Automatické získávání dat z webových stránek, známé jako web scraping, představuje efektivní metodu pro shromažďování velkého množství informací z internetu. Tento postup je zvláště užitečný tam, kde webové stránky neposkytují strukturovaný přístup k datům prostřednictvím API (rozhraní pro programování aplikací).
Uvažujme například o situaci, kdy vytváříte aplikaci porovnávající ceny produktů na různých e-shopech. Jak byste postupovali? Jedním z řešení by bylo ručně kontrolovat ceny na všech webových stránkách a zapisovat zjištěné údaje. Tento přístup by však byl velmi neefektivní, vzhledem k obrovskému množství produktů na platformách elektronického obchodování, a získání relevantních dat by zabralo nepředstavitelné množství času.
Mnohem lepším řešením je použití web scrapingu. Jedná se o proces, při kterém se s pomocí specializovaného softwaru automaticky získávají data z webových stránek.
Tyto softwarové skripty, často nazývané webové škrabky, slouží k navigaci na webové stránky a extrahování dat z jejich obsahu. Získané informace, obvykle ve formátu bez jasné struktury, je následně možné analyzovat a uspořádat do srozumitelné podoby pro uživatele.
Web scraping je neocenitelný nástroj pro získávání dat, neboť umožňuje přístup k rozsáhlým datovým zdrojům a automatizuje proces získávání dat. Díky tomu je možné naplánovat spouštění skriptů v pravidelných intervalech nebo v reakci na určité události. Tato metoda také umožňuje získávat aktuální informace v reálném čase a výrazně usnadňuje průzkum trhu.
Mnohé firmy a organizace využívají web scraping jako klíčový nástroj pro sběr dat pro následnou analýzu. Společnosti z odvětví lidských zdrojů, e-commerce, financí, realit, cestovního ruchu, sociálních médií a výzkumu používají web scraping k získávání relevantních informací z internetových stránek.
Dokonce i společnost Google využívá web scraping pro indexování webových stránek, aby mohla poskytovat uživatelům relevantní výsledky vyhledávání.
Při používání web scrapingu je však nezbytné postupovat obezřetně. I když získávání veřejně dostupných dat není samo o sobě protizákonné, některé webové stránky tuto aktivitu nepovolují. Důvodem mohou být citlivé uživatelské údaje, výslovný zákaz scrapingu v podmínkách používání nebo ochrana duševního vlastnictví.
Navíc, některé weby zakazují web scraping z důvodu možného přetížení serverů a zvýšení nákladů na datový přenos, obzvláště při rozsáhlém provádění scrapingu.
Pro zjištění, zda je scraping dané webové stránky povolen, lze zkontrolovat soubor robots.txt, který se nachází na adrese URL daného webu, doplněné o „/robots.txt“. Tento soubor slouží k definování pravidel pro roboty (automatizované programy) a specifikuje, které části webu mohou být procházeny. Například, chcete-li zjistit, zda lze seškrábat data z Google, přejděte na adresu google.com/robots.txt.
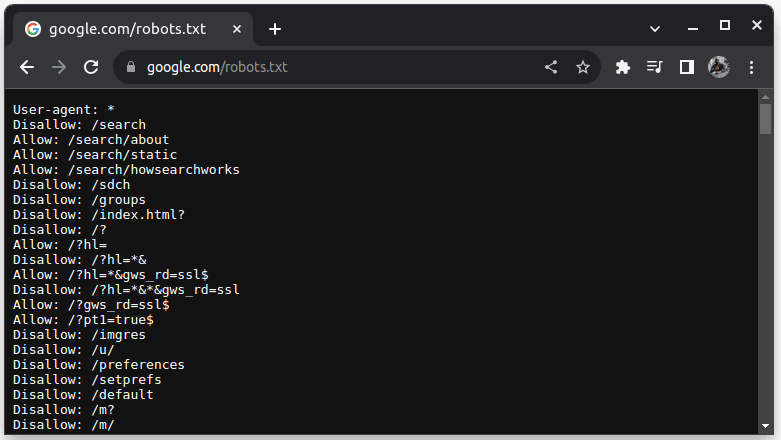
Zápis „User-agent: *“ označuje, že pravidla platí pro všechny roboty, skripty nebo crawlery. Direktiva „Disallow“ specifikuje, že roboti nemají přístup k určeným adresářům, jako například /search. Naopak „Allow“ označuje adresáře, ze kterých roboti mohou data získávat.
