
Plán obnovy po havárii je hlavním opatřením, které organizace musí mít, než ji zasáhne neobvyklá událost.
V IT průmyslu to začíná vytvořením formálního dokumentu obsahujícího plány, akce a postupy pro řešení katastrofy a jejích následků.
Katastrofa je událost, která přichází náhle bez předchozího upozornění a může mít různé typy. A když přistane, jednotlivci a organizace čelí problémům mnoha druhů, včetně finančních problémů a uživatelské zkušenosti.
Pokud k útoku dojde, musíte být připraveni minimalizovat jeho účinky a rychleji obnovit své operace. Zde vám příprava praktického plánu obnovy po havárii pomůže katastrofu zadržet nebo jí předejít. Můžete také snížit jeho následné účinky, pokud jde o uživatelskou zkušenost, náklady a prostoje.
Kromě toho musíte mít připravené své plány, lidi, strategie, vybavení a systémy, abyste mohli vše vrátit do akce. K tomu však musíte do hloubky porozumět obnově po havárii.
V tomto článku to podrobně proberu spolu s klíčovou terminologií obnovy po havárii, abyste se mohli statečně bránit a vyjít silnější v takových nepříznivých podmínkách.
Pojďme začít!
Table of Contents
Co je to katastrofa?
Katastrofa je nepředvídatelná událost, která se může stát kdekoli, včetně IT průmyslu. Vyskytuje se buď přirozeně, nebo lidmi a může zasahovat do provozu společnosti a narušovat strukturu infrastruktury.
V důsledku toho je ovlivněna organizace a její zákazníci, prodejci, zaměstnanci a partneři. Vyvíjí tlak na organizaci, pokud jde o finance, pověst v oboru, důvěru zákazníků a bezpečnostní perimetr.
Proto musíte být předem připraveni překonat takový scénář. K tomu potřebujete okamžitě obnovit každou operaci a data. Jednoduše řečeno, musíte připravit svou organizaci na obnovení všeho v nejkratším možném intervalu pro vaše zákazníky.
Katastrofy jsou mnoha typů, jako jsou kybernetické útoky, sabotáže, teroristické útoky, ransomware nebo fyzické hrozby, hurikány, zemětřesení, požáry, záplavy, průmyslové havárie, výpadky elektřiny a mnoho dalších.
Co máte na mysli pod pojmem zotavení po havárii?

Obnova po havárii je proces obnovení normálního provozu po katastrofě. Zahrnuje obnovení přístupu k hardwaru, softwaru, vybavení, konektivitě, sítím, napájení a datům. Musíte nastavit pravidla a postupy v zdokumentovaném procesu, abyste svou organizaci připravili před katastrofou.
Pokud jsou však zařízení vaší organizace zničena, musíte některé činnosti rozšířit o práci na komunikaci, dopravě, zajišťování zdrojů, pracovních místech a dalších.
Proč je plán obnovy po havárii důležitý?
Vypracování dokonalého plánu pro obnovu po katastrofě, ať už přírodní nebo způsobené člověkem, je nezbytné pro každé odvětví IT. Ujistěte se, že máte správného zaměstnance a nástroje na správném místě, abyste plán hladce provedli.
Pojďme se ponořit hlouběji do toho, proč je obnova po havárii zásadní.
Omezit škody
Katastrofa je nepředvídatelná. Nikdo neví, kdy to přijde a kdy odejde. Ale předem se připravíte na kontrolu škod způsobených vaší infrastruktuře.
Například v oblastech náchylných k záplavám můžete své základní dokumenty a typy vybavení umístit do horního patra, abyste předešli poškození.
Podobně zálohujte svá základní data dříve, než kybernetické útoky mohou data prolomit nebo je ukrást.
Obnovení služeb
Pokud připravíte solidní plán obnovy po katastrofě, obnovení všech služeb do jejich normální podoby je rychlé a snadné. To znamená, že v krátkém časovém intervalu můžete obnovit téměř všechna hlavní aktiva a služby.
