

Klíčové věci
- Platformy sociálních médií prodávají uživatelská data společnostem s umělou inteligencí za účelem školení generativních modelů umělé inteligence, a to navzdory obavám o soukromí.
- Platformy jako Meta, Reddit, Tumblr a WordPress.com se aktivně podílejí na těchto licenčních dohodách na data pro školení AI.
- Uživatelé mohou podniknout několik malých kroků k ochraně svých dat, například upravit nastavení soukromí, odhlásit se ze sdílení a dávat si pozor na to, co zveřejňují online.
Jedním z nejnovějších způsobů, jak společnosti sociálních médií monetizují uživatelská data, jsou dohody se společnostmi AI. Existuje však něco, co mohou běžní uživatelé udělat pro ochranu svých dat a obsahu?
Používání dat sociálních médií k trénování generativních modelů umělé inteligence bylo kontroverzním krokem – ale nezdá se, že by to společnostem sociálních médií bránilo v rozdávání uživatelských dat.
Meta již využívá data sociálních médií k trénování generativních funkcí umělé inteligence oznámených na Meta Connect v roce 2023. To zahrnuje Meta AI a funkce, jako je vytváření nálepek generovaných umělou inteligencí na WhatsApp.
Jak uvedl Mike Clark, ředitel produktového managementu společnosti Meta, v a Příspěvek Meta Newsroom:
„Veřejně sdílené příspěvky z Instagramu a Facebooku – včetně fotografií a textu – byly součástí dat používaných k trénování generativních modelů umělé inteligence, které jsou základem funkcí, které jsme oznámili na Connect.“
Nezdá se, že by se tento trend v roce 2024 zpomaloval ReutersReddit uzavřel s Googlem dohodu o zpřístupnění obsahu platformy sociálních médií pro školení modelů umělé inteligence.
Podání S-1 na Redditu pro svou IPO, podanou 22. února 2024, potvrzuje, že společnost zkoumá licenční smlouvy. V podání je uvedeno:
„Data na Redditu jsou základní součástí konstrukce současné technologie umělé inteligence a mnoha LLM. Věříme, že obrovský korpus konverzačních dat a znalostí na Redditu bude i nadále hrát roli při školení a zlepšování LLM.“
Upřesňuje, že Reddit je „v raných fázích umožňování třetím stranám licencovat přístup k vyhledávání, analýze a zobrazování historických dat a dat v reálném čase z naší platformy“ za účelem školení LLM.
A i když jsou Meta a Reddit jedny z největších jmen na sociálních sítích, nejsou to jediné platformy, které se podílejí na používání dat sociálních médií k výcviku AI. Podle a Zpráva 404 MediaTumblr a WordPress.com se připravují na prodej uživatelských dat Midjourney a OpenAI.
Je pravděpodobné, že pokud používáte Facebook, Instagram, Reddit, Tumblr nebo WordPress.com, váš veřejně dostupný obsah již byl použit při školení LLM.
Pokud například použijete Vyhledávací nástroj Washington Post Chcete-li vidět, jaké stránky byly zahrnuty do datové sady Google C4, která byla použita jako součást Bardova školení, uvidíte, že Reddit.com představuje 7,9 milionu tokenů.

Na Tumblr.com připadá 1,6 milionu tokenů. Můj vlastní malý web, který používá WordPress.com, představoval 14 000 tokenů – takže do datové sady mohly být zahrnuty malé osobní blogy.
S probíhajícími dohodami mezi společnostmi s umělou inteligencí a společnostmi zabývajícími se sociálními médii budou licenční dohody znamenat, že tato data budou aktivně prodávána, nikoli jen seškrabována z webu.
Ale pokud jde o budoucí zpracování, co s tím můžete dělat? Společnost Meta představila a formulář pro generativní práva subjektu údajů AI který vám umožňuje vznést námitku nebo omezit zpracování vašich osobních údajů od třetích stran za účelem školení generativních modelů umělé inteligence Meta.