LinkedIn je příkladem webu, který neumožňuje scraping bez souhlasu. Pokud si chcete ověřit, zda je scraping LinkedIn povolen, navštivte linkedin.com/robots.txt.
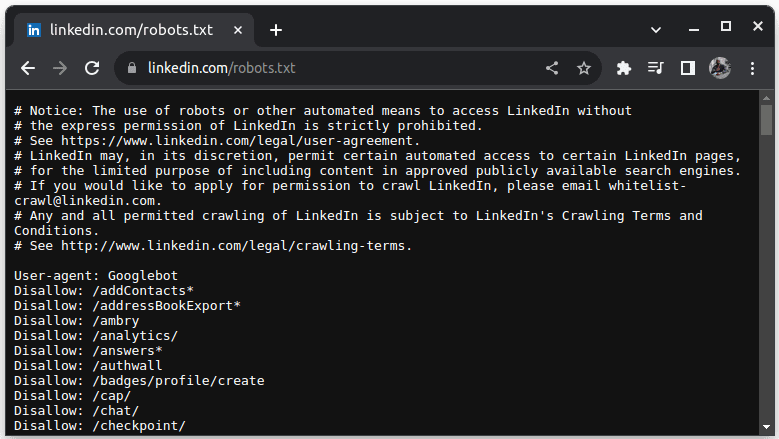
Jak je vidět, scraping LinkedIn bez jejich výslovného povolení je zakázán. Proto je vždy nutné ověřit si, zda je scraping daného webu povolen, aby se předešlo právním komplikacím.
Proč je Java vhodná pro Web Scraping
Ačkoli lze pro web scraping použít různé programovací jazyky, Java se z mnoha důvodů jeví jako obzvláště vhodná volba. Především Java disponuje rozsáhlým ekosystémem a velkou komunitou, a nabízí množství knihoven pro web scraping, jako jsou například JSoup, WebMagic a HTMLUnit. Tyto knihovny výrazně zjednodušují proces psaní webových škrabek.

Java také poskytuje knihovny pro analýzu HTML (HTML Parsing Libraries), které usnadňují extrakci dat z HTML dokumentů a síťové knihovny, jako je HttpURLConnection, které umožňují vytváření požadavků na webové stránky.
Silná podpora souběžného zpracování a multithreadingu v Javě je také velmi výhodná při web scrapingu. Umožňuje zpracovávat více požadavků paralelně a tedy škrábat více stránek současně. Díky tomu, že škálovatelnost je silnou stránkou Javy, je možné provádět web scraping i ve velkém měřítku pomocí webové škrabky napsané v Javě.
Další výhodou Javy je její multiplatformní podpora, která umožňuje psát webové škrabky a spouštět je na jakémkoli systému s kompatibilním Java Virtual Machine. To znamená, že je možné napsat webovou škrabku na jednom operačním systému nebo zařízení a spustit ji na jiném bez nutnosti provádět jakékoliv úpravy.
Java se také dá používat s bezhlavými prohlížeči, jako jsou například Headless Chrome, HTML Unit, Headless Firefox a PhantomJS. Bezhlavý prohlížeč funguje bez grafického uživatelského rozhraní. Tyto prohlížeče dokážou simulovat uživatelské interakce a jsou velmi užitečné při scrapingu stránek, které vyžadují interakci uživatele.
