Co je sdílení databáze?
Shardování databází je technika, která umožňuje dosáhnout horizontální škálovatelnosti u rozsáhlých systémů.
Většina reálných systémů zahrnuje databázový server, který zpracovává velké množství požadavků na čtení i značné množství požadavků na zápis. Tato situace může vést k přetížení serveru a snížení celkového výkonu systému.
Pro zmírnění těchto problémů a zlepšení výkonu existují různé metody, jako je replikace databáze a shardování. V tomto článku se podíváme na techniky pro optimalizaci výkonu, včetně:
- Vertikálního škálování databázového serveru
- Replikace databáze
- Horizontálního dělení dat
Po prozkoumání těchto technik se zaměříme na principy fungování shardování, jeho výhody a omezení.
Začněme!
Techniky pro zlepšení výkonu systému
Nejprve si rozeberme, jak zlepšit výkon systému, pokud je databázový server úzkým hrdlem:
#1. Zvýšení výkonu databázového serveru
Zvýšení kapacity serveru, na kterém běží databáze, se jeví jako jednoduché řešení. To zahrnuje navýšení výpočetního výkonu, přidání paměti RAM a další podobné vylepšení.
Tato technika má však svá omezení. Nemůžeme mít server s nekonečným úložištěm a výpočetním výkonem. Navíc, za určitou hranicí, další investice do hardware přinášejí stále menší zlepšení.
#2. Replikace databáze
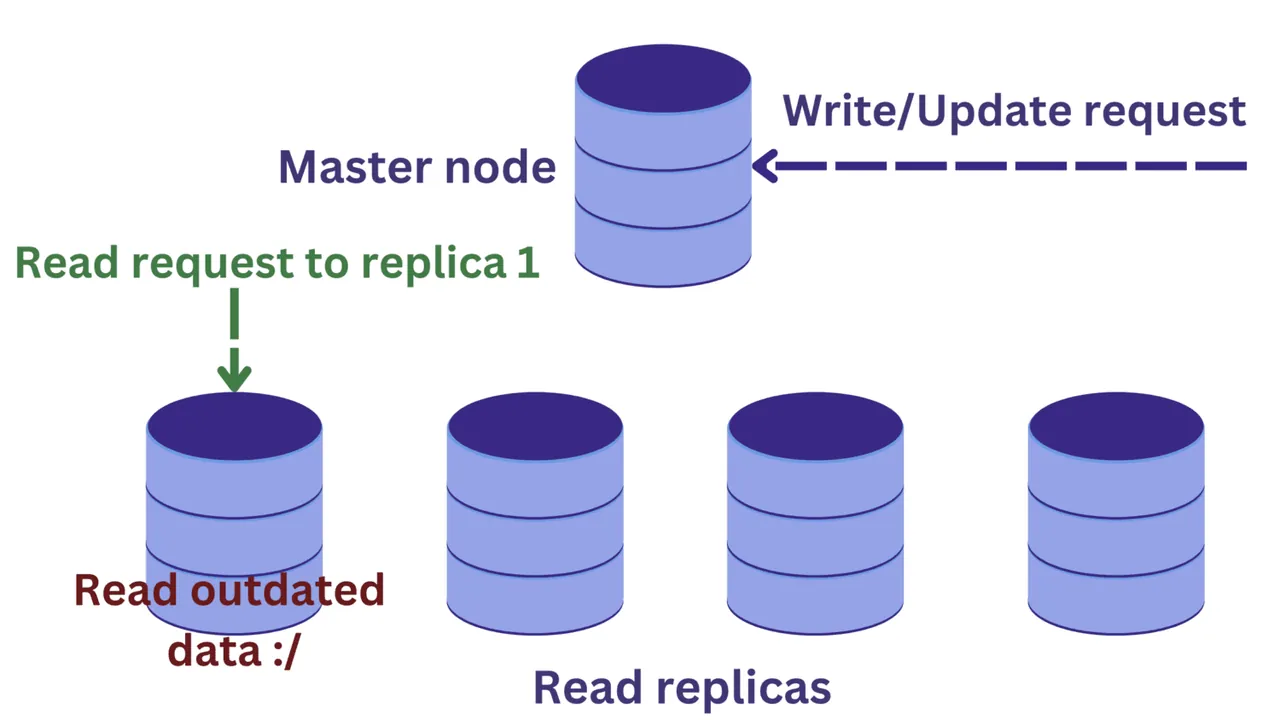
Pokud je instance databázového serveru přetížena příchozími požadavky, můžeme uvažovat o replikaci databáze.
