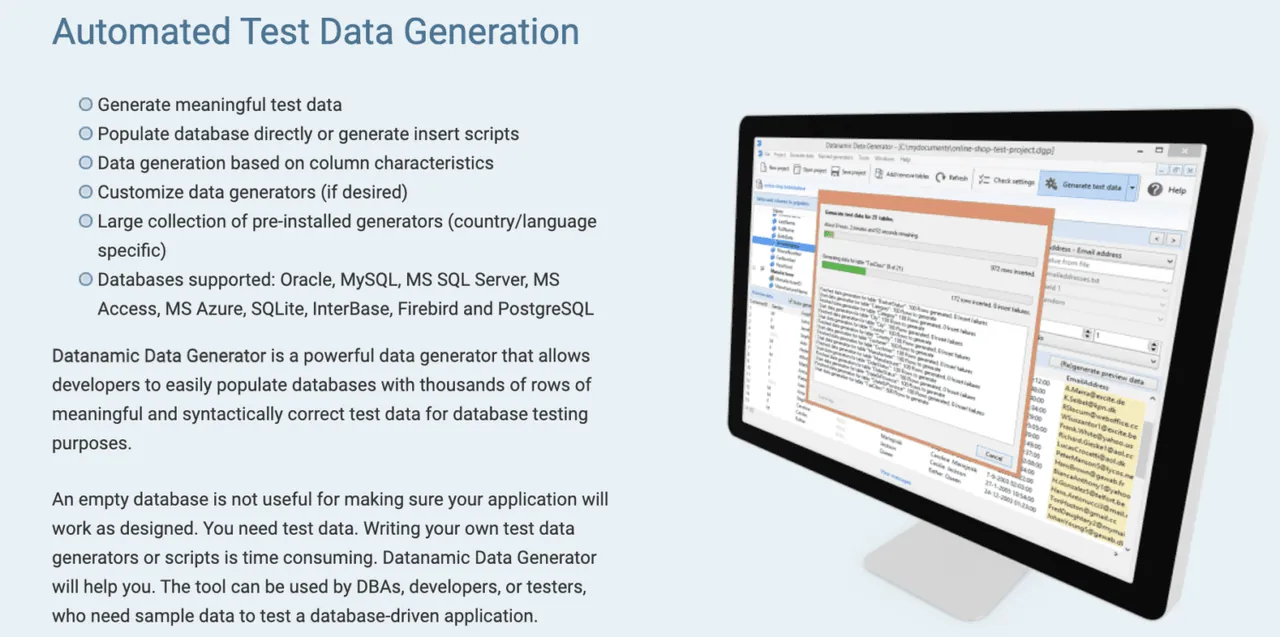
Datanamic vám pomůže vytvářet testovací data pro aplikace řízené daty a strojové učení. Generuje data na základě charakteristik sloupců, jako je e-mail, jméno a telefonní číslo.
Datanamické generátory dat jsou přizpůsobitelné a podporují většinu databází, jako je Oracle, MySQL, MS Access a Postgres. Podporují a zajišťují referenční integritu generovaných dat.
Benerátor
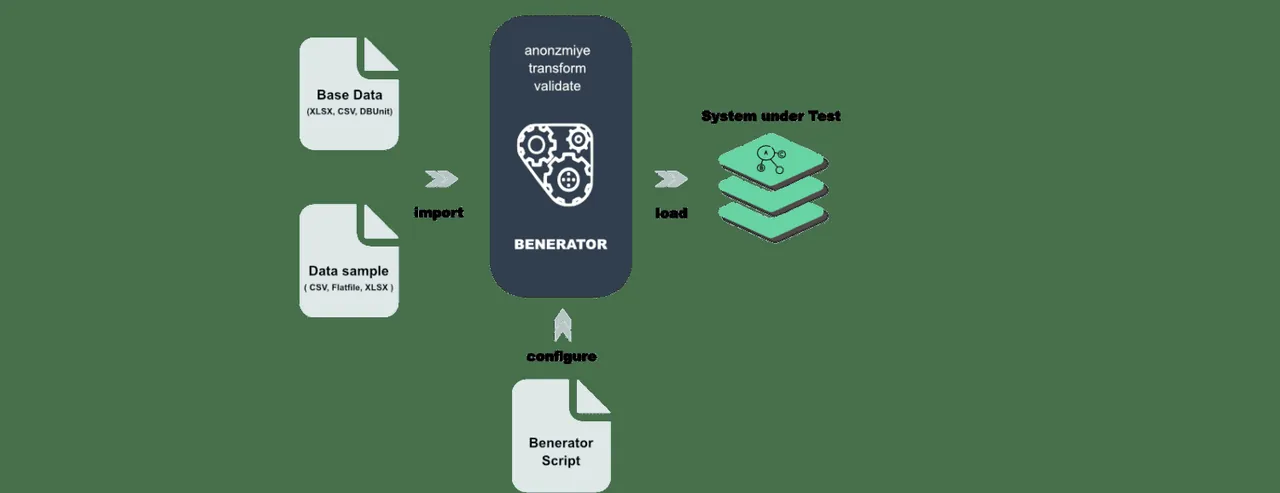
Benerator je software pro anonymizaci, generování a migraci dat pro účely testování a školení. Pomocí Beneratoru popisujete data v XML (Extensible Markup Language) a generujete pomocí nástroje příkazového řádku.
Je navržen tak, aby byl uživatelsky přívětivý i pro netechnické uživatele a umožňuje generovat miliardy řádků dat. Benerator je zdarma a s otevřeným zdrojovým kódem.
Závěrem
Podle odhadů společnosti Gartner se do roku 2030 bude pro strojové učení používat více syntetických než skutečných dat.
Vzhledem k nákladům a obavám o soukromí při práci se skutečnými daty není těžké pochopit, proč tomu tak bude. Proto je pro firmy důležité se seznámit se syntetickými daty a s různými nástroji, které jim pomohou s jejich generováním.
Podívejte se také na syntetické monitorovací nástroje pro vaše online podnikání.