Minimalizujte přerušení
Nemůžete vědět, co se stane zítra nebo v dalším kroku operace. Ale s dokonalým plánem obnovy se nemusíte moc bát následků. Vaše infrastruktura může pokračovat v provozu s minimálním přerušením.
Školení a příprava

IT infrastruktura se skládá z mnoha zaměstnanců pracujících pod střechou. Všichni musí vědět o obnově, aby mohli v případě nouze okamžitě jednat podle požadavků a očekávání.
Správná příprava také sníží úroveň stresu všech, kteří jsou spojeni s vaší organizací. Kromě toho můžete své zaměstnance vyškolit, aby přijali nezbytná opatření, pokud dojde k neočekávané události.
Terminologie zotavení po havárii
Začněme s terminologií, abychom porozuměli zotavení po havárii z bližšího pohledu.
RTO
Recovery Time Objective (RTO) je doba, kterou organizace stanoví podle povahy podnikání, aby tolerovala katastrofu bez ovlivnění finančního růstu.
Při nastavování RTO musí společnost zkontrolovat prostoje, které mohou ovlivnit vaši organizaci mnoha způsoby. Používá se ke studiu životaschopných strategií pro pokračování vašich obchodních operací i po katastrofě. Když se zákazníci potýkají s nějakým rušením v aplikaci, zeptají se, jak dlouho bude aplikaci trvat, než se vrátí k akci. Odpověď je RTO pro každou organizaci.
Příklad: Předpokládejme, že jste online transakční společnost jako PayPal nebo Pioneer čelící nepředvídatelným událostem. V tomto případě bude vaše RTO dostatečně rychlé na obnovení operace.
Jinými slovy, společnost nastaví RTO na hodinu nebo dvě, aby se vyhnula následkům ve formě financí nebo dat.
RPO
Cíle bodu obnovení (RPO) představují ztrátu dat, kterou může IT infrastruktura zvládnout z hlediska času a množství informací.
Matoucí?
Vezměte si příklad databáze, která zaznamenává transakce banky, včetně převodů, plánování, plateb a dalších. Když dojde ke katastrofě, databáze se obnoví v reálném čase. Rozdíl mezi databází v době havárie a obnovou databáze po havárii je v tomto případě nulový.
Pro některé společnosti je přijatelné, aby obnovení všech informací ze zálohy trvalo asi 24 hodin, ale někdy to může být katastrofální. Je nezbytné nastavit vaši infrastrukturu podle požadavků RPO. To zahrnuje zvýšení frekvence zálohování, přidání záložní databáze do vaší architektury a další.
Failover
Představte si situaci, kdy cestujete na velkou vzdálenost. Najednou vám z nějakého neočekávaného důvodu praskla pneumatika. Poděkujete za náhradní pneumatiku, která je k dispozici ve vašem vozidle, a za nástroje pro výměnu defektní pneumatiky.
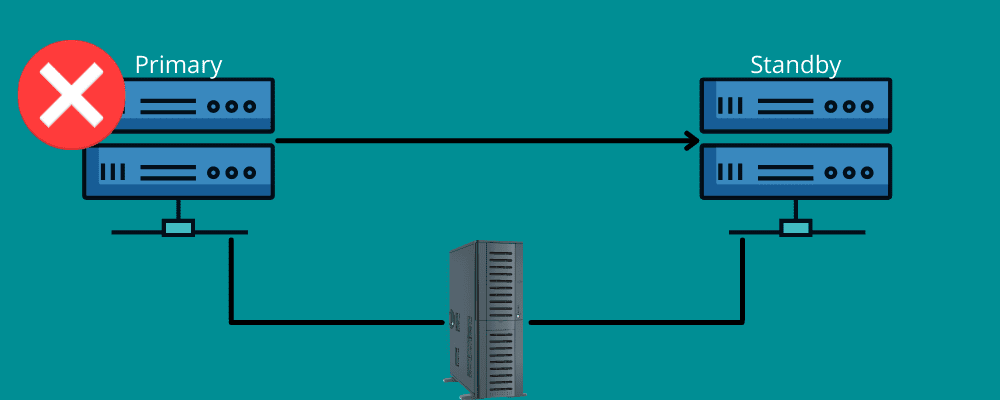
Failover funguje stejným způsobem.