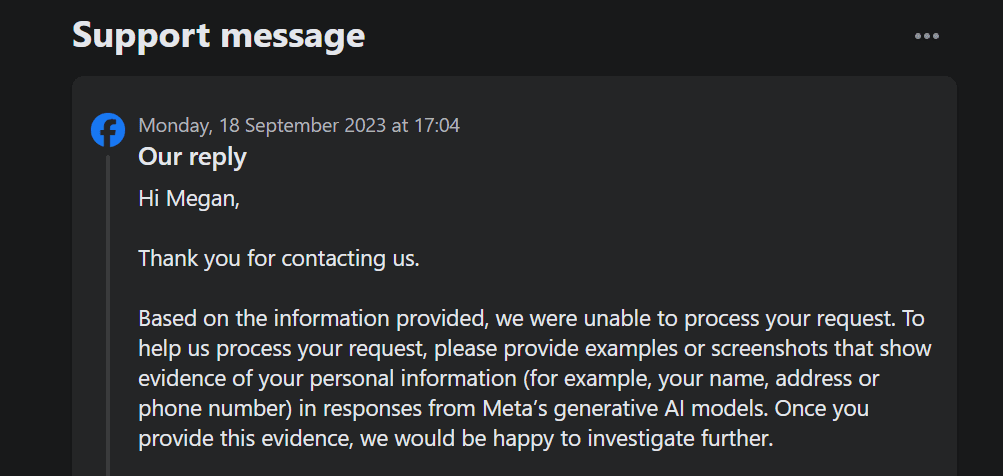
Je pozoruhodné, že tato možnost vám nedovolí vznést námitky proti vlastnímu zpracování vašich dat společností Meta pro trénování generativní umělé inteligence. Kromě toho, když jsem prostřednictvím formuláře odeslal tiket s námitky proti použití mých osobních údajů, tiket podpory po mě vyžadoval, abych prokázal, že mé osobní údaje se již objevují v generativních výsledcích AI společnosti Meta.
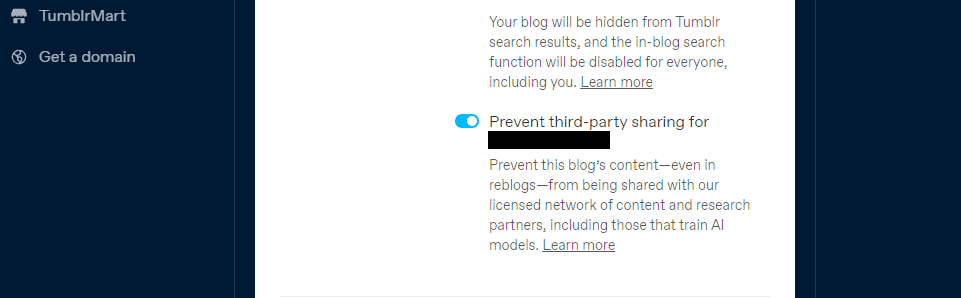
Tumblr také zavedl možnost odhlásit se ze sdílení obsahu vašich veřejných blogů s třetími stranami pomocí nastavení vašeho blogu. Najdete ho v nastavení kliknutím na svůj blog a posunutím dolů do nastavení viditelnosti. Poté zvolte možnost Zabránit sdílení blogu třetí stranou.
Pokud jde o platformu, jako je Instagram, můžete zkusit přepnout svůj účet na Instagramu na soukromý, abyste zabránili použití svých dat. To nezaručuje, že vaše data nebudou použita, ale protože se zdá, že se sběr dat pro LLM zaměřuje na veřejná data, může to být potenciální ochrana.
Svůj účet X (Twitter) můžete také nastavit jako soukromý, ale opět se jedná pouze o potenciální ochranu a nezaručuje, že vaše data zůstanou soukromá.
A společné prohlášení od různých národních komisařů pro informace a expertů z celého světa také navrhla některá opatření pro jednotlivce, kteří chtějí minimalizovat riziko ochrany osobních údajů související s seškrabováním dat ze strany společností AI. Rada zahrnuje:
- Přečtěte si podmínky a zásady ochrany osobních údajů webové stránky, abyste viděli, jak sdílí vaše osobní údaje.
- Omezte informace, které zveřejňujete online, zejména citlivé informace.
- Spravujte svá nastavení soukromí.
- Přemýšlejte dlouhodobě o informacích, které sdílíte online.
- Pokud se domníváte, že vaše data byla nesprávně smazána, kontaktujte společnost nebo web sociálních médií. Pokud nejste spokojeni s jejich odpovědí, podejte stížnost příslušnému úřadu pro ochranu osobních údajů.
Můžete také smazat určité informace online, pokud vám nevyhovuje, že k nim mají přístup třetí strany, ačkoli veřejně dostupné informace ve vašich profilech již mohly být odstraněny.
Bohužel, my jako běžní uživatelé můžeme udělat jen tolik, abychom ochránili svá data před společnostmi AI. Skutečná kontrola nad těmito informacemi pravděpodobně přijde pouze s pomocí regulátorů.