Závěrem lze říci, že Java je velmi populární a široce používaný jazyk, který je podporován a lze jej snadno integrovat s množstvím nástrojů, jako jsou databáze a rámce pro zpracování dat. To je velkou výhodou, protože zajišťuje, že všechny nástroje potřebné pro získávání, zpracování a ukládání dat, pravděpodobně podporují jazyk Java.
Nyní se podíváme, jak lze Javu využít pro web scraping.
Java pro Web Scraping: Předpoklady
Abychom mohli efektivně využívat Javu pro web scraping, je nezbytné splnit následující požadavky:
1. Java – Je nutné mít nainstalovanou Javu, nejlépe její nejnovější verzi s dlouhodobou podporou. Pokud ještě nemáte Javu nainstalovanou, vyhledejte si návod, jak provést instalaci na vašem počítači.
2. Integrované vývojové prostředí (IDE) – Na počítači byste měli mít nainstalované IDE. V tomto tutoriálu budeme používat IntelliJ IDEA, ale můžete zvolit jakékoli IDE, které vám vyhovuje.
3. Maven – Pro správu závislostí a instalaci knihovny pro web scraping bude použit Maven.
Pokud Maven ještě nemáte nainstalovaný, můžete ho nainstalovat otevřením terminálu a zadáním následujícího příkazu:
sudo apt install maven
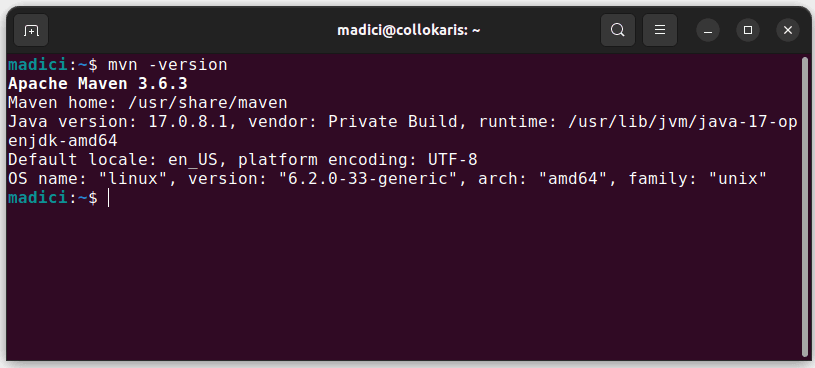
Tím se nainstaluje Maven z oficiálního úložiště. Úspěšnou instalaci můžete ověřit spuštěním následujícího příkazu:
mvn -version
Pokud byla instalace úspěšná, měl by se zobrazit výstup podobný následujícímu:
Nastavení prostředí
Nastavení vývojového prostředí:
1. Spusťte IntelliJ IDEA. V levém menu klikněte na „Projekty“ a následně zvolte „Nový projekt“.
2. V nově otevřeném okně „Nový projekt“ vyplňte údaje, jak je uvedeno níže. Ujistěte se, že je jazyk nastaven na „Java“ a „Build System“ na „Maven“. Projektu můžete dát libovolný název a pomocí pole „Umístění“ určit složku, ve které chcete projekt vytvořit. Po dokončení klikněte na „Vytvořit“.