To znamená, že během katastrofy potřebujete záložní připojení. Stručně řečeno, převzetí služeb při selhání znamená mít sítě a systémy, které můžete použít v době havárie k přepnutí vašich informací do systému obnovy.
Failover zajišťuje hladký chod všech vašich služeb, i když dojde k selhání infrastruktury nebo hardwaru. Tímto způsobem můžete zabránit tomu, aby vaše organizace přišla o data a příjmy, a vyhnout se přerušení služeb pro vaše koncové uživatele.
Můžete jej buď nastavit ručně, nebo povolit automatické přesouvání dat na záložní server.
Failback
IT failback je jednoduchá operace, kdy se původní produkce vrátí na své původní místo (systém) po zvládnutí katastrofy. Během útoku společnosti následují operaci převzetí služeb při selhání, díky které se všechna pracovní zatížení přenesou na repliku virtuálního počítače nebo záložní systém.
Další krok návratu však nemůžete jen tak přeskočit. Když vše obnovíte a vrátíte se do akce, musíte přenést všechny pracovní zátěže na jejich původní virtuální počítače nebo systémy. Tento celkový proces vracení úloh na původní pracoviště nebo systém je známý jako failback. Znamená to, že se po útoku „vracíte“.
Failback se také používá pro plánovanou údržbu podniku. Je pravda, že po převzetí služeb při selhání vždy dojde k návratu k selhání. Jinými slovy, převzetí služeb při selhání je prvním krokem a návrat po selhání je druhým krokem při obnově důležitých dat. Lze jej nastavit mezi cloudem, cloudem, místním a místním, místním a cloudem nebo jakoukoli jejich kombinací.
DR
Obnova po havárii (DR) je proces, při kterém máte předem připravené plány na obnovu svých aktiv v daném časovém rámci.
DR umožňuje organizaci rychle reagovat a obnovit každou jednotlivou službu z neočekávané události. Poskytuje také formální dokumentaci, která obsahuje pokyny k přijetí okamžitých opatření v případě nepředvídaných událostí.
BCP
Business Continuity Plan (BCP) je jedním z nejpřijatelnějších plánů obnovy po havárii, který umožňuje IT infrastruktuře vytvářet strategie pro řešení výpadků IT na serverech, mobilních zařízeních, osobních počítačích a sítích.
BCP se mírně liší od obnovy po havárii, protože pomáhá organizaci plánovat obnovení podnikového softwaru a produktivity tak, aby vyhovovaly klíčovým obchodním potřebám.
Zde společnost vytváří systém obnovy k překonání potenciálních hrozeb, jako jsou kybernetické útoky nebo přírodní katastrofy. Je navržen tak, aby zabezpečil majetek a zajistil, že všechny služby budou po stávce rychle zpět v provozu.
BCM

Business Continuity Management (BCM) je proces řízení rizik speciálně navržený tak, aby fungoval jako štít proti hrozbám pro podnikové procesy. BCM je dalším krokem BCP, kde ověřuje plány obnovy, aby se zajistilo, že všichni v podniku na plán okamžitě zareagují a obnoví všechny podstatné věci.
BCM funguje jako řídicí rámec pro identifikaci rizik infrastruktury, když čelí externím a/nebo interním hrozbám. Zajišťuje také, že rámec funguje efektivně pomocí pravidelného testování za účelem zlepšení předvídatelnosti, snížení rizika a sladění plánu pro budoucí útoky.
BIA
Business Impact Analysis (BIA) je proces analýzy míry přežití podniku identifikací klíčových systémů, operací a procesů. Vypovídá o dopadu katastrofy na vaši organizaci v důsledku přerušení vašich operací.
BIA předpovídá následky ještě předtím, než k útoku skutečně dojde, aby shromáždila klíčové informace, které mohou pomoci vytvořit výkonné strategie obnovy. Také identifikuje náklady spojené s poruchami, jako jsou náklady na výměnu zařízení, ztráta peněžního toku, zisky, platy a další.