Při replikaci máme jeden hlavní uzel, který obvykle zpracovává požadavky na zápis, a několik replik pro čtení.
Tím se zvyšuje dostupnost a snižuje se zatížení systému. Nyní je možné zpracovávat více dotazů paralelně, protože požadavky na čtení mohou být směrovány na jednu z replik.
Tento přístup však přináší i nové problémy. Zápisy do hlavního uzlu mění data, a tyto změny se pravidelně šíří do replik.
Představme si, že na jednu z replik pro čtení dorazí požadavek ve stejnou dobu, kdy probíhá operace zápisu do hlavního uzlu.
Změny z hlavního uzlu se ještě nestihly přenést do replik. V takovém případě můžeme číst zastaralá data, což není žádoucí.
#3. Horizontální dělení
Horizontální dělení je další metoda pro optimalizaci výkonu systému. Můžeme mít velkou tabulku s miliardami záznamů (například tabulku zákazníků a transakcí).
Operace čtení z takové tabulky jsou pomalé. Horizontální dělení rozdělí tuto velkou tabulku na menší části (nebo menší tabulky), ze kterých můžeme číst. Relační databáze jako PostgreSQL podporují dělení nativně.
Všechny části jsou však stále uvnitř jedné instance databázového serveru. Rozdíl je v tom, že nyní čteme z menších oddílů namísto jedné velké tabulky.
Pokud se počet příchozích požadavků zvýší, jeden server nemusí být schopen zvládnout takový nárůst.
Jak funguje shardování databáze?
Nyní, když jsme probrali metody zlepšení výkonu a jejich limity, pojďme pochopit, jak funguje shardování databáze.
Při shardování rozdělujeme jednu velkou databázi na několik menších databází, z nichž každá běží na samostatné instanci databázového serveru. Každá taková menší databáze se nazývá shard. Každý shard obsahuje unikátní podmnožinu dat.
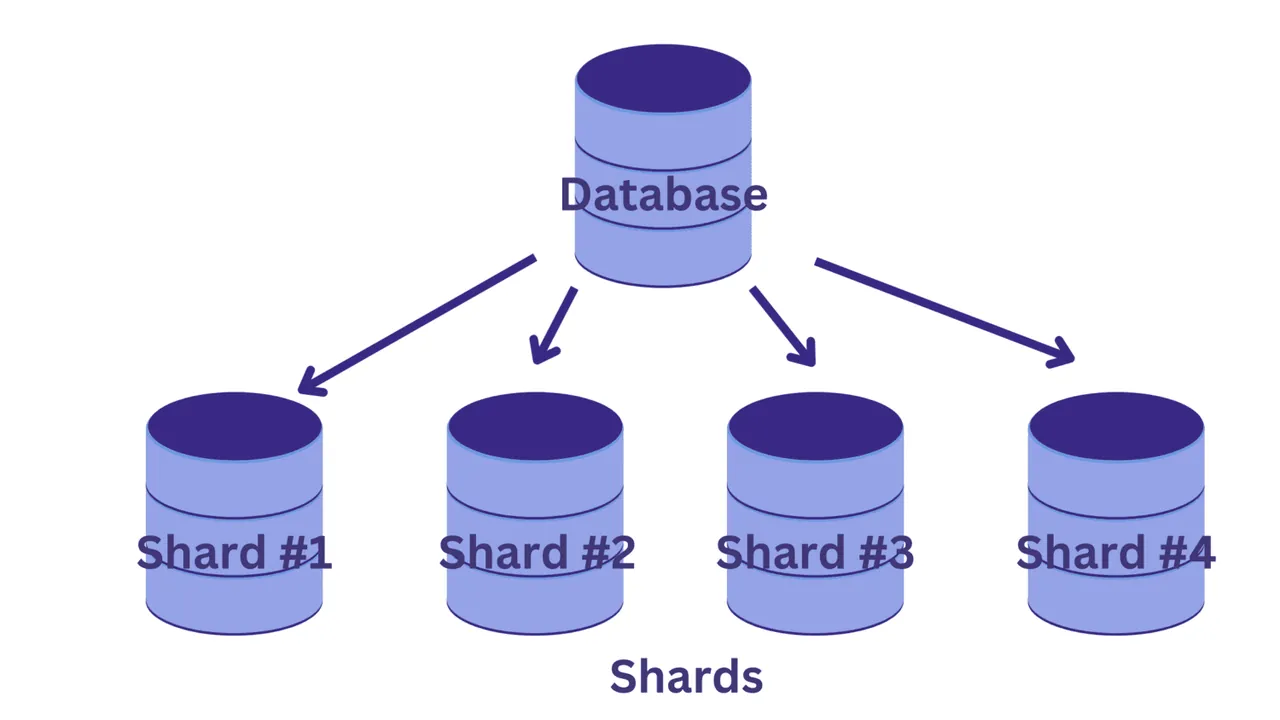
Jak ale rozhodneme, jak rozdělit databázi na jednotlivé shardy? A jak určíme, který záznam se dostane do kterého shardu?
🔑 Zde přichází na řadu sharding klíč.
Pochopení sharding klíče
Pojďme se podívat na roli sharding klíče.