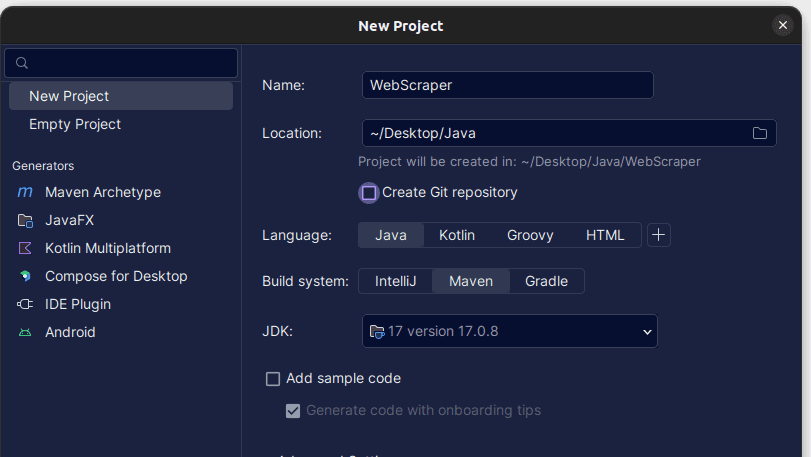
3. Po vytvoření projektu by se měl ve vašem projektu zobrazit soubor „pom.xml“, jak je znázorněno níže.
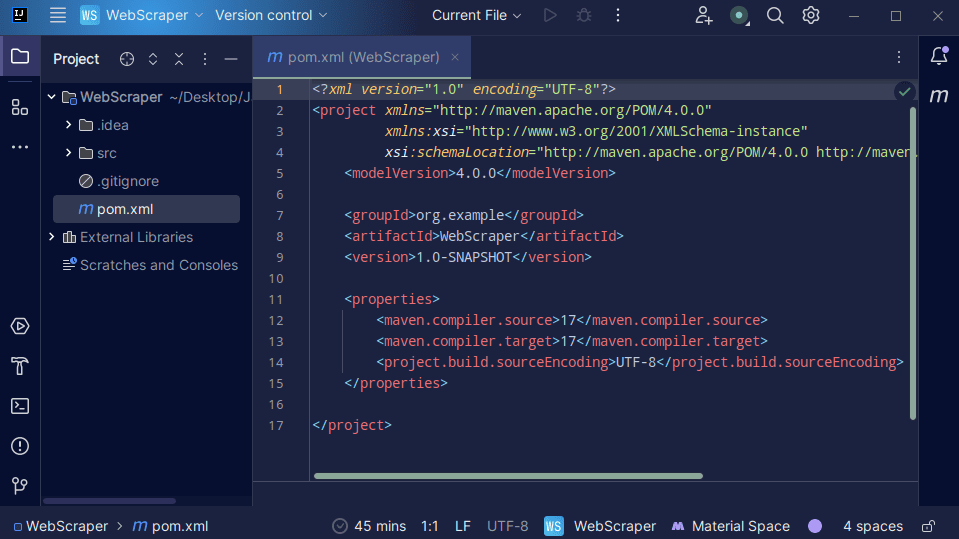
Soubor „pom.xml“ je vytvářen Mavenem a obsahuje informace o projektu a detaily konfigurace používané Mavenem k sestavení projektu. Tento soubor také využíváme k určení externích knihoven, které budeme používat.
Pro vytvoření webové škrabky budeme používat knihovnu jsoup. Proto ji musíme přidat jako závislost v souboru „pom.xml“, aby byla pro Maven dostupná v našem projektu.
4. Přidejte závislost jsoup do souboru „pom.xml“ zkopírováním níže uvedeného kódu a vložením do souboru „pom.xml“.
<dependencies>
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.16.1</version>
</dependency>
</dependencies>
Výsledek by měl vypadat následovně:
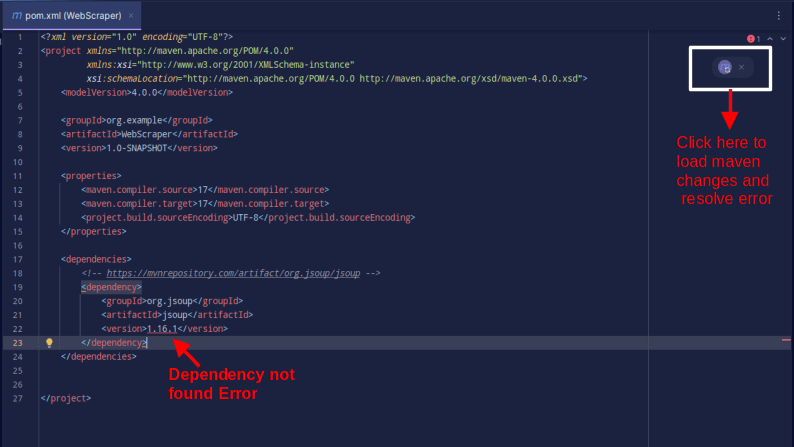
Pokud se zobrazí chyba, že závislost nelze najít, klikněte na ikonu pro Maven, čímž načtete změny a knihovna bude načtena a chyba se odstraní.