Při vytváření zprávy BIA musíte vzít v úvahu klíčové procesy související s vaším podnikáním, dopad narušení na různé oblasti, přijatelné trvání, tolerovatelné oblasti, finanční náklady a další.
Call Tree
Strom hovorů je proces kurátorství seznamu zaměstnanců, kteří se mají v případě nouze dovolat. Je to postup, který sleduje stromovou strukturu.
Například během katastrofy jedna osoba kontaktuje malou skupinu členů s naléhavou zprávou, tito zaměstnanci volají každé skupině zvlášť. Tímto způsobem budou všichni zaměstnanci během hrozby informováni a začnou svou přidělenou práci, aby včas obnovili každou funkci a proces. Vytvoření seznamu je jednoduché, ale jeho implementace v reálném čase vytváří zmatek.
Musíte provádět pravidelné hovory, abyste připravili každého člena tísňového personálu zůstat ve střehu. Pravidelné testování může také pomoci identifikovat změněná nebo chybějící čísla, která mohou vážně ovlivnit výkon.
Strom volání obsahuje informace, které se použijí v případě nouze k doručení pokynů. Lze to také provést ručně, ale lidé používají automatizaci k urychlení procesu a informování členů v dnešním digitálním světě.
Command Center/Control Center
Je to virtuální nebo fyzické zařízení speciálně připravené k poskytování velení nebo řízení plánů obnovy během krize. Komunikuje s týmem za účelem správy systémů a funkcí během katastrofy.
Infrastruktura tradičně závisí na řídícím centru, které řeší krize bez jakéhokoli vhodného přístupu. V dnešní době mají organizace dokonale navržené své řídicí centrum, které mění okamžitou reakci na základní kompetence.
Jakmile velitelské centrum zaznamená katastrofu, rychle přejde do fáze obnovy. Navíc slouží jako reportovací místo v případě služeb, tisku, dodávek a dalších. Během takových scénářů také spojuje lidi z různých oborů.
Odezva na incident

Reakce na incident je typ reakce dané k řešení útoku. Provádí se s pomocí správných postupů a personálu, aby byla efektivně zachována síť a zabezpečení dat ve správný čas.
Pokud má organizace plán incidentů před neočekávanou událostí, může zabezpečit svá data před hrozbami v reálném čase. Specialisté na reakce na incidenty jsou vždy pozorní vůči problémům a během incidentu jednají přirozeně. Přijímají určitá opatření, aby se vyhnuli narušení bezpečnosti a zajistili, že během obnovy po havárii nepřeskočí ani jeden krok.
Na začátku musíte určit kritická data a uložit je do cloudu nebo na jakékoli vzdálené místo, abyste zajistili bezpečnost. Řešte aktuální potřeby infrastruktury a vyvíjející se kybernetické hrozby pravidelnou aktualizací plánů reakce na incidenty.
Záloha
Zálohovací řešení pomáhají IT infrastruktuře udržovat kopie dat a bezpečně je ukládat ve správný čas. Pokud narazíte na poškození databáze, náhodné smazání všech dat nebo jakýkoli jiný problém, musíte být připraveni se zálohou okamžitě obnovit data a pokračovat ve využívání služeb.

Zahrnuje replikaci souborů a jejich uložení na bezpečné místo pro snadný přístup ke všem datům po neobvyklé události. Pomůže, když budete svá data zálohovat na více místech, abyste zajistili, že je budete moci obnovit, i když některý web selže.
Odolnost
Schopnost komunit, států, organizací a jednotlivců odolat katastrofě nebo jí odolat bez ohrožení služeb a systémů je známá jako odolnost vůči katastrofám.
Organizace musí být připravena odolat velkému množství stresu kvůli rizikům. Ujistěte se, že máte schopnosti minimalizovat své ztráty lepším plánováním, místo abyste čekali na někoho, kdo vás přijde zachránit. To vám pomůže vypořádat se s katastrofami a efektivně obnovit vaši IT infrastrukturu.
Zde je hlavním cílem zachovat a obnovit základní funkce a struktury ve správný čas, kdykoli je to nutné. Chcete-li se stát organizací odolnou vůči katastrofám, musíte se předem připravit a mít schopnost předvídat rizika, přizpůsobovat se změnám, sdílet a učit se, integrovat různá odvětví a řídit úrovně rizik.
