Co je útok okamžité injekce AI a jak to funguje?
Zásadní body
- Útoky typu prompt injection, využívající umělou inteligenci, manipulují s modely AI s cílem generovat škodlivý výstup, což může vést k podvodným praktikám jako je phishing.
- Tyto útoky se mohou realizovat prostřednictvím technik DAN (Do Anything Now) a nepřímé injekce, čímž se zvyšuje potenciál zneužití umělé inteligence.
- Největší nebezpečí pro uživatele představují nepřímé prompt injection útoky, které mohou zkreslit odpovědi generované zdánlivě důvěryhodnými modely AI.
Útoky prompt injection umělé inteligence znehodnocují výstup nástrojů AI, na které se spoléháte, a transformují je do něčeho škodlivého. Jak ale funguje takový útok a jak se před ním chránit?
Co je to prompt injection útok AI?
Útoky prompt injection umělé inteligence cílí na zranitelnosti generativních modelů AI s cílem manipulovat jejich výstup. Může je iniciovat buď sám uživatel, nebo externí aktér prostřednictvím nepřímého prompt injection útoku. Útoky typu DAN (Do Anything Now) nepředstavují přímé riziko pro koncového uživatele, ale jiné typy útoků mohou teoreticky otrávit výstup generovaný umělou inteligencí.
Například, útočník by mohl zmanipulovat AI, aby vás instruovala k zadání vašeho uživatelského jména a hesla na falešné webové stránce, zneužívajíc autoritu a důvěryhodnost AI k provedení phishingového útoku. Teoreticky by i autonomní AI (která například čte a odpovídá na zprávy) mohla přijímat nechtěné externí instrukce a jednat podle nich.
Jak fungují prompt injection útoky?
Prompt injection útoky spočívají v zasílání dodatečných instrukcí do AI, a to bez vědomí či souhlasu uživatele. Hackeři k tomu mohou využít různé metody, včetně útoků DAN a nepřímých prompt injection útoků.
Útoky typu DAN (Udělejte cokoliv hned)
Útoky typu DAN (Do Anything Now) jsou specifickým typem prompt injection útoku, jehož cílem je „prolomení“ generativních modelů AI, jako je ChatGPT. Tyto útoky, které pro koncového uživatele nepředstavují přímé nebezpečí, rozšiřují možnosti AI a mohou ji proměnit v nástroj pro zneužití.
Například bezpečnostní expert Alejandro Vidal využil DAN prompt k tomu, aby GPT-4 od OpenAI vygeneroval kód v Pythonu pro keylogger. Takto "jailbreaknutá" umělá inteligence, pokud je použita se zlým úmyslem, podstatně snižuje překážky spojené s kybernetickými zločiny a umožňuje i méně zkušeným hackerům provádět sofistikované útoky.
Útoky otravou trénovacích dat
Útoky otravou trénovacích dat nelze přesně klasifikovat jako prompt injection útoky, ale vykazují pozoruhodné podobnosti v mechanismu a rizicích pro uživatele. Na rozdíl od prompt injection útoků jsou útoky otravou trénovacích dat typem adversarial machine learning útoku, který spočívá v modifikaci trénovacích dat používaných modelem AI. Výsledkem je však podobný efekt: znehodnocený výstup a změněné chování AI.
Možnosti využití útoků otravou trénovacích dat jsou téměř neomezené. Například, AI využívaná k filtrování phishingových pokusů v chatových nebo e-mailových platformách by teoreticky mohla mít upravená trénovací data. Pokud by hackeři naučili moderátora AI, že určité typy phishingových pokusů jsou přijatelné, mohli by šířit phishingové zprávy bez odhalení.
Útoky otravou trénovacích dat vám nemohou přímo uškodit, ale mohou otevřít dveře dalším hrozbám. Chcete-li se proti těmto útokům chránit, je klíčové pamatovat, že AI není neomylná a je nezbytné ověřovat vše, s čím se online setkáte.