Tím je vaše prostředí plně nastaveno pro vývoj webové škrabky.
Web scraping s Java
Pro účely web scrapingu budeme získávat data z webu ScrapeThisSite. Tento web poskytuje prostředí pro vývojáře, kde si mohou procvičovat web scraping bez obav z právních problémů.
Chcete-li škrábat web pomocí Javy:
1. V levém panelu IntelliJ rozbalte složku „src“ a dále složku „main“. Uvnitř složky „main“ se nachází složka „java“. Klikněte na ni pravým tlačítkem a zvolte „Nový“, následně „Java Class“.
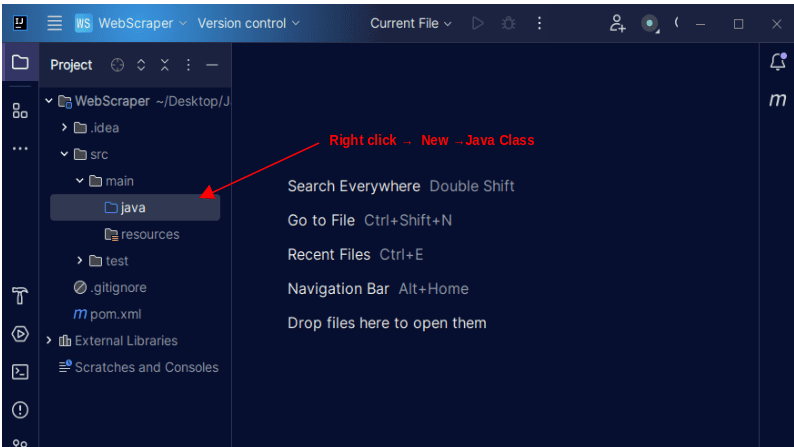
Pojmenujte třídu libovolně, například „WebScraper“ a stiskněte Enter. Tím se vytvoří nová třída Java.
Otevřete nově vytvořený soubor obsahující třídu Java, kterou jste právě vytvořili.
2. Web scraping zahrnuje získávání dat z webových stránek. Nejprve musíme určit URL adresu, ze které chceme data extrahovat. Poté se musíme k této adrese připojit a provést požadavek GET, abychom načetli obsah HTML stránky.