SLA

Service Level Agreement (SLA) je plán pro případ havárie, ve kterém koncovým uživatelům zmiňujete čas, který můžete využít k obnovení služeb v případě nouze.
SLA zajišťuje zákazníkům, že jejich data jsou v bezpečí a nejsou kompromitována nebo sdílena s třetími stranami. Je to jediné kontaktní místo pro záležitosti koncových uživatelů.
Každá IT infrastruktura poskytuje svým zákazníkům jistotu ohledně SLA. Ujistěte se tedy, že předem komunikujete se svými koncovými uživateli.
SPOF
Single Point of Failure (SPOF) je část zařízení, jednotlivec, zdroj nebo aplikace, ke které je připojeno mnoho dalších systémů nebo aplikací.
Pokud dojde k výpadku takového zařízení nebo zdroje, spadnou s ním i všechny podstatné části připojené k systému. Tím bude ovlivněn celý proces a obchodní operace.
Proto musíte mít strategii, jak takový problém zvládnout, aby vaše organizace fungovala. Úplně první věc, kterou můžete udělat, je identifikovat ten jediný kus zařízení nebo systému, který může ovlivnit více. Dále spusťte analýzu dopadu na podnikání a získejte skóre hodnocení rizik, abyste si byli vědomi scén, které se budou dít. Zakopejte a najděte je před akcí.
Jakmile uvedete seznam všech SPOF, klasifikujte je podle procesu obnovy. Zařaďte každý ze SPOF do tří různých kategorií:
- Obnovte snadno a přímo za méně času a rozpočtu.
- Obnova by byla obtížná, ale mohl by být vyvinut spolehlivý proces obnovy.
- Jakmile to spadne, nelze nic udělat pro obnovení.
Podle kategorie můžete jednat.
Obnova systému
Během selhání hardwaru musíte spustit proces obnovy, abyste získali konkrétní systém nebo server do původní podoby. A abyste mohli obnovit celý systém, musíte mít připravené požadavky na obnovu, zálohy, kompatibilitu firmwaru a kompatibilitu hardwaru.
Obnova systému je proces, který resetuje počítač do předchozího nastavení nebo do stejného stavu, v jakém byl, když byl nový. Tímto způsobem odstraníte všechny virové infekce způsobené nainstalovaným softwarem nebo aplikacemi ve vašem systému.
Tento proces zahrnuje plánování obnovy IT infrastruktury, které stanoví a dodržuje určité postupy pro zajištění dostupnosti dat proti umělým nebo přírodním poruchám.
Obnovení systému
Obnovení systému je nástroj pro obnovu, který umožňuje ve správný čas obnovit určité soubory a informace do předchozího stavu.
Pomocí obnovení systému můžete obnovit klíče registru, nainstalované programy, ovladače, systémové soubory a další zpět do předchozí verze. To funguje jako zachránce při mnoha katastrofách.
Testovací plán
Odkazuje na dokument, který uchovává informace o testovací strategii, odhadech, zdrojích, termínech, cílech a harmonogramech. Funguje jako plán, který spouští testy k zajištění bezpečnosti hardwaru a softwaru.
To zahrnuje různé testy podle postupů a kroků plánovaných pro zvládnutí následků katastrofy. Provádějte pravidelné testy, abyste sebe a svou organizaci připravili na to, že v průběhu akce nepřeskočíte jediný krok. Tímto způsobem může IT infrastruktura pochopit nedostatky a být připravena na boj.
Závěr
Nikdo neví, kdy dojde ke katastrofě. Proto jsou správná bezpečnostní a bezpečnostní opatření nezbytná pro každé podnikání.
Terminologie obnovy po havárii vám pomůže pochopit, jak reagovat na útoky a katastrofy. Pomůže vám také připravit se předem, abyste mohli chránit svou infrastrukturu během neočekávané události. Budete schopni vytvořit efektivní strategii obnovy po havárii v reálném čase, abyste ušetřili miliony dolarů a udrželi důvěru zákazníků.