Sharding klíč, obvykle sloupec (nebo kombinace sloupců) v databázové tabulce, by měl být zvolen tak, aby rozdělení dat mezi shardy bylo co nejvíce rovnoměrné. Chceme se vyhnout situaci, kdy je jeden shard mnohem větší než ostatní.
V databázi, která ukládá informace o zákaznících a jejich transakcích, je například `customer_ID` dobrým kandidátem na sharding klíč.
Jakmile zvolíme sharding klíč, můžeme použít hashovací funkci, která určí, který záznam se uloží do kterého shardu.
V tomto příkladu si představme, že potřebujeme rozdělit databázi na pět shardů (shard #0 až shard #4) s `customer_ID` jako sharding klíčem. V takovém případě může být jednoduchá hashovací funkce `customer_ID % 5`.
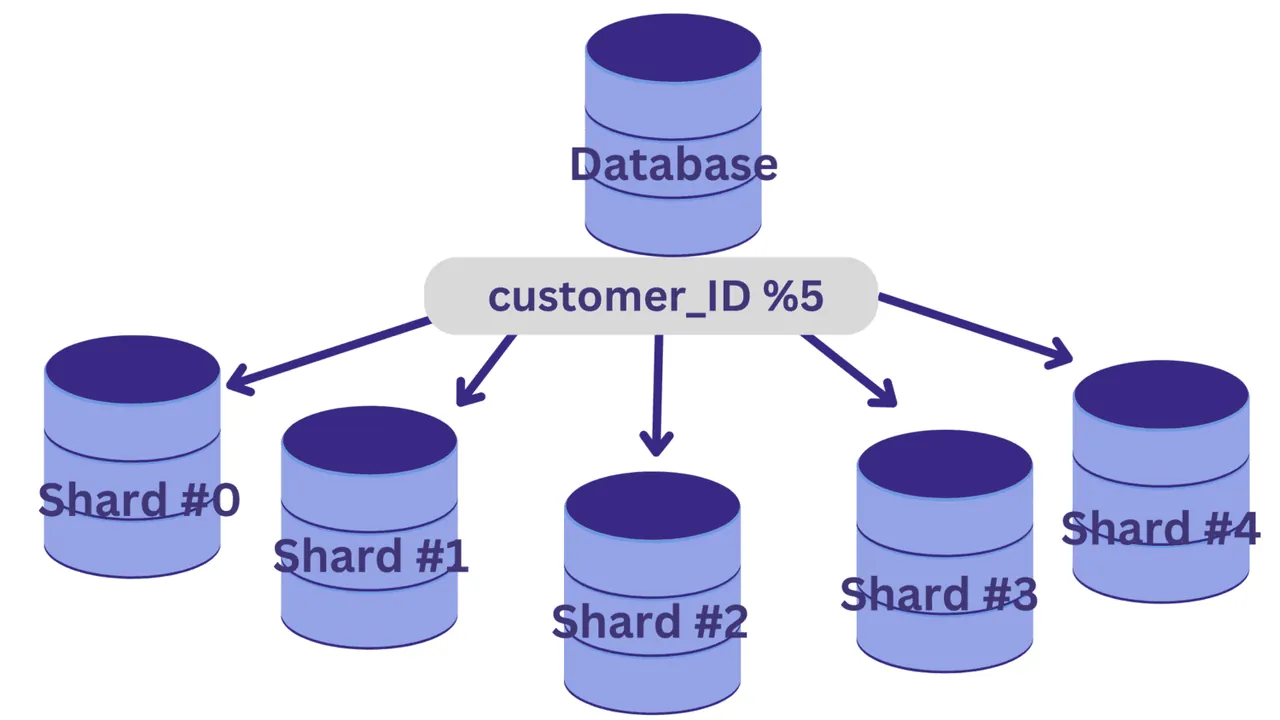
Všechny hodnoty `customer_ID`, které po dělení 5 dají zbytek nula, budou umístěny do shard #0. Hodnoty, které dávají zbytek 1 až 4, se uloží do shardů #1 až #4.
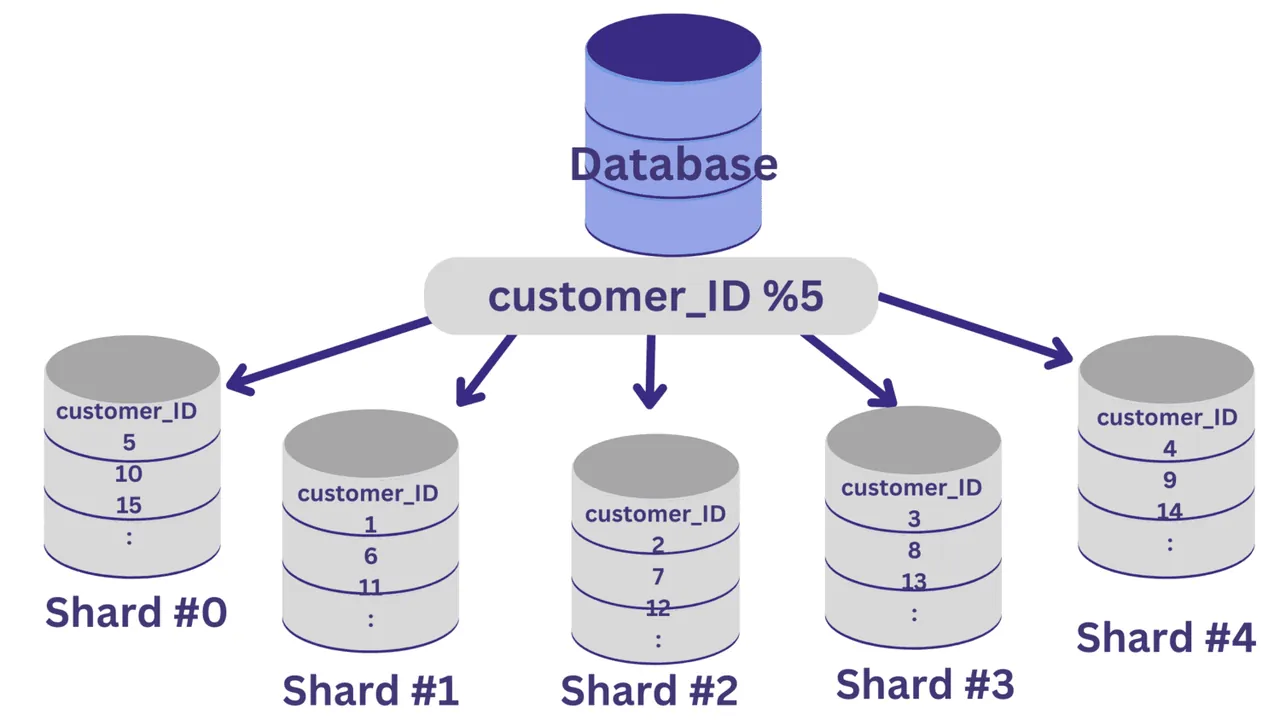
Po implementaci shardování je důležité mít směrovací vrstvu, která posílá příchozí požadavky do správného databázového shardu.