Kód, který to provádí, je uveden níže:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
System.out.println(doc);
} catch (IOException e) {
System.out.println("An IOException occurred. Please try again.");
}
}
}
Výstup:
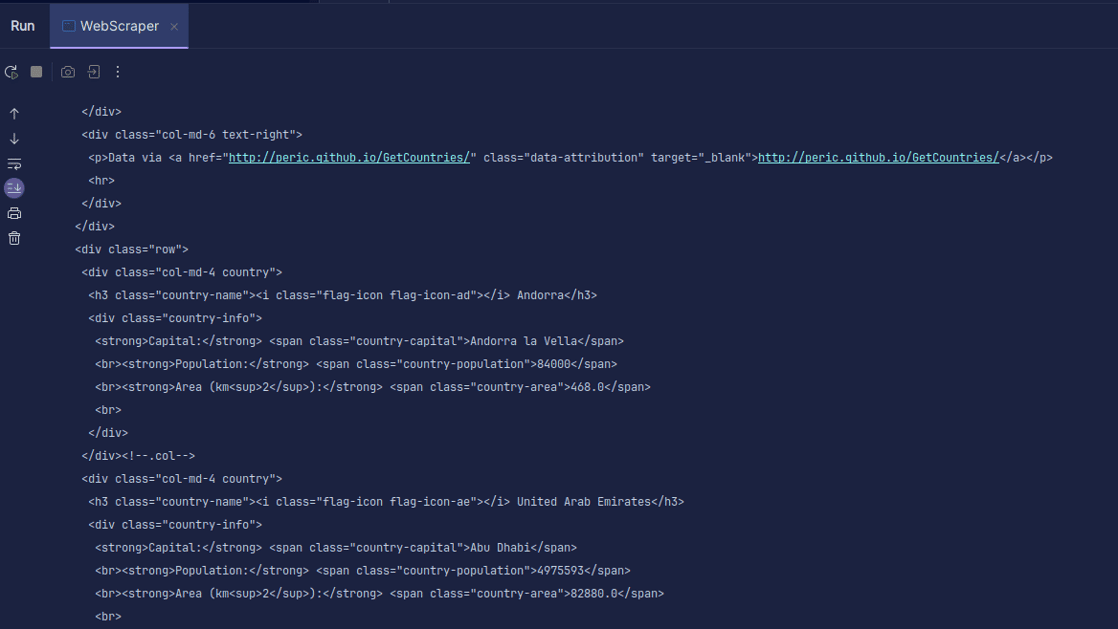
Jak můžete vidět, je vrácen obsah HTML stránky, který se následně vypíše. Během scrapingu může dojít k chybě ve zadané URL adrese nebo zdroj, ze kterého se snažíme data získat, nemusí vůbec existovat. Proto je nezbytné ošetřit náš kód pomocí příkazu „try-catch“.
Řádek:
Document doc = Jsoup.connect(url).get();
Slouží k připojení k zadané URL adrese. Metoda „get()“ se používá k vytvoření požadavku GET a načtení HTML stránky. Vrácený výsledek je uložen do objektu dokumentu JSOUP s názvem „doc“. Uložení výsledku do objektu JSOUP umožňuje používat rozhraní API knihovny JSOUP k manipulaci s vráceným HTML.
3. Přejděte na ScrapeThisSite a prohlédněte si strukturu HTML stránky. V HTML kódu byste měli vidět strukturu podobnou následující:
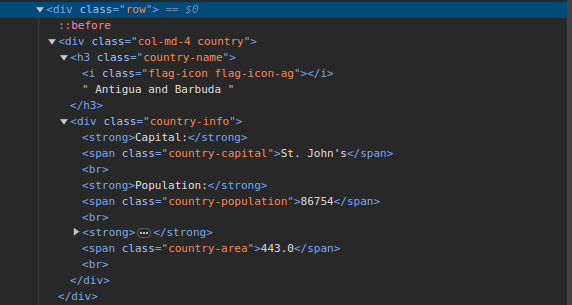
Všimněte si, že všechny země na stránce jsou uloženy pod podobnou strukturou. Existuje div s třídou „country“, který obsahuje prvek h3 s třídou „country-name“, kde je uložen název každé země.
Uvnitř divu s třídou „country“ se nachází další div s třídou „country-info“, který obsahuje informace, jako je hlavní město, populace a rozloha dané země. Tyto názvy tříd můžeme použít k výběru HTML prvků a extrahování informací z nich.
4. Extrahujte konkrétní obsah z HTML stránky pomocí následujících řádků kódu:
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " Population - " + population);
}
Pro výběr elementů z HTML stránky, které odpovídají konkrétnímu CSS selektoru, používáme metodu „select()“. V tomto případě předáváme názvy tříd. Po prozkoumání stránky jsme zjistili, že všechny informace o zemích jsou uloženy uvnitř divů s třídou „country“.
Každá země má vlastní div s třídou „country“ a uvnitř tohoto divu jsou informace jako název země, hlavní město a počet obyvatel.