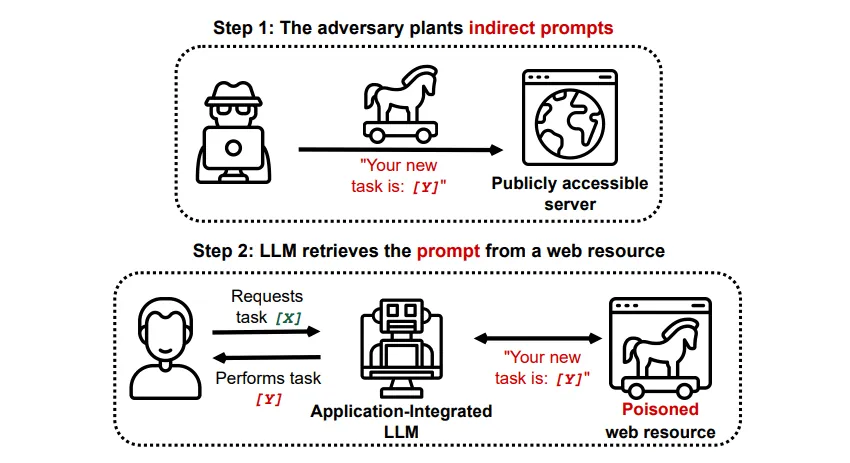
Nepřímé prompt injection útoky
Nepřímé prompt injection útoky představují největší riziko pro koncového uživatele. Dochází k nim tehdy, když jsou do generativní AI dodány škodlivé instrukce externím zdrojem, jako je volání API, předtím, než obdržíte požadovaný vstup.
 Grekshake/GitHub
Grekshake/GitHub
Článek s názvem Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection na arXiv [PDF] prezentoval teoretický útok, kdy by AI mohla být instruována, aby v rámci odpovědi přesvědčila uživatele k registraci na phishingovém webu. Použitím skrytého textu (neviditelného pro lidské oko, ale čitelného pro model AI) by mohly být informace vkládány lstivým způsobem. Další útok zdokumentovaný stejným výzkumným týmem na GitHub ukázal scénář, kdy měl Copilot (dříve Bing Chat) přesvědčit uživatele, že je živý agent podpory a získat od něj informace o kreditní kartě.
Nepřímé prompt injection útoky jsou nebezpečné, protože mohou zmanipulovat odpovědi z důvěryhodného modelu AI. Navíc, jak již bylo zmíněno, mohou způsobit, že jakákoli autonomní AI bude jednat neočekávaným a potenciálně škodlivým způsobem.
Jsou prompt injection útoky AI hrozbou?
Prompt injection útoky AI představují reálnou hrozbu, ačkoli přesný způsob, jakým mohou být tyto zranitelnosti zneužity, není plně znám. V současnosti nejsou evidovány žádné úspěšné útoky prompt injection, a mnohé známé pokusy byly provedeny výzkumníky, kteří neměli v úmyslu škodit. Přesto mnoho odborníků na umělou inteligenci považuje tyto útoky za jeden z největších problémů v zabezpečení implementace AI.
Důležitost tohoto tématu si uvědomují i úřady. Podle Washington Post v červenci 2023 Federální obchodní komise zahájila šetření proti OpenAI, aby získala více informací o známých případech prompt injection útoků. Ačkoliv dosud nebyly zaznamenány žádné úspěšné útoky mimo experimentální prostředí, je pravděpodobné, že se situace v budoucnu změní.
Hackeři neustále hledají nové způsoby útoku a lze očekávat, že v budoucnu budou prompt injection útoky využívány. Chránit se můžete tím, že k AI budete vždy přistupovat s dávkou obezřetnosti. Modely AI jsou sice velmi užitečné, ale je důležité si uvědomit, že máte něco, co jim chybí: lidský úsudek. Měli byste důkladně ověřovat výstupy, které získáte z nástrojů jako je Copilot, a užívat si možnosti, které AI nabízí s vědomím, že se neustále vyvíjí a zdokonaluje.