Výhody shardování databáze
Zde jsou některé výhody shardování databáze:
#1. Vysoká škálovatelnost
Větší databázi je vždy možné rozdělit na menší fragmenty. Shardování databáze nám tak umožňuje horizontální škálování.
#2. Vysoká dostupnost
Pokud je jen jedna instance databázového serveru, která zpracovává veškeré požadavky, máme jediný bod selhání. Pokud databázový server přestane fungovat, přestane fungovat i celá aplikace.
U shardované databáze je šance, že všechny fragmenty budou nedostupné ve stejnou chvíli, poměrně malá. Pokud tedy jeden shard vypadne, nebudeme moci zpracovávat požadavky, které na něj cílí. Ostatní shardy však mohou dále zpracovávat příchozí požadavky. To přináší vysokou dostupnost a odolnost proti chybám.
Omezení shardování databáze
Nyní se podívejme na některá omezení shardování databáze:
#1. Složitost
I když shardování přináší výhody z hlediska škálovatelnosti a odolnosti proti chybám, také zvyšuje složitost systému.
Od mapování záznamů na jednotlivé shardy přes implementaci směrovací vrstvy až po směrování dotazů na správné shardy dat, shardování sebou nese značnou složitost.
#2. Reshardování
Dalším omezením shardování je nutnost reshardování.
Přestože používáme hashovací funkci pro dosažení rovnoměrného rozložení dat, je možné, že jeden shard bude mnohem větší než ostatní. V takovém případě musíme přeskupit shardy, což vyžaduje značné úsilí.
#3. Provádění složitých dotazů
Pokud potřebujete spouštět analytické dotazy, které vyžadují spojování dat z více shardů, může to být problém. Pro obcházení tohoto problému můžeme denormalizovat databáze, ale i to vyžaduje určité úsilí.
Závěr
Závěrem shrňme to, co jsme se naučili.
Vertikální škálování hardware nemusí být vždy nejlepší řešení. Proto se nedoporučuje pouze posilovat instanci serveru. Zkoumali jsme také techniky jako replikace a horizontální dělení a jejich omezení.
Poté jsme se dozvěděli, jak funguje shardování databáze, tedy rozdělení jedné velké databáze na menší, snadno spravovatelné fragmenty. Probrali jsme, jak by měl být sharding klíč zvolen tak, aby se dosáhlo rovnoměrného rozložení dat, a jak je důležitá směrovací vrstva pro směrování požadavků na správné shardy.
Shardování databáze má výhody, jako je vysoká dostupnost a škálovatelnost. Mezi nevýhody patří složitost nastavení a reshardování, když se některé shardy naplní.
Pokud si myslíte, že výhody shardování převažují nad složitostí, je to něco, o čem byste měli uvažovat. Také se podívejte na srovnání různých relačních databází AWS.