Proto nejprve vybereme všechny země na stránce pomocí selektoru třídy „.country“. Výsledek uložíme do proměnné „countries“ typu Elements, která funguje podobně jako seznam. Poté pomocí cyklu „for“ procházíme jednotlivé země a extrahujeme název země, hlavní město a populaci a tyto údaje vypíšeme na obrazovku.
Celý kód je zobrazen níže:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import org.jsoup.nodes.Element;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " - Population - " + population);
}
} catch (IOException e) {
System.out.println("An IOException occurred. Please try again.");
}
}
}
Výstup:
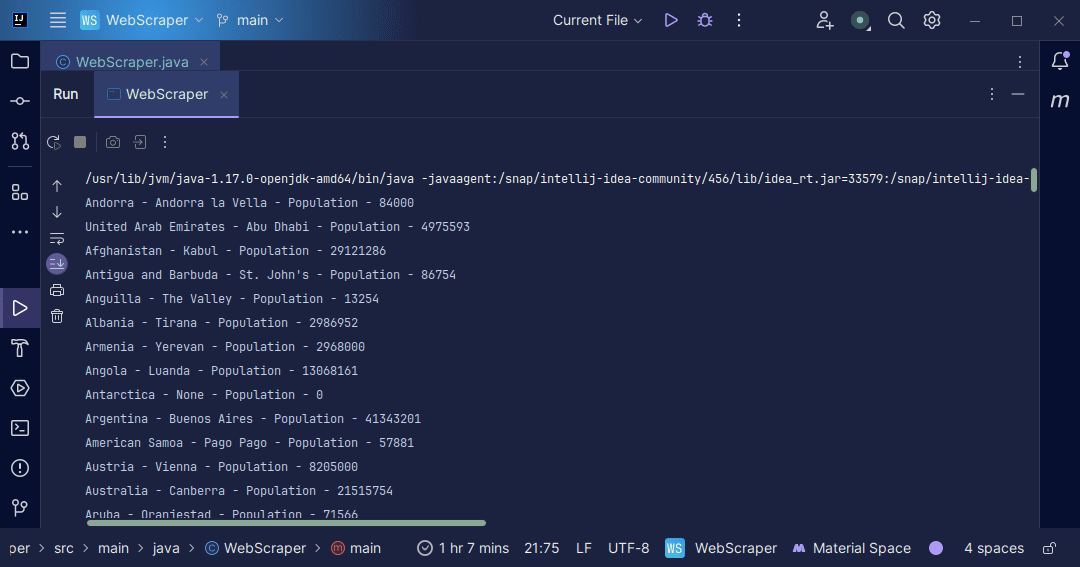
S informacemi, které získáme z webové stránky, můžeme dále pracovat. Můžeme je například vypsat na obrazovku, jak jsme to udělali, nebo je uložit do souboru pro další zpracování.
Závěr
Web scraping je vynikající metoda pro extrahování nestrukturovaných dat z webových stránek, ukládání dat strukturovaným způsobem a zpracování dat za účelem získání užitečných informací. Je však nezbytné být při web scrapingu opatrní, protože některé weby tuto aktivitu zakazují.
Pro jistotu, využívejte webové stránky, které poskytují sandboxy pro cvičení web scrapingu. Pokud taková možnost není, vždy zkontrolujte soubor „robots.txt“ webové stránky, kterou se chystáte škrábat, abyste ověřili, zda je scraping povolen.
Pro vývoj webové škrabky je Java vynikající volbou, protože nabízí množství knihoven, které usnadňují a zefektivňují tento proces. Pro vývojáře v jazyce Java je vytvoření webové škrabky výbornou příležitostí pro další rozvoj programátorských dovedností. Takže neváhejte a vytvořte si vlastní webovou škrabku nebo si upravte tu, kterou jsme použili v článku, a získávejte různé druhy informací. Přejeme vám mnoho úspěchů při kódování!
Můžete také prozkoumat některé oblíbené cloudové platformy pro web scraping.